 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2CoPre: Energy Efficient and Cooperative Collision Avoidance for UAV Swarms with Trajectory Prediction
Mar 11, 2023This paper addresses the collision avoidance problem of UAV swarms in three-dimensional (3D) space. The key challenges are energy efficiency and cooperation of swarm members. We propose to combine Artificial Potential Field (APF) with Particle Swarm Planning (PSO). APF provides environmental awareness and implicit coordination to UAVs. PSO searches for the optimal trajectories for each UAV in terms of safety and energy efficiency by minimizing a fitness function. The fitness function exploits the advantages of the Active Contour Model in image processing for trajectory planning. Lastly, vehicle-to-vehicle collisions are detected in advance based on trajectory prediction and are resolved by cooperatively adjusting the altitude of UAVs. Simulation results demonstrate that our method can save up to 80\% of energy compared to state-of-the-art schemes.
WRHT: Efficient All-reduce for Distributed DNN Training in Optical Interconnect System
Jul 22, 2022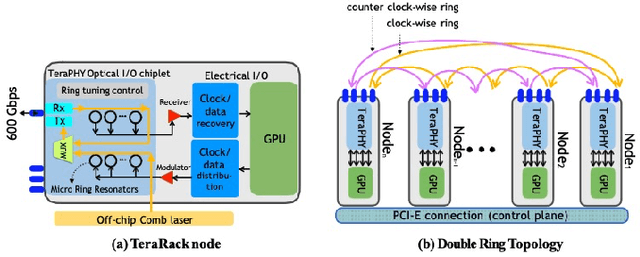
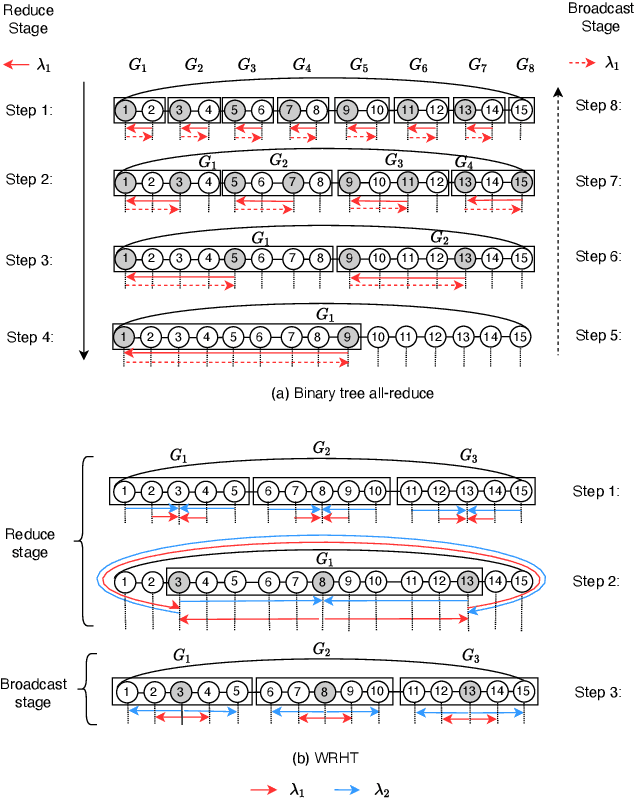
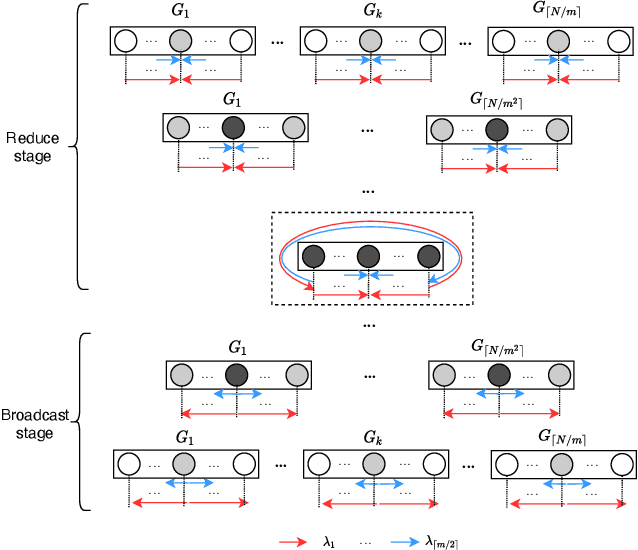
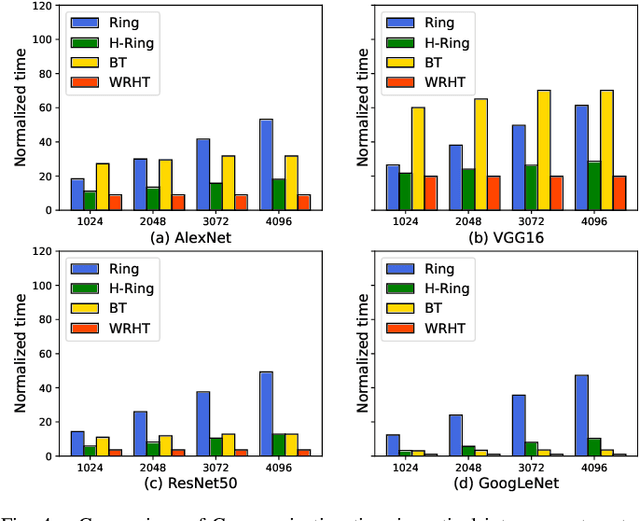
Communication efficiency plays an important role in accelerating the distributed training of Deep Neural Networks (DNN). All-reduce is the key communication primitive to reduce model parameters in distributed DNN training. Most existing all-reduce algorithms are designed for traditional electrical interconnect systems, which cannot meet the communication requirements for distributed training of large DNNs. One of the promising alternatives for electrical interconnect is optical interconnect, which can provide high bandwidth, low transmission delay, and low power cost. We