 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automatic Evaluation of Dialog Systems: A Model-Free Off-Policy Evaluation Approach
Feb 28, 2021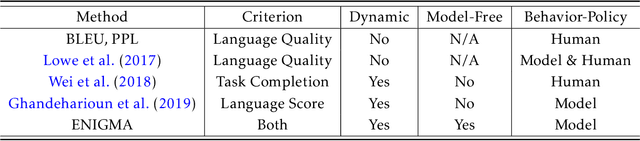
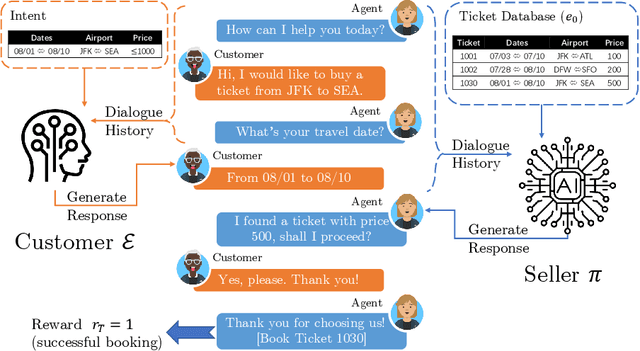
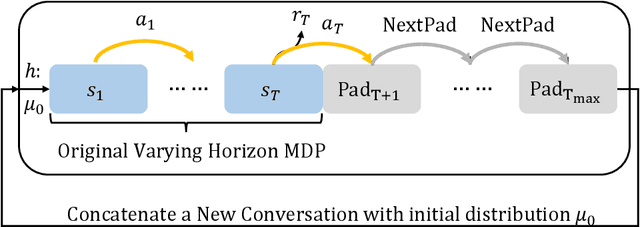
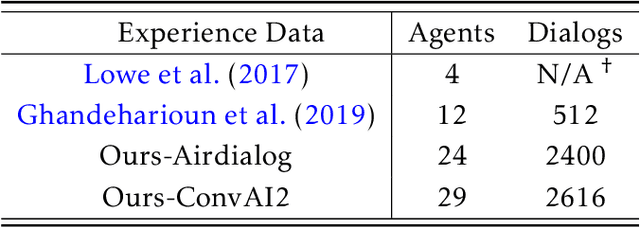
Reliable automatic evaluation of dialogue systems under an interactive environment has long been overdue. An ideal environment for evaluating dialog systems, also known as the Turing test, needs to involve human interaction, which is usually not affordable for large-scale experiments. Though researchers have attempted to use metrics (e.g., perplexity, BLEU) in language generation tasks or some model-based reinforcement learning methods (e.g., self-play evaluation) for automatic evaluation, these methods only show a very weak correlation with the actual human evaluation in practice. To bridge such a gap, we propose a new framework named ENIGMA for estimating human evaluation scores based on recent advances of off-policy evaluation in reinforcement learning. ENIGMA only requires a handful of pre-collected experience data, and therefore does not involve human interaction with the target policy during the evaluation, making automatic evaluations feasible. More importantly, ENIGMA is model-free and agnostic to the behavior policies for collecting the experience data (see details in Section 2), which significantly alleviates the technical difficulties of modeling complex dialogue environments and human behaviors. Our experiments show that ENIGMA significantly outperforms existing methods in terms of correlation with human evaluation scores.
