 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Memory Placement using Evolutionary Graph Reinforcement Learning
Jul 14, 2020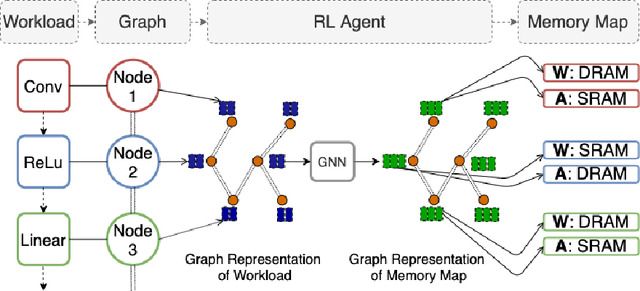

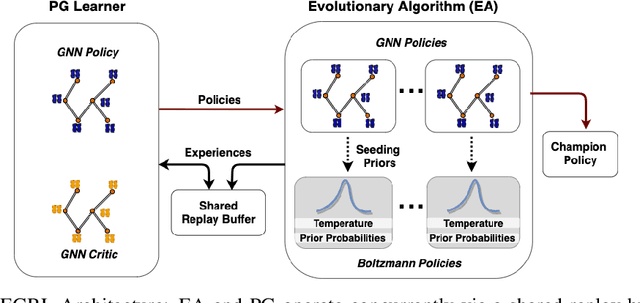
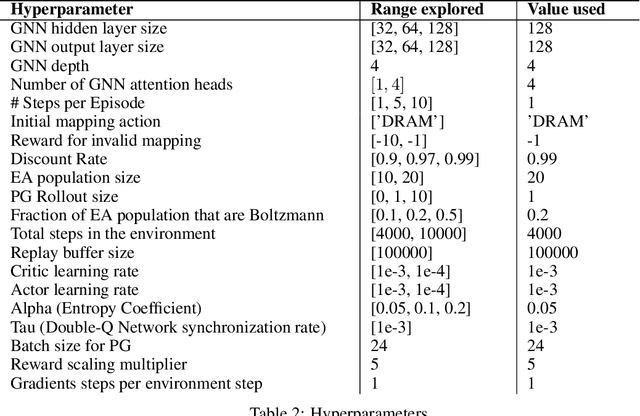
As modern neural networks have grown to billions of parameters, meeting tight latency budgets has become increasingly challenging. Approaches like compression, sparsification and network pruning have proven effective to tackle this problem - but they rely on modifications of the underlying network. In this paper, we look at a complimentary approach of optimizing how tensors are mapped to on-chip memory in an inference accelerator while leaving the network parameters untouched. Since different memory components trade off capacity for bandwidth differently, a sub-optimal mapping can result in high latency. We introduce evolutionary graph reinforcement learning (EGRL) - a method combining graph neural networks, reinforcement learning (RL) and evolutionary search - that aims to find the optimal mapping to minimize latency. Furthermore, a set of fast, stateless policies guide the evolutionary search to improve sample-efficiency. We train and validate our approach directly on the Intel NNP-I chip for inference using a batch size of 1. EGRL outperforms policy-gradient, evolutionary search and dynamic programming baselines on BERT, ResNet-101 and ResNet-50. We achieve 28-78% speed-up compared to the native NNP-I compiler on all three workloads.
