 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Denoising via Momentum Ascent in Gradient Fields
Mar 15, 2022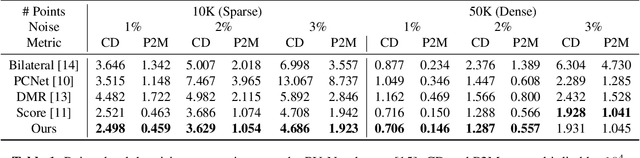
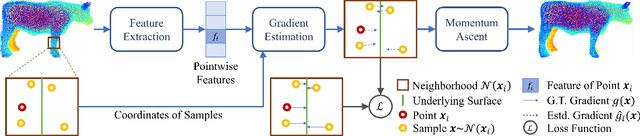

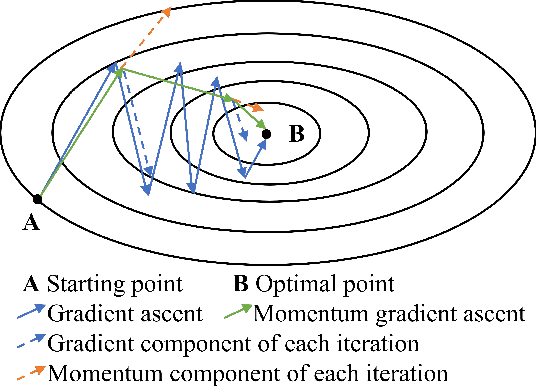
To achieve point cloud denoising, traditional methods heavily rely on geometric priors, and most learning-based approaches suffer from outliers and loss of details. Recently, the gradient-based method was proposed to estimate the gradient fields from the noisy point clouds using neural networks, and refine the position of each point according to the estimated gradient. However, the predicted gradient could fluctuate, leading to perturbed and unstable solutions, as well as a large inference time. To address these issues, we develop the momentum gradient ascent method that leverages the information of previous iterations in determining the trajectories of the points, thus improving the stability of the solution and reducing the inference time. Experiments demonstrate that the proposed method outperforms state-of-the-art methods with a variety of point clouds and noise levels.
MANet: Improving Video Denoising with a Multi-Alignment Network
Feb 20, 2022
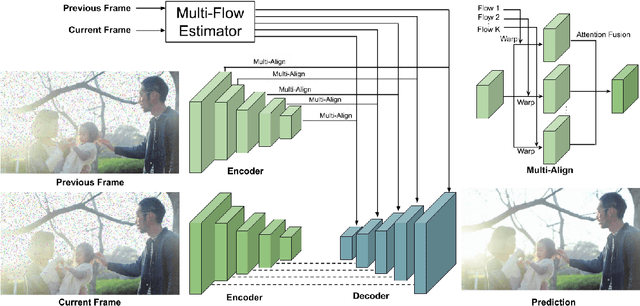
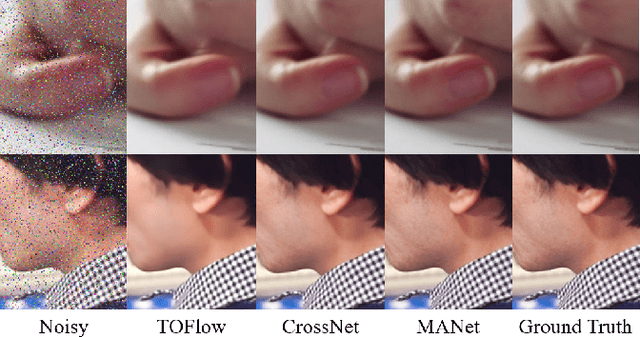
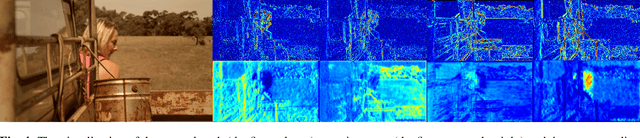
In video denoising, the adjacent frames often provide very useful information, but accurate alignment is needed before such information can be harnassed. In this work, we present a multi-alignment network, which generates multiple flow proposals followed by attention-based averaging. It serves to mimics the non-local mechanism, suppressing noise by averaging multiple observations. Our approach can be applied to various state-of-the-art models that are based on flow estimation. Experiments on a large-scale video dataset demonstrate that our method improves the denoising baseline model by 0.2dB, and further reduces the parameters by 47% with model distillation.
