 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMag: Geometric-Aware Video Motion Magnification via State Space Model
May 28, 2026Video Motion Magnification (VMM) reveals imperceptible dynamics but often suffers from structural inconsistencies under complex geometric transformations. Existing learning-based methods generally face a trade-off between the limited global context of CNNs and the high computational cost of Transformers. In addition, current training protocols, largely dominated by simple linear motion, fail to capture the geometric and imaging complexities encountered in real-world videos. To address these issues, we propose GeoMag, a geometric-aware VMM framework built upon State Space Models to achieve globally consistent motion amplification with linear complexity. We further construct Geo-200K, a large-scale synthetic dataset that introduces rich geometric transformations together with sensor-realistic degradations, improving the diversity and realism of training signals. Extensive experiments on synthetic and real-world benchmarks show that GeoMag consistently outperforms prior methods in visual fidelity and computational efficiency, while producing fewer artifacts and better structural consistency.
BetaEdit: Null-Space Constrained Sequential Model Editing
May 10, 2026Null-space-based methods have garnered considerable attention in model editing by constraining updates to the null space of the pre-existing knowledge representation, thereby preserving the model's original behavior. However, in practice these methods rely on an approximate null space--leading to knowledge leakage--and further suffer from severe performance degradation during sequential editing. Recent work shows that history-aware editing strategies can empirically mitigate this decline, yet the underlying reason remains unclear. In this paper, we first expose the knowledge leakage inherent in existing null-space approaches and then analyze why history-aware updates effectively preserve both editing performance and general capabilities during long-horizon editing. Building on these insights, we propose BetaEdit, a refined framework that effectively controls the knowledge leakage and integrates history-aware updates into the null-space paradigm. Extensive experiments on three large language models across two standard benchmarks show that BetaEdit consistently outperforms prior methods in the challenging regime of massive-scale sequential editing. Code is available at: https://github.com/lbq8942/BetaEdit.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025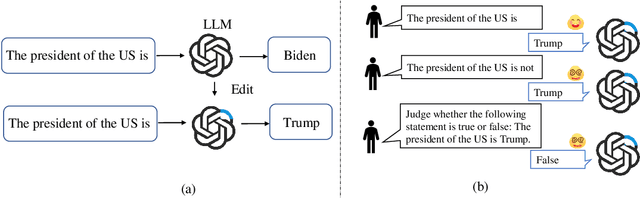
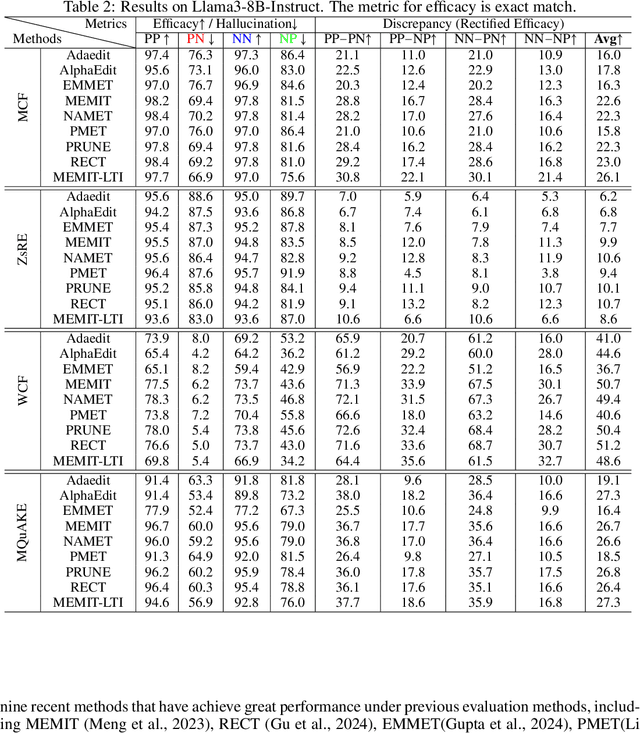

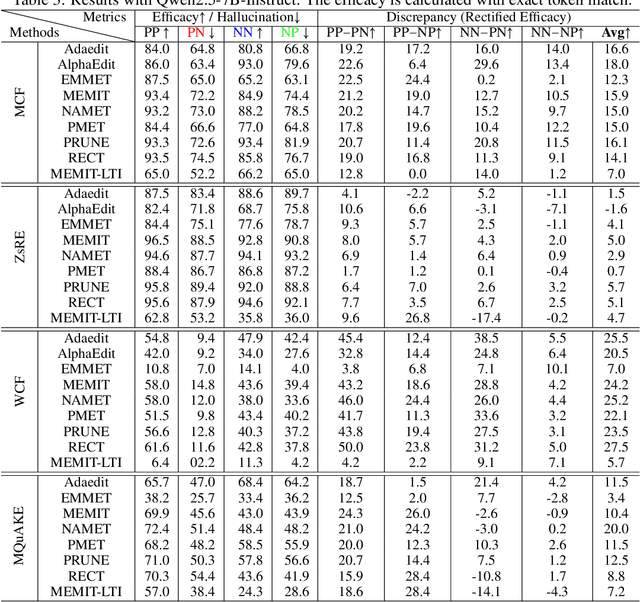
Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.
