 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
USM-SCD: Multilingual Speaker Change Detection Based on Large Pretrained Foundation Models
Sep 14, 2023We introduce a multilingual speaker change detection model (USM-SCD) that can simultaneously detect speaker turns and perform ASR for 96 languages. This model is adapted from a speech foundation model trained on a large quantity of supervised and unsupervised data, demonstrating the utility of fine-tuning from a large generic foundation model for a downstream task. We analyze the performance of this multilingual speaker change detection model through a series of ablation studies. We show that the USM-SCD model can achieve more than 75% average speaker change detection F1 score across a test set that consists of data from 96 languages. On American English, the USM-SCD model can achieve an 85.8% speaker change detection F1 score across various public and internal test sets, beating the previous monolingual baseline model by 21% relative. We also show that we only need to fine-tune one-quarter of the trainable model parameters to achieve the best model performance. The USM-SCD model exhibits state-of-the-art ASR quality compared with a strong public ASR baseline, making it suitable to handle both tasks with negligible additional computational cost.
Rethinking k-means from manifold learning perspective
May 12, 2023Although numerous clustering algorithms have been developed, many existing methods still leverage k-means technique to detect clusters of data points. However, the performance of k-means heavily depends on the estimation of centers of clusters, which is very difficult to achieve an optimal solution. Another major drawback is that it is sensitive to noise and outlier data. In this paper, from manifold learning perspective, we rethink k-means and present a new clustering algorithm which directly detects clusters of data without mean estimation. Specifically, we construct distance matrix between data points by Butterworth filter such that distance between any two data points in the same clusters equals to a small constant, while increasing the distance between other data pairs from different clusters. To well exploit the complementary information embedded in different views, we leverage the tensor Schatten p-norm regularization on the 3rd-order tensor which consists of indicator matrices of different views. Finally, an efficient alternating algorithm is derived to optimize our model. The constructed sequence was proved to converge to the stationary KKT point. Extensive experimental results indicate the superiority of our proposed method.
Scalable Randomized Kernel Methods for Multiview Data Integration and Prediction
Apr 10, 2023We develop scalable randomized kernel methods for jointly associating data from multiple sources and simultaneously predicting an outcome or classifying a unit into one of two or more classes. The proposed methods model nonlinear relationships in multiview data together with predicting a clinical outcome and are capable of identifying variables or groups of variables that best contribute to the relationships among the views. We use the idea that random Fourier bases can approximate shift-invariant kernel functions to construct nonlinear mappings of each view and we use these mappings and the outcome variable to learn view-independent low-dimensional representations. Through simulation studies, we show that the proposed methods outperform several other linear and nonlinear methods for multiview data integration. When the proposed methods were applied to gene expression, metabolomics, proteomics, and lipidomics data pertaining to COVID-19, we identified several molecular signatures forCOVID-19 status and severity. Results from our real data application and simulations with small sample sizes suggest that the proposed methods may be useful for small sample size problems. Availability: Our algorithms are implemented in Pytorch and interfaced in R and would be made available at: https://github.com/lasandrall/RandMVLearn.
Active Finetuning: Exploiting Annotation Budget in the Pretraining-Finetuning Paradigm
Mar 25, 2023Given the large-scale data and the high annotation cost, pretraining-finetuning becomes a popular paradigm in multiple computer vision tasks. Previous research has covered both the unsupervised pretraining and supervised finetuning in this paradigm, while little attention is paid to exploiting the annotation budget for finetuning. To fill in this gap, we formally define this new active finetuning task focusing on the selection of samples for annotation in the pretraining-finetuning paradigm. We propose a novel method called ActiveFT for active finetuning task to select a subset of data distributing similarly with the entire unlabeled pool and maintaining enough diversity by optimizing a parametric model in the continuous space. We prove that the Earth Mover's distance between the distributions of the selected subset and the entire data pool is also reduced in this process. Extensive experiments show the leading performance and high efficiency of ActiveFT superior to baselines on both image classification and semantic segmentation. Our code is released at https://github.com/yichen928/ActiveFT.
Interpretable Deep Learning Methods for Multiview Learning
Feb 15, 2023Technological advances have enabled the generation of unique and complementary types of data or views (e.g. genomics, proteomics, metabolomics) and opened up a new era in multiview learning research with the potential to lead to new biomedical discoveries. We propose iDeepViewLearn (Interpretable Deep Learning Method for Multiview Learning) for learning nonlinear relationships in data from multiple views while achieving feature selection. iDeepViewLearn combines deep learning flexibility with the statistical benefits of data and knowledge-driven feature selection, giving interpretable results. Deep neural networks are used to learn view-independent low-dimensional embedding through an optimization problem that minimizes the difference between observed and reconstructed data, while imposing a regularization penalty on the reconstructed data. The normalized Laplacian of a graph is used to model bilateral relationships between variables in each view, therefore, encouraging selection of related variables. iDeepViewLearn is tested on simulated and two real-world data, including breast cancer-related gene expression and methylation data. iDeepViewLearn had competitive classification results and identified genes and CpG sites that differentiated between individuals who died from breast cancer and those who did not. The results of our real data application and simulations with small to moderate sample sizes suggest that iDeepViewLearn may be a useful method for small-sample-size problems compared to other deep learning methods for multiview learning.
