 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Good Generated Image? Investigating Human and Multimodal LLM Image Preference Alignment
Sep 16, 2025



Automated evaluation of generative text-to-image models remains a challenging problem. Recent works have proposed using multimodal LLMs to judge the quality of images, but these works offer little insight into how multimodal LLMs make use of concepts relevant to humans, such as image style or composition, to generate their overall assessment. In this work, we study what attributes of an image--specifically aesthetics, lack of artifacts, anatomical accuracy, compositional correctness, object adherence, and style--are important for both LLMs and humans to make judgments on image quality. We first curate a dataset of human preferences using synthetically generated image pairs. We use inter-task correlation between each pair of image quality attributes to understand which attributes are related in making human judgments. Repeating the same analysis with LLMs, we find that the relationships between image quality attributes are much weaker. Finally, we study individual image quality attributes by generating synthetic datasets with a high degree of control for each axis. Humans are able to easily judge the quality of an image with respect to all of the specific image quality attributes (e.g. high vs. low aesthetic image), however we find that some attributes, such as anatomical accuracy, are much more difficult for multimodal LLMs to learn to judge. Taken together, these findings reveal interesting differences between how humans and multimodal LLMs perceive images.
CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images
Oct 25, 2023



We assemble a dataset of Creative-Commons-licensed (CC) images, which we use to train a set of open diffusion models that are qualitatively competitive with Stable Diffusion 2 (SD2). This task presents two challenges: (1) high-resolution CC images lack the captions necessary to train text-to-image generative models; (2) CC images are relatively scarce. In turn, to address these challenges, we use an intuitive transfer learning technique to produce a set of high-quality synthetic captions paired with curated CC images. We then develop a data- and compute-efficient training recipe that requires as little as 3% of the LAION-2B data needed to train existing SD2 models, but obtains comparable quality. These results indicate that we have a sufficient number of CC images (~70 million) for training high-quality models. Our training recipe also implements a variety of optimizations that achieve ~3X training speed-ups, enabling rapid model iteration. We leverage this recipe to train several high-quality text-to-image models, which we dub the CommonCanvas family. Our largest model achieves comparable performance to SD2 on a human evaluation, despite being trained on our CC dataset that is significantly smaller than LAION and using synthetic captions for training. We release our models, data, and code at https://github.com/mosaicml/diffusion/blob/main/assets/common-canvas.md
Fast Benchmarking of Accuracy vs. Training Time with Cyclic Learning Rates
Jun 02, 2022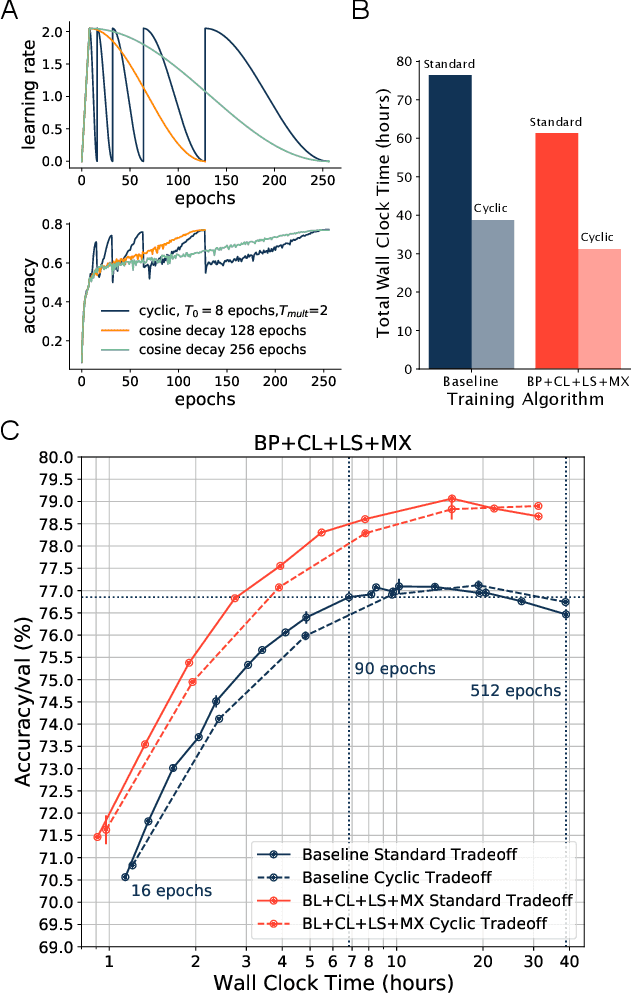
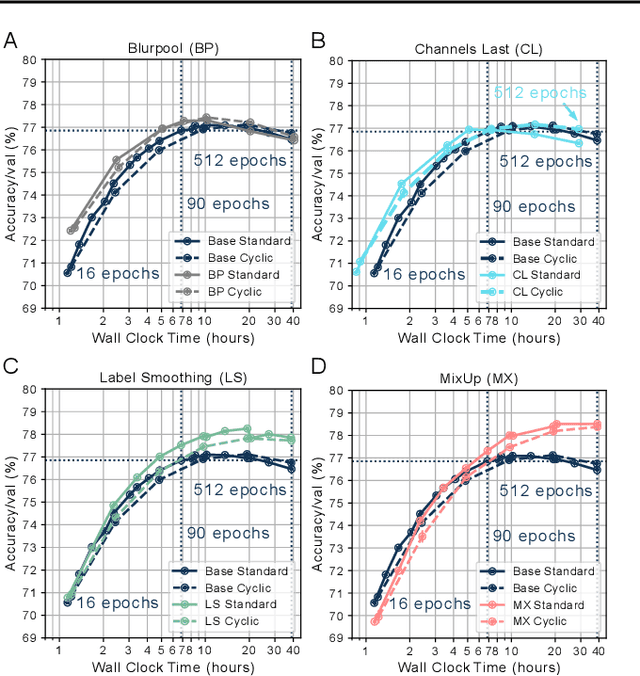
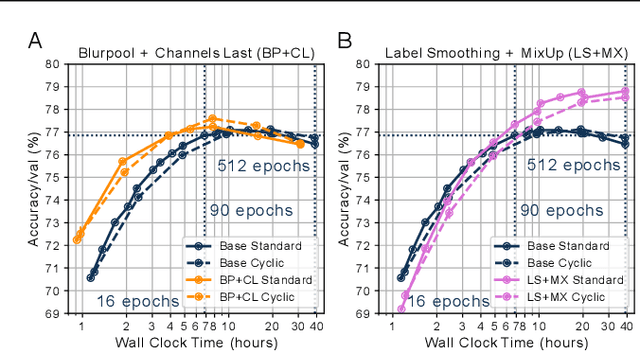
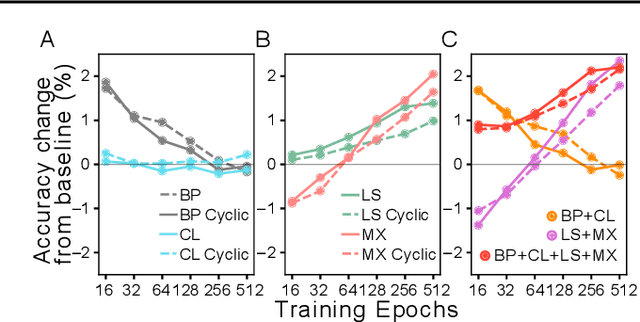
Benchmarking the tradeoff between neural network accuracy and training time is computationally expensive. Here we show how a multiplicative cyclic learning rate schedule can be used to construct a tradeoff curve in a single training run. We generate cyclic tradeoff curves for combinations of training methods such as Blurpool, Channels Last, Label Smoothing and MixUp, and highlight how these cyclic tradeoff curves can be used to evaluate the effects of algorithmic choices on network training efficiency.
