 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Content Complementation Network for Salient Object Detection in Optical Remote Sensing Images
Dec 02, 2021
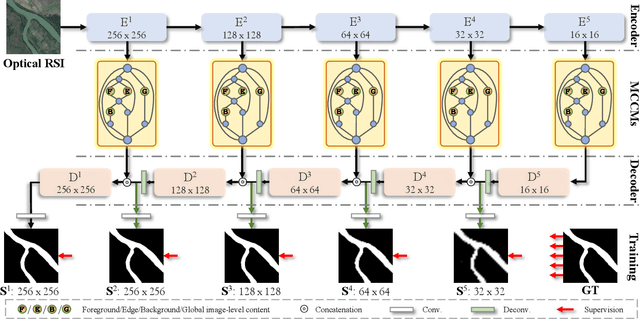
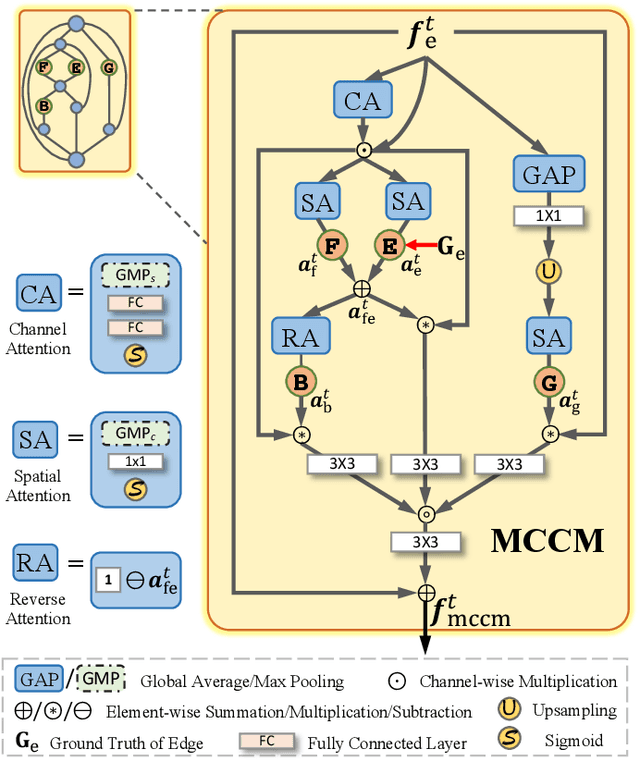
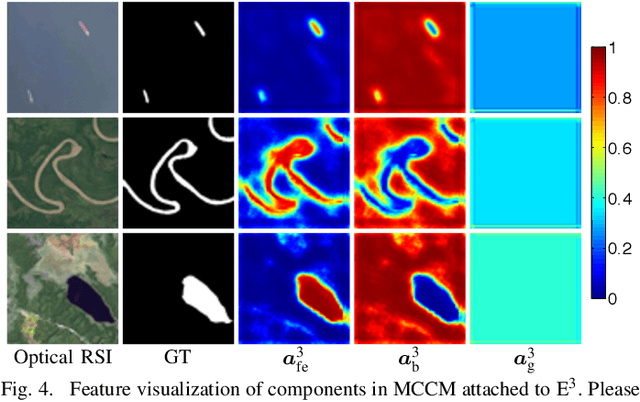
In the computer vision community, great progresses have been achieved in salient object detection from natural scene images (NSI-SOD); by contrast, salient object detection in optical remote sensing images (RSI-SOD) remains to be a challenging emerging topic. The unique characteristics of optical RSIs, such as scales, illuminations and imaging orientations, bring significant differences between NSI-SOD and RSI-SOD. In this paper, we propose a novel Multi-Content Complementation Network (MCCNet) to explore the complementarity of multiple content for RSI-SOD. Specifically, MCCNet is based on the general encoder-decoder architecture, and contains a novel key component named Multi-Content Complementation Module (MCCM), which bridges the encoder and the decoder. In MCCM, we consider multiple types of features that are critical to RSI-SOD, including foreground features, edge features, background features, and global image-level features, and exploit the content complementarity between them to highlight salient regions over various scales in RSI features through the attention mechanism. Besides, we comprehensively introduce pixel-level, map-level and metric-aware losses in the training phase. Extensive experiments on two popular datasets demonstrate that the proposed MCCNet outperforms 23 state-of-the-art methods, including both NSI-SOD and RSI-SOD methods. The code and results of our method are available at https://github.com/MathLee/MCCNet.