propose an efficient scheme called WRHT (Wavelength Reused Hierarchical Tree) for implementing all-reduce operation in optical interconnect system, which can take advantage of WDM (Wavelength Division Multiplexing) to reduce the communication time of distributed data-parallel DNN training. We further derive the minimum number of communication steps and communication time to realize the all-reduce using WRHT. Simulation results show that the communication time of WRHT is reduced by 75.59%, 49.25%, and 70.1% respectively compared with three traditional all-reduce algorithms simulated in optical interconnect system. Simulation results also show that WRHT can reduce the communication time for all-reduce operation by 86.69% and 84.71% in comparison with two existing all-reduce algorithms in electrical interconnect system.
Attention Mechanism with Energy-Friendly Operations
Apr 28, 2022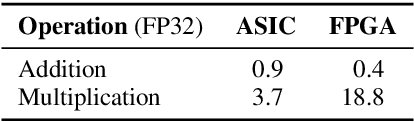
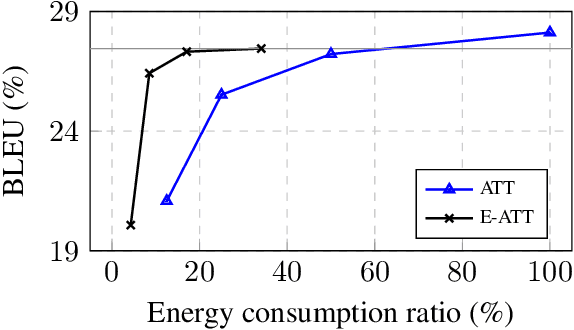
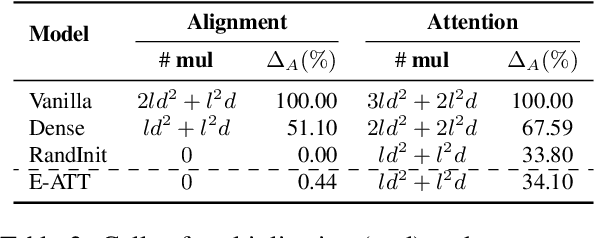
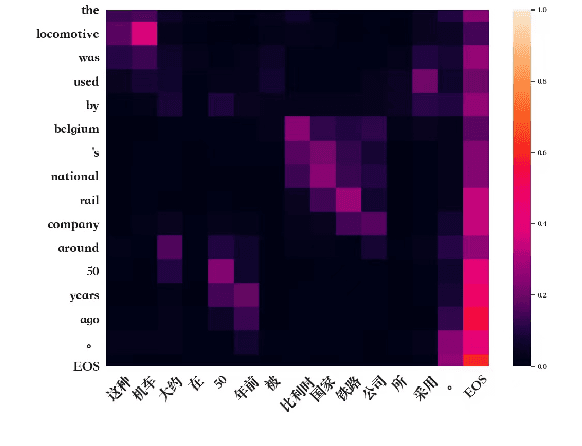
Attention mechanism has become the dominant module in natural language processing models. It is computationally intensive and depends on massive power-hungry multiplications. In this paper, we rethink variants of attention mechanism from the energy consumption aspects. After reaching the conclusion that the energy costs of several energy-friendly operations are far less than their multiplication counterparts, we build a novel attention model by replacing multiplications with either selective operations or additions. Empirical results on three machine translation tasks demonstrate that the proposed model, against the vanilla one, achieves competitable accuracy while saving 99\% and 66\% energy during alignment calculation and the whole attention procedure. Code is available at: https://github.com/NLP2CT/E-Att.
