 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPRA: Predicting an LLM-Judge for Efficient but Performant Inference
Apr 14, 2026Large language models (LLMs) face a fundamental trade-off between computational efficiency (e.g., number of parameters) and output quality, especially when deployed on computationally limited devices such as phones or laptops. One way to address this challenge is by following the example of humans and have models ask for help when they believe they are incapable of solving a problem on their own; we can overcome this trade-off by allowing smaller models to respond to queries when they believe they can provide good responses, and deferring to larger models when they do not believe they can. To this end, in this paper, we investigate the viability of Predict-Answer/Act (PA) and Reason-Predict-Reason-Answer/Act (RPRA) paradigms where models predict -- prior to responding -- how an LLM judge would score their output. We evaluate three approaches: zero-shot prediction, prediction using an in-context report card, and supervised fine-tuning. Our results show that larger models (particularly reasoning models) perform well when predicting generic LLM judges zero-shot, while smaller models can reliably predict such judges well after being fine-tuned or provided with an in-context report card. Altogether, both approaches can substantially improve the prediction accuracy of smaller models, with report cards and fine-tuning achieving mean improvements of up to 55% and 52% across datasets, respectively. These findings suggest that models can learn to predict their own performance limitations, paving the way for more efficient and self-aware AI systems.
Free-Range Gaussians: Non-Grid-Aligned Generative 3D Gaussian Reconstruction
Apr 06, 2026We present Free-Range Gaussians, a multi-view reconstruction method that predicts non-pixel, non-voxel-aligned 3D Gaussians from as few as four images. This is done through flow matching over Gaussian parameters. Our generative formulation of reconstruction allows the model to be supervised with non-grid-aligned 3D data, and enables it to synthesize plausible content in unobserved regions. Thus, it improves on prior methods that produce highly redundant grid-aligned Gaussians, and suffer from holes or blurry conditional means in unobserved regions. To handle the number of Gaussians needed for high-quality results, we introduce a hierarchical patching scheme to group spatially related Gaussians into joint transformer tokens, halving the sequence length while preserving structure. We further propose a timestep-weighted rendering loss during training, and photometric gradient guidance and classifier-free guidance at inference to improve fidelity. Experiments on Objaverse and Google Scanned Objects show consistent improvements over pixel and voxel-aligned methods while using significantly fewer Gaussians, with large gains when input views leave parts of the object unobserved.
LaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
Discontinuity-aware Normal Integration for Generic Central Camera Models
Jul 08, 2025



Recovering a 3D surface from its surface normal map, a problem known as normal integration, is a key component for photometric shape reconstruction techniques such as shape-from-shading and photometric stereo. The vast majority of existing approaches for normal integration handle only implicitly the presence of depth discontinuities and are limited to orthographic or ideal pinhole cameras. In this paper, we propose a novel formulation that allows modeling discontinuities explicitly and handling generic central cameras. Our key idea is based on a local planarity assumption, that we model through constraints between surface normals and ray directions. Compared to existing methods, our approach more accurately approximates the relation between depth and surface normals, achieves state-of-the-art results on the standard normal integration benchmark, and is the first to directly handle generic central camera models.
MMG-Ego4D: Multi-Modal Generalization in Egocentric Action Recognition
May 12, 2023



In this paper, we study a novel problem in egocentric action recognition, which we term as "Multimodal Generalization" (MMG). MMG aims to study how systems can generalize when data from certain modalities is limited or even completely missing. We thoroughly investigate MMG in the context of standard supervised action recognition and the more challenging few-shot setting for learning new action categories. MMG consists of two novel scenarios, designed to support security, and efficiency considerations in real-world applications: (1) missing modality generalization where some modalities that were present during the train time are missing during the inference time, and (2) cross-modal zero-shot generalization, where the modalities present during the inference time and the training time are disjoint. To enable this investigation, we construct a new dataset MMG-Ego4D containing data points with video, audio, and inertial motion sensor (IMU) modalities. Our dataset is derived from Ego4D dataset, but processed and thoroughly re-annotated by human experts to facilitate research in the MMG problem. We evaluate a diverse array of models on MMG-Ego4D and propose new methods with improved generalization ability. In particular, we introduce a new fusion module with modality dropout training, contrastive-based alignment training, and a novel cross-modal prototypical loss for better few-shot performance. We hope this study will serve as a benchmark and guide future research in multimodal generalization problems. The benchmark and code will be available at https://github.com/facebookresearch/MMG_Ego4D.