Emergence of Separable Manifolds in Deep Language Representations
Jun 06, 2020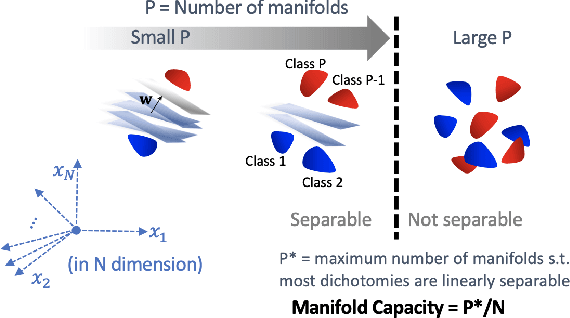
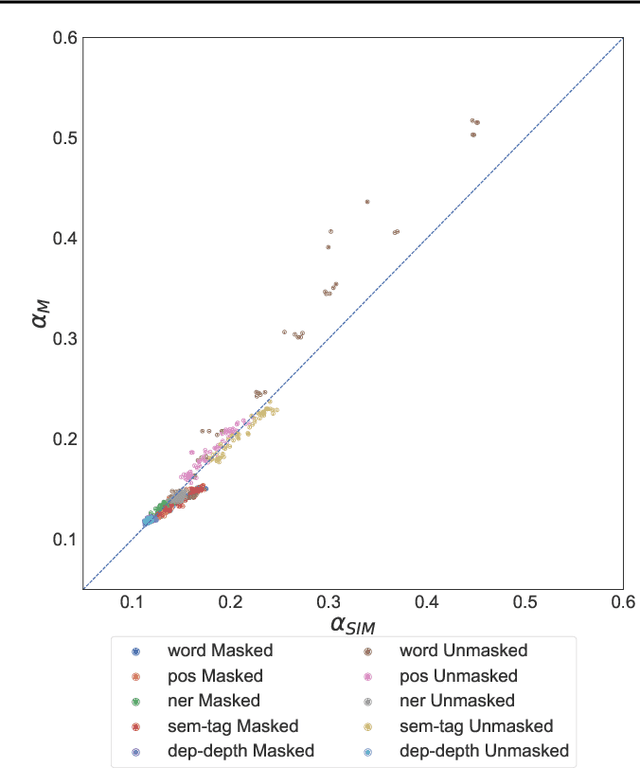
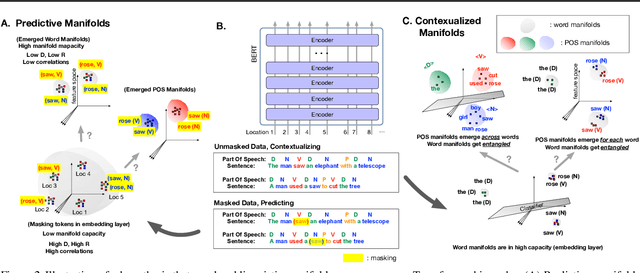
Artificial neural networks (ANNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representation extracted from task-optimized ANNs and neural populations in the brain. ANNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience, to analyze the high dimensional geometry of language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT-2, etc. ) and find evidence for emergence of linguistic manifold across layer depth (e.g., manifolds for part-of-speech and combinatory categorical grammar tags). We further observe that different encoding schemes used to obtain the representations lead to differences in whether these linguistic manifolds emerge in earlier or later layers of the network. In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds radius, dimensionality and inter-manifold correlations.
Untangling in Invariant Speech Recognition
Mar 03, 2020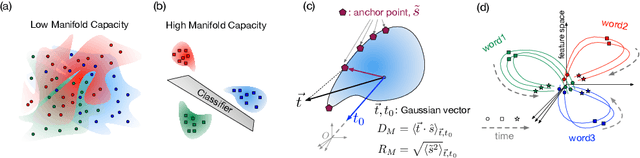
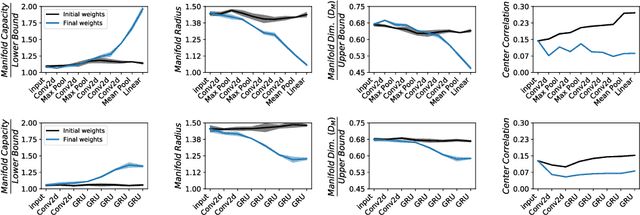
Encouraged by the success of deep neural networks on a variety of visual tasks, much theoretical and experimental work has been aimed at understanding and interpreting how vision networks operate. Meanwhile, deep neural networks have also achieved impressive performance in audio processing applications, both as sub-components of larger systems and as complete end-to-end systems by themselves. Despite their empirical successes, comparatively little is understood about how these audio models accomplish these tasks. In this work, we employ a recently developed statistical mechanical theory that connects geometric properties of network representations and the separability of classes to probe how information is untangled within neural networks trained to recognize speech. We observe that speaker-specific nuisance variations are discarded by the network's hierarchy, whereas task-relevant properties such as words and phonemes are untangled in later layers. Higher level concepts such as parts-of-speech and context dependence also emerge in the later layers of the network. Finally, we find that the deep representations carry out significant temporal untangling by efficiently extracting task-relevant features at each time step of the computation. Taken together, these findings shed light on how deep auditory models process time dependent input signals to achieve invariant speech recognition, and show how different concepts emerge through the layers of the network.
