 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Study on Unsupervised Spatiotemporal Representation Learning
Apr 29, 2021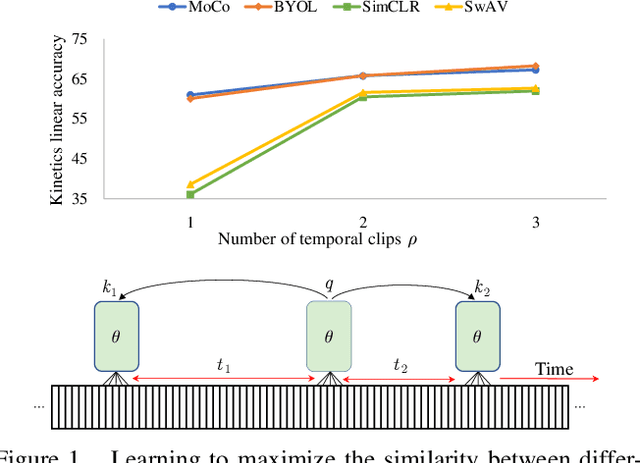

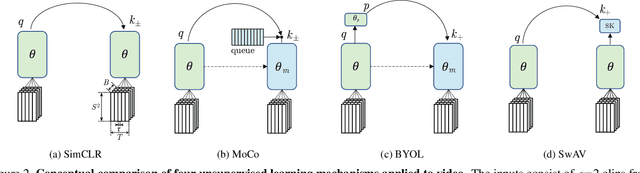
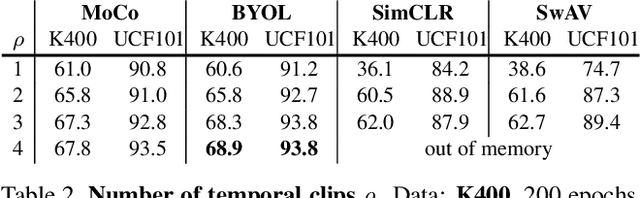
We present a large-scale study on unsupervised spatiotemporal representation learning from videos. With a unified perspective on four recent image-based frameworks, we study a simple objective that can easily generalize all these methods to space-time. Our objective encourages temporally-persistent features in the same video, and in spite of its simplicity, it works surprisingly well across: (i) different unsupervised frameworks, (ii) pre-training datasets, (iii) downstream datasets, and (iv) backbone architectures. We draw a series of intriguing observations from this study, e.g., we discover that encouraging long-spanned persistency can be effective even if the timespan is 60 seconds. In addition to state-of-the-art results in multiple benchmarks, we report a few promising cases in which unsupervised pre-training can outperform its supervised counterpart. Code is made available at https://github.com/facebookresearch/SlowFast
Multiscale Vision Transformers
Apr 22, 2021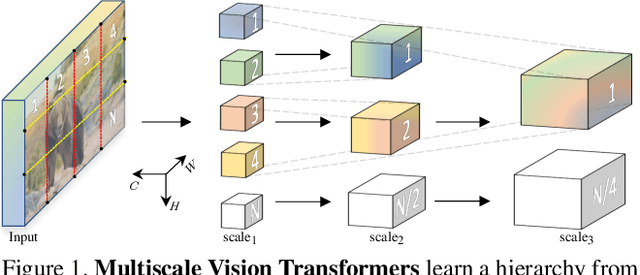

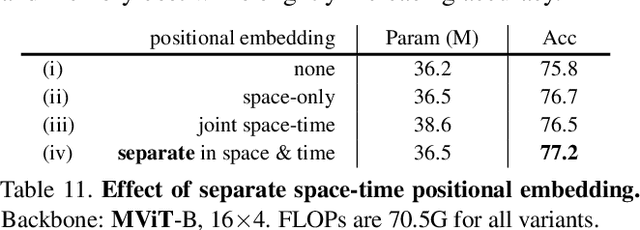
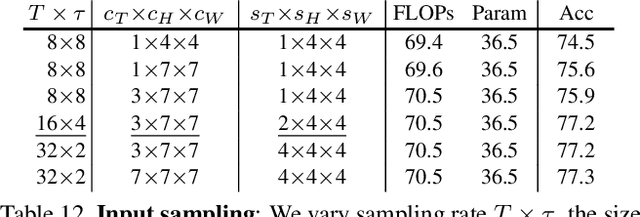
We present Multiscale Vision Transformers (MViT) for video and image recognition, by connecting the seminal idea of multiscale feature hierarchies with transformer models. Multiscale Transformers have several channel-resolution scale stages. Starting from the input resolution and a small channel dimension, the stages hierarchically expand the channel capacity while reducing the spatial resolution. This creates a multiscale pyramid of features with early layers operating at high spatial resolution to model simple low-level visual information, and deeper layers at spatially coarse, but complex, high-dimensional features. We evaluate this fundamental