 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024



Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.
4DRecons: 4D Neural Implicit Deformable Objects Reconstruction from a single RGB-D Camera with Geometrical and Topological Regularizations
Jun 14, 2024



This paper presents a novel approach 4DRecons that takes a single camera RGB-D sequence of a dynamic subject as input and outputs a complete textured deforming 3D model over time. 4DRecons encodes the output as a 4D neural implicit surface and presents an optimization procedure that combines a data term and two regularization terms. The data term fits the 4D implicit surface to the input partial observations. We address fundamental challenges in fitting a complete implicit surface to partial observations. The first regularization term enforces that the deformation among adjacent frames is as rigid as possible (ARAP). To this end, we introduce a novel approach to compute correspondences between adjacent textured implicit surfaces, which are used to define the ARAP regularization term. The second regularization term enforces that the topology of the underlying object remains fixed over time. This regularization is critical for avoiding self-intersections that are typical in implicit-based reconstructions. We have evaluated the performance of 4DRecons on a variety of datasets. Experimental results show that 4DRecons can handle large deformations and complex inter-part interactions and outperform state-of-the-art approaches considerably.
TIM: Temporal Interaction Model in Notification System
Jun 11, 2024



Modern mobile applications heavily rely on the notification system to acquire daily active users and enhance user engagement. Being able to proactively reach users, the system has to decide when to send notifications to users. Although many researchers have studied optimizing the timing of sending notifications, they only utilized users' contextual features, without modeling users' behavior patterns. Additionally, these efforts only focus on individual notifications, and there is a lack of studies on optimizing the holistic timing of multiple notifications within a period. To bridge these gaps, we propose the Temporal Interaction Model (TIM), which models users' behavior patterns by estimating CTR in every time slot over a day in our short video application Kuaishou. TIM leverages long-term user historical interaction sequence features such as notification receipts, clicks, watch time and effective views, and employs a temporal attention unit (TAU) to extract user behavior patterns. Moreover, we provide an elegant strategy of holistic notifications send time control to improve user engagement while minimizing disruption. We evaluate the effectiveness of TIM through offline experiments and online A/B tests. The results indicate that TIM is a reliable tool for forecasting user behavior, leading to a remarkable enhancement in user engagement without causing undue disturbance.
CoFie: Learning Compact Neural Surface Representations with Coordinate Fields
Jun 05, 2024



This paper introduces CoFie, a novel local geometry-aware neural surface representation. CoFie is motivated by the theoretical analysis of local SDFs with quadratic approximation. We find that local shapes are highly compressive in an aligned coordinate frame defined by the normal and tangent directions of local shapes. Accordingly, we introduce Coordinate Field, which is a composition of coordinate frames of all local shapes. The Coordinate Field is optimizable and is used to transform the local shapes from the world coordinate frame to the aligned shape coordinate frame. It largely reduces the complexity of local shapes and benefits the learning of MLP-based implicit representations. Moreover, we introduce quadratic layers into the MLP to enhance expressiveness concerning local shape geometry. CoFie is a generalizable surface representation. It is trained on a curated set of 3D shapes and works on novel shape instances during testing. When using the same amount of parameters with prior works, CoFie reduces the shape error by 48% and 56% on novel instances of both training and unseen shape categories. Moreover, CoFie demonstrates comparable performance to prior works when using only 70% fewer parameters.
Query-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.
GenCorres: Consistent Shape Matching via Coupled Implicit-Explicit Shape Generative Models
Apr 20, 2023



