 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-FLAN: A Preliminary Release
Feb 23, 2025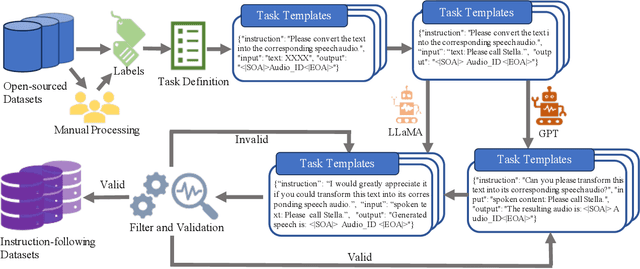

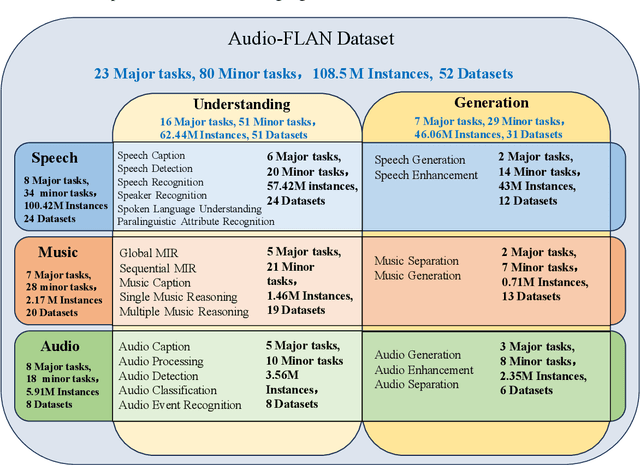

Recent advancements in audio tokenization have significantly enhanced the integration of audio capabilities into large language models (LLMs). However, audio understanding and generation are often treated as distinct tasks, hindering the development of truly unified audio-language models. While instruction tuning has demonstrated remarkable success in improving generalization and zero-shot learning across text and vision, its application to audio remains largely unexplored. A major obstacle is the lack of comprehensive datasets that unify audio understanding and generation. To address this, we introduce Audio-FLAN, a large-scale instruction-tuning dataset covering 80 diverse tasks across speech, music, and sound domains, with over 100 million instances. Audio-FLAN lays the foundation for unified audio-language models that can seamlessly handle both understanding (e.g., transcription, comprehension) and generation (e.g., speech, music, sound) tasks across a wide range of audio domains in a zero-shot manner. The Audio-FLAN dataset is available on HuggingFace and GitHub and will be continuously updated.
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.
AudioSetCaps: An Enriched Audio-Caption Dataset using Automated Generation Pipeline with Large Audio and Language Models
Nov 28, 2024



With the emergence of audio-language models, constructing large-scale paired audio-language datasets has become essential yet challenging for model development, primarily due to the time-intensive and labour-heavy demands involved. While large language models (LLMs) have improved the efficiency of synthetic audio caption generation, current approaches struggle to effectively extract and incorporate detailed audio information. In this paper, we propose an automated pipeline that integrates audio-language models for fine-grained content extraction, LLMs for synthetic caption generation, and a contrastive language-audio pretraining (CLAP) model-based refinement process to improve the quality of captions. Specifically, we employ prompt chaining techniques in the content extraction stage to obtain accurate and fine-grained audio information, while we use the refinement process to mitigate potential hallucinations in the generated captions. Leveraging the AudioSet dataset and the proposed approach, we create AudioSetCaps, a dataset comprising 1.9 million audio-caption pairs, the largest audio-caption dataset at the time of writing. The models trained with AudioSetCaps achieve state-of-the-art performance on audio-text retrieval with R@1 scores of 46.3% for text-to-audio and 59.7% for audio-to-text retrieval and automated audio captioning with the CIDEr score of 84.8. As our approach has shown promising results with AudioSetCaps, we create another dataset containing 4.1 million synthetic audio-language pairs based on the Youtube-8M and VGGSound datasets. To facilitate research in audio-language learning, we have made our pipeline, datasets with 6 million audio-language pairs, and pre-trained models publicly available at https://github.com/JishengBai/AudioSetCaps.
FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
Sep 11, 2024



Language-queried audio source separation (LASS) focuses on separating sounds using textual descriptions of the desired sources. Current methods mainly use discriminative approaches, such as time-frequency masking, to separate target sounds and minimize interference from other sources. However, these models face challenges when separating overlapping soundtracks, which may lead to artifacts such as spectral holes or incomplete separation. Rectified flow matching (RFM), a generative model that establishes linear relations between the distribution of data and noise, offers superior theoretical properties and simplicity, but has not yet been explored in sound separation. In this work, we introduce FlowSep, a new generative model based on RFM for LASS tasks. FlowSep learns linear flow trajectories from noise to target source features within the variational autoencoder (VAE) latent space. During inference, the RFM-generated latent features are reconstructed into a mel-spectrogram via the pre-trained VAE decoder, followed by a pre-trained vocoder to synthesize the waveform. Trained on 1,680 hours of audio data, FlowSep outperforms the state-of-the-art models across multiple benchmarks, as evaluated with subjective and objective metrics. Additionally, our results show that FlowSep surpasses a diffusion-based LASS model in both separation quality and inference efficiency, highlighting its strong potential for audio source separation tasks. Code, pre-trained models and demos can be found at: https://audio-agi.github.io/FlowSep_demo/.
Efficient Audio Captioning with Encoder-Level Knowledge Distillation
Jul 19, 2024