RoBLEURT Submission for the WMT2021 Metrics Task
Apr 28, 2022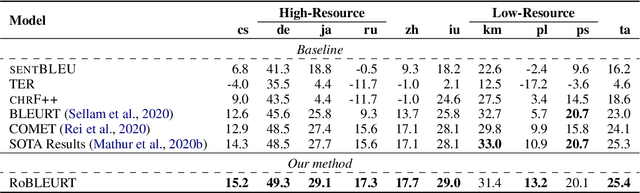

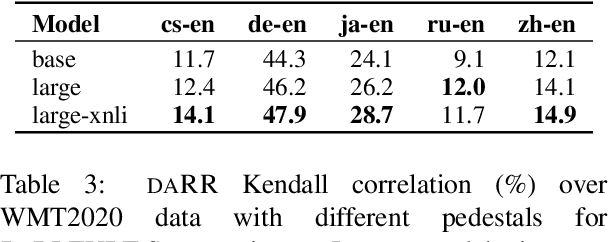
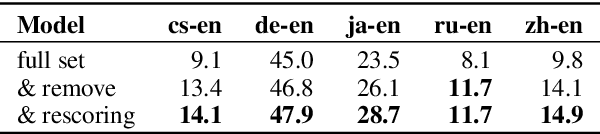
In this paper, we present our submission to Shared Metrics Task: RoBLEURT (Robustly Optimizing the training of BLEURT). After investigating the recent advances of trainable metrics, we conclude several aspects of vital importance to obtain a well-performed metric model by: 1) jointly leveraging the advantages of source-included model and reference-only model, 2) continuously pre-training the model with massive synthetic data pairs, and 3) fine-tuning the model with data denoising strategy. Experimental results show that our model reaching state-of-the-art correlations with the WMT2020 human annotations upon 8 out of 10 to-English language pairs.
UniTE: Unified Translation Evaluation
Apr 28, 2022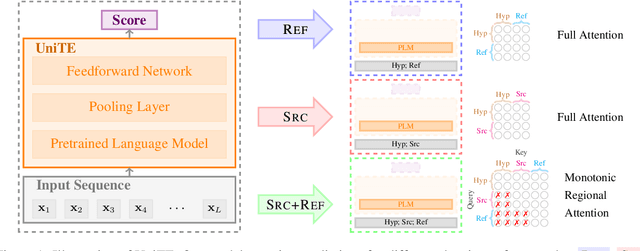
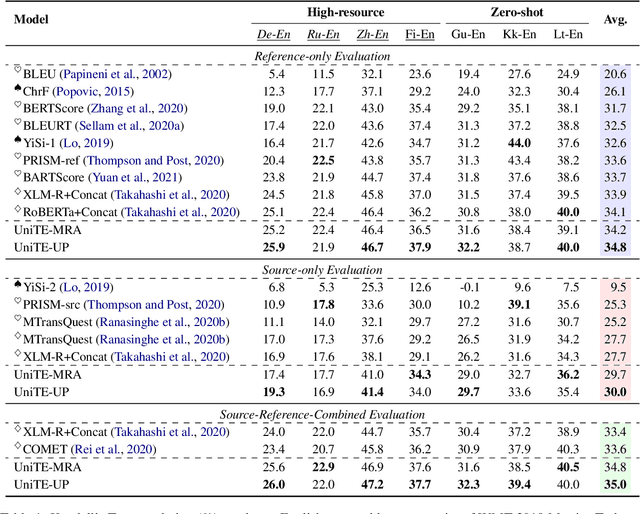
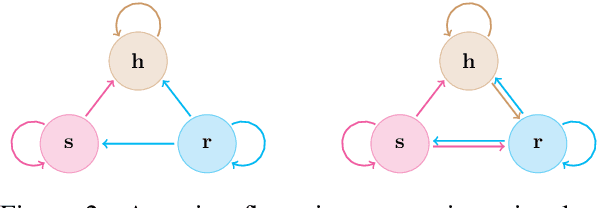
Translation quality evaluation plays a crucial role in machine translation. According to the input format, it is mainly separated into three tasks, i.e., reference-only, source-only and source-reference-combined. Recent methods, despite their promising results, are specifically designed and optimized on one of them. This limits the convenience of these methods, and overlooks the commonalities among tasks. In this paper, we propose UniTE, which is the first unified framework engaged with abilities to handle all three evaluation tasks. Concretely, we propose monotonic regional attention to control the interaction among input segments, and unified pretraining to better adapt multi-task learning. We testify our framework on