 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning Empowered Graph Neural Networks for Radio Resource Management
Aug 29, 2024



In this paper, we consider a radio resource management (RRM) problem in the dynamic wireless networks, comprising multiple communication links that share the same spectrum resource. To achieve high network throughput while ensuring fairness across all links, we formulate a resilient power optimization problem with per-user minimum-rate constraints. We obtain the corresponding Lagrangian dual problem and parameterize all variables with neural networks, which can be trained in an unsupervised manner due to the provably acceptable duality gap. We develop a meta-learning approach with graph neural networks (GNNs) as parameterization that exhibits fast adaptation and scalability to varying network configurations. We formulate the objective of meta-learning by amalgamating the Lagrangian functions of different network configurations and utilize a first-order meta-learning algorithm, called Reptile, to obtain the meta-parameters. Numerical results verify that our method can efficiently improve the overall throughput and ensure the minimum rate performance. We further demonstrate that using the meta-parameters as initialization, our method can achieve fast adaptation to new wireless network configurations and reduce the number of required training data samples.
Integrated Dynamic Phenological Feature for Remote Sensing Image Land Cover Change Detection
Aug 08, 2024



Remote sensing image change detection (CD) is essential for analyzing land surface changes over time, with a significant challenge being the differentiation of actual changes from complex scenes while filtering out pseudo-changes. A primary contributor to this challenge is the intra-class dynamic changes due to phenological characteristics in natural areas. To overcome this, we introduce the InPhea model, which integrates phenological features into a remote sensing image CD framework. The model features a detector with a differential attention module for improved feature representation of change information, coupled with high-resolution feature extraction and spatial pyramid blocks to enhance performance. Additionally, a constrainer with four constraint modules and a multi-stage contrastive learning approach is employed to aid in the model's understanding of phenological characteristics. Experiments on the HRSCD, SECD, and PSCD-Wuhan datasets reveal that InPhea outperforms other models, confirming its effectiveness in addressing phenological pseudo-changes and its overall model superiority.
On Purely Data-Driven Massive MIMO Detectors
Jan 15, 2024To enhance the performance of massive multi-input multi-output (MIMO) detection using deep learning, prior research primarily adopts a model-driven methodology, integrating deep neural networks (DNNs) with traditional iterative detectors. Despite these efforts, achieving a purely data-driven detector has remained elusive, primarily due to the inherent complexities arising from the problem's high dimensionality. This paper introduces ChannelNet, a simple yet effective purely data-driven massive MIMO detector. ChannelNet embeds the channel matrix into the network as linear layers rather than viewing it as input, enabling scalability to massive MIMO scenarios. ChannelNet is computationally efficient and has a computational complexity of $\mathcal{O}(N_t N_r)$, where $N_t$ and $N_r$ represent the numbers of transmit and receive antennas, respectively. Despite the low computation complexity, ChannelNet demonstrates robust empirical performance, matching or surpassing state-of-the-art detectors in various scenarios. In addition, theoretical insights establish ChannelNet as a universal approximator in probability for any continuous permutation-equivariant functions. ChannelNet demonstrates that designing deep learning based massive MIMO detectors can be purely data-driven and free from the constraints posed by the conventional iterative frameworks as well as the channel and noise distribution models.
Semantic Communication for Cooperative Perception based on Importance Map
Nov 11, 2023Cooperative perception, which has a broader perception field than single-vehicle perception, has played an increasingly important role in autonomous driving to conduct 3D object detection. Through vehicle-to-vehicle (V2V) communication technology, various connected automated vehicles (CAVs) can share their sensory information (LiDAR point clouds) for cooperative perception. We employ an importance map to extract significant semantic information and propose a novel cooperative perception semantic communication scheme with intermediate fusion. Meanwhile, our proposed architecture can be extended to the challenging time-varying multipath fading channel. To alleviate the distortion caused by the time-varying multipath fading, we adopt explicit orthogonal frequency-division multiplexing (OFDM) blocks combined with channel estimation and channel equalization. Simulation results demonstrate that our proposed model outperforms the traditional separate source-channel coding over various channel models. Moreover, a robustness study indicates that only part of semantic information is key to cooperative perception. Although our proposed model has only been trained over one specific channel, it has the ability to learn robust coded representations of semantic information that remain resilient to various channel models, demonstrating its generality and robustness.