SpaceEdit: Learning a Unified Editing Space for Open-Domain Image Editing
Nov 30, 2021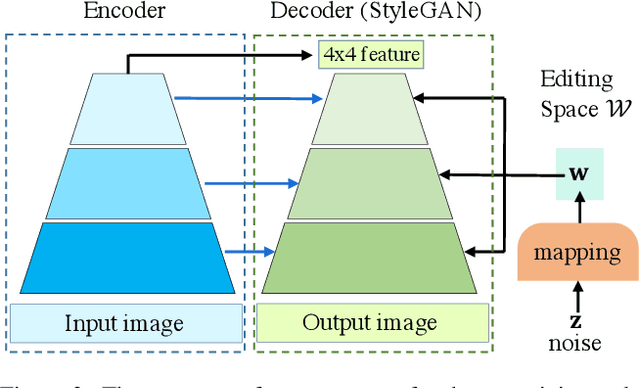
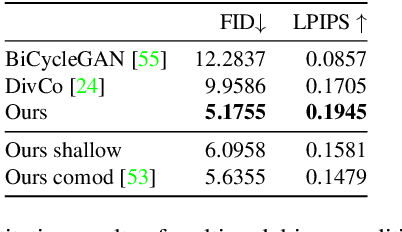


Recently, large pretrained models (e.g., BERT, StyleGAN, CLIP) have shown great knowledge transfer and generalization capability on various downstream tasks within their domains. Inspired by these efforts, in this paper we propose a unified model for open-domain image editing focusing on color and tone adjustment of open-domain images while keeping their original content and structure. Our model learns a unified editing space that is more semantic, intuitive, and easy to manipulate than the operation space (e.g., contrast, brightness, color curve) used in many existing photo editing softwares. Our model belongs to the image-to-image translation framework which consists of an image encoder and decoder, and is trained on pairs of before- and after-images to produce multimodal outputs. We show that by inverting image pairs into latent codes of the learned editing space, our model can be leveraged for various downstream editing tasks such as language-guided image editing, personalized editing, editing-style clustering, retrieval, etc. We extensively study the unique properties of the editing space in experiments and demonstrate superior performance on the aforementioned tasks.
Learning to Aggregate and Refine Noisy Labels for Visual Sentiment Analysis
Sep 15, 2021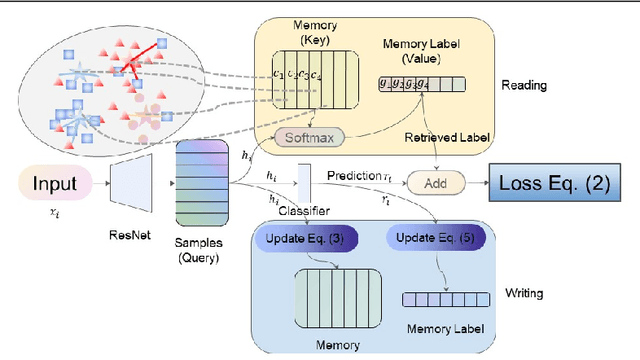
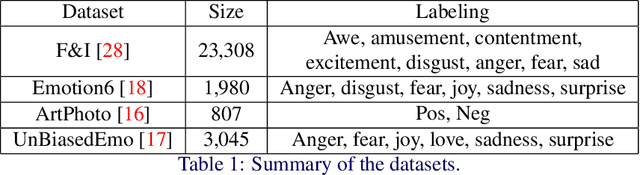

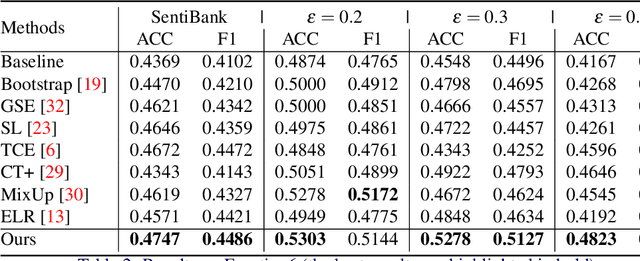
Visual sentiment analysis has received increasing attention in recent years. However, the quality of the dataset is a concern because the sentiment labels are crowd-sourcing, subjective, and prone to mistakes. This poses a severe threat to the data-driven models including the deep neural networks which would generalize poorly on the testing cases if they are trained to over-fit the samples with noisy sentiment labels. Inspired by the recent progress on learning with noisy labels, we propose a robust learning method to perform robust visual sentiment analysis. Our method relies on an external memory to aggregate and filter noisy labels during training and thus can prevent the model from overfitting the noisy cases. The memory is composed of the prototypes with corresponding labels, both of which can be updated online. We establish a benchmark for visual sentiment analysis with label noise using publicly available datasets. The experiment results of the proposed benchmark settings comprehensively show the effectiveness of our method.