Calibrated Language Model Fine-Tuning for In- and Out-of-Distribution Data
Oct 22, 2020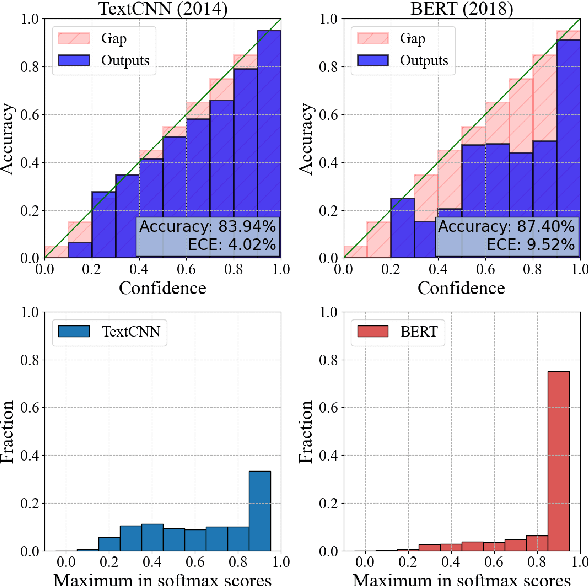
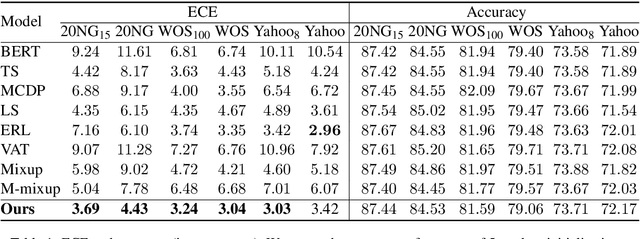
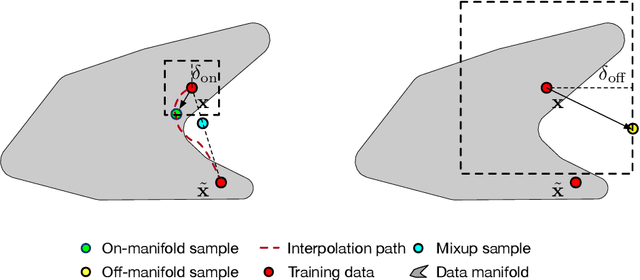
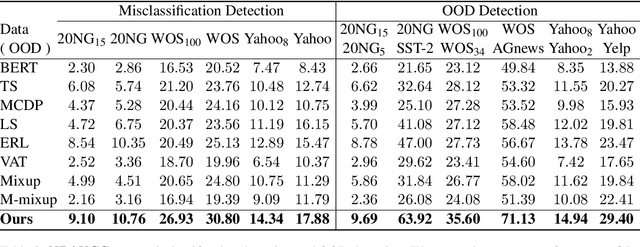
Fine-tuned pre-trained language models can suffer from severe miscalibration for both in-distribution and out-of-distribution (OOD) data due to over-parameterization. To mitigate this issue, we propose a regularized fine-tuning method. Our method introduces two types of regularization for better calibration: (1) On-manifold regularization, which generates pseudo on-manifold samples through interpolation within the data manifold. Augmented training with these pseudo samples imposes a smoothness regularization to improve in-distribution calibration. (2) Off-manifold regularization, which encourages the model to output uniform distributions for pseudo off-manifold samples to address the over-confidence issue for OOD data. Our experiments demonstrate that the proposed method outperforms existing calibration methods for text classification in terms of expectation calibration error, misclassification detection, and OOD detection on six datasets. Our code can be found at https://github.com/Lingkai-Kong/Calibrated-BERT-Fine-Tuning.
Fine-Tuning Pre-trained Language Model with Weak Supervision: A Contrastive-Regularized Self-Training Approach
Oct 20, 2020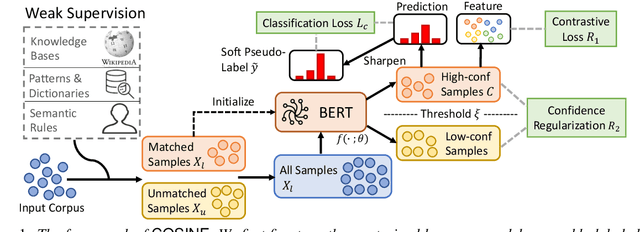
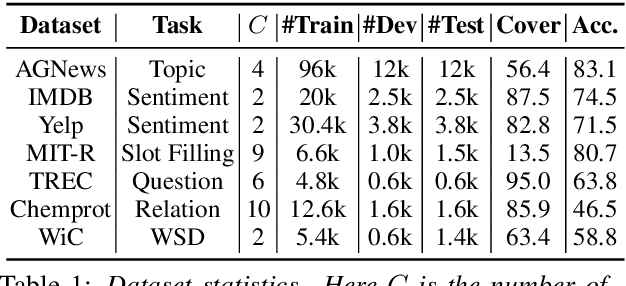
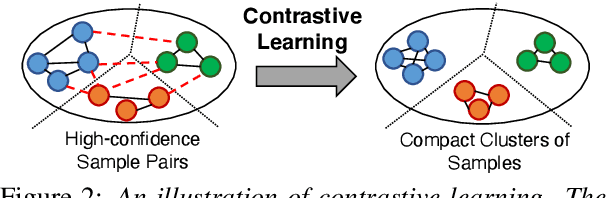
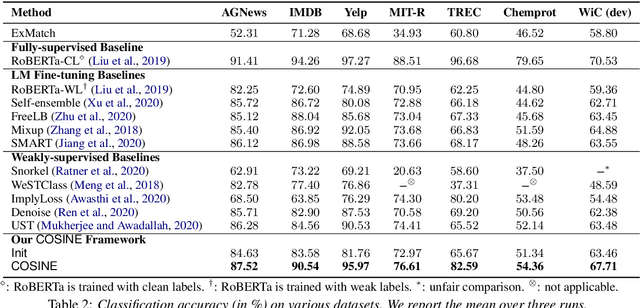
Fine-tuned pre-trained language models (LMs) achieve enormous success in many natural language processing (NLP) tasks, but they still require excessive labeled data in the fine-tuning stage. We study the problem of fine-tuning pre-trained LMs using only weak supervision, without any labeled data. This problem is challenging because the high capacity of LMs makes them