WMT 2019 Metrics and WMT 2020 Quality Estimation benchmarks. Extensive analyses show that our \textit{single model} can universally surpass various state-of-the-art or winner methods across tasks. Both source code and associated models are available at https://github.com/NLP2CT/UniTE.
Multi-UAV Collision Avoidance using Multi-Agent Reinforcement Learning with Counterfactual Credit Assignment
Apr 19, 2022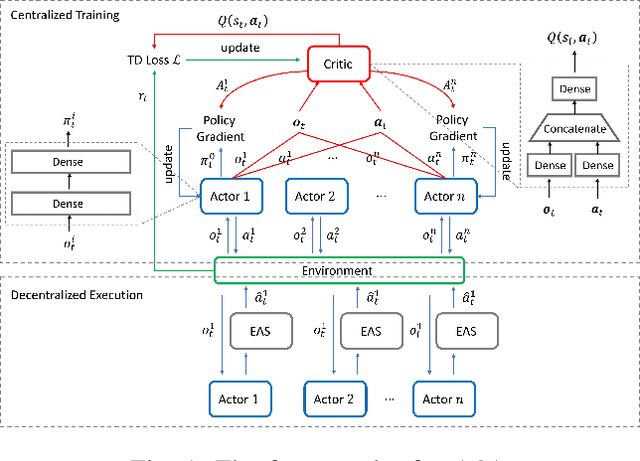

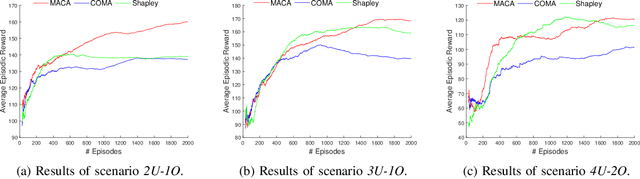
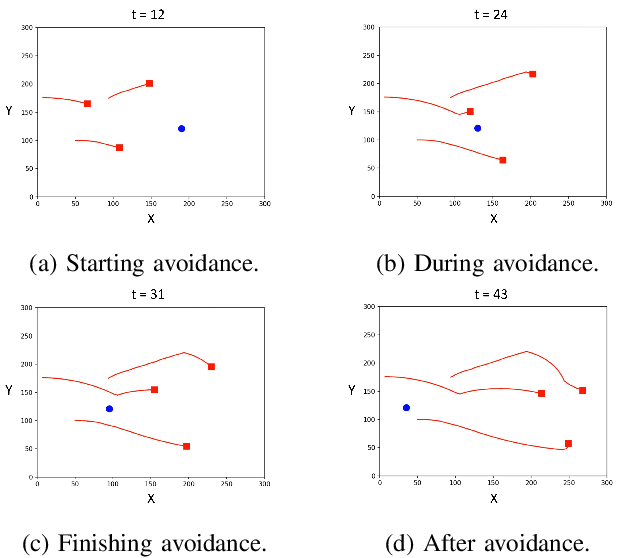
Multi-UAV collision avoidance is a challenging task for UAV swarm applications due to the need of tight cooperation among swarm members for collision-free path planning. Centralized Training with Decentralized Execution (CTDE) in Multi-Agent Reinforcement Learning is a promising method for multi-UAV collision avoidance, in which the key challenge is to effectively learn decentralized policies that can maximize a global reward cooperatively. We propose a new multi-agent critic-actor learning scheme called MACA for UAV swarm collision avoidance. MACA uses a centralized critic to maximize the discounted global reward that considers both safety and energy efficiency, and an actor per UAV to find decentralized policies to avoid collisions. To solve the credit assignment problem in CTDE, we design a counterfactual baseline that marginalizes both an agent's state and action, enabling to evaluate the importance of an agent in the joint observation-action space. To train and evaluate MACA, we design our own simulation environment MACAEnv to closely mimic the realistic behaviors of a UAV swarm. Simulation results show that MACA achieves more than 16% higher average reward than two state-of-the-art MARL algorithms and reduces failure rate by 90% and response time by over 99% compared to a conventional UAV swarm collision avoidance algorithm in all test scenarios.