When and how epochwise double descent happens
Aug 26, 2021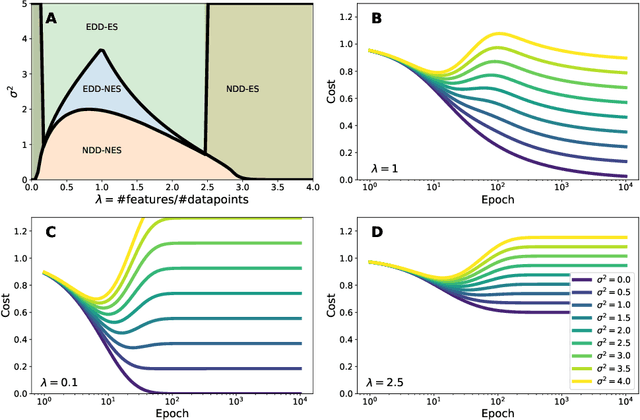
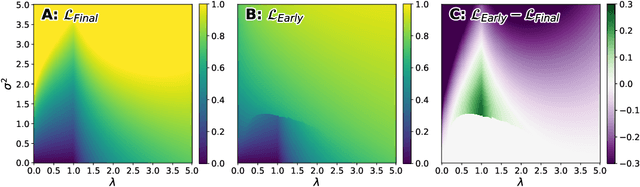
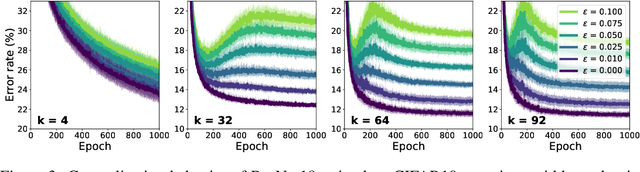
Deep neural networks are known to exhibit a `double descent' behavior as the number of parameters increases. Recently, it has also been shown that an `epochwise double descent' effect exists in which the generalization error initially drops, then rises, and finally drops again with increasing training time. This presents a practical problem in that the amount of time required for training is long, and early stopping based on validation performance may result in suboptimal generalization. In this work we develop an analytically tractable model of epochwise double descent that allows us to characterise theoretically when this effect is likely to occur. This model is based on the hypothesis that the training data contains features that are slow to learn but informative. We then show experimentally that deep neural networks behave similarly to our theoretical model. Our findings indicate that epochwise double descent requires a critical amount of noise to occur, but above a second critical noise level early stopping remains effective. Using insights from theory, we give two methods by which epochwise double descent can be removed: one that removes slow to learn features from the input and reduces generalization performance, and another that instead modifies the training dynamics and matches or exceeds the generalization performance of standard training. Taken together, our results suggest a new picture of how epochwise double descent emerges from the interplay between the dynamics of training and noise in the training data.
On the geometry of generalization and memorization in deep neural networks
May 30, 2021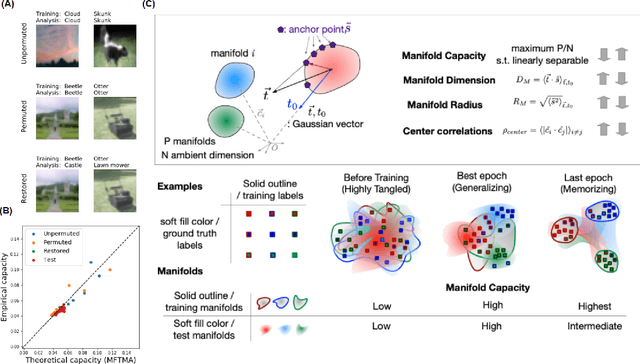
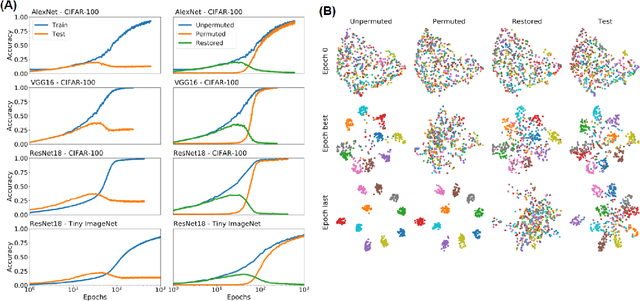
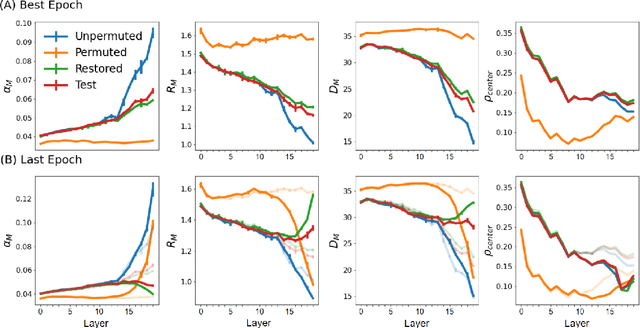