Learning Bias-Invariant Representation by Cross-Sample Mutual Information Minimization
Aug 13, 2021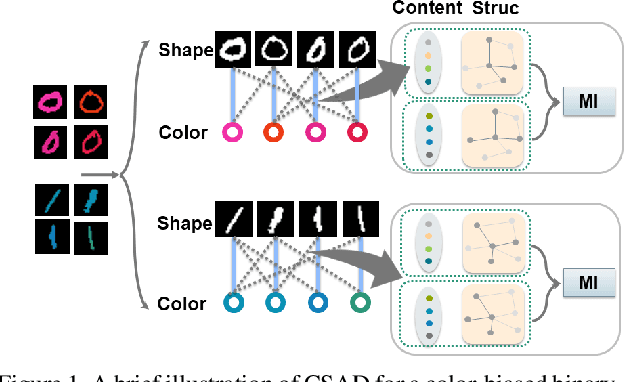
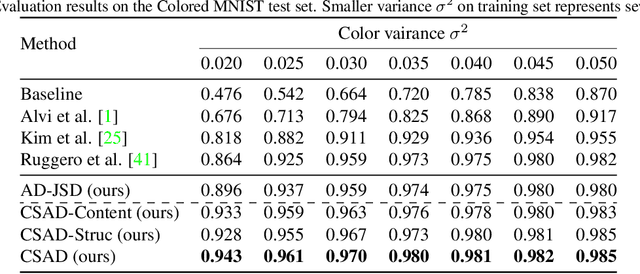
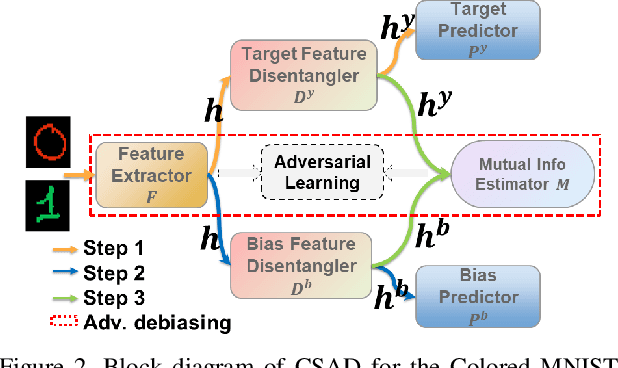
Deep learning algorithms mine knowledge from the training data and thus would likely inherit the dataset's bias information. As a result, the obtained model would generalize poorly and even mislead the decision process in real-life applications. We propose to remove the bias information misused by the target task with a cross-sample adversarial debiasing (CSAD) method. CSAD explicitly extracts target and bias features disentangled from the latent representation generated by a feature extractor and then learns to discover and remove the correlation between the target and bias features. The correlation measurement plays a critical role in adversarial debiasing and is conducted by a cross-sample neural mutual information estimator. Moreover, we propose joint content and local structural representation learning to boost mutual information estimation for better performance. We conduct thorough experiments on publicly available datasets to validate the advantages of the proposed method over state-of-the-art approaches.