architectural prior for modeling the dense nature of visual signals for a variety of video recognition tasks where it outperforms concurrent vision transformers that rely on large scale external pre-training and are 5-10x more costly in computation and parameters. We further remove the temporal dimension and apply our model for image classification where it outperforms prior work on vision transformers. Code is available at: https://github.com/facebookresearch/SlowFast
Beyond Short Clips: End-to-End Video-Level Learning with Collaborative Memories
Apr 02, 2021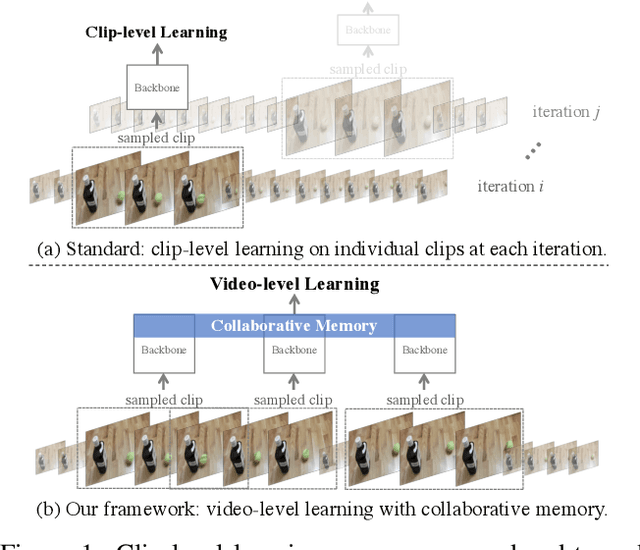
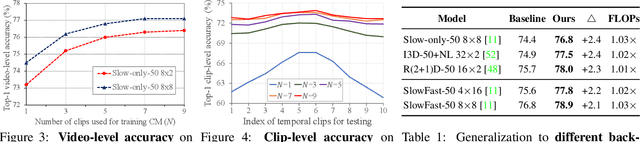
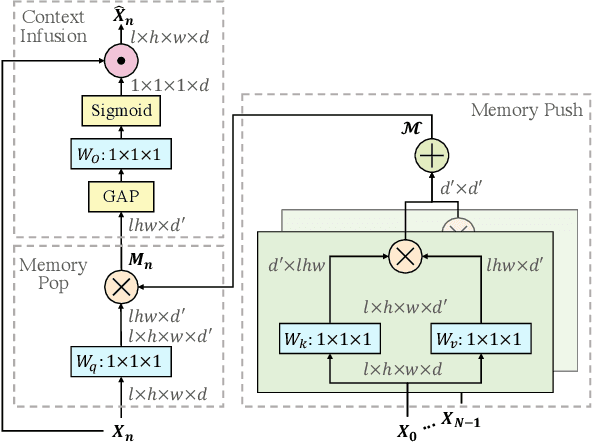
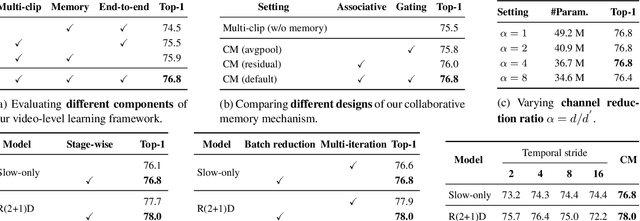
The standard way of training video models entails sampling at each iteration a single clip from a video and optimizing the clip prediction with respect to the video-level label. We argue that a single clip may not have enough temporal coverage to exhibit the label to recognize, since video datasets are often weakly labeled with categorical information but without dense temporal annotations. Furthermore, optimizing the model over brief clips impedes its ability to learn long-term temporal dependencies. To overcome these limitations, we introduce a collaborative memory mechanism that encodes information across multiple sampled clips of a video at each training iteration. This enables the learning of long-range dependencies beyond a single clip. We explore different design choices for the collaborative memory to ease the optimization difficulties. Our proposed framework is end-to-end trainable and significantly improves the accuracy of video classification at a negligible computational overhead. Through extensive experiments, we demonstrate that our framework generalizes to different video architectures and tasks, outperforming the state of the art on both action recognition (e.g., Kinetics-400 & 700, Charades, Something-Something-V1) and action detection (e.g., AVA v2.1 & v2.2).