Searching the Search Space of Vision Transformer
Nov 29, 2021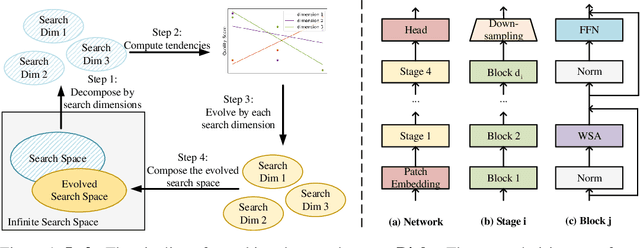
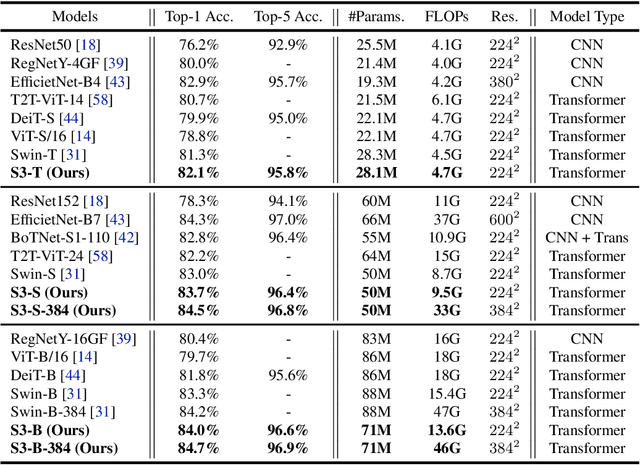
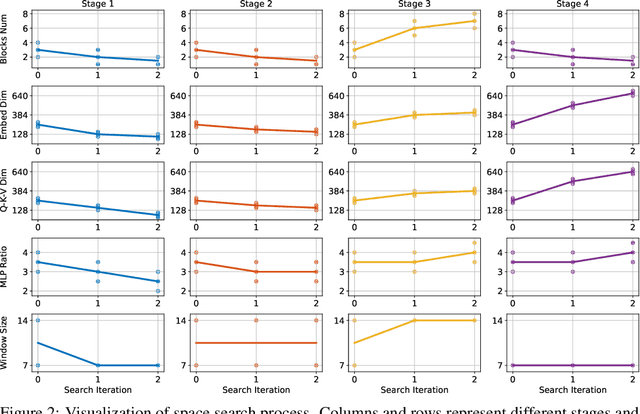
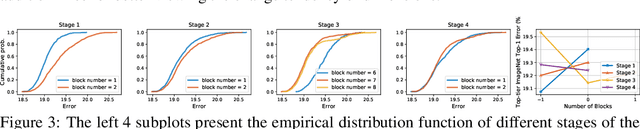
Vision Transformer has shown great visual representation power in substantial vision tasks such as recognition and detection, and thus been attracting fast-growing efforts on manually designing more effective architectures. In this paper, we propose to use neural architecture search to automate this process, by searching not only the architecture but also the search space. The central idea is to gradually evolve different search dimensions guided by their E-T Error computed using a weight-sharing supernet. Moreover, we provide design guidelines of general vision transformers with extensive analysis according to the space searching process, which could promote the understanding of vision transformer. Remarkably, the searched models, named S3 (short for Searching the Search Space), from the searched space achieve superior performance to recently proposed models, such as Swin, DeiT and ViT, when evaluated on ImageNet. The effectiveness of S3 is also illustrated on object detection, semantic segmentation and visual question answering, demonstrating its generality to downstream vision and vision-language tasks. Code and models will be available at https://github.com/microsoft/Cream.