Significant improvement has been achieved in automated audio captioning (AAC) with recent models. However, these models have become increasingly large as their performance is enhanced. In this work, we propose a knowledge distillation (KD) framework for AAC. Our analysis shows that in the encoder-decoder based AAC models, it is more effective to distill knowledge into the encoder as compared with the decoder. To this end, we incorporate encoder-level KD loss into training, in addition to the standard supervised loss and sequence-level KD loss. We investigate two encoder-level KD methods, based on mean squared error (MSE) loss and contrastive loss, respectively. Experimental results demonstrate that contrastive KD is more robust than MSE KD, exhibiting superior performance in data-scarce situations. By leveraging audio-only data into training in the KD framework, our student model achieves competitive performance, with an inference speed that is 19 times faster\footnote{An online demo is available at \url{https://huggingface.co/spaces/wsntxxn/efficient_audio_captioning}}.
Text-Queried Target Sound Event Localization
Jun 23, 2024



Sound event localization and detection (SELD) aims to determine the appearance of sound classes, together with their Direction of Arrival (DOA). However, current SELD systems can only predict the activities of specific classes, for example, 13 classes in DCASE challenges. In this paper, we propose text-queried target sound event localization (SEL), a new paradigm that allows the user to input the text to describe the sound event, and the SEL model can predict the location of the related sound event. The proposed task presents a more user-friendly way for human-computer interaction. We provide a benchmark study for the proposed task and perform experiments on datasets created by simulated room impulse response (RIR) and real RIR to validate the effectiveness of the proposed methods. We hope that our benchmark will inspire the interest and additional research for text-queried sound source localization.
Fish Tracking, Counting, and Behaviour Analysis in Digital Aquaculture: A Comprehensive Review
Jun 20, 2024Digital aquaculture leverages advanced technologies and data-driven methods, providing substantial benefits over traditional aquaculture practices. Fish tracking, counting, and behaviour analysis are crucial components of digital aquaculture, which are essential for optimizing production efficiency, enhancing fish welfare, and improving resource management. Previous reviews have focused on single modalities, limiting their ability to address the diverse challenges encountered in these tasks comprehensively. This review provides a comprehensive analysis of the current state of aquaculture digital technologies, including vision-based, acoustic-based, and biosensor-based methods. We examine the advantages, limitations, and applications of these methods, highlighting recent advancements and identifying critical research gaps. The scarcity of comprehensive fish datasets and the lack of unified evaluation standards, which make it difficult to compare the performance of different technologies, are identified as major obstacles hindering progress in this field. To overcome current limitations and improve the accuracy, robustness, and efficiency of fish monitoring systems, we explore the potential of emerging technologies such as multimodal data fusion and deep learning. Additionally, we contribute to the field by providing a summary of existing datasets available for fish tracking, counting, and behaviour analysis. Future research directions are outlined, emphasizing the need for comprehensive datasets and evaluation standards to facilitate meaningful comparisons between technologies and promote their practical implementation in real-world aquaculture settings.
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Jun 10, 2024



In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
SemantiCodec: An Ultra Low Bitrate Semantic Audio Codec for General Sound
Apr 30, 2024Large language models (LLMs) have significantly advanced audio processing through audio codecs that convert audio into discrete tokens, enabling the application of language modelling techniques to audio data. However, traditional codecs often operate at high bitrates or within narrow domains such as speech and lack the semantic clues required for efficient language modelling. Addressing these challenges, we introduce SemantiCodec, a novel codec designed to compress audio into fewer than a hundred tokens per second across diverse audio types, including speech, general audio, and music, without compromising quality. SemantiCodec features a dual-encoder architecture: a semantic encoder using a self-supervised AudioMAE, discretized using k-means clustering on extensive audio data, and an acoustic encoder to capture the remaining details. The semantic and acoustic encoder outputs are used to reconstruct audio via a diffusion-model-based decoder. SemantiCodec is presented in three variants with token rates of 25, 50, and 100 per second, supporting a range of ultra-low bit rates between 0.31 kbps and 1.43 kbps. Experimental results demonstrate that SemantiCodec significantly outperforms the state-of-the-art Descript codec on reconstruction quality. Our results also suggest that SemantiCodec contains significantly richer semantic information than all evaluated audio codecs, even at significantly lower bitrates. Our code and demos are available at https://haoheliu.github.io/SemantiCodec/.
T-CLAP: Temporal-Enhanced Contrastive Language-Audio Pretraining
Apr 27, 2024



Contrastive language-audio pretraining~(CLAP) has been developed to align the representations of audio and language, achieving remarkable performance in retrieval and classification tasks. However, current CLAP struggles to capture temporal information within audio and text features, presenting substantial limitations for tasks such as audio retrieval and generation. To address this gap, we introduce T-CLAP, a temporal-enhanced CLAP model. We use Large Language Models~(LLMs) and mixed-up strategies to generate temporal-contrastive captions for audio clips from extensive audio-text datasets. Subsequently, a new temporal-focused contrastive loss is designed to fine-tune the CLAP model by incorporating these synthetic data. We conduct comprehensive experiments and analysis in multiple downstream tasks. T-CLAP shows improved capability in capturing the temporal relationship of sound events and outperforms state-of-the-art models by a significant margin.