Aperture Diffraction for Compact Snapshot Spectral Imaging
Sep 27, 2023



We demonstrate a compact, cost-effective snapshot spectral imaging system named Aperture Diffraction Imaging Spectrometer (ADIS), which consists only of an imaging lens with an ultra-thin orthogonal aperture mask and a mosaic filter sensor, requiring no additional physical footprint compared to common RGB cameras. Then we introduce a new optical design that each point in the object space is multiplexed to discrete encoding locations on the mosaic filter sensor by diffraction-based spatial-spectral projection engineering generated from the orthogonal mask. The orthogonal projection is uniformly accepted to obtain a weakly calibration-dependent data form to enhance modulation robustness. Meanwhile, the Cascade Shift-Shuffle Spectral Transformer (CSST) with strong perception of the diffraction degeneration is designed to solve a sparsity-constrained inverse problem, realizing the volume reconstruction from 2D measurements with Large amount of aliasing. Our system is evaluated by elaborating the imaging optical theory and reconstruction algorithm with demonstrating the experimental imaging under a single exposure. Ultimately, we achieve the sub-super-pixel spatial resolution and high spectral resolution imaging. The code will be available at: https://github.com/Krito-ex/CSST.
Metric Distribution to Vector: Constructing Data Representation via Broad-Scale Discrepancies
Oct 02, 2022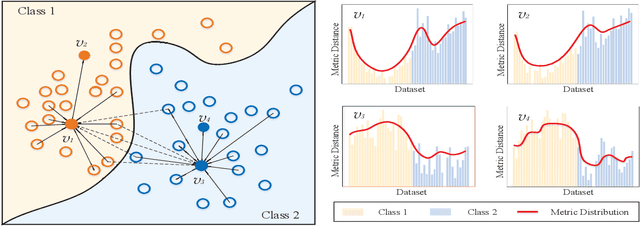
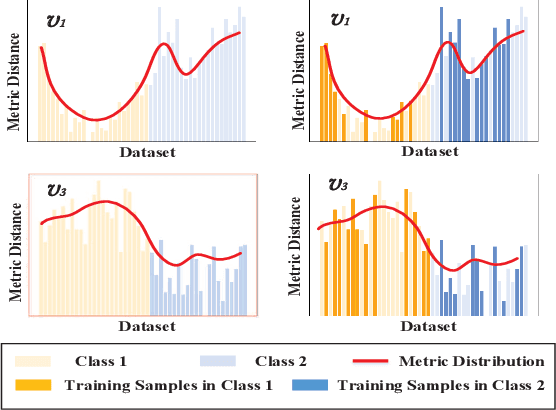

Graph embedding provides a feasible methodology to conduct pattern classification for graph-structured data by mapping each data into the vectorial space. Various pioneering works are essentially coding method that concentrates on a vectorial representation about the inner properties of a graph in terms of the topological constitution, node attributions, link relations, etc. However, the classification for each targeted data is a qualitative issue based on understanding the overall discrepancies within the dataset scale. From the statistical point of view, these discrepancies manifest a metric distribution over the dataset scale if the distance metric is adopted to measure the pairwise similarity or dissimilarity. Therefore, we present a novel embedding strategy named $\mathbf{MetricDistribution2vec}$ to extract such distribution characteristics into the vectorial representation for each data. We demonstrate the application and effectiveness of our representation method in the supervised prediction tasks on extensive real-world structural graph datasets. The results have gained some unexpected increases compared with a surge of baselines on all the datasets, even if we take the lightweight models as classifiers. Moreover, the proposed methods also conducted experiments in Few-Shot classification scenarios, and the results still show attractive discrimination in rare training samples based inference.