HeadPosr: End-to-end Trainable Head Pose Estimation using Transformer Encoders
Feb 07, 2022



In this paper, HeadPosr is proposed to predict the head poses using a single RGB image. \textit{HeadPosr} uses a novel architecture which includes a transformer encoder. In concrete, it consists of: (1) backbone; (2) connector; (3) transformer encoder; (4) prediction head. The significance of using a transformer encoder for HPE is studied. An extensive ablation study is performed on varying the (1) number of encoders; (2) number of heads; (3) different position embeddings; (4) different activations; (5) input channel size, in a transformer used in HeadPosr. Further studies on using: (1) different backbones, (2) using different learning rates are also shown. The elaborated experiments and ablations studies are conducted using three different open-source widely used datasets for HPE, i.e., 300W-LP, AFLW2000, and BIWI datasets. Experiments illustrate that \textit{HeadPosr} outperforms all the state-of-art methods including both the landmark-free and the others based on using landmark or depth estimation on the AFLW2000 dataset and BIWI datasets when trained with 300W-LP. It also outperforms when averaging the results from the compared datasets, hence setting a benchmark for the problem of HPE, also demonstrating the effectiveness of using transformers over the state-of-the-art.
* 8 pages, 4 figures
LwPosr: Lightweight Efficient Fine-Grained Head Pose Estimation
Feb 07, 2022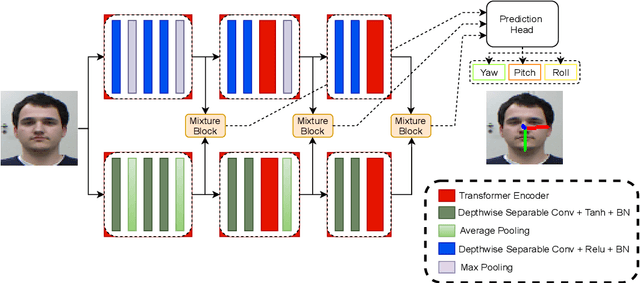
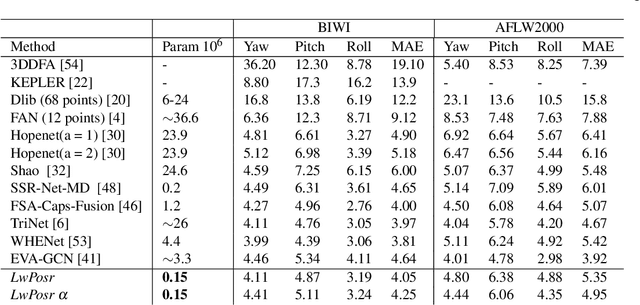
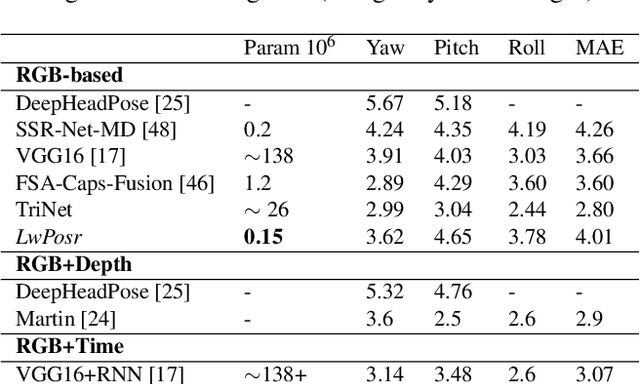
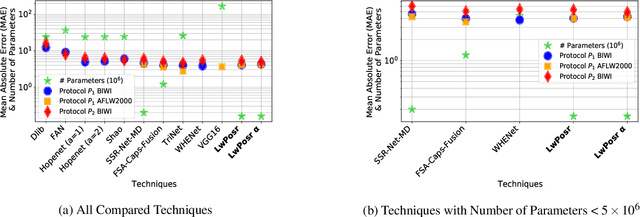
This paper presents a lightweight network for head pose estimation (HPE) task. While previous approaches rely on convolutional neural networks, the proposed network \textit{LwPosr} uses mixture of depthwise separable convolutional (DSC) and transformer encoder layers which are structured in two streams and three stages to provide fine-grained regression for predicting head poses. The quantitative and qualitative demonstration is provided to show that the proposed network is able to learn head poses efficiently while using less parameter space. Extensive ablations are conducted using three open-source datasets namely 300W-LP, AFLW2000, and BIWI datasets. To our knowledge, (1) \textit{LwPosr} is the lightest network proposed for estimating head poses compared to both keypoints-based and keypoints-free approaches; (2) it sets a benchmark for both overperforming the previous lightweight network on mean absolute error and on reducing number of parameters; (3) it is first of its kind to use mixture of DSCs and transformer encoders for HPE. This approach is suitable for mobile devices which require lightweight networks.