prone to overfitting the noisy labels generated by weak supervision. To address this problem, we develop a contrastive self-training framework, COSINE, to enable fine-tuning LMs with weak supervision. Underpinned by contrastive regularization and confidence-based reweighting, this contrastive self-training framework can gradually improve model fitting while effectively suppressing error propagation. Experiments on sequence, token, and sentence pair classification tasks show that our model outperforms the strongest baseline by large margins on 7 benchmarks in 6 tasks, and achieves competitive performance with fully-supervised fine-tuning methods.
BOND: BERT-Assisted Open-Domain Named Entity Recognition with Distant Supervision
Jun 28, 2020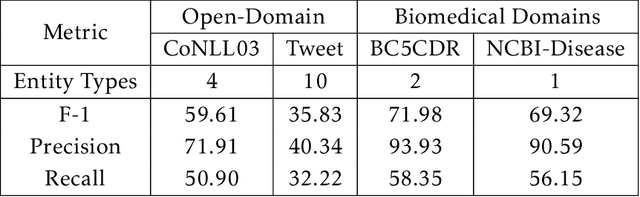
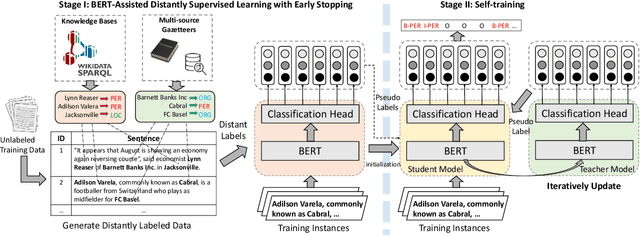
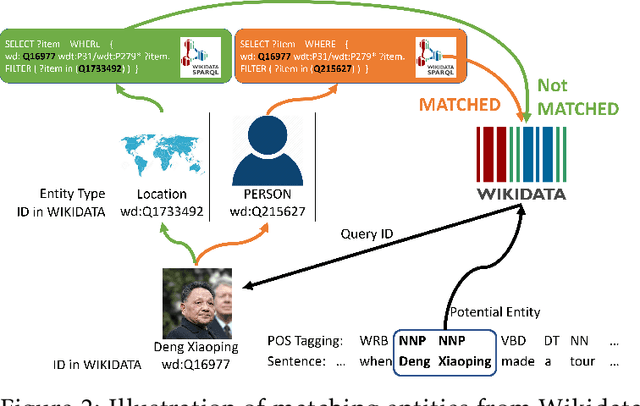
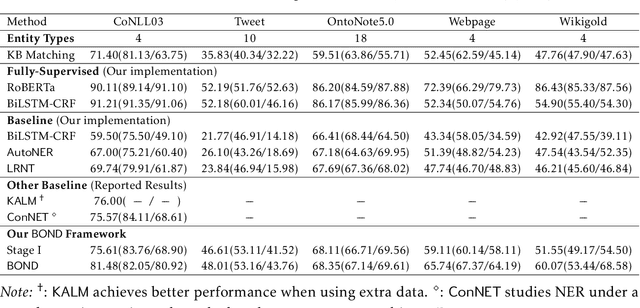
We study the open-domain named entity recognition (NER) problem under distant supervision. The distant supervision, though does not require large amounts of manual annotations, yields highly incomplete and noisy distant labels via external knowledge bases. To address this challenge, we propose a new computational framework -- BOND, which leverages the power of pre-trained language models (e.g., BERT and RoBERTa) to improve the prediction performance of NER models. Specifically, we propose a two-stage training algorithm: In the first stage, we adapt the pre-trained language model to the NER tasks using the distant labels, which can significantly improve the recall and precision; In the second stage, we drop the distant labels, and propose a self-training approach to further improve the model performance. Thorough experiments on 5 benchmark datasets demonstrate the superiority of BOND over existing distantly supervised NER methods. The code and distantly labeled data have been released in https://github.com/cliang1453/BOND.