Augmenting Transformer-Transducer Based Speaker Change Detection With Token-Level Training Loss
Nov 11, 2022



In this work we propose a novel token-based training strategy that improves Transformer-Transducer (T-T) based speaker change detection (SCD) performance. The conventional T-T based SCD model loss optimizes all output tokens equally. Due to the sparsity of the speaker changes in the training data, the conventional T-T based SCD model loss leads to sub-optimal detection accuracy. To mitigate this issue, we use a customized edit-distance algorithm to estimate the token-level SCD false accept (FA) and false reject (FR) rates during training and optimize model parameters to minimize a weighted combination of the FA and FR, focusing the model on accurately predicting speaker changes. We also propose a set of evaluation metrics that align better with commercial use cases. Experiments on a group of challenging real-world datasets show that the proposed training method can significantly improve the overall performance of the SCD model with the same number of parameters.
Highly Efficient Real-Time Streaming and Fully On-Device Speaker Diarization with Multi-Stage Clustering
Oct 25, 2022



While recent research advances in speaker diarization mostly focus on improving the quality of diarization results, there is also an increasing interest in improving the efficiency of diarization systems. In this paper, we propose a multi-stage clustering strategy, that uses different clustering algorithms for input of different lengths. Specifically, a fallback clusterer is used to handle short-form inputs; a main clusterer is used to handle medium-length inputs; and a pre-clusterer is used to compress long-form inputs before they are processed by the main clusterer. Both the main clusterer and the pre-clusterer can be configured with an upper bound of the computational complexity to adapt to devices with different constraints. This multi-stage clustering strategy is critical for streaming on-device speaker diarization systems, where the budgets of CPU, memory and battery are tight.