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
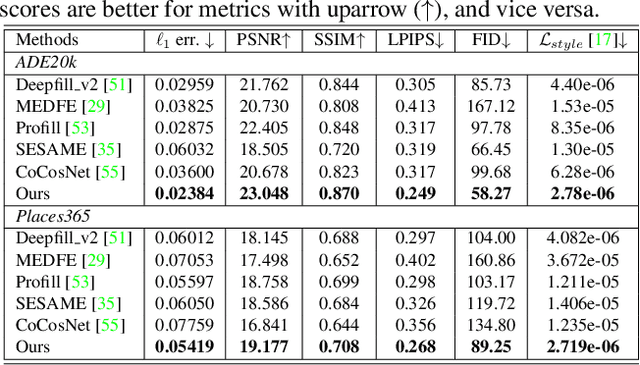
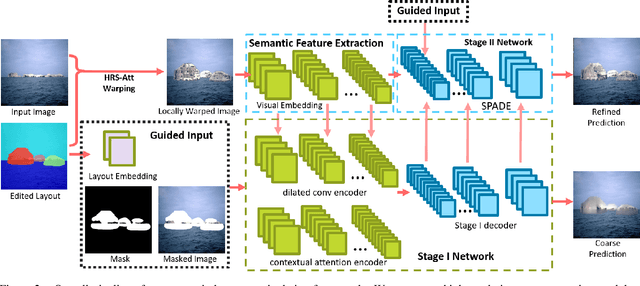
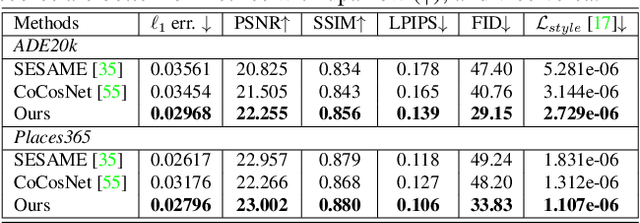
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
Actor-Action Video Classification CSC 249/449 Spring 2020 Challenge Report
Aug 18, 2020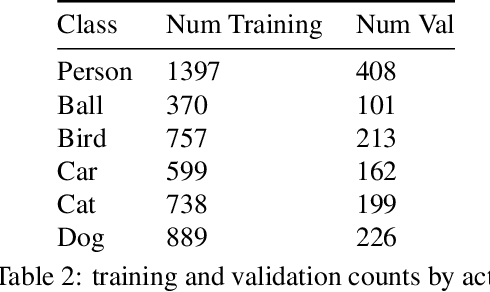
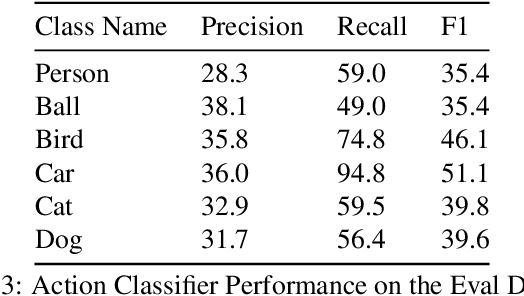
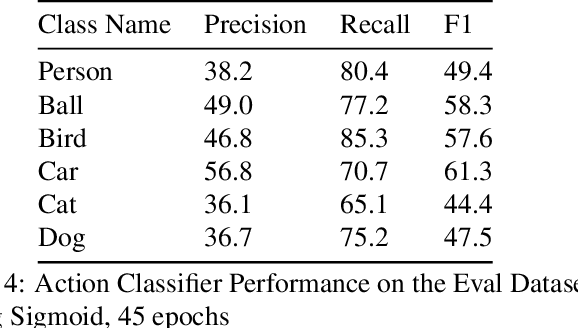
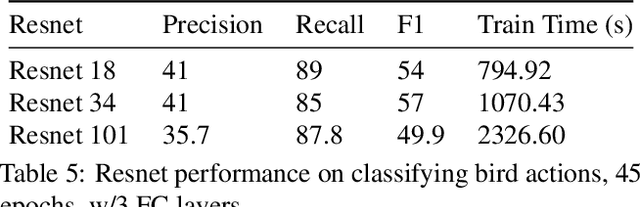
This technical report summarizes submissions and compiles from Actor-Action video classification challenge held as a final project in CSC 249/449 Machine Vision course (Spring 2020) at University of Rochester
Image Sentiment Transfer
Jun 19, 2020
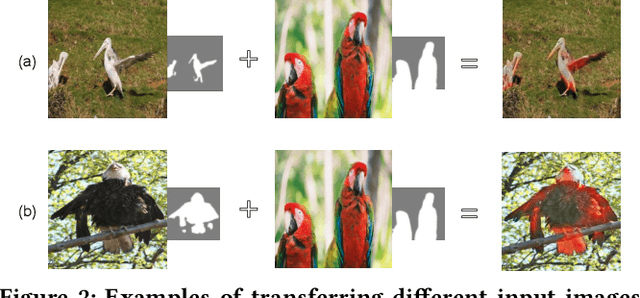
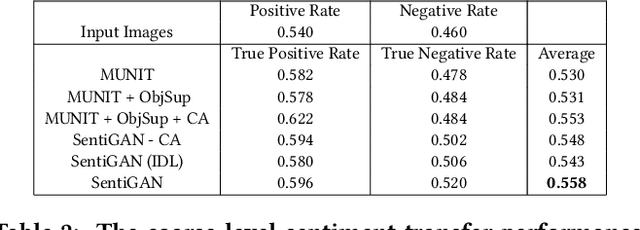
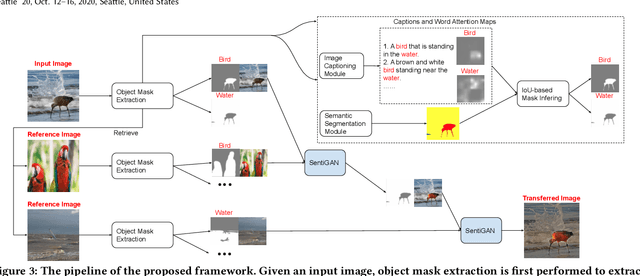
In this work, we introduce an important but still unexplored research task -- image sentiment transfer. Compared with other related tasks that have been well-studied, such as image-to-image translation and image style transfer, transferring the sentiment of an image is more challenging. Given an input image, the rule to transfer the sentiment of each contained object can be completely different, making existing approaches that perform global image transfer by a single reference image inadequate to achieve satisfactory performance. In this paper, we propose an effective and flexible framework that performs image sentiment transfer at the object level. It first detects the objects and extracts their pixel-level masks, and then performs object-level sentiment transfer guided by multiple