Picasso: A Sparse Learning Library for High Dimensional Data Analysis in R and Python
Jun 27, 2020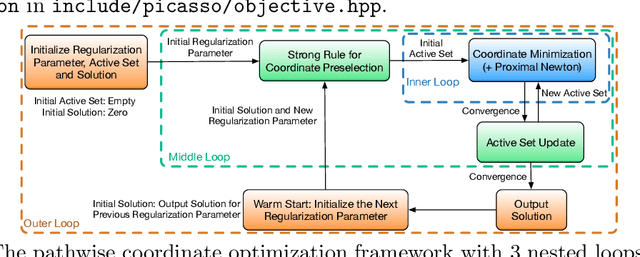
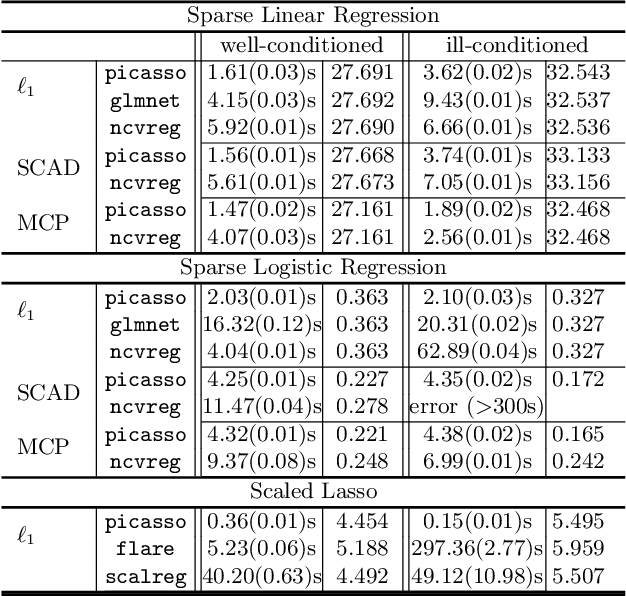
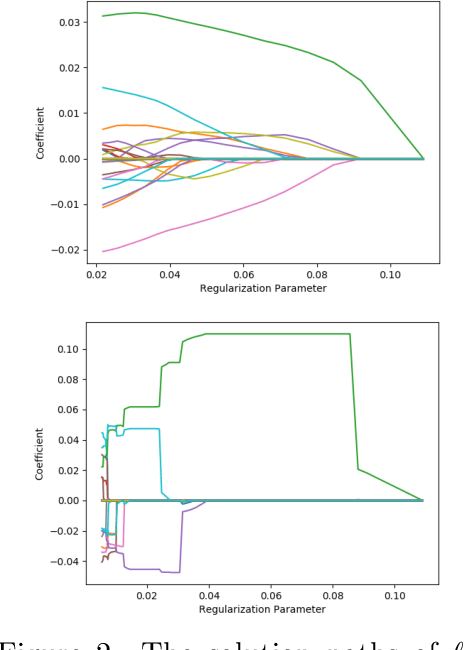
We describe a new library named picasso, which implements a unified framework of pathwise coordinate optimization for a variety of sparse learning problems (e.g., sparse linear regression, sparse logistic regression, sparse Poisson regression and scaled sparse linear regression) combined with efficient active set selection strategies. Besides, the library allows users to choose different sparsity-inducing regularizers, including the convex $\ell_1$, nonconvex MCP and SCAD regularizers. The library is coded in C++ and has user-friendly R and Python wrappers. Numerical experiments demonstrate that picasso can scale up to large problems efficiently.
