 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEPA-DNA: Grounding Genomic Foundation Models through Joint-Embedding Predictive Architectures
Feb 19, 2026Genomic Foundation Models (GFMs) have largely relied on Masked Language Modeling (MLM) or Next Token Prediction (NTP) to learn the language of life. While these paradigms excel at capturing local genomic syntax and fine-grained motif patterns, they often fail to capture the broader functional context, resulting in representations that lack a global biological perspective. We introduce JEPA-DNA, a novel pre-training framework that integrates the Joint-Embedding Predictive Architecture (JEPA) with traditional generative objectives. JEPA-DNA introduces latent grounding by coupling token-level recovery with a predictive objective in the latent space by supervising a CLS token. This forces the model to predict the high-level functional embeddings of masked genomic segments rather than focusing solely on individual nucleotides. JEPA-DNA extends both NTP and MLM paradigms and can be deployed either as a standalone from-scratch objective or as a continual pre-training enhancement for existing GFMs. Our evaluations across a diverse suite of genomic benchmarks demonstrate that JEPA-DNA consistently yields superior performance in supervised and zero-shot tasks compared to generative-only baselines. By providing a more robust and biologically grounded representation, JEPA-DNA offers a scalable path toward foundation models that understand not only the genomic alphabet, but also the underlying functional logic of the sequence.
Feature Whitening via Gradient Transformation for Improved Convergence
Oct 04, 2020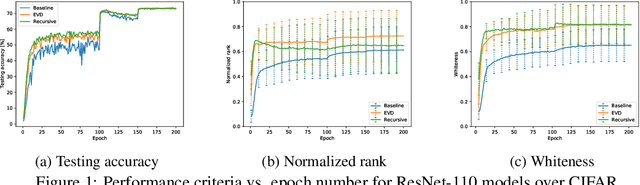
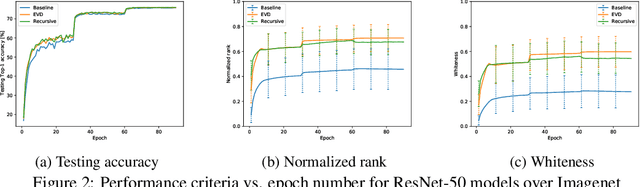
Feature whitening is a known technique for speeding up training of DNN. Under certain assumptions, whitening the activations reduces the Fisher information matrix to a simple identity matrix, in which case stochastic gradient descent is equivalent to the faster natural gradient descent. Due to the additional complexity resulting from transforming the layer inputs and their corresponding gradients in the forward and backward propagation, and from repeatedly computing the Eigenvalue decomposition (EVD), this method is not commonly used to date. In this work, we address the complexity drawbacks of feature whitening. Our contribution is twofold. First, we derive an equivalent method, which replaces the sample transformations by a transformation to the weight gradients, applied to every batch of B samples. The complexity is reduced by a factor of S=(2B), where S denotes the feature dimension of the layer output. As the batch size increases with distributed training, the benefit of using the proposed method becomes more compelling. Second, motivated by the theoretical relation between the condition number of the sample covariance matrix and the convergence speed, we derive an alternative sub-optimal algorithm which recursively reduces the condition number of the latter matrix. Compared to EVD, complexity is reduced by a factor of the input feature dimension M. We exemplify the proposed algorithms with ResNet-based networks for image classification demonstrated on the CIFAR and Imagenet datasets. Parallelizing the proposed algorithms is straightforward and we implement a distributed version thereof. Improved convergence, in terms of speed and attained accuracy, can be observed in our experiments.
Mimic The Raw Domain: Accelerating Action Recognition in the Compressed Domain
Nov 20, 2019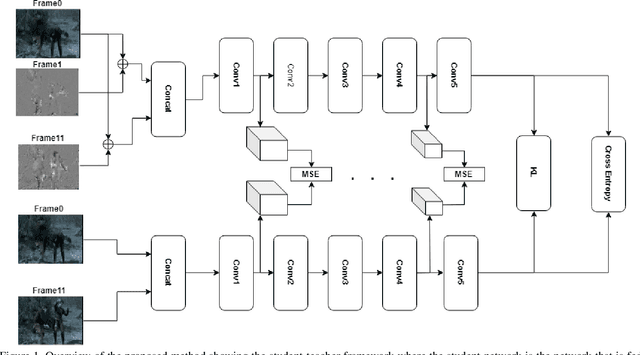
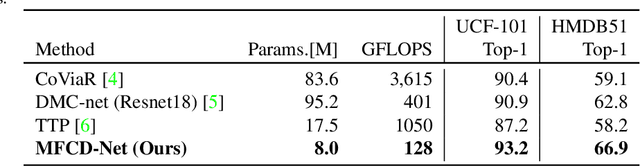


Video understanding usually requires expensive computation that prohibits its deployment, yet videos contain significant spatiotemporal redundancy that can be exploited. In particular, operating directly on the motion vectors and residuals in the compressed video domain can significantly accelerate the compute, by not using the raw videos which demand colossal storage capacity. Existing methods approach this task as a multiple modalities problem. In this paper we are approaching the task in a completely different way; we are looking at the data from the compressed stream as a one unit clip and propose that the residual frames can replace the original RGB frames from the raw domain. Furthermore, we are using teacher-student method to aid the network in the compressed domain to mimic the teacher network in the raw domain. We show experiments on three leading datasets (HMDB51, UCF1, and Kinetics) that approach state-of-the-art accuracy on raw video data by using compressed data. Our model MFCD-Net outperforms prior methods in the compressed domain and more importantly, our model has 11X fewer parameters and 3X fewer Flops, dramatically improving the efficiency of video recognition inference. This approach enables applying neural networks exclusively in the compressed domain without compromising accuracy while accelerating performance.