* 11 pages, 3 figures
Border-SegGCN: Improving Semantic Segmentation by Refining the Border Outline using Graph Convolutional Network
Sep 11, 2021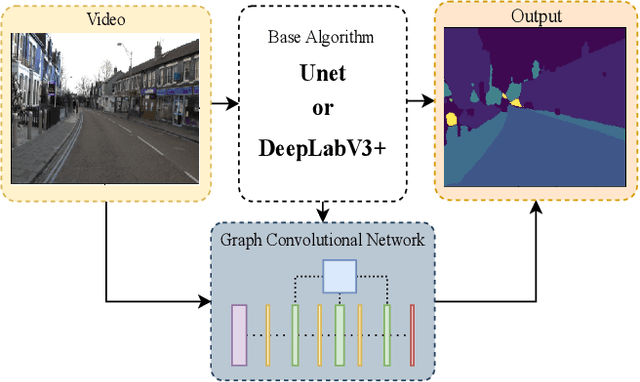
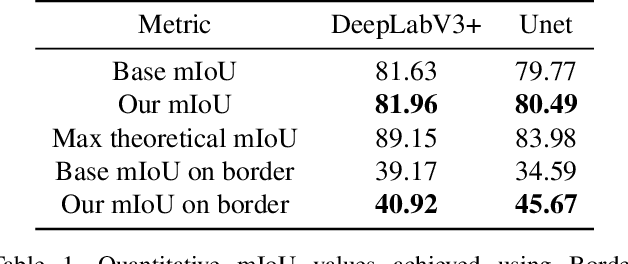
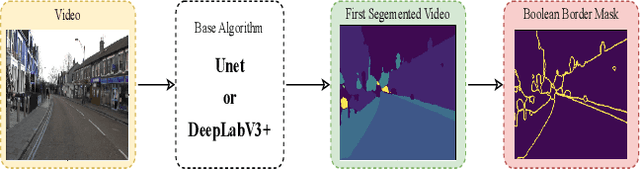
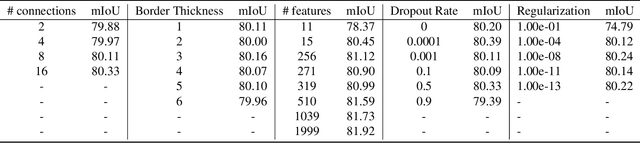
We present Border-SegGCN, a novel architecture to improve semantic segmentation by refining the border outline using graph convolutional networks (GCN). The semantic segmentation network such as Unet or DeepLabV3+ is used as a base network to have pre-segmented output. This output is converted into a graphical structure and fed into the GCN to improve the border pixel prediction of the pre-segmented output. We explored and studied the factors such as border thickness, number of edges for a node, and the number of features to be fed into the GCN by performing experiments. We demonstrate the effectiveness of the Border-SegGCN on the CamVid and Carla dataset, achieving a test set performance of 81.96% without any post-processing on CamVid dataset. It is higher than the reported state of the art mIoU achieved on CamVid dataset by 0.404%
BGT-Net: Bidirectional GRU Transformer Network for Scene Graph Generation
Sep 11, 2021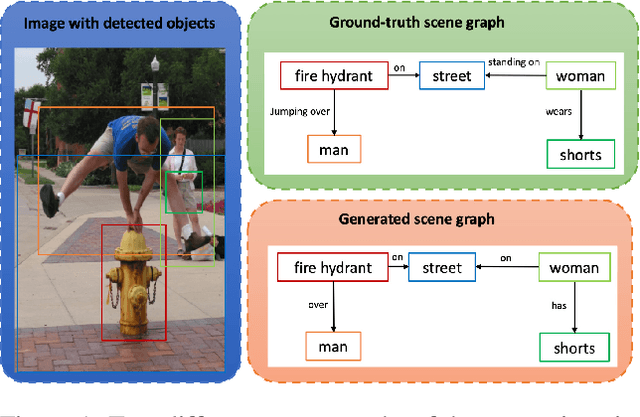
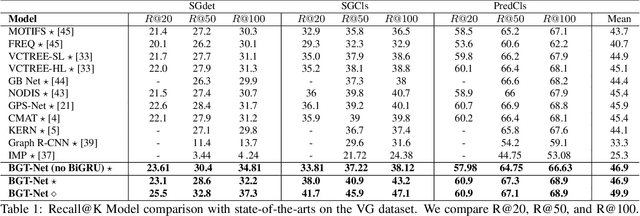
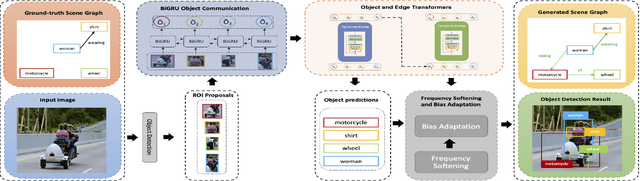
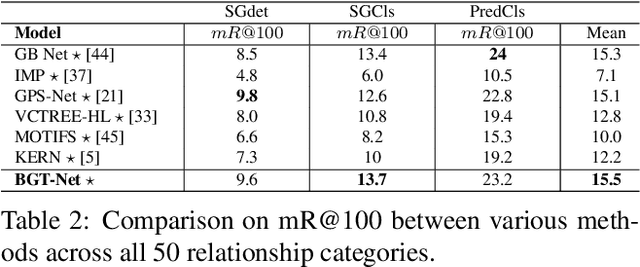
Scene graphs are nodes and edges consisting of objects and object-object relationships, respectively. Scene graph generation (SGG) aims to identify the objects and their relationships. We propose a bidirectional GRU (BiGRU) transformer network (BGT-Net) for the scene graph generation for images. This model implements novel object-object communication to enhance the object information using a BiGRU layer. Thus, the information of all objects in the image is available for the other