Deep Reinforcement Learning with Smooth Policy
Mar 24, 2020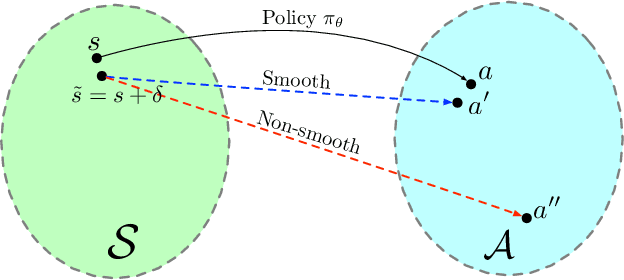

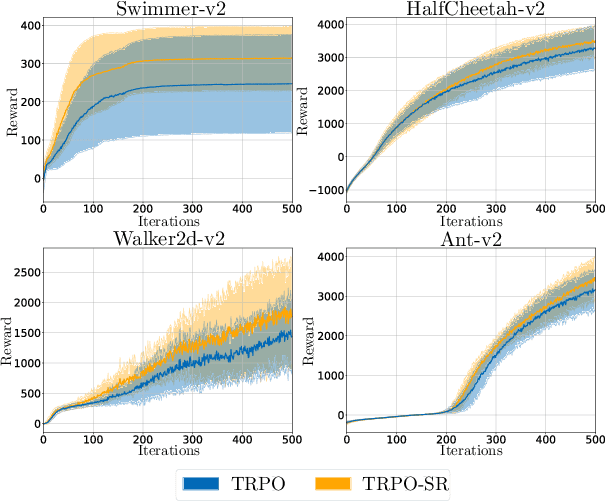
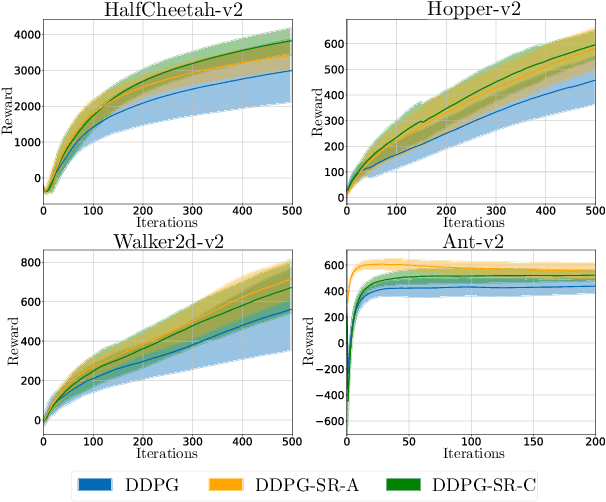
Deep neural networks have been widely adopted in modern reinforcement learning (RL) algorithms with great empirical successes in various domains. However, the large search space of training a neural network requires a significant amount of data, which makes the current RL algorithms not sample efficient. Motivated by the fact that many environments with continuous state space have smooth transitions, we propose to learn a smooth policy that behaves smoothly with respect to states. In contrast to policies parameterized by linear/reproducing kernel functions, where simple regularization techniques suffice to control smoothness, for neural network based reinforcement learning algorithms, there is no readily available solution to learn a smooth policy. In this paper, we develop a new training framework --- $\textbf{S}$mooth $\textbf{R}$egularized $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SR}^2\textbf{L}$), where the policy is trained with smoothness-inducing regularization. Such regularization effectively constrains the search space of the learning algorithms and enforces smoothness in the learned policy. We apply the proposed framework to both on-policy (TRPO) and off-policy algorithm (DDPG). Through extensive experiments, we demonstrate that our method achieves improved sample efficiency.