Shifted and Squeezed 8-bit Floating Point format for Low-Precision Training of Deep Neural Networks
Jan 16, 2020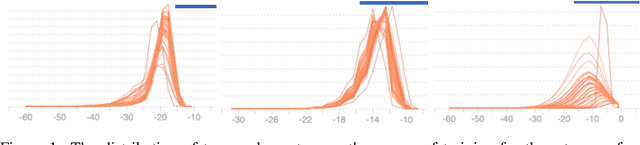

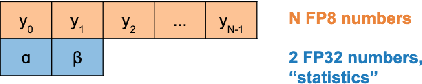

Training with larger number of parameters while keeping fast iterations is an increasingly adopted strategy and trend for developing better performing Deep Neural Network (DNN) models. This necessitates increased memory footprint and computational requirements for training. Here we introduce a novel methodology for training deep neural networks using 8-bit floating point (FP8) numbers. Reduced bit precision allows for a larger effective memory and increased computational speed. We name this method Shifted and Squeezed FP8 (S2FP8). We show that, unlike previous 8-bit precision training methods, the proposed method works out-of-the-box for representative models: ResNet-50, Transformer and NCF. The method can maintain model accuracy without requiring fine-tuning loss scaling parameters or keeping certain layers in single precision. We introduce two learnable statistics of the DNN tensors - shifted and squeezed factors that are used to optimally adjust the range of the tensors in 8-bits, thus minimizing the loss in information due to quantization.
Mimic The Raw Domain: Accelerating Action Recognition in the Compressed Domain
Nov 20, 2019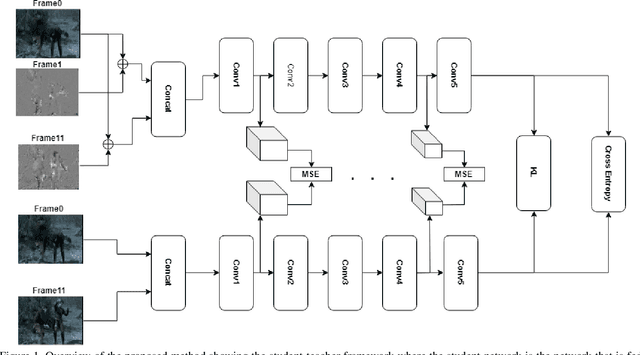
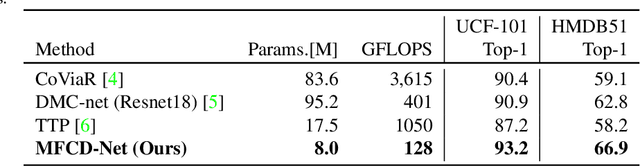


Video understanding usually requires expensive computation that prohibits its deployment, yet videos contain significant spatiotemporal redundancy that can be exploited. In particular, operating directly on the motion vectors and residuals in the compressed video domain can significantly accelerate the compute, by not using the raw videos which demand colossal storage capacity. Existing methods approach this task as a multiple modalities problem. In this paper we are approaching the task in a completely different way; we are looking at the data from the compressed stream as a one unit clip and propose that the residual frames can replace the original RGB frames from the raw domain. Furthermore, we are using teacher-student method to aid the network in the compressed domain to mimic the teacher network in the raw domain. We show experiments on three leading datasets (HMDB51, UCF1, and Kinetics) that approach state-of-the-art accuracy on raw video data by using compressed data. Our model MFCD-Net outperforms prior methods in the compressed domain and more importantly, our model has 11X fewer parameters and 3X fewer Flops, dramatically improving the efficiency of video recognition inference. This approach enables applying neural networks exclusively in the compressed domain without compromising accuracy while accelerating performance.