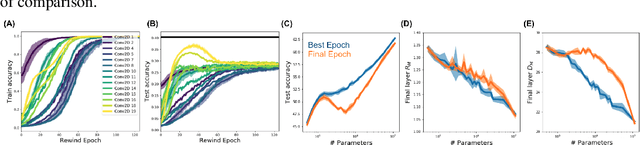
Understanding how large neural networks avoid memorizing training data is key to explaining their high generalization performance. To examine the structure of when and where memorization occurs in a deep network, we use a recently developed replica-based mean field theoretic geometric analysis method. We find that all layers preferentially learn from examples which share features, and link this behavior to generalization performance. Memorization predominately occurs in the deeper layers, due to decreasing object manifolds' radius and dimension, whereas early layers are minimally affected. This predicts that generalization can be restored by reverting the final few layer weights to earlier epochs before significant memorization occurred, which is confirmed by the experiments. Additionally, by studying generalization under different model sizes, we reveal the connection between the double descent phenomenon and the underlying model geometry. Finally, analytical analysis shows that networks avoid memorization early in training because close to initialization, the gradient contribution from permuted examples are small. These findings provide quantitative evidence for the structure of memorization across layers of a deep neural network, the drivers for such structure, and its connection to manifold geometric properties.
Emergence of Separable Manifolds in Deep Language Representations
Jun 06, 2020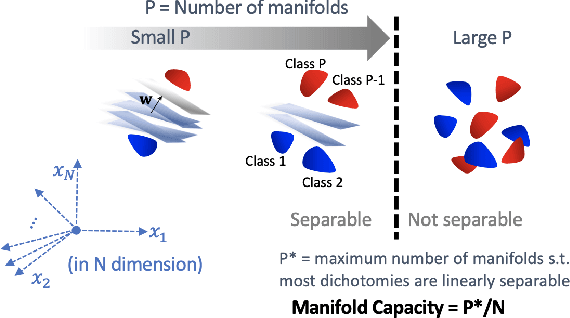
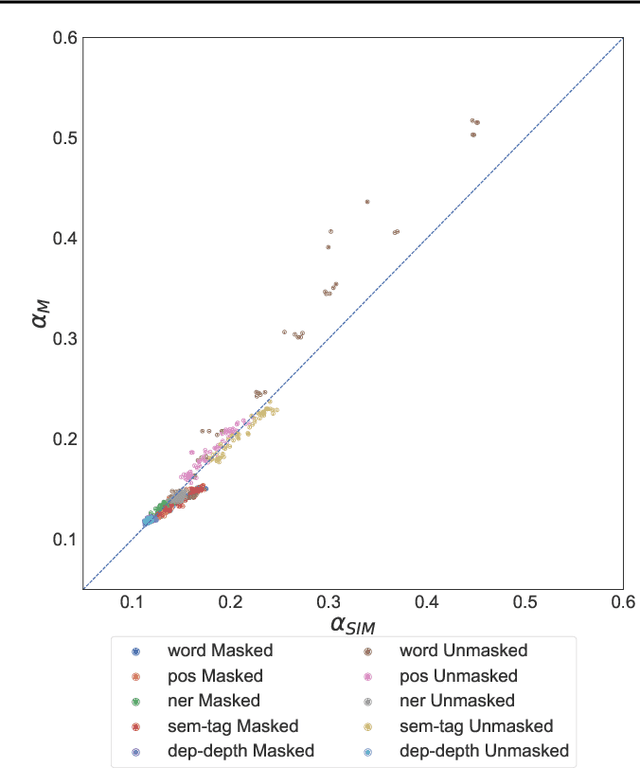
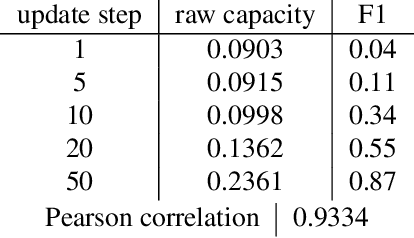
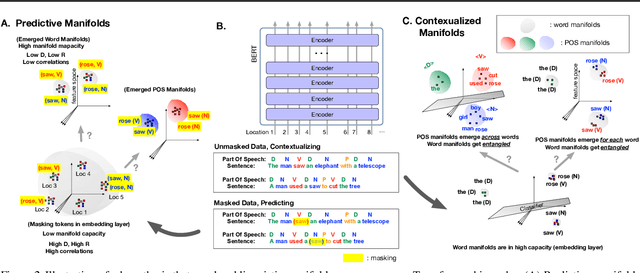
Artificial neural networks (ANNs) have shown much empirical success in solving perceptual tasks across various cognitive modalities. While they are only loosely inspired by the biological brain, recent studies report considerable similarities between representation extracted from task-optimized