Transformer Hawkes Process
Feb 21, 2020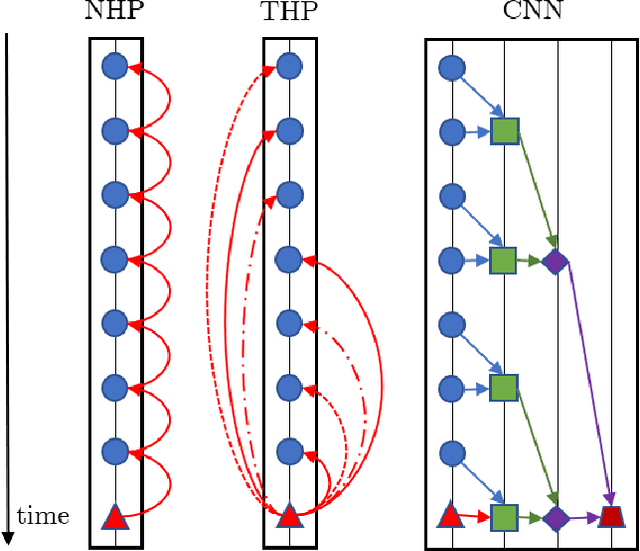
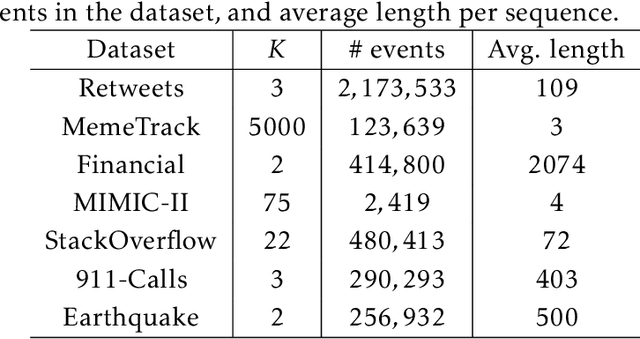
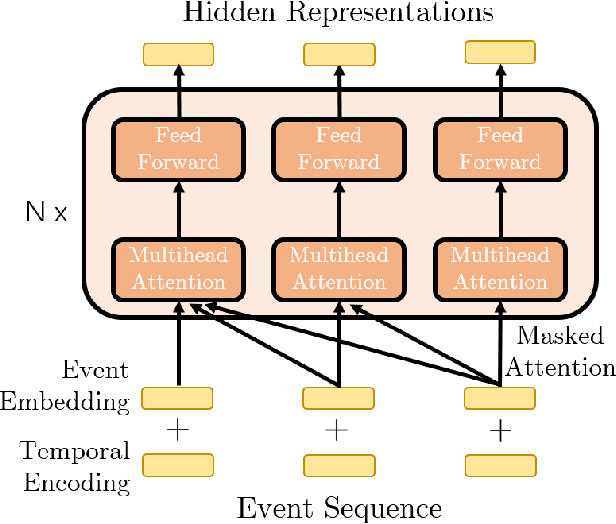
Modern data acquisition routinely produce massive amounts of event sequence data in various domains, such as social media, healthcare, and financial markets. These data often exhibit complicated short-term and long-term temporal dependencies. However, most of the existing recurrent neural network-based point process models fail to capture such dependencies, and yield unreliable prediction performance. To address this issue, we propose a Transformer Hawkes Process (THP) model, which leverages the self-attention mechanism to capture long-term dependencies and meanwhile enjoys computational efficiency. Numerical experiments on various datasets show that THP outperforms existing models in terms of both likelihood and event prediction accuracy by a notable margin. Moreover, THP is quite general and can incorporate additional structural knowledge. We provide a concrete example, where THP achieves improved prediction performance for learning multiple point processes when incorporating their relational information.