Multiview Pseudo-Labeling for Semi-supervised Learning from Video
Apr 01, 2021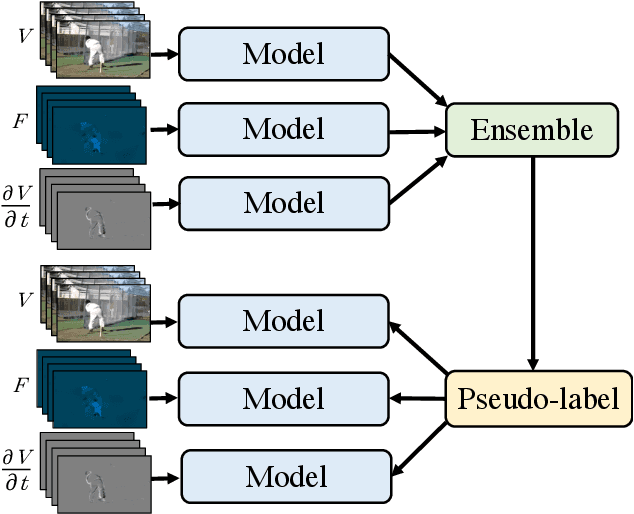
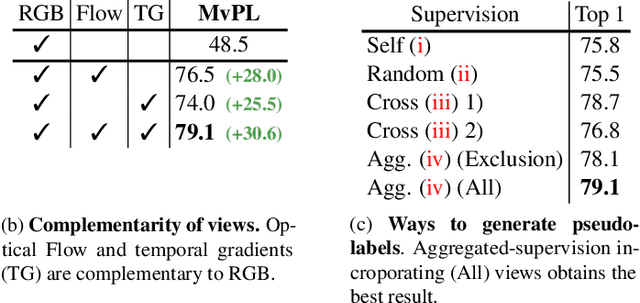
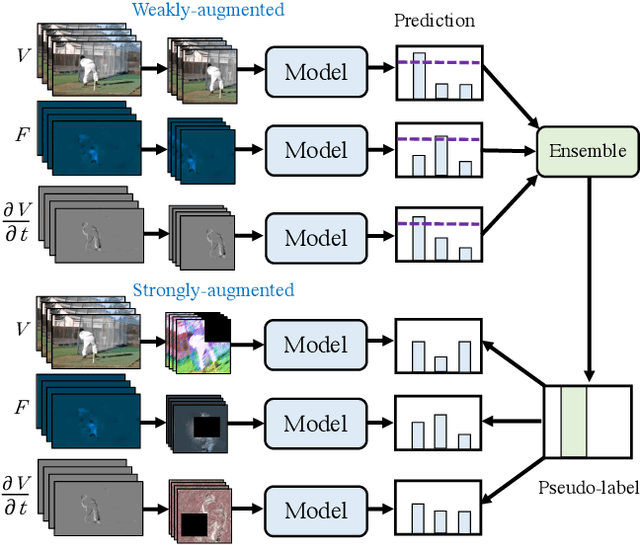

We present a multiview pseudo-labeling approach to video learning, a novel framework that uses complementary views in the form of appearance and motion information for semi-supervised learning in video. The complementary views help obtain more reliable pseudo-labels on unlabeled video, to learn stronger video representations than from purely supervised data. Though our method capitalizes on multiple views, it nonetheless trains a model that is shared across appearance and motion input and thus, by design, incurs no additional computation overhead at inference time. On multiple video recognition datasets, our method substantially outperforms its supervised counterpart, and compares favorably to previous work on standard benchmarks in self-supervised video representation learning.
HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval
Mar 28, 2021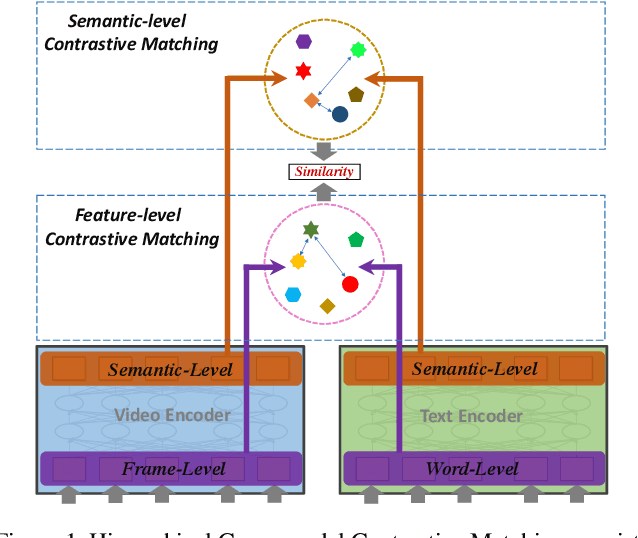
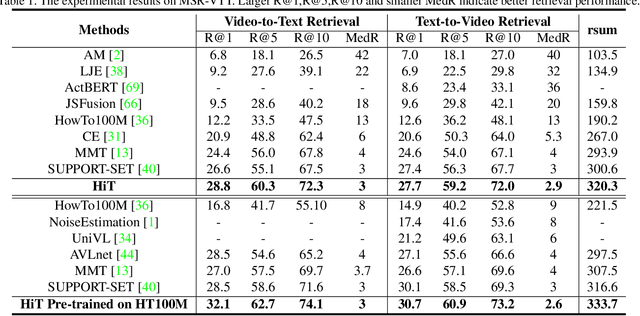
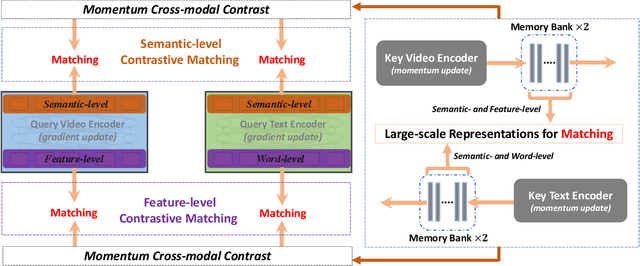
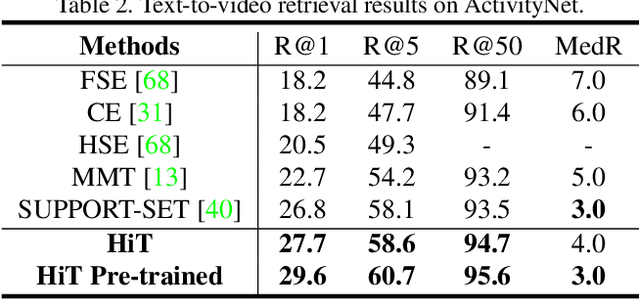
Video-Text Retrieval has been a hot research topic with the explosion of multimedia data on the Internet. Transformer for video-text learning has attracted increasing attention due to the promising performance.However, existing cross-modal transformer approaches typically suffer from two major limitations: 1) Limited exploitation of the transformer architecture where different layers have different feature characteristics. 2) End-to-end training mechanism limits negative interactions among samples in a mini-batch. In this paper, we propose a novel approach named Hierarchical Transformer (HiT) for video-text retrieval. HiT performs hierarchical cross-modal contrastive matching in feature-level and semantic-level to achieve multi-view and comprehensive retrieval results. Moreover, inspired by MoCo, we propose Momentum Cross-modal Contrast for cross-modal learning to enable large-scale negative interactions on-the-fly, which contributes to the generation of more precise and discriminative representations. Experimental results on three major Video-Text Retrieval benchmark datasets demonstrate the advantages of our methods.