objects, which can be leveraged later in the object prediction step. This object information is used in a transformer encoder to predict the object class as well as to create object-specific edge information via the use of another transformer encoder. To handle the dataset bias induced by the long-tailed relationship distribution, softening with a log-softmax function and adding a bias adaptation term to regulate the bias for every relation prediction individually showed to be an effective approach. We conducted an elaborate study on experiments and ablations using open-source datasets, i.e., Visual Genome, Open-Images, and Visual Relationship Detection datasets, demonstrating the effectiveness of the proposed model over state of the art.
* 8 pages, 7 supplementary pages
Recognition and Localisation of Pointing Gestures using a RGB-D Camera
Jan 10, 2020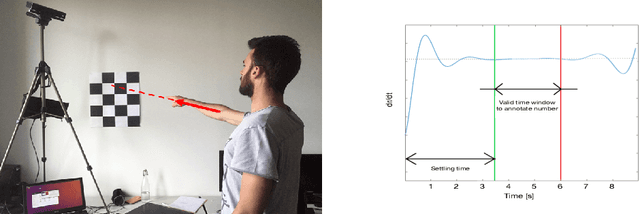


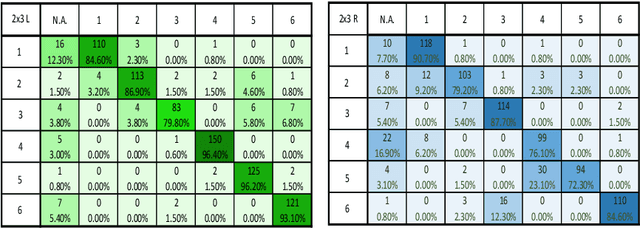
Non-verbal communication is part of our regular conversation, and multiple gestures are used to exchange information. Among those gestures, pointing is the most important one. If such gestures cannot be perceived by other team members, e.g. by blind and visually impaired people (BVIP), they lack important information and can hardly participate in a lively workflow. Thus, this paper describes a system for detecting such pointing gestures to provide input for suitable output modalities to BVIP. Our system employs an RGB-D camera to recognize the pointing gestures performed by the users. The system also locates the target of pointing e.g. on a common workspace. We evaluated the system by conducting a user study with 26 users. The results show that the system has a success rate of 89.59 and 79.92 % for a 2 x 3 matrix using the left and right arm respectively, and 73.57 and 68.99 % for 3 x 4 matrix using the left and right arm respectively.