reference images for the corresponding objects. For the core object-level sentiment transfer, we propose a novel Sentiment-aware GAN (SentiGAN). Both global image-level and local object-level supervisions are imposed to train SentiGAN. More importantly, an effective content disentanglement loss cooperating with a content alignment step is applied to better disentangle the residual sentiment-related information of the input image. Extensive quantitative and qualitative experiments are performed on the object-oriented VSO dataset we create, demonstrating the effectiveness of the proposed framework.
Personalized Fashion Recommendation from Personal Social Media Data: An Item-to-Set Metric Learning Approach
May 25, 2020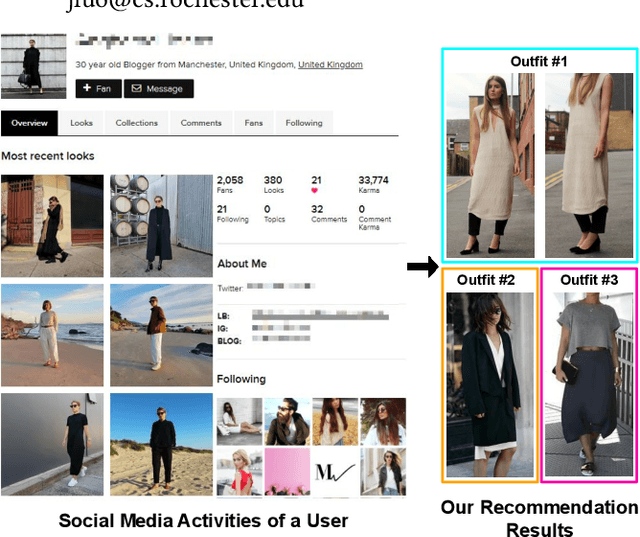
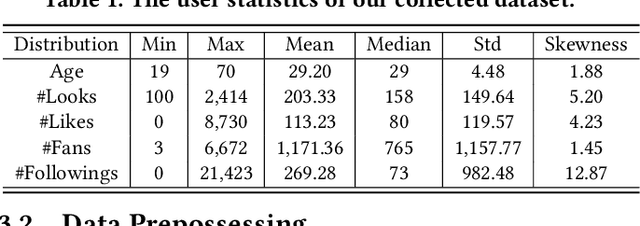
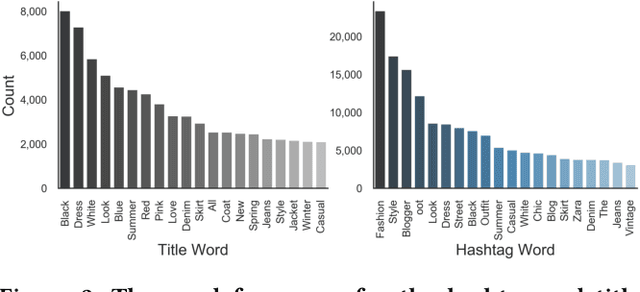
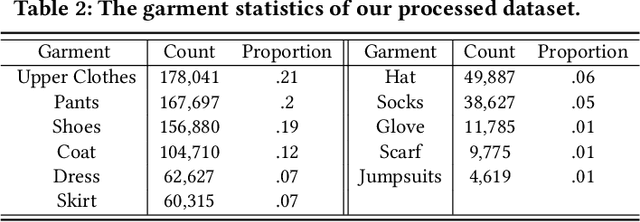
With the growth of online shopping for fashion products, accurate fashion recommendation has become a critical problem. Meanwhile, social networks provide an open and new data source for personalized fashion analysis. In this work, we study the problem of personalized fashion recommendation from social media data, i.e. recommending new outfits to social media users that fit their fashion preferences. To this end, we present an item-to-set metric learning framework that learns to compute the similarity between a set of historical fashion items of a user to a new fashion item. To extract features from multi-modal street-view fashion items, we propose an embedding module that performs multi-modality feature extraction and cross-modality gated fusion. To validate the effectiveness of our approach, we collect a real-world social media dataset. Extensive experiments on the collected dataset show the superior performance of our proposed approach.