Cascaded Detail-Preserving Networks for Super-Resolution of Document Images
Nov 25, 2019
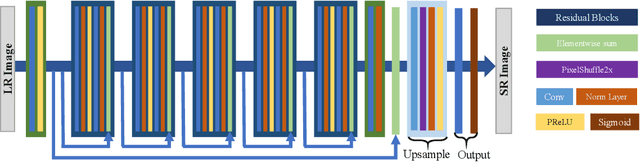
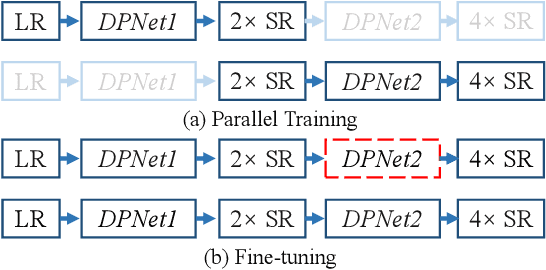

The accuracy of OCR is usually affected by the quality of the input document image and different kinds of marred document images hamper the OCR results. Among these scenarios, the low-resolution image is a common and challenging case. In this paper, we propose the cascaded networks for document image super-resolution. Our model is composed by the Detail-Preserving Networks with small magnification. The loss function with perceptual terms is designed to simultaneously preserve the original patterns and enhance the edge of the characters. These networks are trained with the same architecture and different parameters and then assembled into a pipeline model with a larger magnification. The low-resolution images can upscale gradually by passing through each Detail-Preserving Network until the final high-resolution images. Through extensive experiments on two scanning document image datasets, we demonstrate that the proposed approach outperforms recent state-of-the-art image super-resolution methods, and combining it with standard OCR system lead to signification improvements on the recognition results.
Scene Text Recognition with Temporal Convolutional Encoder
Nov 04, 2019

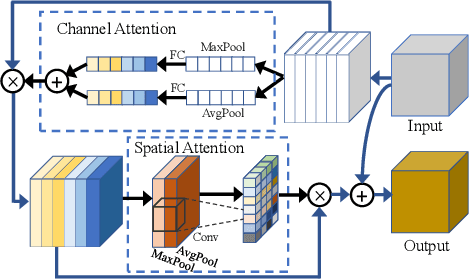
Texts from scene images typically consist of several characters and exhibit a characteristic sequence structure. Existing methods capture the structure with the sequence-to-sequence models by an encoder to have the visual representations and then a decoder to translate the features into the label sequence. In this paper, we study text recognition framework by considering the long-term temporal dependencies in the encoder stage. We demonstrate that the proposed Temporal Convolutional Encoder with increased sequential extents improves the accuracy of text recognition. We also study the impact of different attention modules in convolutional blocks for learning accurate text representations. We conduct comparisons on seven datasets and the experiments demonstrate the effectiveness of our proposed approach.