Can Temporal Information Help with Contrastive Self-Supervised Learning?
Nov 25, 2020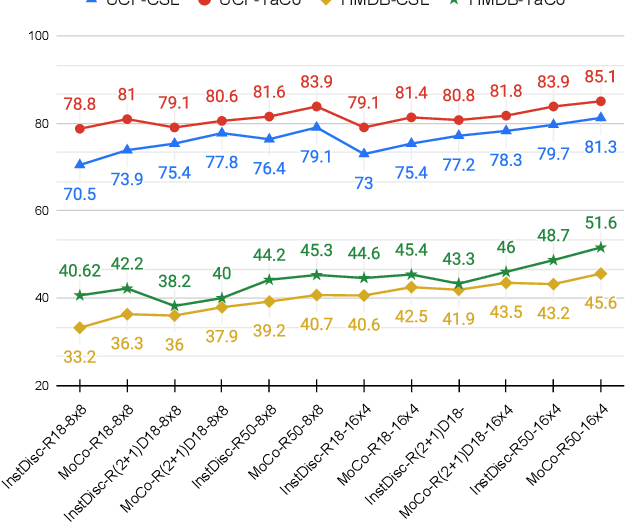
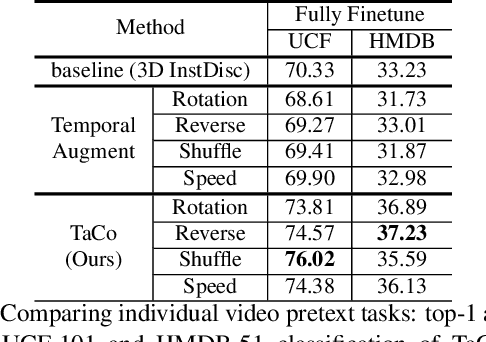
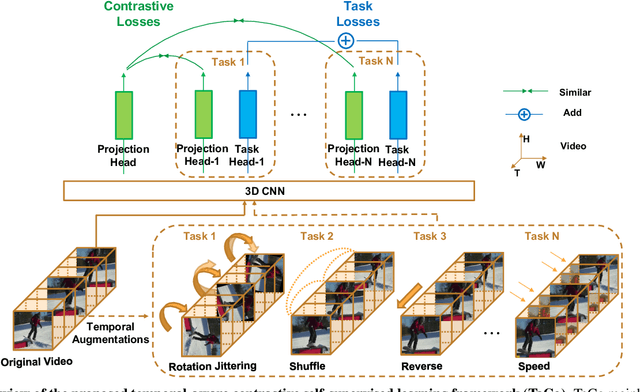
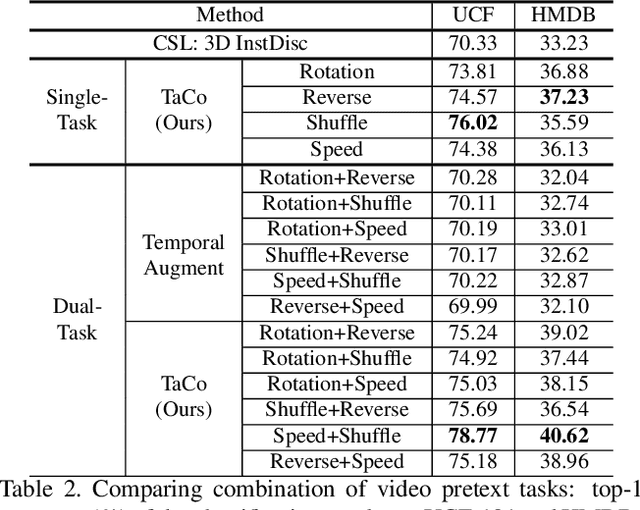
Leveraging temporal information has been regarded as essential for developing video understanding models. However, how to properly incorporate temporal information into the recent successful instance discrimination based contrastive self-supervised learning (CSL) framework remains unclear. As an intuitive solution, we find that directly applying temporal augmentations does not help, or even impair video CSL in general. This counter-intuitive observation motivates us to re-design existing video CSL frameworks, for better integration of temporal knowledge. To this end, we present Temporal-aware Contrastive self-supervised learningTaCo, as a general paradigm to enhance video CSL. Specifically, TaCo selects a set of temporal transformations not only as strong data augmentation but also to constitute extra self-supervision for video understanding. By jointly contrasting instances with enriched temporal transformations and learning these transformations as self-supervised signals, TaCo can significantly enhance unsupervised video representation learning. For instance, TaCo demonstrates consistent improvement in downstream classification tasks over a list of backbones and CSL approaches. Our best model achieves 85.1% (UCF-101) and 51.6% (HMDB-51) top-1 accuracy, which is a 3% and 2.4% relative improvement over the previous state-of-the-art.
