 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We Evaluating the Edit Locality of LLM Model Editing Properly?
Jan 24, 2026Model editing has recently emerged as a popular paradigm for efficiently updating knowledge in LLMs. A central desideratum of updating knowledge is to balance editing efficacy, i.e., the successful injection of target knowledge, and specificity (also known as edit locality), i.e., the preservation of existing non-target knowledge. However, we find that existing specificity evaluation protocols are inadequate for this purpose. We systematically elaborated on the three fundamental issues it faces. Beyond the conceptual issues, we further empirically demonstrate that existing specificity metrics are weakly correlated with the strength of specificity regularizers. We also find that current metrics lack sufficient sensitivity, rendering them ineffective at distinguishing the specificity performance of different methods. Finally, we propose a constructive evaluation protocol. Under this protocol, the conflict between open-ended LLMs and the assumption of determined answers is eliminated, query-independent fluency biases are avoided, and the evaluation strictness can be smoothly adjusted within a near-continuous space. Experiments across various LLMs, datasets, and editing methods show that metrics derived from the proposed protocol are more sensitive to changes in the strength of specificity regularizers and exhibit strong correlation with them, enabling more fine-grained discrimination of different methods' knowledge preservation capabilities.
Is Model Editing Built on Sand? Revealing Its Illusory Success and Fragile Foundation
Oct 01, 2025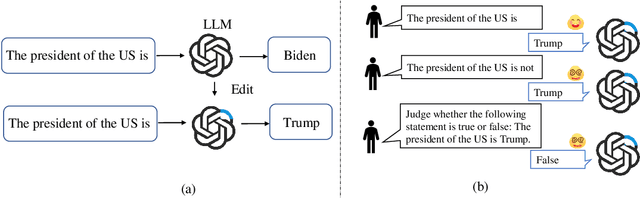
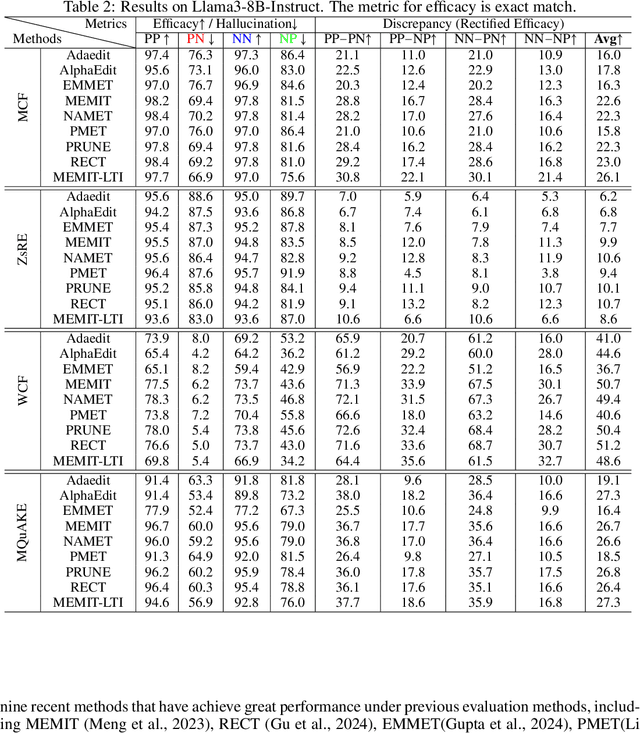

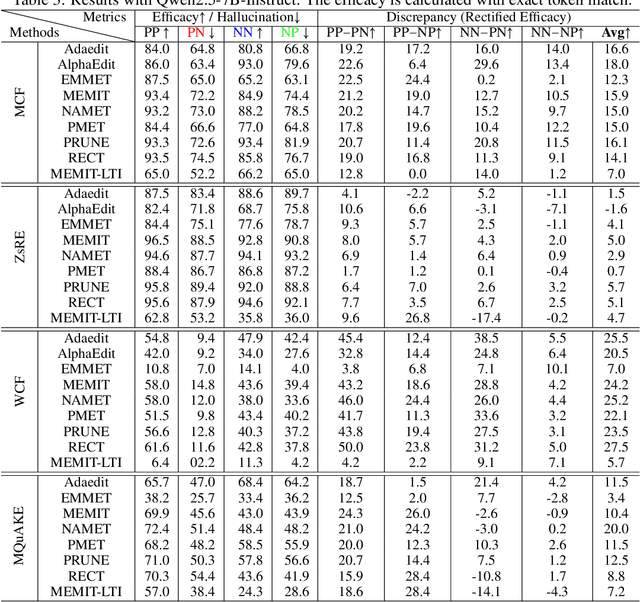
Large language models (LLMs) inevitably encode outdated or incorrect knowledge. Updating, deleting, and forgetting such knowledge is important for alignment, safety, and other issues. To address this issue, model editing has emerged as a promising paradigm: by precisely editing a small subset of parameters such that a specific fact is updated while preserving other knowledge. Despite its great success reported in previous papers, we find the apparent reliability of editing rests on a fragile foundation and the current literature is largely driven by illusory success. The fundamental goal of steering the model's output toward a target with minimal modification would encourage exploiting hidden shortcuts, rather than utilizing real semantics. This problem directly challenges the feasibility of the current model editing literature at its very foundation, as shortcuts are inherently at odds with robust knowledge integration. Coincidentally, this issue has long been obscured by evaluation frameworks that lack the design of negative examples. To uncover it, we systematically develop a suite of new evaluation methods. Strikingly, we find that state-of-the-art approaches collapse even under the simplest negation queries. Our empirical evidence shows that editing is likely to be based on shortcuts rather than full semantics, calling for an urgent reconsideration of the very basis of model editing before further advancements can be meaningfully pursued.