Frequency-Aware Contrastive Learning for Neural Machine Translation
Dec 29, 2021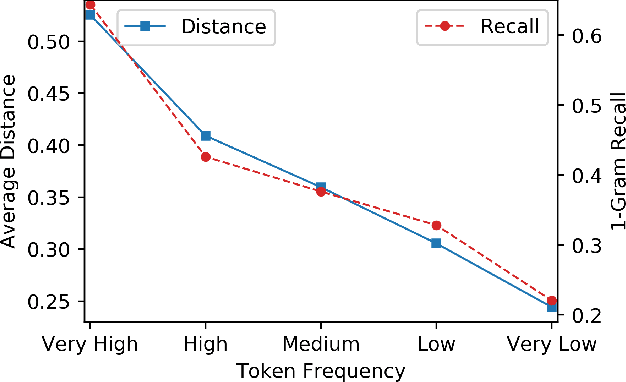
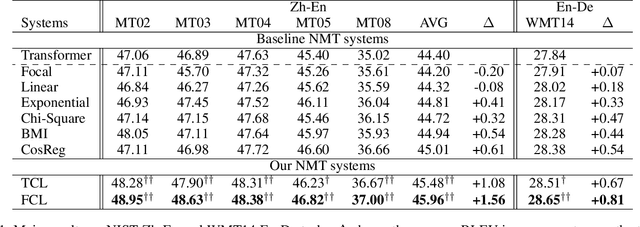
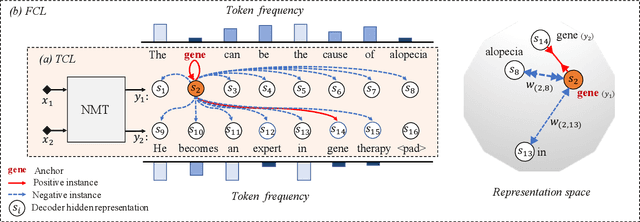
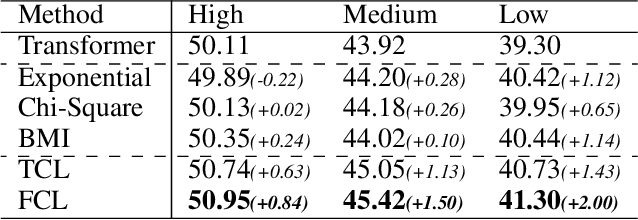
Low-frequency word prediction remains a challenge in modern neural machine translation (NMT) systems. Recent adaptive training methods promote the output of infrequent words by emphasizing their weights in the overall training objectives. Despite the improved recall of low-frequency words, their prediction precision is unexpectedly hindered by the adaptive objectives. Inspired by the observation that low-frequency words form a more compact embedding space, we tackle this challenge from a representation learning perspective. Specifically, we propose a frequency-aware token-level contrastive learning method, in which the hidden state of each decoding step is pushed away from the counterparts of other target words, in a soft contrastive way based on the corresponding word frequencies. We conduct experiments on widely used NIST Chinese-English and WMT14 English-German translation tasks. Empirical results show that our proposed methods can not only significantly improve the translation quality but also enhance lexical diversity and optimize word representation space. Further investigation reveals that, comparing with related adaptive training strategies, the superiority of our method on low-frequency word prediction lies in the robustness of token-level recall across different frequencies without sacrificing precision.