Learn to Compress CSI and Allocate Resources in Vehicular Networks
Aug 12, 2019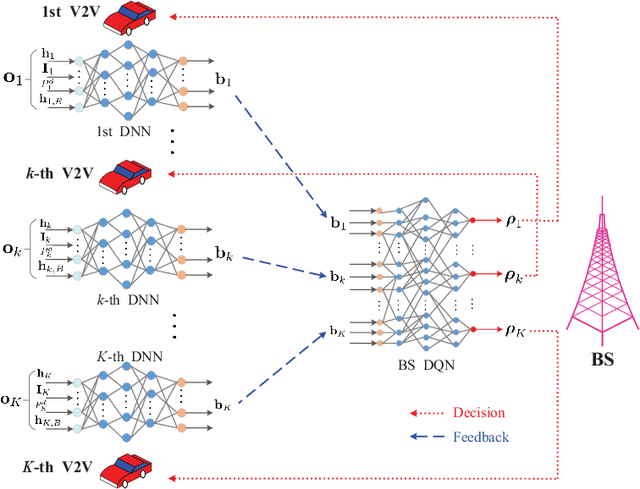
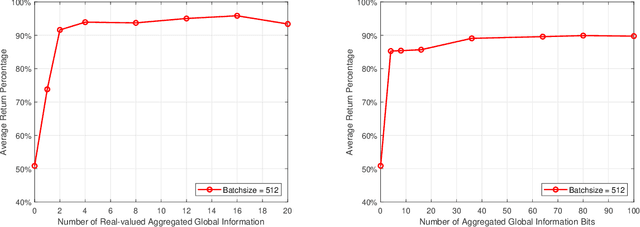
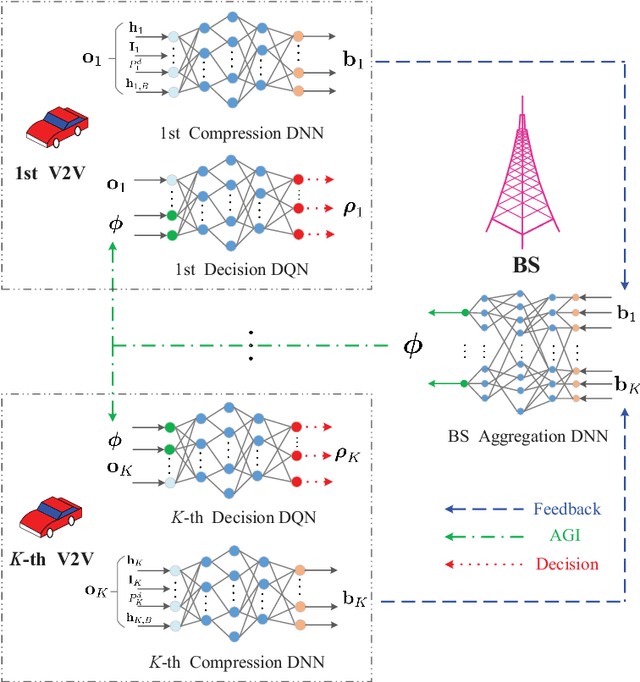
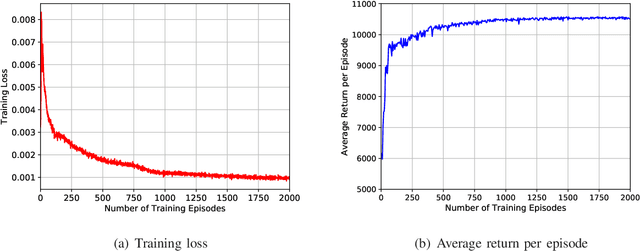
Resource allocation has a direct and profound impact on the performance of vehicle-to-everything (V2X) networks. In this paper, we develop a hybrid architecture consisting of centralized decision making and distributed resource sharing (the C-Decision scheme) to maximize the long-term sum rate of all vehicles. To reduce the network signaling overhead, each vehicle uses a deep neural network to compress its observed information that is thereafter fed back to the centralized decision making unit. The centralized decision unit employs a deep Q-network to allocate resources and then sends the decision results to all vehicles. We further adopt a quantization layer for each vehicle that learns to quantize the continuous feedback. In addition, we devise a mechanism to balance the transmission of vehicle-to-vehicle (V2V) links and vehicle-to-infrastructure (V2I) links. To further facilitate distributed spectrum sharing, we also propose a distributed decision making and spectrum sharing architecture (the D-Decision scheme) for each V2V link. Through extensive simulation results, we demonstrate that the proposed C-Decision and D-Decision schemes can both achieve near-optimal performance and are robust to feedback interval variations, input noise, and feedback noise.
