 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGFort: Dual-Path Defense Against Proprietary Knowledge Base Extraction in Retrieval-Augmented Generation
Nov 13, 2025



Retrieval-Augmented Generation (RAG) systems deployed over proprietary knowledge bases face growing threats from reconstruction attacks that aggregate model responses to replicate knowledge bases. Such attacks exploit both intra-class and inter-class paths, progressively extracting fine-grained knowledge within topics and diffusing it across semantically related ones, thereby enabling comprehensive extraction of the original knowledge base. However, existing defenses target only one path, leaving the other unprotected. We conduct a systematic exploration to assess the impact of protecting each path independently and find that joint protection is essential for effective defense. Based on this, we propose RAGFort, a structure-aware dual-module defense combining "contrastive reindexing" for inter-class isolation and "constrained cascade generation" for intra-class protection. Experiments across security, performance, and robustness confirm that RAGFort significantly reduces reconstruction success while preserving answer quality, offering comprehensive defense against knowledge base extraction attacks.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025



We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Executable Counterfactuals: Improving LLMs' Causal Reasoning Through Code
Oct 02, 2025Counterfactual reasoning, a hallmark of intelligence, consists of three steps: inferring latent variables from observations (abduction), constructing alternatives (interventions), and predicting their outcomes (prediction). This skill is essential for advancing LLMs' causal understanding and expanding their applications in high-stakes domains such as scientific research. However, existing efforts in assessing LLM's counterfactual reasoning capabilities tend to skip the abduction step, effectively reducing to interventional reasoning and leading to overestimation of LLM performance. To address this, we introduce executable counterfactuals, a novel framework that operationalizes causal reasoning through code and math problems. Our framework explicitly requires all three steps of counterfactual reasoning and enables scalable synthetic data creation with varying difficulty, creating a frontier for evaluating and improving LLM's reasoning. Our results reveal substantial drop in accuracy (25-40%) from interventional to counterfactual reasoning for SOTA models like o4-mini and Claude-4-Sonnet. To address this gap, we construct a training set comprising counterfactual code problems having if-else condition and test on out-of-domain code structures (e.g. having while-loop); we also test whether a model trained on code would generalize to counterfactual math word problems. While supervised finetuning on stronger models' reasoning traces improves in-domain performance of Qwen models, it leads to a decrease in accuracy on OOD tasks such as counterfactual math problems. In contrast, reinforcement learning induces the core cognitive behaviors and generalizes to new domains, yielding gains over the base model on both code (improvement of 1.5x-2x) and math problems. Analysis of the reasoning traces reinforces these findings and highlights the promise of RL for improving LLMs' counterfactual reasoning.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025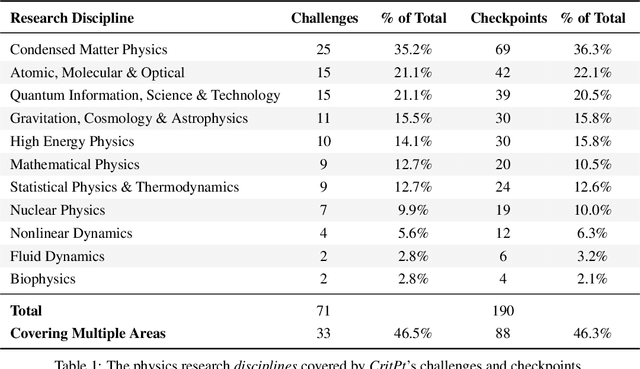



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Structural Information-based Hierarchical Diffusion for Offline Reinforcement Learning
Sep 26, 2025