Improved Baselines with Momentum Contrastive Learning
Mar 09, 2020
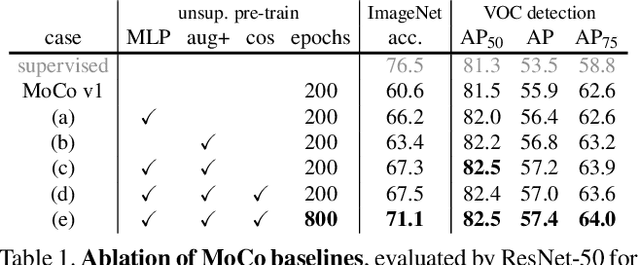
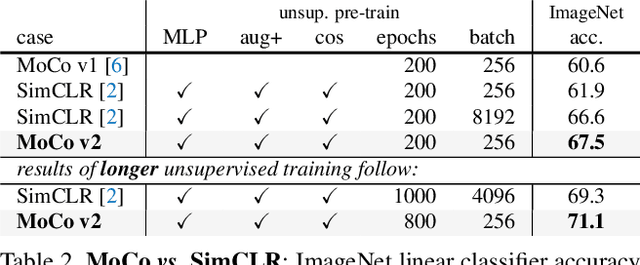

Contrastive unsupervised learning has recently shown encouraging progress, e.g., in Momentum Contrast (MoCo) and SimCLR. In this note, we verify the effectiveness of two of SimCLR's design improvements by implementing them in the MoCo framework. With simple modifications to MoCo---namely, using an MLP projection head and more data augmentation---we establish stronger baselines that outperform SimCLR and do not require large training batches. We hope this will make state-of-the-art unsupervised learning research more accessible. Code will be made public.
Momentum Contrast for Unsupervised Visual Representation Learning
Nov 14, 2019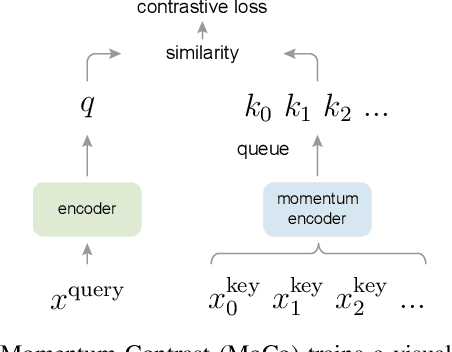
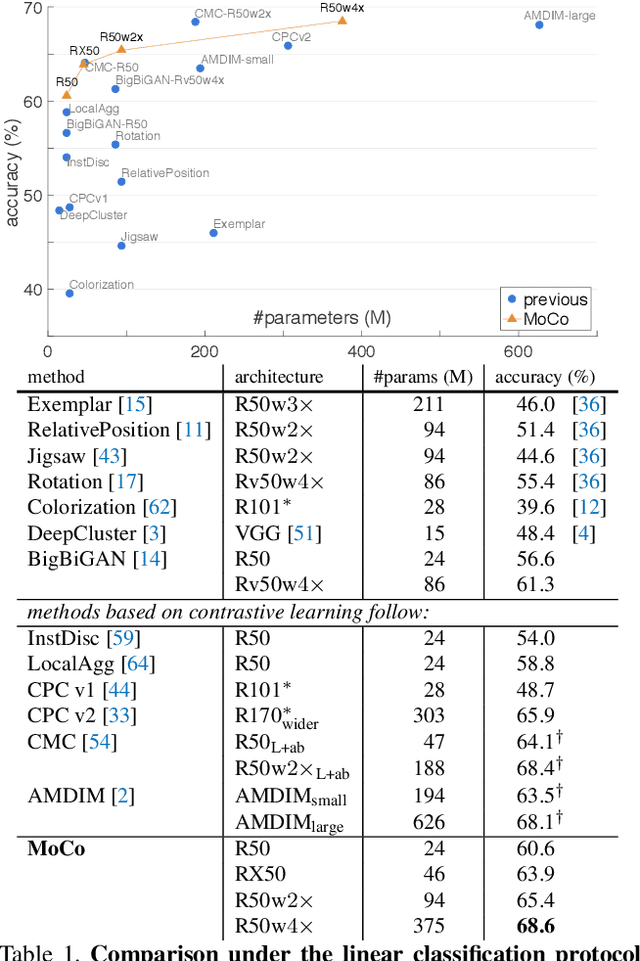
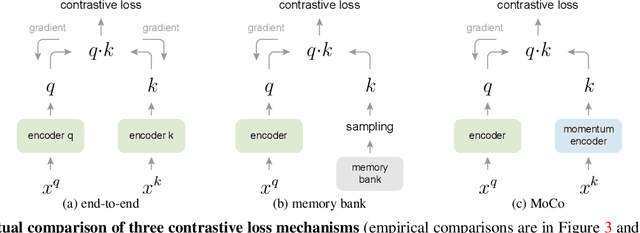
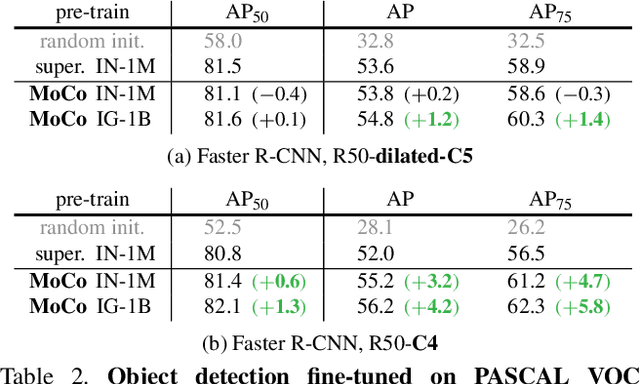
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large and consistent dictionary on-the-fly that facilitates contrastive unsupervised learning. MoCo provides competitive results under the common linear protocol on