Learn to Allocate Resources in Vehicular Networks
Jul 30, 2019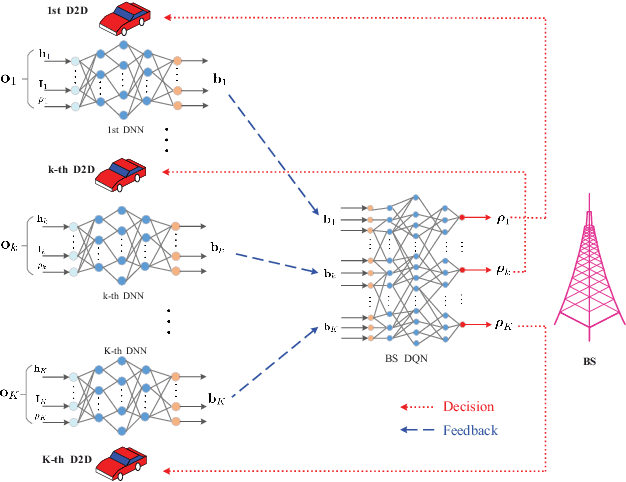
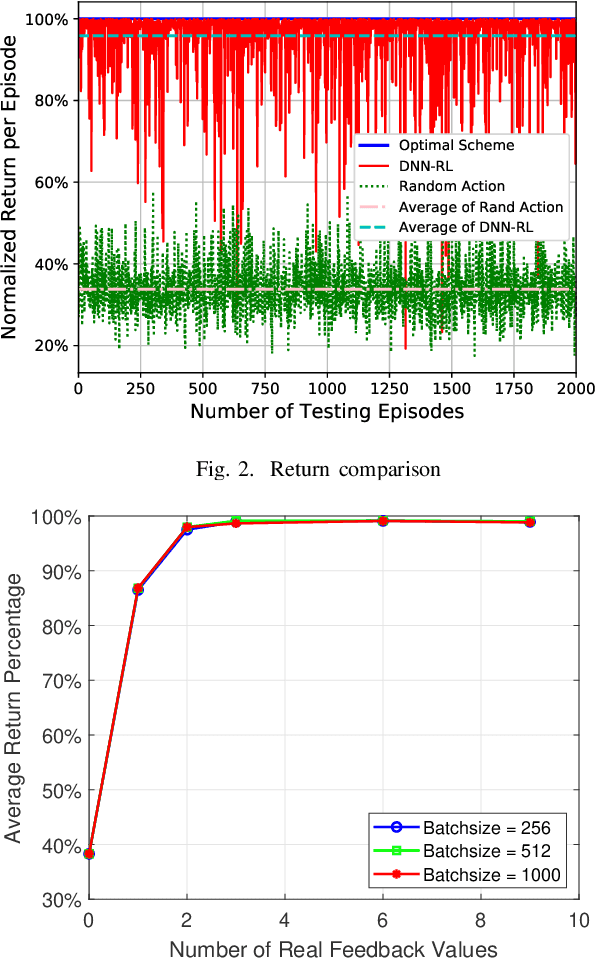
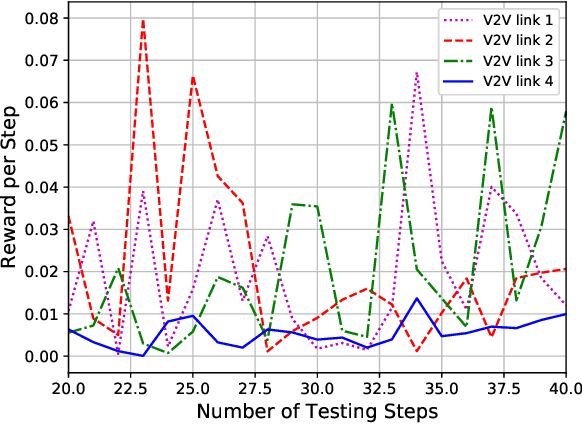
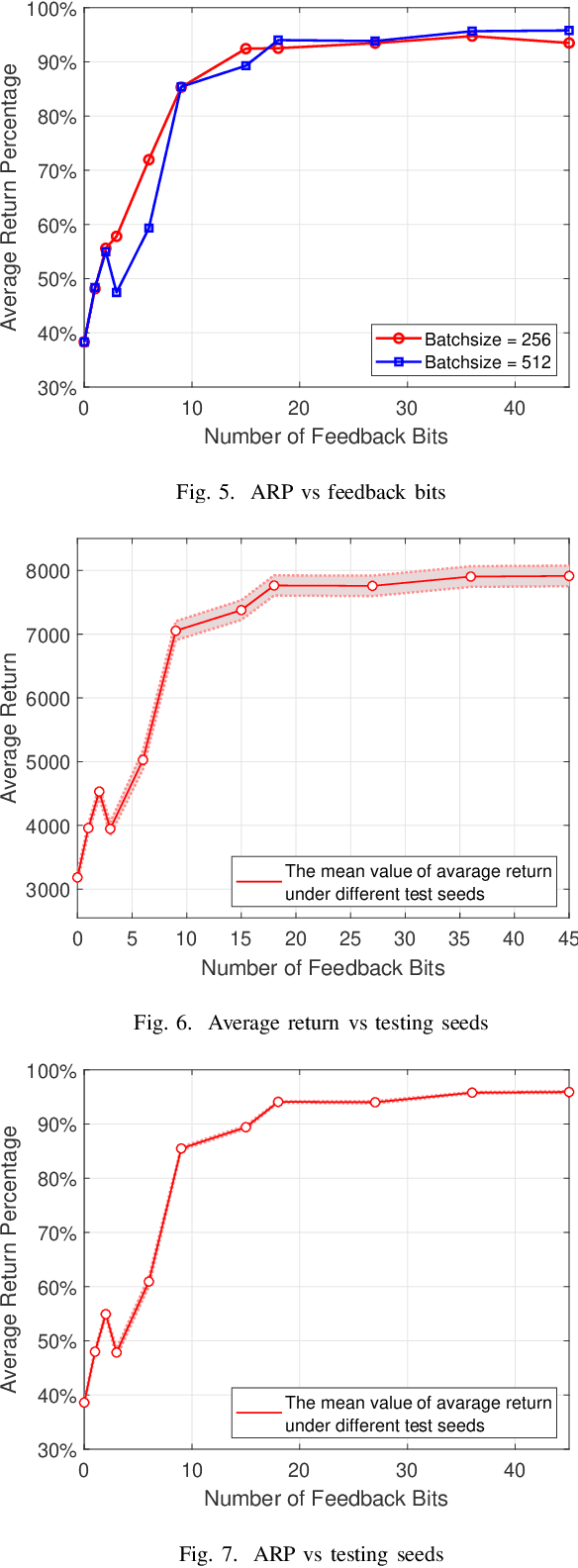
Resource allocation has a direct and profound impact on the performance of vehicle-to-everything (V2X) networks. Considering the dynamic nature of vehicular environments, it is appealing to devise a decentralized strategy to perform effective resource sharing. In this paper, we exploit deep learning to promote coordination among multiple vehicles and propose a hybrid architecture consisting of centralized decision making and distributed resource sharing to maximize the long-term sum rate of all vehicles. To reduce the network signaling overhead, each vehicle uses a deep neural network to compress its own observed information that is thereafter fed back to the centralized decision-making unit, which employs a deep Q-network to allocate resources and then sends the decision results to all vehicles. We further adopt a quantization layer for each vehicle that learns to quantize the continuous feedback. Extensive simulation results demonstrate that the proposed hybrid architecture can achieve near-optimal performance. Meanwhile, there exists an optimal number of continuous feedback and binary feedback, respectively. Besides, this architecture is robust to different feedback intervals, input noise, and feedback noise.