KGR^4: Retrieval, Retrospect, Refine and Rethink for Commonsense Generation
Dec 15, 2021
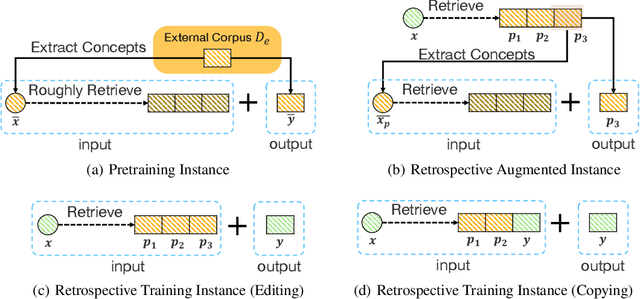
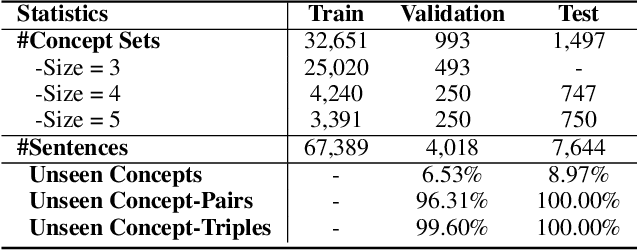
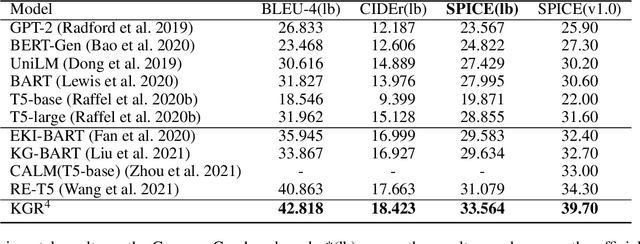
Generative commonsense reasoning requires machines to generate sentences describing an everyday scenario given several concepts, which has attracted much attention recently. However, existing models cannot perform as well as humans, since sentences they produce are often implausible and grammatically incorrect. In this paper, inspired by the process of humans creating sentences, we propose a novel Knowledge-enhanced Commonsense Generation framework, termed KGR^4, consisting of four stages: Retrieval, Retrospect, Refine, Rethink. Under this framework, we first perform retrieval to search for relevant sentences from external corpus as the prototypes. Then, we train the generator that either edits or copies these prototypes to generate candidate sentences, of which potential errors will be fixed by an autoencoder-based refiner. Finally, we select the output sentence from candidate sentences produced by generators with different hyper-parameters. Experimental results and in-depth analysis on the CommonGen benchmark strongly demonstrate the effectiveness of our framework. Particularly, KGR^4 obtains 33.56 SPICE points in the official leaderboard, outperforming the previously-reported best result by 2.49 SPICE points and achieving state-of-the-art performance.
Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Nov 03, 2021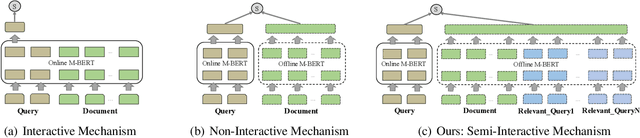
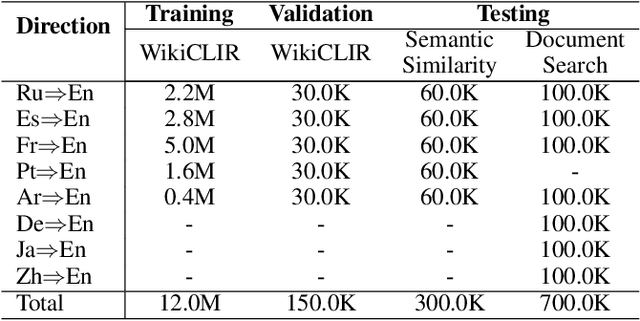
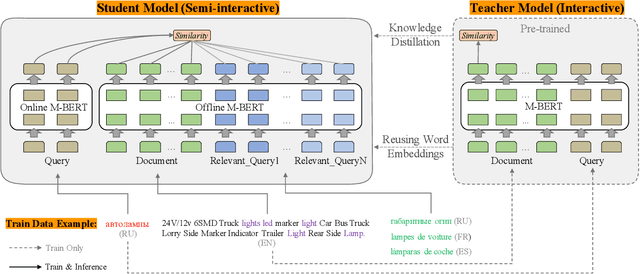

Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency.
