 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer
Mar 15, 2026We present OCRA, an Object-Centric framework for video-based human-to-Robot Action transfer that learns directly from human demonstration videos to enable robust manipulation. Object-centric learning emphasizes task-relevant objects and their interactions while filtering out irrelevant background, providing a natural and scalable way to teach robots. OCRA leverages multi-view RGB videos, the state-of-the-art 3D foundation model VGGT, and advanced detection and segmentation models to reconstruct object-centric 3D point clouds, capturing rich interactions between objects. To handle properties not easily perceived by vision alone, we incorporate tactile priors via a large-scale dataset of over one million tactile images. These 3D and tactile priors are fused through a multimodal module (ResFiLM) and fed into a Diffusion Policy to generate robust manipulation actions. Extensive experiments on both vision-only and visuo-tactile tasks show that OCRA significantly outperforms existing baselines and ablations, demonstrating its effectiveness for learning from human demonstration videos.
A multi-branch convolutional neural network for detecting double JPEG compression
Oct 16, 2017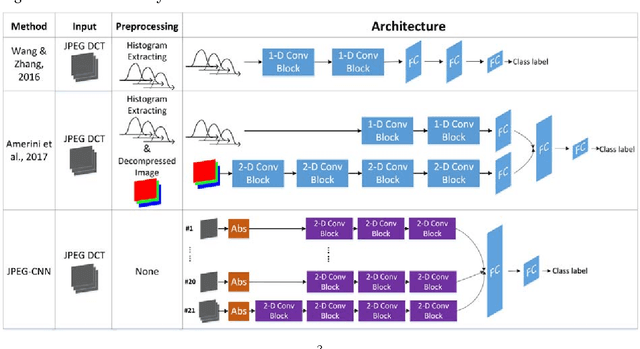
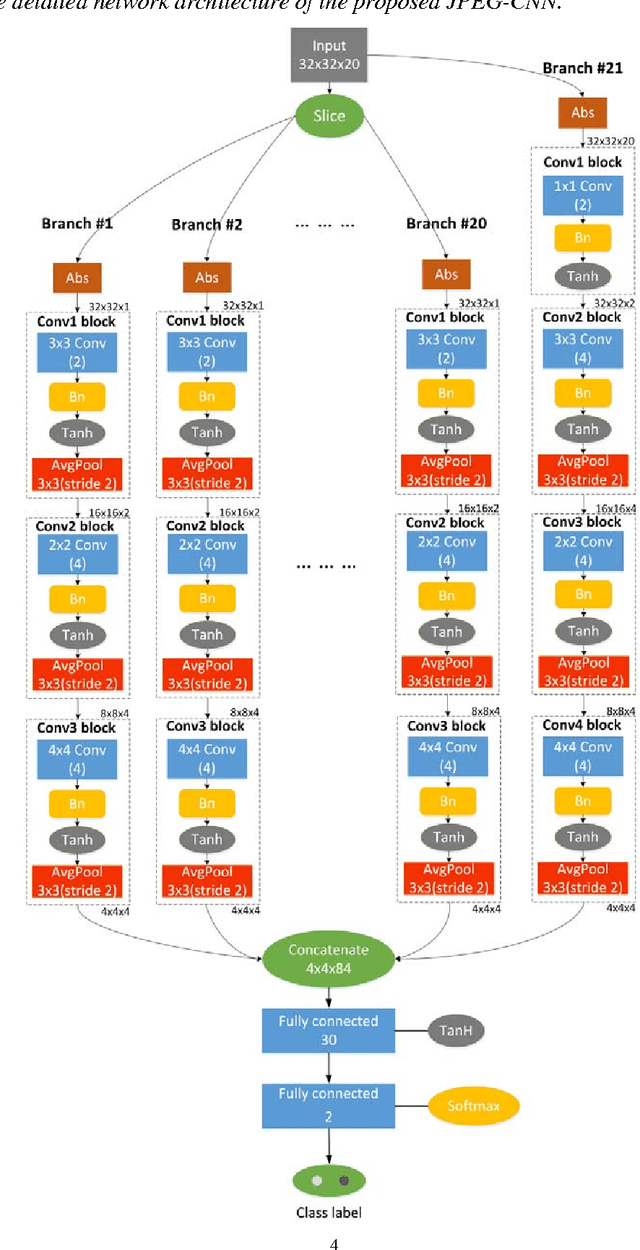
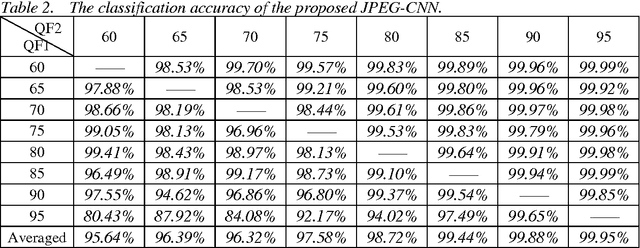
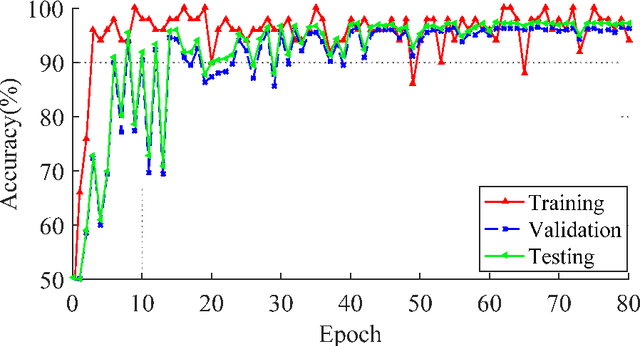
Detection of double JPEG compression is important to forensics analysis. A few methods were proposed based on convolutional neural networks (CNNs). These methods only accept inputs from pre-processed data, such as histogram features and/or decompressed images. In this paper, we present a CNN solution by using raw DCT (discrete cosine transformation) coefficients from JPEG images as input. Considering the DCT sub-band nature in JPEG, a multiple-branch CNN structure has been designed to reveal whether a JPEG format image has been doubly compressed. Comparing with previous methods, the proposed method provides end-to-end detection capability. Extensive experiments have been carried out to demonstrate the effectiveness of the proposed network.