ANNs and neural populations in the brain. ANNs have subsequently become a popular model class to infer computational principles underlying complex cognitive functions, and in turn they have also emerged as a natural testbed for applying methods originally developed to probe information in neural populations. In this work, we utilize mean-field theoretic manifold analysis, a recent technique from computational neuroscience, to analyze the high dimensional geometry of language representations from large-scale contextual embedding models. We explore representations from different model families (BERT, RoBERTa, GPT-2, etc. ) and find evidence for emergence of linguistic manifold across layer depth (e.g., manifolds for part-of-speech and combinatory categorical grammar tags). We further observe that different encoding schemes used to obtain the representations lead to differences in whether these linguistic manifolds emerge in earlier or later layers of the network. In addition, we find that the emergence of linear separability in these manifolds is driven by a combined reduction of manifolds radius, dimensionality and inter-manifold correlations.
Untangling in Invariant Speech Recognition
Mar 03, 2020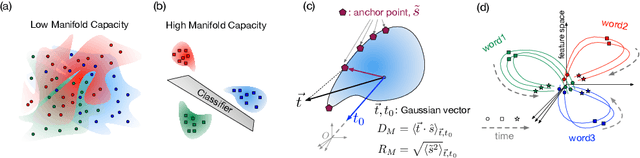
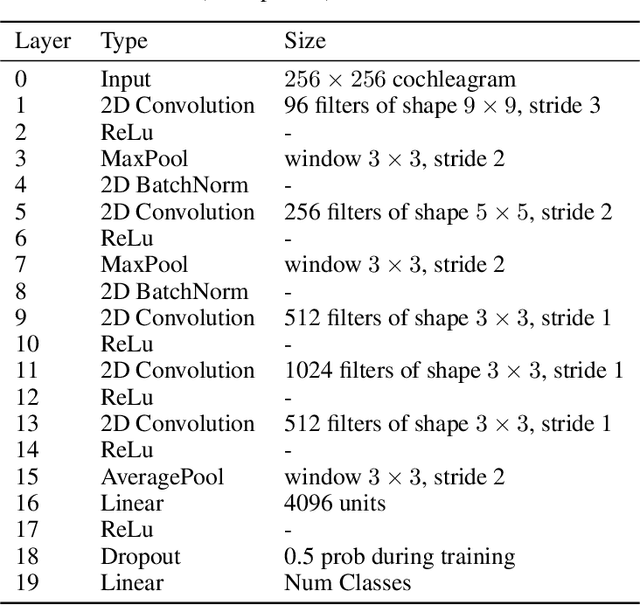
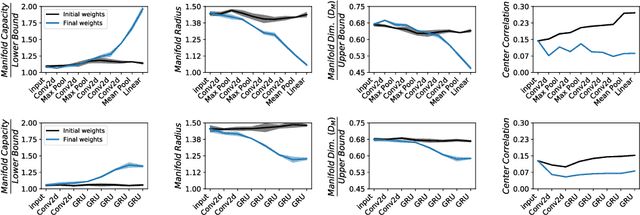
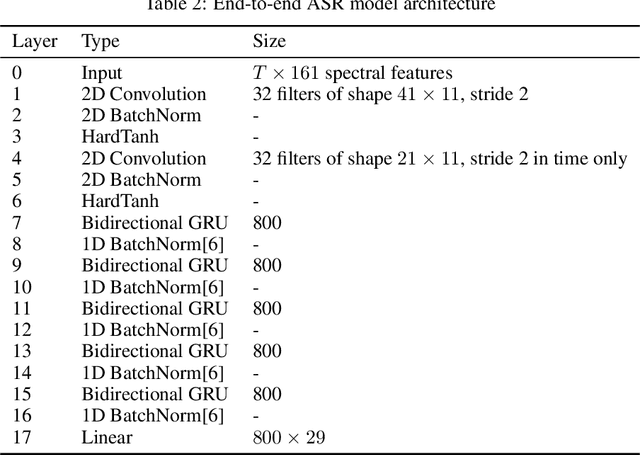
Encouraged by the success of deep neural networks on a variety of visual tasks, much theoretical and experimental work has been aimed at understanding and interpreting how vision networks operate. Meanwhile, deep neural networks have also achieved impressive performance in audio processing applications, both as sub-components of larger systems and as complete end-to-end systems by themselves. Despite their empirical successes, comparatively little is understood about how these audio models accomplish these tasks. In this work, we employ a