This paper introduces GenCorres, a novel unsupervised joint shape matching (JSM) approach. The basic idea of GenCorres is to learn a parametric mesh generator to fit an unorganized deformable shape collection while constraining deformations between adjacent synthetic shapes to preserve geometric structures such as local rigidity and local conformality. GenCorres presents three appealing advantages over existing JSM techniques. First, GenCorres performs JSM among a synthetic shape collection whose size is much bigger than the input shapes and fully leverages the data-driven power of JSM. Second, GenCorres unifies consistent shape matching and pairwise matching (i.e., by enforcing deformation priors between adjacent synthetic shapes). Third, the generator provides a concise encoding of consistent shape correspondences. However, learning a mesh generator from an unorganized shape collection is challenging. It requires a good initial fitting to each shape and can easily get trapped by local minimums. GenCorres addresses this issue by learning an implicit generator from the input shapes, which provides intermediate shapes between two arbitrary shapes. We introduce a novel approach for computing correspondences between adjacent implicit surfaces and force the correspondences to preserve geometric structures and be cycle-consistent. Synthetic shapes of the implicit generator then guide initial fittings (i.e., via template-based deformation) for learning the mesh generator. Experimental results show that GenCorres considerably outperforms state-of-the-art JSM techniques on benchmark datasets. The synthetic shapes of GenCorres preserve local geometric features and yield competitive performance gains against state-of-the-art deformable shape generators.
LiDAR-Based 3D Object Detection via Hybrid 2D Semantic Scene Generation
Apr 04, 2023Bird's-Eye View (BEV) features are popular intermediate scene representations shared by the 3D backbone and the detector head in LiDAR-based object detectors. However, little research has been done to investigate how to incorporate additional supervision on the BEV features to improve proposal generation in the detector head, while still balancing the number of powerful 3D layers and efficient 2D network operations. This paper proposes a novel scene representation that encodes both the semantics and geometry of the 3D environment in 2D, which serves as a dense supervision signal for better BEV feature learning. The key idea is to use auxiliary networks to predict a combination of explicit and implicit semantic probabilities by exploiting their complementary properties. Extensive experiments show that our simple yet effective design can be easily integrated into most state-of-the-art 3D object detectors and consistently improves upon baseline models.
AnyFlow: Arbitrary Scale Optical Flow with Implicit Neural Representation
Mar 29, 2023



To apply optical flow in practice, it is often necessary to resize the input to smaller dimensions in order to reduce computational costs. However, downsizing inputs makes the estimation more challenging because objects and motion ranges become smaller. Even though recent approaches have demonstrated high-quality flow estimation, they tend to fail to accurately model small objects and precise boundaries when the input resolution is lowered, restricting their applicability to high-resolution inputs. In this paper, we introduce AnyFlow, a robust network that estimates accurate flow from images of various resolutions. By representing optical flow as a continuous coordinate-based representation, AnyFlow generates outputs at arbitrary scales from low-resolution inputs, demonstrating superior performance over prior works in capturing tiny objects with detail preservation on a wide range of scenes. We establish a new state-of-the-art performance of cross-dataset generalization on the KITTI dataset, while achieving comparable accuracy on the online benchmarks to other SOTA methods.
Scene Synthesis via Uncertainty-Driven Attribute Synchronization
Sep 01, 2021
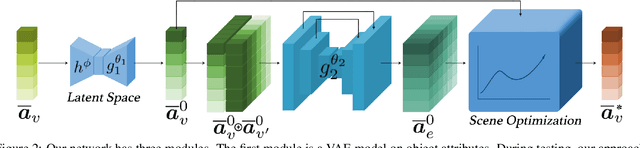


Developing deep neural networks to generate 3D scenes is a fundamental problem in neural synthesis with immediate applications in architectural CAD, computer graphics, as well as in generating virtual robot training environments. This task is challenging because 3D scenes exhibit diverse patterns, ranging from continuous ones, such as object sizes and the relative poses between pairs of shapes, to discrete patterns, such as occurrence and co-occurrence of objects with symmetrical relationships. This paper introduces a novel neural scene synthesis approach that can capture diverse feature patterns of 3D scenes. Our method combines the strength of both neural network-based and conventional scene synthesis approaches. We use the parametric prior distributions learned from training data, which provide uncertainties of object attributes and relative attributes, to regularize the outputs of feed-forward neural models. Moreover, instead of merely predicting a scene layout, our approach predicts an over-complete set of attributes. This methodology allows us to utilize the underlying consistency constraints among the predicted attributes to prune infeasible predictions. Experimental results show that our approach outperforms existing methods considerably. The generated 3D scenes interpolate the training data faithfully while preserving both continuous and discrete feature patterns.