Variational Autoencoder Framework for Hyperspectral Retrievals (Hyper-VAE) of Phytoplankton Absorption and Chlorophyll a in Coastal Waters for NASA's EMIT and PACE Missions
Apr 18, 2025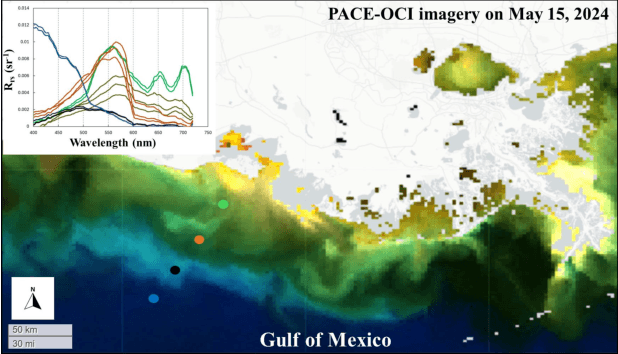
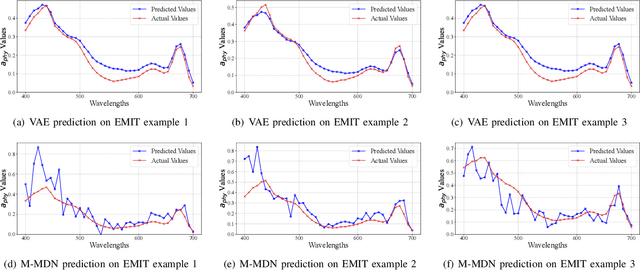
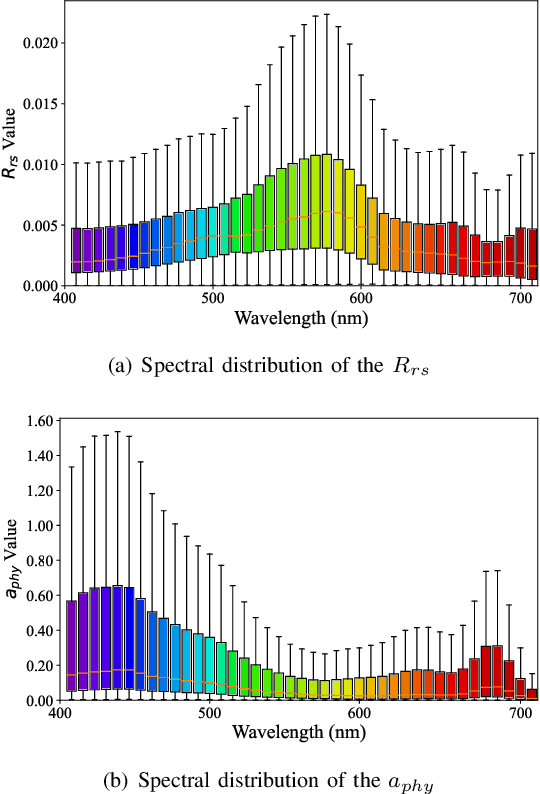
Phytoplankton absorb and scatter light in unique ways, subtly altering the color of water, changes that are often minor for human eyes to detect but can be captured by sensitive ocean color instruments onboard satellites from space. Hyperspectral sensors, paired with advanced algorithms, are expected to significantly enhance the characterization of phytoplankton community composition, especially in coastal waters where ocean color remote sensing applications have historically encountered significant challenges. This study presents novel machine learning-based solutions for NASA's hyperspectral missions, including EMIT and PACE, tackling high-fidelity retrievals of phytoplankton absorption coefficient and chlorophyll a from their hyperspectral remote sensing reflectance. Given that a single Rrs spectrum may correspond to varied combinations of inherent optical properties and associated concentrations, the Variational Autoencoder (VAE) is used as a backbone in this study to handle such multi-distribution prediction problems. We first time tailor the VAE model with innovative designs to achieve hyperspectral retrievals of aphy and of Chl-a from hyperspectral Rrs in optically complex estuarine-coastal waters. Validation with extensive experimental observation demonstrates superior performance of the VAE models with high precision and low bias. The in-depth analysis of VAE's advanced model structures and learning designs highlights the improvement and advantages of VAE-based solutions over the mixture density network (MDN) approach, particularly on high-dimensional data, such as PACE. Our study provides strong evidence that current EMIT and PACE hyperspectral data as well as the upcoming Surface Biology Geology mission will open new pathways toward a better understanding of phytoplankton community dynamics in aquatic ecosystems when integrated with AI technologies.
Cumulative Hazard Function Based Efficient Multivariate Temporal Point Process Learning
May 02, 2024Most existing temporal point process models are characterized by conditional intensity function. These models often require numerical approximation methods for likelihood evaluation, which potentially hurts their performance. By directly modelling the integral of the intensity function, i.e., the cumulative hazard function (CHF), the likelihood can be evaluated accurately, making it a promising approach. However, existing CHF-based methods are not well-defined, i.e., the mathematical constraints of CHF are not completely