Osteoporosis Prescreening using Panoramic Radiographs through a Deep Convolutional Neural Network with Attention Mechanism
Oct 19, 2021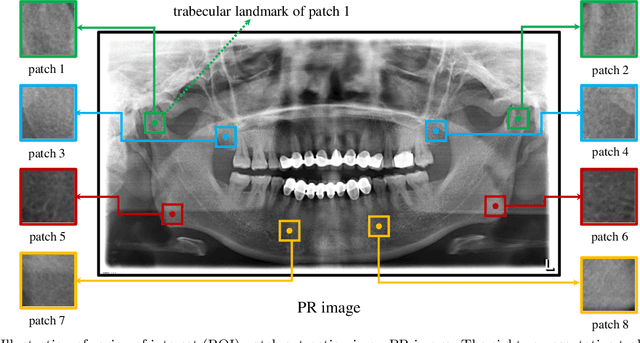
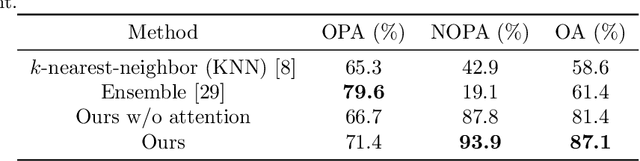
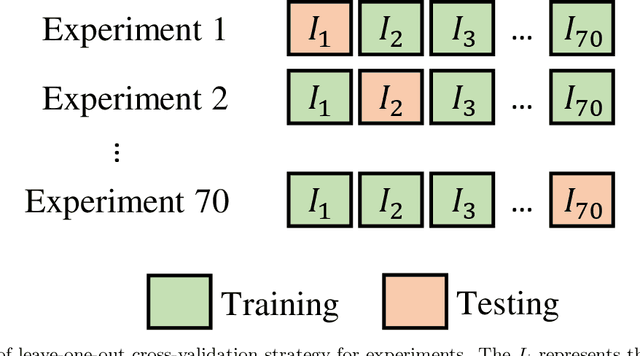
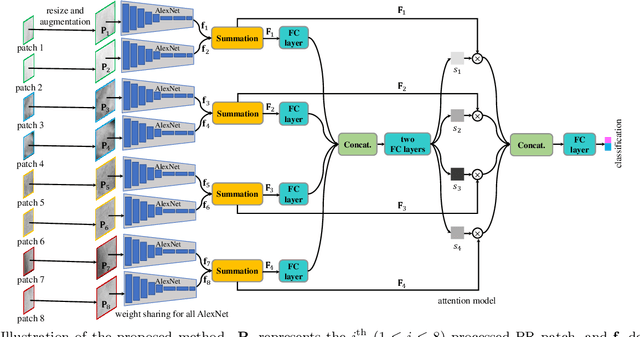
Objectives. The aim of this study was to investigate whether a deep convolutional neural network (CNN) with an attention module can detect osteoporosis on panoramic radiographs. Study Design. A dataset of 70 panoramic radiographs (PRs) from 70 different subjects of age between 49 to 60 was used, including 49 subjects with osteoporosis and 21 normal subjects. We utilized the leave-one-out cross-validation approach to generate 70 training and test splits. Specifically, for each split, one image was used for testing and the remaining 69 images were used for training. A deep convolutional neural network (CNN) using the Siamese architecture was implemented through a fine-tuning process to classify an PR image using patches extracted from eight representative trabecula bone areas (Figure 1). In order to automatically learn the importance of different PR patches, an attention module was integrated into the deep CNN. Three metrics, including osteoporosis accuracy (OPA), non-osteoporosis accuracy (NOPA) and overall accuracy (OA), were utilized for performance evaluation. Results. The proposed baseline CNN approach achieved the OPA, NOPA and OA scores of 0.667, 0.878 and 0.814, respectively. With the help of the attention module, the OPA, NOPA and OA scores were further improved to 0.714, 0.939 and 0.871, respectively. Conclusions. The proposed method obtained promising results using deep CNN with an attention module, which might be applied to osteoporosis prescreening.