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization
Nov 08, 2019
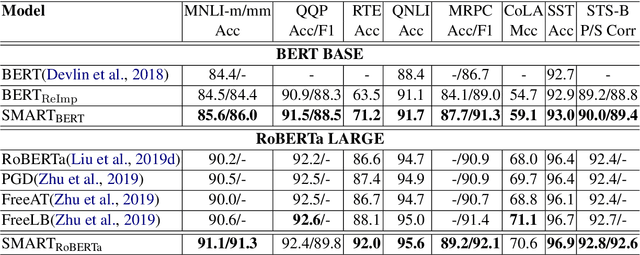
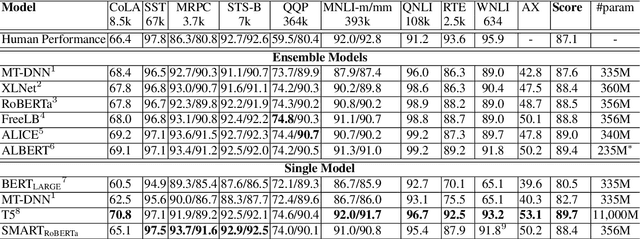
Transfer learning has fundamentally changed the landscape of natural language processing (NLP) research. Many existing state-of-the-art models are first pre-trained on a large text corpus and then fine-tuned on downstream tasks. However, due to limited data resources from downstream tasks and the extremely large capacity of pre-trained models, aggressive fine-tuning often causes the adapted model to overfit the data of downstream tasks and forget the knowledge of the pre-trained model. To address the above issue in a more principled manner, we propose a new computational framework for robust and efficient fine-tuning for pre-trained language models. Specifically, our proposed framework contains two important ingredients: 1. Smoothness-inducing regularization, which effectively manages the capacity of the model; 2. Bregman proximal point optimization, which is a class of trust-region methods and can prevent knowledge forgetting. Our experiments demonstrate that our proposed method achieves the state-of-the-art performance on multiple NLP benchmarks.
Multi-Domain Neural Machine Translation with Word-Level Adaptive Layer-wise Domain Mixing
Nov 07, 2019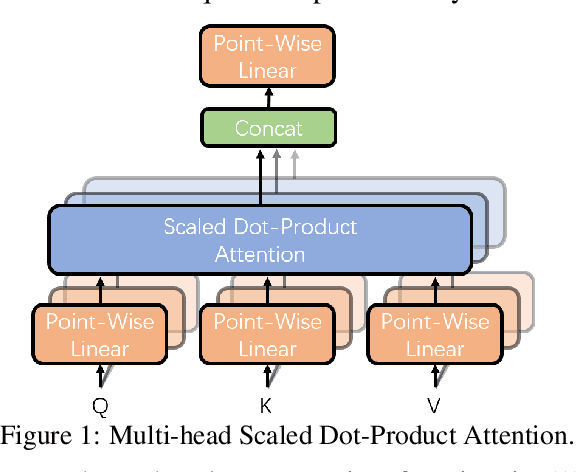
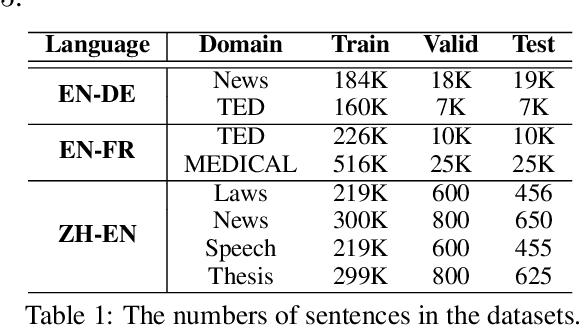
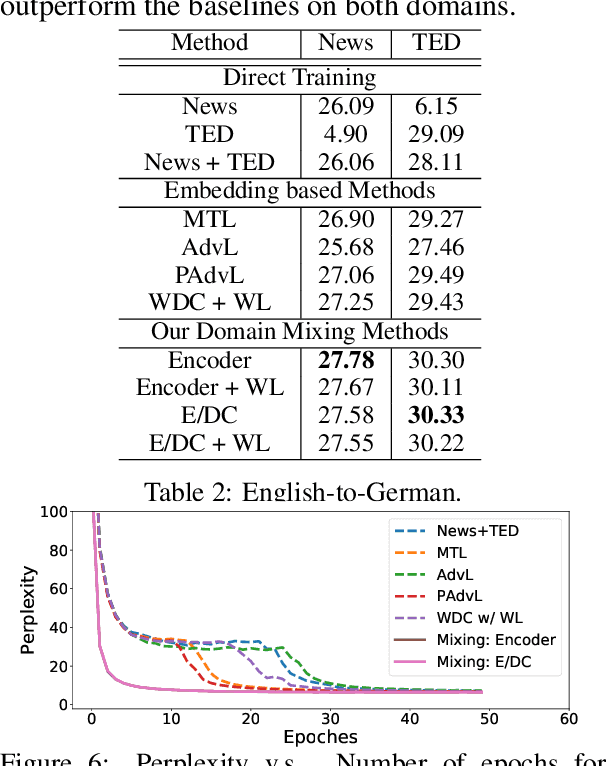
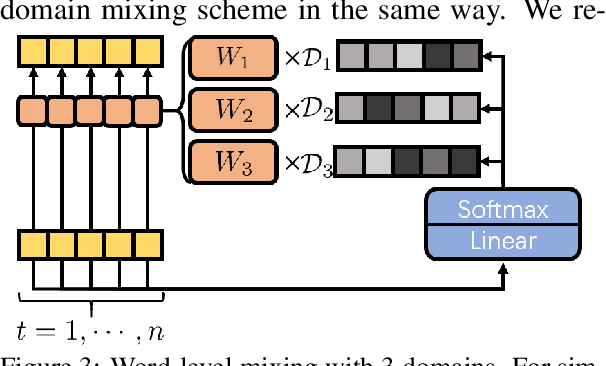
Many multi-domain neural machine translation (NMT) models achieve knowledge transfer by enforcing one encoder to learn shared embedding across domains. However, this design lacks adaptation to individual domains. To overcome this limitation, we propose a novel