MLPerf Inference Benchmark
Nov 06, 2019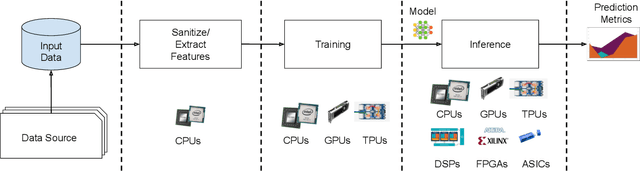
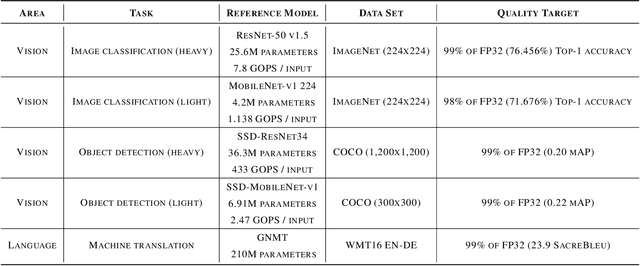
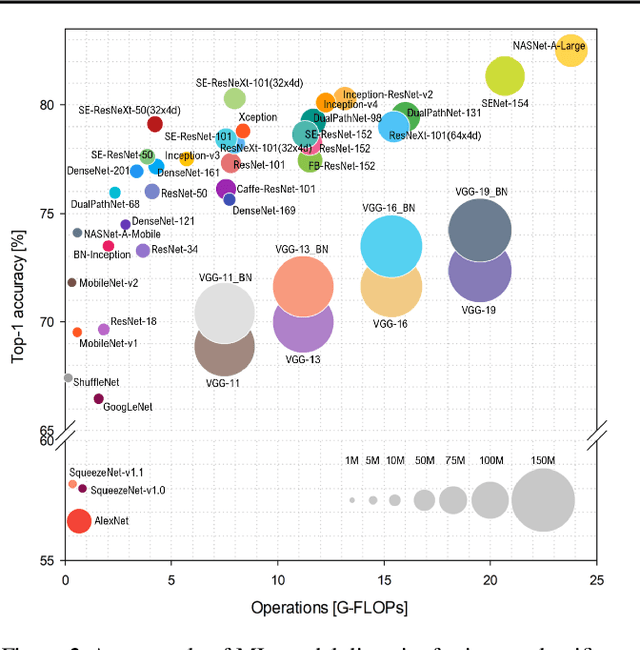
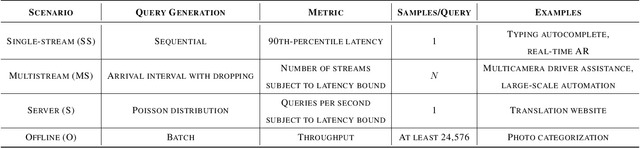
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
MLPerf Training Benchmark
Oct 30, 2019
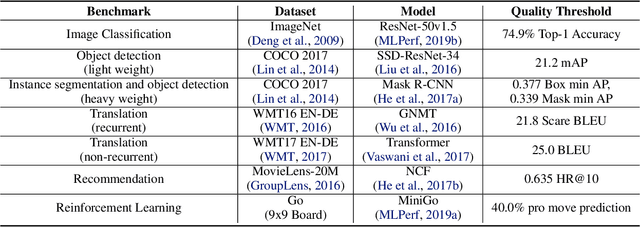
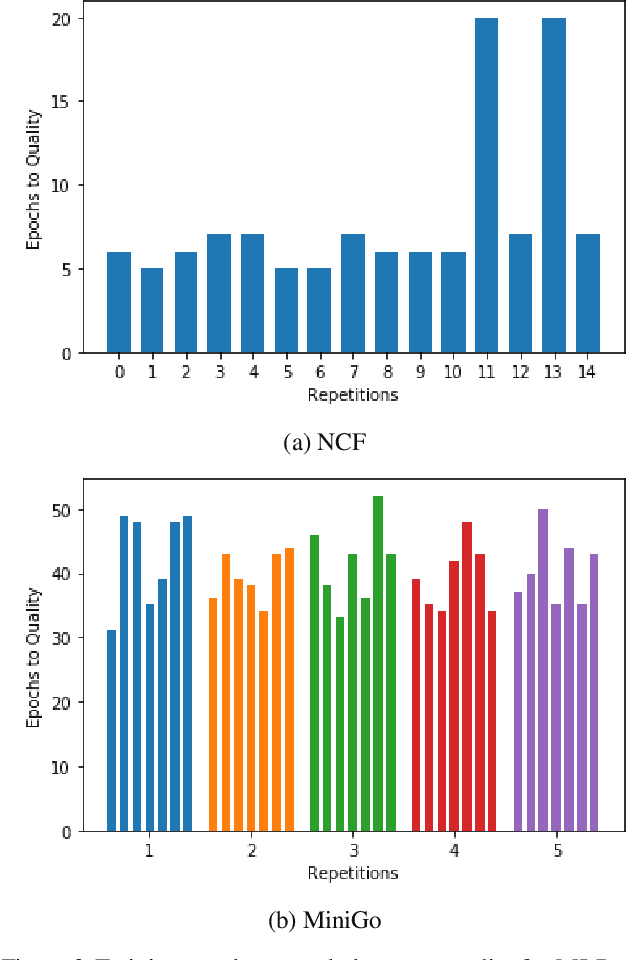
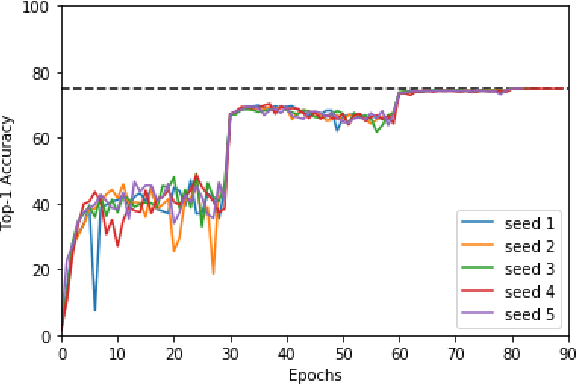
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
Central Server Free Federated Learning over Single-sided Trust Social Networks
Oct 11, 2019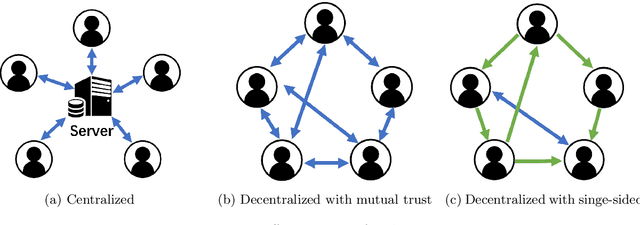
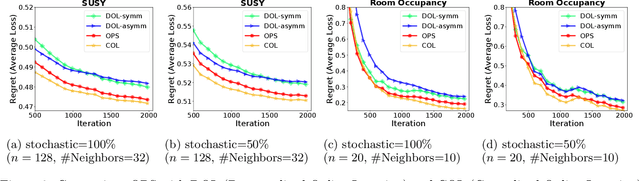
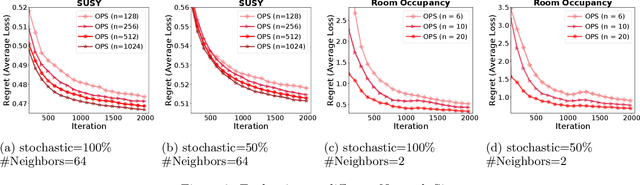
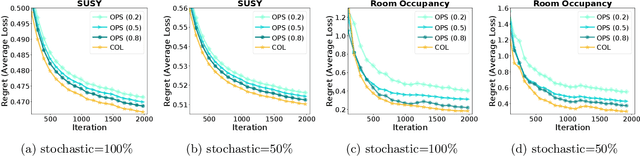
Federated learning has become increasingly important for modern machine learning, especially for data privacy-sensitive scenarios. Existing federated learning mostly adopts the central server-based architecture or centralized architecture. However, in many social network scenarios, centralized federated learning is not applicable (e.g., a central agent or server connecting all users may not exist, or the communication cost to the central server is not affordable). In this paper, we consider a generic setting: 1) the central server may not exist, and 2) the social network is unidirectional or of single-sided trust (i.e., user A trusts user B but user B may not trust user A). We propose a central server free federated learning algorithm, named Online Push-Sum (OPS) method, to handle this challenging but generic scenario. A rigorous regret analysis is also provided, which shows very interesting results on how users can benefit from communication with trusted users in the federated learning scenario. This work builds upon the fundamental algorithm framework and theoretical guarantees for federated learning in the generic social network scenario.