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022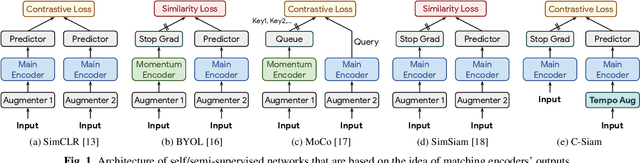
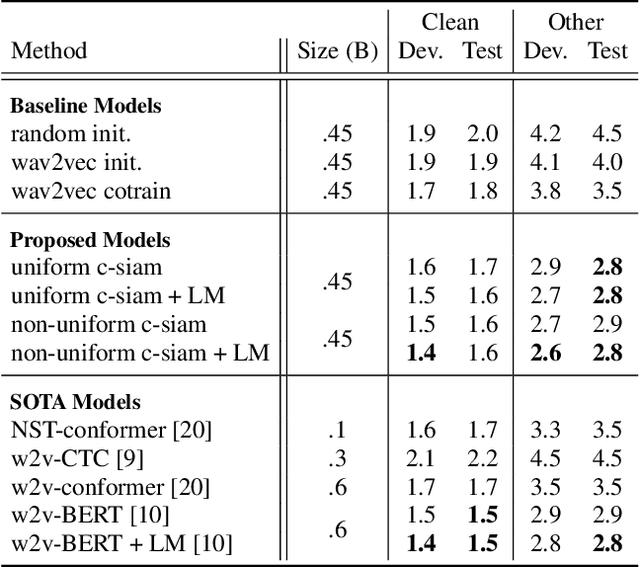
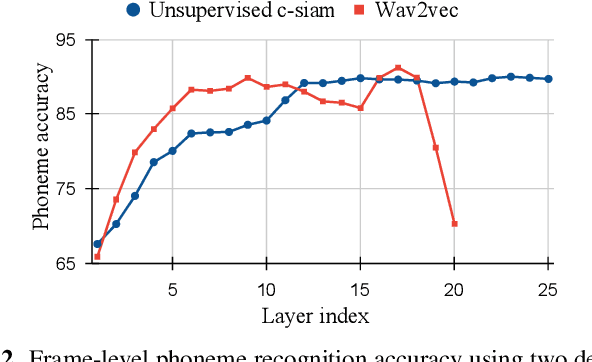
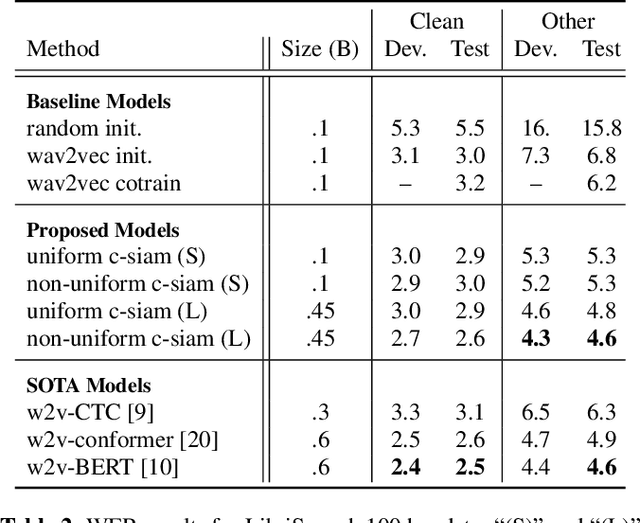
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Continual Predictive Learning from Videos
Apr 12, 2022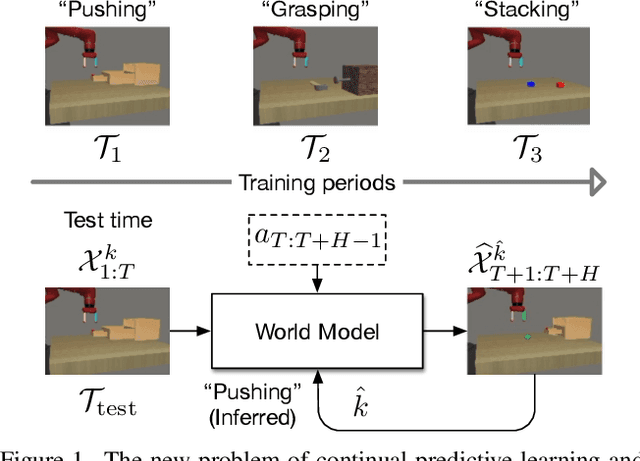
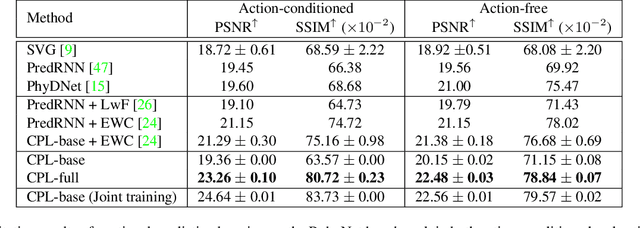
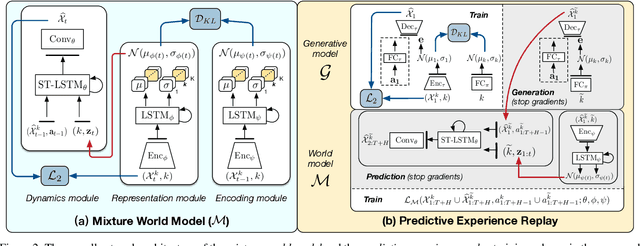
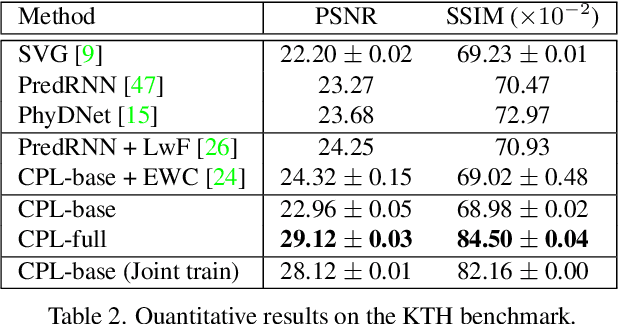
Predictive learning ideally builds the world model of physical processes in one or more given environments. Typical setups assume that we can collect data from all environments at all times. In practice, however, different prediction tasks may arrive sequentially so that the environments may change persistently throughout the training procedure. Can we develop predictive learning algorithms that can deal with more realistic, non-stationary physical environments? In this paper, we study a new continual learning problem in the context of video prediction, and observe that most existing methods suffer from severe catastrophic forgetting in this setup. To tackle this problem, we propose the continual predictive learning (CPL) approach, which learns a mixture world model via predictive experience replay and performs test-time adaptation with non-parametric task inference. We construct two new benchmarks based on RoboNet and KTH, in which different tasks correspond to different physical robotic environments or human actions. Our approach is shown to effectively mitigate forgetting and remarkably outperform the na\"ive combinations of previous art in video prediction and continual learning.