multi-domain NMT model using individual modules for each domain, on which we apply word-level, adaptive and layer-wise domain mixing. We first observe that words in a sentence are often related to multiple domains. Hence, we assume each word has a domain proportion, which indicates its domain preference. Then word representations are obtained by mixing their embedding in individual domains based on their domain proportions. We show this can be achieved by carefully designing multi-head dot-product attention modules for different domains, and eventually taking weighted averages of their parameters by word-level layer-wise domain proportions. Through this, we can achieve effective domain knowledge sharing, and capture fine-grained domain-specific knowledge as well. Our experiments show that our proposed model outperforms existing ones in several NMT tasks.
Contextual Text Denoising with Masked Language Models
Oct 30, 2019
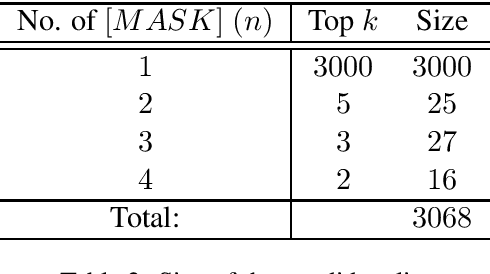
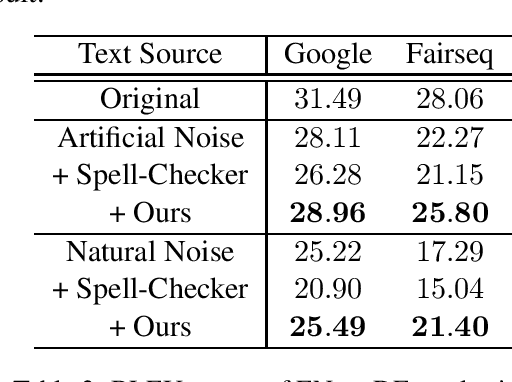
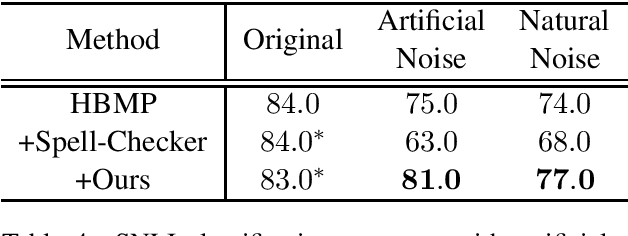
Recently, with the help of deep learning models, significant advances have been made in different Natural Language Processing (NLP) tasks. Unfortunately, state-of-the-art models are vulnerable to noisy texts. We propose a new contextual text denoising algorithm based on the ready-to-use masked language model. The proposed algorithm does not require retraining of the model and can be integrated into any NLP system without additional training on paired cleaning training data. We evaluate our method under synthetic noise and natural noise and show that the proposed algorithm can use context information to correct noise text and improve the performance of noisy inputs in several downstream tasks.