Diffusion-based generative methods have shown promising potential for modeling trajectories from offline reinforcement learning (RL) datasets, and hierarchical diffusion has been introduced to mitigate variance accumulation and computational challenges in long-horizon planning tasks. However, existing approaches typically assume a fixed two-layer diffusion hierarchy with a single predefined temporal scale, which limits adaptability to diverse downstream tasks and reduces flexibility in decision making. In this work, we propose SIHD, a novel Structural Information-based Hierarchical Diffusion framework for effective and stable offline policy learning in long-horizon environments with sparse rewards. Specifically, we analyze structural information embedded in offline trajectories to construct the diffusion hierarchy adaptively, enabling flexible trajectory modeling across multiple temporal scales. Rather than relying on reward predictions from localized sub-trajectories, we quantify the structural information gain of each state community and use it as a conditioning signal within the corresponding diffusion layer. To reduce overreliance on offline datasets, we introduce a structural entropy regularizer that encourages exploration of underrepresented states while avoiding extrapolation errors from distributional shifts. Extensive evaluations on challenging offline RL tasks show that SIHD significantly outperforms state-of-the-art baselines in decision-making performance and demonstrates superior generalization across diverse scenarios.
Leveraging Support Vector Regression for Outcome Prediction in Personalized Ultra-fractionated Stereotactic Adaptive Radiotherapy
Sep 09, 2025Personalized ultra-fractionated stereotactic adaptive radiotherapy (PULSAR) is a novel treatment that delivers radiation in pulses of protracted intervals. Accurate prediction of gross tumor volume (GTV) changes through regression models has substantial prognostic value. This study aims to develop a multi-omics based support vector regression (SVR) model for predicting GTV change. A retrospective cohort of 39 patients with 69 brain metastases was analyzed, based on radiomics (MRI images) and dosiomics (dose maps) features. Delta features were computed to capture relative changes between two time points. A feature selection pipeline using least absolute shrinkage and selection operator (Lasso) algorithm with weight- or frequency-based ranking criterion was implemented. SVR models with various kernels were evaluated using the coefficient of determination (R2) and relative root mean square error (RRMSE). Five-fold cross-validation with 10 repeats was employed to mitigate the limitation of small data size. Multi-omics models that integrate radiomics, dosiomics, and their delta counterparts outperform individual-omics models. Delta-radiomic features play a critical role in enhancing prediction accuracy relative to features at single time points. The top-performing model achieves an R2 of 0.743 and an RRMSE of 0.022. The proposed multi-omics SVR model shows promising performance in predicting continuous change of GTV. It provides a more quantitative and personalized approach to assist patient selection and treatment adjustment in PULSAR.
Emotion Transfer with Enhanced Prototype for Unseen Emotion Recognition in Conversation
Aug 27, 2025



Current Emotion Recognition in Conversation (ERC) research follows a closed-domain assumption. However, there is no clear consensus on emotion classification in psychology, which presents a challenge for models when it comes to recognizing previously unseen emotions in real-world applications. To bridge this gap, we introduce the Unseen Emotion Recognition in Conversation (UERC) task for the first time and propose ProEmoTrans, a solid prototype-based emotion transfer framework. This prototype-based approach shows promise but still faces key challenges: First, implicit expressions complicate emotion definition, which we address by proposing an LLM-enhanced description approach. Second, utterance encoding in long conversations is difficult, which we tackle with a proposed parameter-free mechanism for efficient encoding and overfitting prevention. Finally, the Markovian flow nature of emotions is hard to transfer, which we address with an improved Attention Viterbi Decoding (AVD) method to transfer seen emotion transitions to unseen emotions. Extensive experiments on three datasets show that our method serves as a strong baseline for preliminary exploration in this new area.
Exploring Strategies for Personalized Radiation Therapy: Part III Identifying genetic determinants for Radiation Response with Meta Learning
Aug 11, 2025



Radiation response in cancer is shaped by complex, patient specific biology, yet current treatment strategies often rely on uniform dose prescriptions without accounting for tumor heterogeneity. In this study, we introduce a meta learning framework for one-shot prediction of radiosensitivity measured by SF2 using cell line level gene expression data. Unlike the widely used Radiosensitivity Index RSI a rank-based linear model trained on a fixed 10-gene signature, our proposed meta-learned model allows the importance of each gene to vary by sample through fine tuning. This flexibility addresses key limitations of static models like RSI, which assume uniform gene contributions across tumor types and discard expression magnitude and gene gene interactions. Our results show that meta learning offers robust generalization to unseen samples and performs well in tumor subgroups with high radiosensitivity variability, such as adenocarcinoma and large cell carcinoma. By learning transferable structure across tasks while preserving sample specific adaptability, our approach enables rapid adaptation to individual samples, improving predictive accuracy across diverse tumor subtypes while uncovering context dependent patterns of gene influence that may inform personalized therapy.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Dialogues Aspect-based Sentiment Quadruple Extraction via Structural Entropy Minimization Partitioning
Aug 07, 2025Dialogues Aspect-based Sentiment Quadruple Extraction (DiaASQ) aims to extract all target-aspect-opinion-sentiment quadruples from a given multi-round, multi-participant dialogue. Existing methods typically learn word relations across entire dialogues, assuming a uniform distribution of sentiment elements. However, we find that dialogues often contain multiple semantically independent sub-dialogues without clear dependencies between them. Therefore, learning word relationships across the entire dialogue inevitably introduces additional noise into the extraction process. To address this, our method focuses on partitioning dialogues into semantically independent sub-dialogues. Achieving completeness while minimizing these sub-dialogues presents a significant challenge. Simply partitioning based on reply relationships is ineffective. Instead, we propose utilizing a structural entropy minimization algorithm to partition the dialogues. This approach aims to preserve relevant utterances while distinguishing irrelevant ones as much as possible. Furthermore, we introduce a two-step framework for quadruple extraction: first extracting individual sentiment elements at the utterance level, then matching quadruples at the sub-dialogue level. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in DiaASQ with much lower computational costs.