 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-S: Image-Aligned Tactile Saliency for Robust Dexterous Manipulation
Jun 07, 2026Effective visuo-tactile integration is critical for robotic dexterous manipulation, especially when visual observations are unreliable or occluded. However, robustly aligning sparse, heterogeneous tactile measurements with dense visual representations remains a fundamental challenge. Most existing approaches require policies to learn cross-modal correspondences implicitly from limited demonstrations, without leveraging geometric priors. As a result, they are often data-inefficient and generalize poorly when visual observations are degraded. To address this limitation, we propose a framework that explicitly grounds physical contacts in the image domain. Using robot forward kinematics and camera calibration, we project tactile sensor locations directly onto the RGB image plane. We then render force-modulated Gaussian saliency maps to model spatial uncertainty arising from kinematic and calibration errors. By integrating these 2D spatial anchors through a zero-initialized conditioning architecture, our method injects physical contact priors into standard visual backbones while preserving pre-trained visual representations. We evaluate our method on six dexterous manipulation tasks in both simulation and the real world under severe visual occlusions. Real-world experiments show that explicit RGB-S grounding in the image domain improves real-world occluded manipulation success rates by $26.7$ percentage points over the strongest implicit visuo-tactile baseline, suggesting its improved spatial reasoning and robustness to occlusion. Project page: touch-as-saliency.github.io
Personalized Fashion Recommendation from Personal Social Media Data: An Item-to-Set Metric Learning Approach
May 25, 2020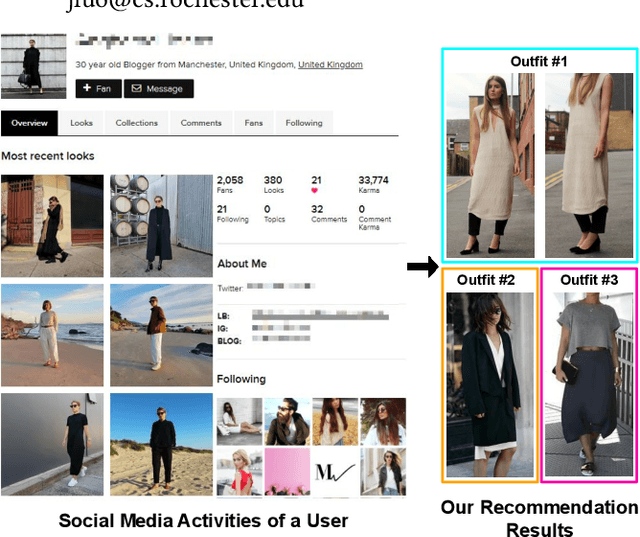
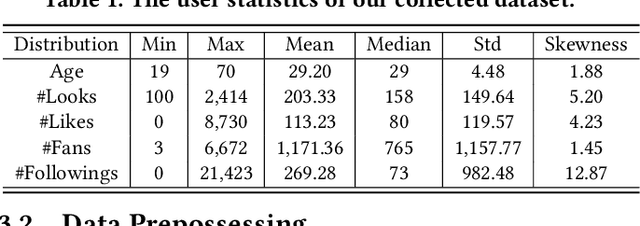
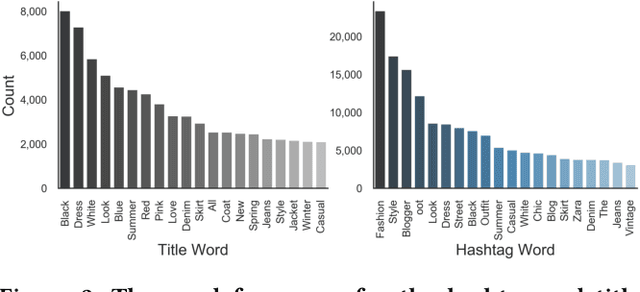
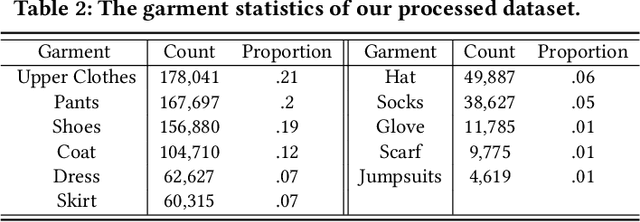
With the growth of online shopping for fashion products, accurate fashion recommendation has become a critical problem. Meanwhile, social networks provide an open and new data source for personalized fashion analysis. In this work, we study the problem of personalized fashion recommendation from social media data, i.e. recommending new outfits to social media users that fit their fashion preferences. To this end, we present an item-to-set metric learning framework that learns to compute the similarity between a set of historical fashion items of a user to a new fashion item. To extract features from multi-modal street-view fashion items, we propose an embedding module that performs multi-modality feature extraction and cross-modality gated fusion. To validate the effectiveness of our approach, we collect a real-world social media dataset. Extensive experiments on the collected dataset show the superior performance of our proposed approach.