Using Image Priors to Improve Scene Understanding
Oct 02, 2019
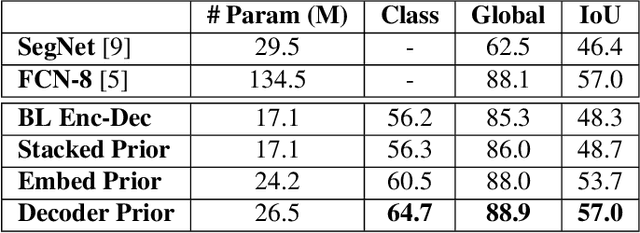
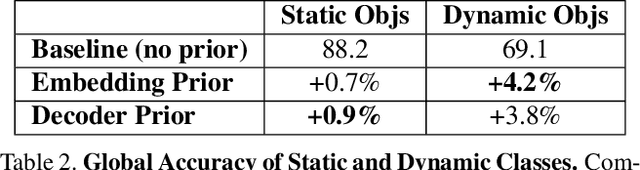
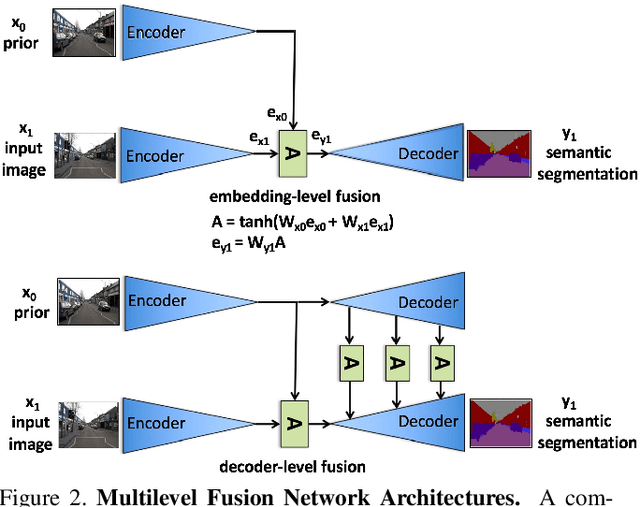
Semantic segmentation algorithms that can robustly segment objects across multiple camera viewpoints are crucial for assuring navigation and safety in emerging applications such as autonomous driving. Existing algorithms treat each image in isolation, but autonomous vehicles often revisit the same locations or maintain information from the immediate past. We propose a simple yet effective method for leveraging these image priors to improve semantic segmentation of images from sequential driving datasets. We examine several methods to fuse these temporal scene priors, and introduce a prior fusion network that is able to learn how to transfer this information. The prior fusion model improves the accuracy over the non-prior baseline from 69.1% to 73.3% for dynamic classes, and from 88.2% to 89.1% for static classes. Compared to models such as FCN-8, our prior method achieves the same accuracy with 5 times fewer parameters. We used a simple encoder decoder backbone, but this general prior fusion method could be applied to more complex semantic segmentation backbones. We also discuss how structured representations of scenes in the form of a scene graph could be leveraged as priors to further improve scene understanding.
Triplet-Aware Scene Graph Embeddings
Sep 19, 2019
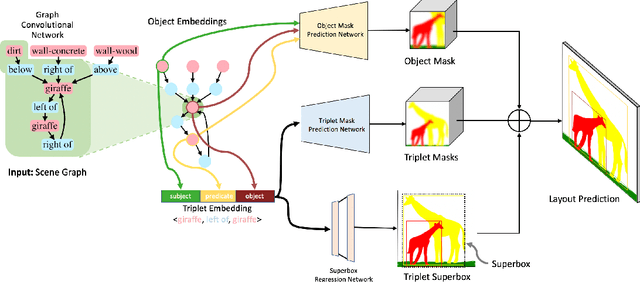

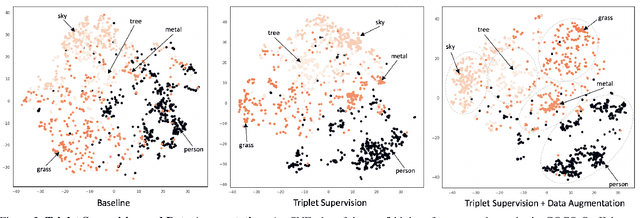
Scene graphs have become an important form of structured knowledge for tasks such as for image generation, visual relation detection, visual question answering, and image retrieval. While visualizing and interpreting word embeddings is well understood, scene graph embeddings have not been fully explored. In this work, we train scene graph embeddings in a layout generation task with different forms of supervision, specifically introducing triplet super-vision and data augmentation. We see a significant performance increase in both metrics that measure the goodness of layout prediction, mean intersection-over-union (mIoU)(52.3% vs. 49.2%) and relation score (61.7% vs. 54.1%),after the addition of triplet supervision and data augmentation. To understand how these different methods affect the scene graph representation, we apply several new visualization and evaluation methods to explore the evolution of the scene graph embedding. We find that triplet supervision significantly improves the embedding separability, which is highly correlated with the performance of the layout prediction model.