ImageNet classification. More importantly, the representations learned by MoCo transfer well to downstream tasks. MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Apr 30, 2019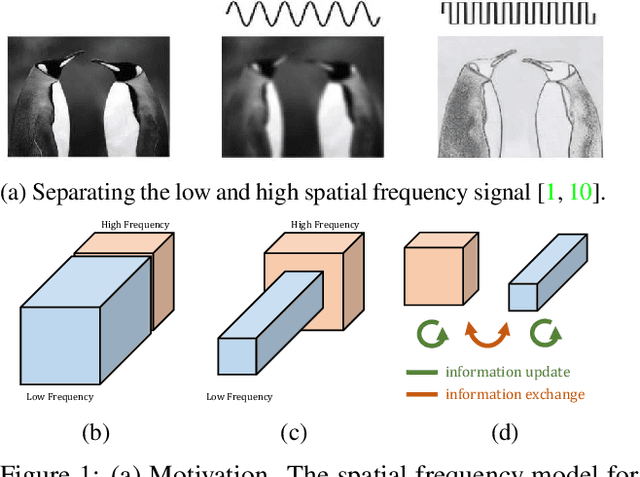

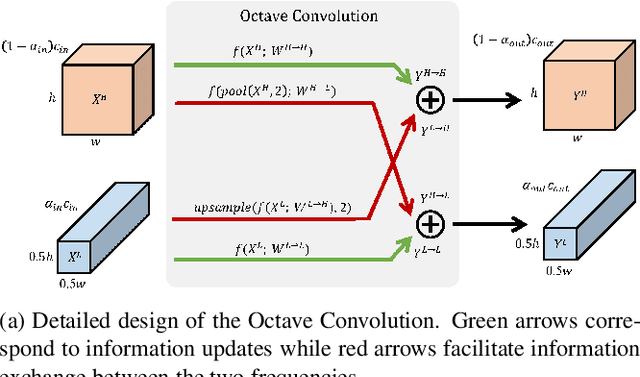
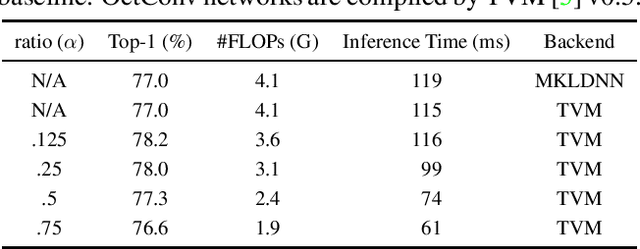
In natural images, information is conveyed at different frequencies where higher frequencies are usually encoded with fine details and lower frequencies are usually encoded with global structures. Similarly, the output feature maps of a convolution layer can also be seen as a mixture of information at different frequencies. In this work, we propose to factorize the mixed feature maps by their frequencies and design a novel Octave Convolution (OctConv) operation to store and process feature maps that vary spatially "slower" at a lower spatial resolution reducing both memory and computation cost. Unlike existing multi-scale meth-ods, OctConv is formulated as a single, generic, plug-and-play convolutional unit that can be used as a direct replacement of (vanilla) convolutions without any adjustments in the network architecture. It is also orthogonal and complementary