Accelerating Fully Connected Neural Network on Optical Network-on-Chip (ONoC)
Sep 30, 2021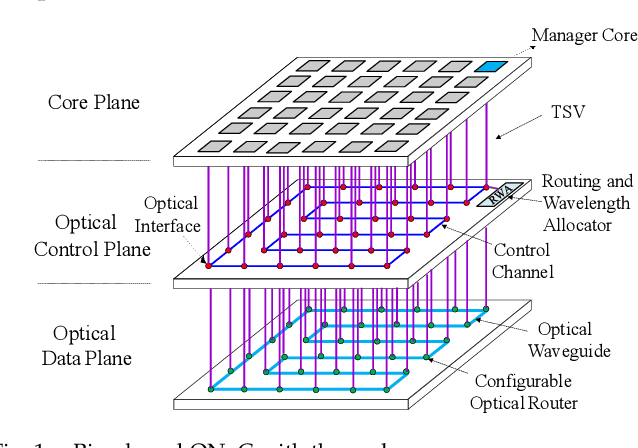

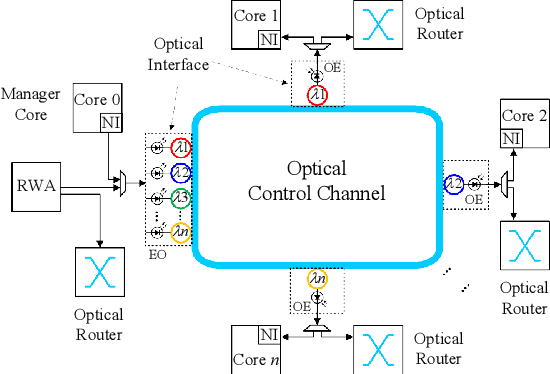
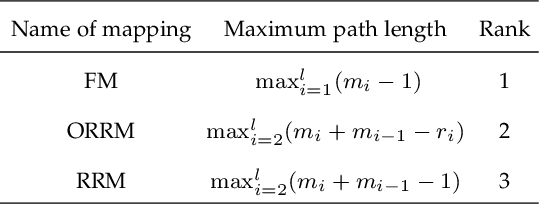
Fully Connected Neural Network (FCNN) is a class of Artificial Neural Networks widely used in computer science and engineering, whereas the training process can take a long time with large datasets in existing many-core systems. Optical Network-on-Chip (ONoC), an emerging chip-scale optical interconnection technology, has great potential to accelerate the training of FCNN with low transmission delay, low power consumption, and high throughput. However, existing methods based on Electrical Network-on-Chip (ENoC) cannot fit in ONoC because of the unique properties of ONoC. In this paper, we propose a fine-grained parallel computing model for accelerating FCNN training on ONoC and derive the optimal number of cores for each execution stage with the objective of minimizing the total amount of time to complete one epoch of FCNN training. To allocate the optimal number of cores for each execution stage, we present three mapping strategies and compare their advantages and disadvantages in terms of hotspot level, memory requirement, and state transitions. Simulation results show that the average prediction error for the optimal number of cores in NN benchmarks is within 2.3%. We further carry out extensive simulations which demonstrate that FCNN training time can be reduced by 22.28% and 4.91% on average using our proposed scheme, compared with traditional parallel computing methods that either allocate a fixed number of cores or allocate as many cores as possible, respectively. Compared with ENoC, simulation results show that under batch sizes of 64 and 128, on average ONoC can achieve 21.02% and 12.95% on reducing training time with 47.85% and 39.27% on saving energy, respectively.