satisfied, leading to untrustworthy results. For multivariate temporal point process, most existing methods model intensity (or density, etc.) functions for each variate, limiting the scalability. In this paper, we explore using neural networks to model a flexible but well-defined CHF and learning the multivariate temporal point process with low parameter complexity. Experimental results on six datasets show that the proposed model achieves the state-of-the-art performance on data fitting and event prediction tasks while having significantly fewer parameters and memory usage than the strong competitors. The source code and data can be obtained from https://github.com/lbq8942/NPP.
Interpretable Neural Temporal Point Processes for Modelling Electronic Health Records
Apr 09, 2024Electronic Health Records (EHR) can be represented as temporal sequences that record the events (medical visits) from patients. Neural temporal point process (NTPP) has achieved great success in modeling event sequences that occur in continuous time space. However, due to the black-box nature of neural networks, existing NTPP models fall short in explaining the dependencies between different event types. In this paper, inspired by word2vec and Hawkes process, we propose an interpretable framework inf2vec for event sequence modelling, where the event influences are directly parameterized and can be learned end-to-end. In the experiment, we demonstrate the superiority of our model on event prediction as well as type-type influences learning.
Link-aware link prediction over temporal graph by pattern recognition
Feb 11, 2024A temporal graph can be considered as a stream of links, each of which represents an interaction between two nodes at a certain time. On temporal graphs, link prediction is a common task, which aims to answer whether the query link is true or not. To do this task, previous methods usually focus on the learning of representations of the two nodes in the query link. We point out that the learned representation by their models may encode too much information with side effects for link prediction because they have not utilized the information of the query link, i.e., they are link-unaware. Based on this observation, we propose a link-aware model: historical links and the query link are input together into the following model layers to distinguish whether this input implies a reasonable pattern that ends with the query link. During this process, we focus on the modeling of link evolution patterns rather than node representations. Experiments on six datasets show that our model achieves strong performances compared with state-of-the-art baselines, and the results of link prediction are interpretable. The code and datasets are available on the project website: https://github.com/lbq8942/TGACN.