recently developed statistical mechanical theory that connects geometric properties of network representations and the separability of classes to probe how information is untangled within neural networks trained to recognize speech. We observe that speaker-specific nuisance variations are discarded by the network's hierarchy, whereas task-relevant properties such as words and phonemes are untangled in later layers. Higher level concepts such as parts-of-speech and context dependence also emerge in the later layers of the network. Finally, we find that the deep representations carry out significant temporal untangling by efficiently extracting task-relevant features at each time step of the computation. Taken together, these findings shed light on how deep auditory models process time dependent input signals to achieve invariant speech recognition, and show how different concepts emerge through the layers of the network.
Semi-supervised voice conversion with amortized variational inference
Sep 30, 2019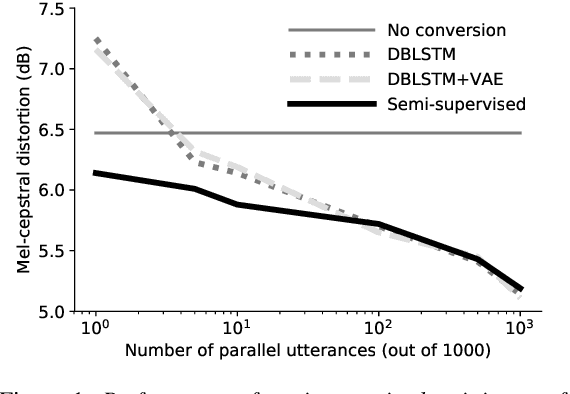

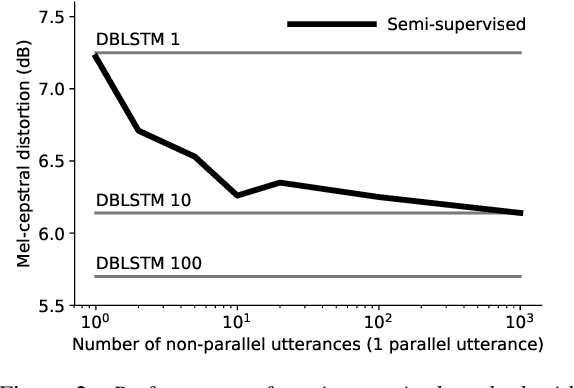
In this work we introduce a semi-supervised approach to the voice conversion problem, in which speech from a source speaker is converted into speech of a target speaker. The proposed method makes use of both parallel and non-parallel utterances from the source and target simultaneously during training. This approach can be used to extend existing parallel data voice conversion systems such that they can be trained with semi-supervision. We show that incorporating semi-supervision improves the voice conversion performance compared to fully supervised training when the number of parallel utterances is limited as in many practical applications. Additionally, we find that increasing the number non-parallel utterances used in training continues to improve performance when the amount of parallel training data is held constant.