What comprises a good talking-head video generation?: A Survey and Benchmark
May 07, 2020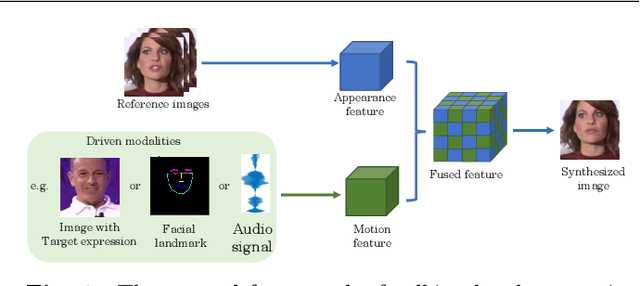
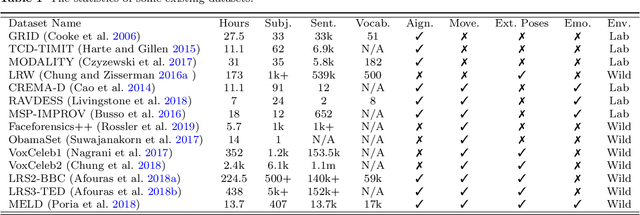
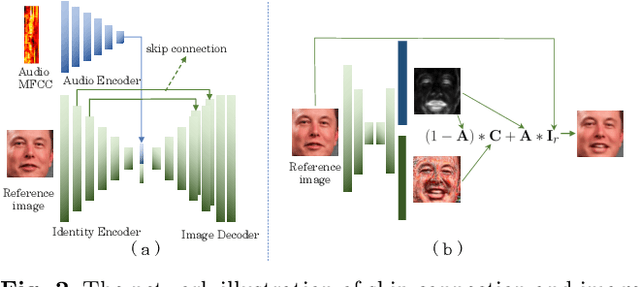

Over the years, performance evaluation has become essential in computer vision, enabling tangible progress in many sub-fields. While talking-head video generation has become an emerging research topic, existing evaluations on this topic present many limitations. For example, most approaches use human subjects (e.g., via Amazon MTurk) to evaluate their research claims directly. This subjective evaluation is cumbersome, unreproducible, and may impend the evolution of new research. In this work, we present a carefully-designed benchmark for evaluating talking-head video generation with standardized dataset pre-processing strategies. As for evaluation, we either propose new metrics or select the most appropriate ones to evaluate results in what we consider as desired properties for a good talking-head video, namely, identity preserving, lip synchronization, high video quality, and natural-spontaneous motion. By conducting a thoughtful analysis across several state-of-the-art talking-head generation approaches, we aim to uncover the merits and drawbacks of current methods and point out promising directions for future work. All the evaluation code is available at: https://github.com/lelechen63/talking-head-generation-survey.