to methods that suggest better topologies or reduce channel-wise redundancy like group or depth-wise convolutions. We experimentally show that by simply replacing con-volutions with OctConv, we can consistently boost accuracy for both image and video recognition tasks, while reducing memory and computational cost. An OctConv-equipped ResNet-152 can achieve 82.9% top-1 classification accuracy on ImageNet with merely 22.2 GFLOPs.
Long-Term Feature Banks for Detailed Video Understanding
Dec 12, 2018
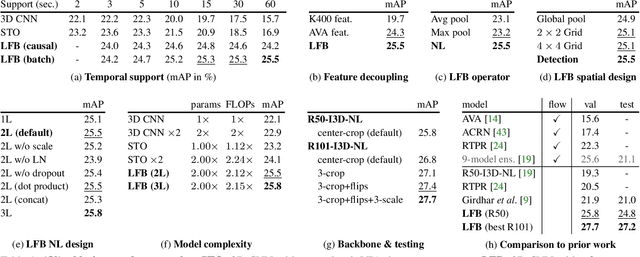

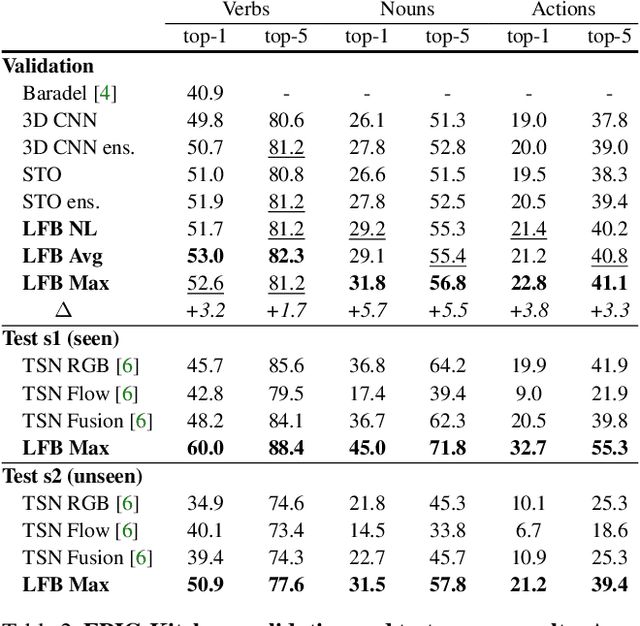
To understand the world, we humans constantly need to relate the present to the past, and put events in context. In this paper, we enable existing video models to do the same. We propose a long-term feature bank---supportive information extracted over the entire span of a video---to augment state-of-the-art video models that otherwise would only view short clips of 2-5 seconds. Our experiments demonstrate that augmenting 3D convolutional networks with a long-term feature bank yields state-of-the-art results on three challenging video datasets: AVA, EPIC-Kitchens, and Charades.