* Accepted for publication at Interspeech 2019
Adversarially Trained Autoencoders for Parallel-Data-Free Voice Conversion
May 09, 2019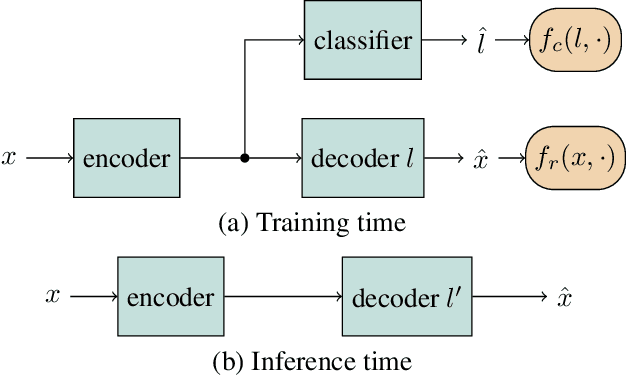
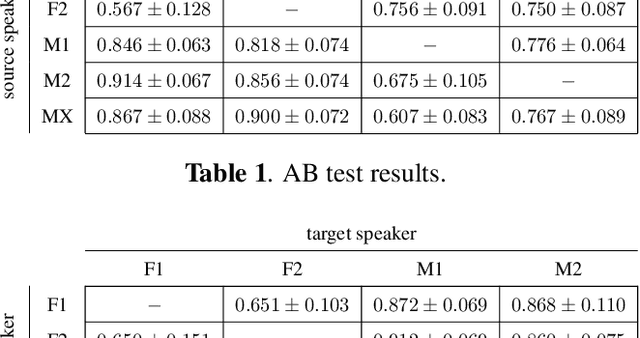
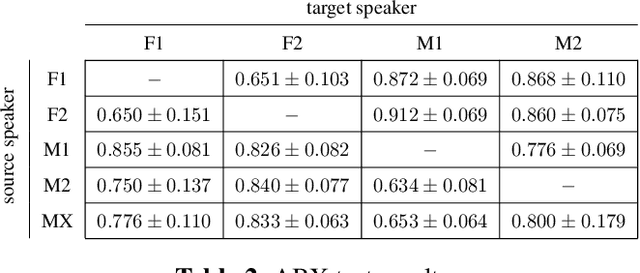
We present a method for converting the voices between a set of speakers. Our method is based on training multiple autoencoder paths, where there is a single speaker-independent encoder and multiple speaker-dependent decoders. The autoencoders are trained with an addition of an adversarial loss which is provided by an auxiliary classifier in order to guide the output of the encoder to be speaker independent. The training of the model is unsupervised in the sense that it does not require collecting the same utterances from the speakers nor does it require time aligning over phonemes. Due to the use of a single encoder, our method can generalize to converting the voice of out-of-training speakers to speakers in the training dataset. We present subjective tests corroborating the performance of our method.
Many-to-Many Voice Conversion with Out-of-Dataset Speaker Support
Apr 30, 2019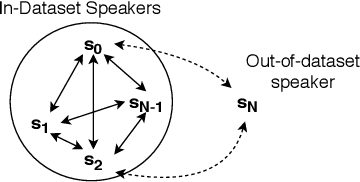
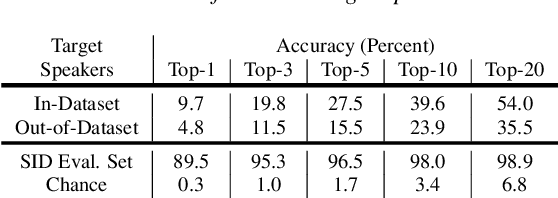
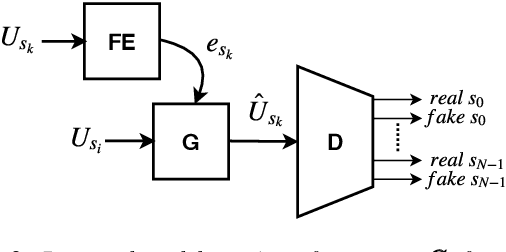

We present a Cycle-GAN based many-to-many voice conversion method that can convert between speakers that are not in the training set. This property is enabled through speaker embeddings generated by a neural network that is jointly trained with the Cycle-GAN. In contrast to prior work in this domain, our method enables conversion between an out-of-dataset speaker and a target speaker in either direction and does not require re-training. Out-of-dataset speaker conversion quality is evaluated using an independently trained speaker identification model, and shows good style conversion characteristics for previously unheard speakers. Subjective tests on human listeners show style conversion quality for in-dataset speakers is comparable to the state-of-the-art baseline model.