Deep Learning Approach Protecting Privacy in Camera-Based Critical Applications
Oct 04, 2021

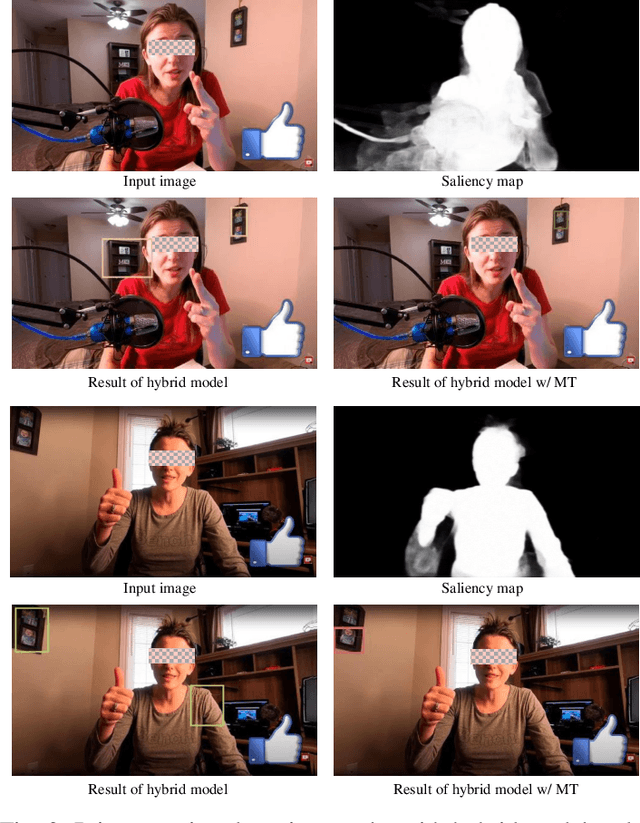

Many critical applications rely on cameras to capture video footage for analytical purposes. This has led to concerns about these cameras accidentally capturing more information than is necessary. In this paper, we propose a deep learning approach towards protecting privacy in camera-based systems. Instead of specifying specific objects (e.g. faces) are privacy sensitive, our technique distinguishes between salient (visually prominent) and non-salient objects based on the intuition that the latter is unlikely to be needed by the application.
Joint Graph Learning and Matching for Semantic Feature Correspondence
Sep 01, 2021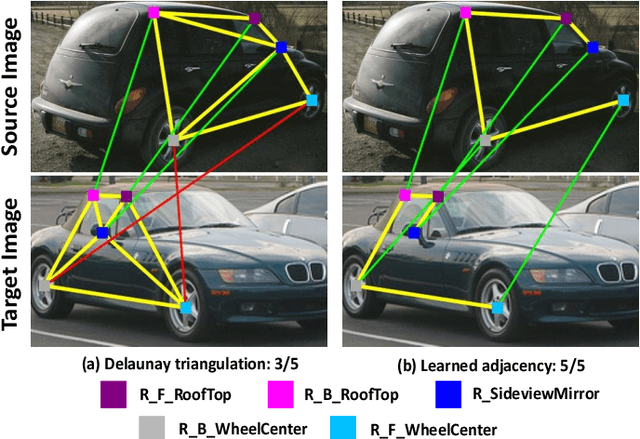

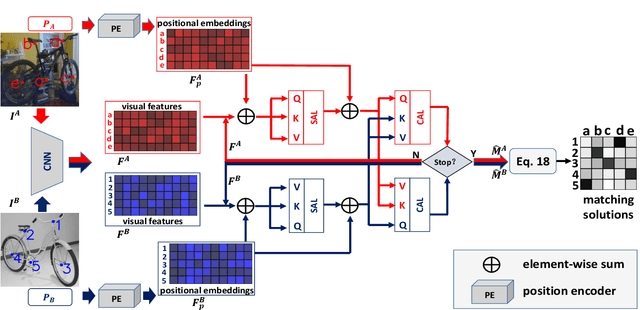

In recent years, powered by the learned discriminative representation via graph neural network (GNN) models, deep graph matching methods have made great progresses in the task of matching semantic features. However, these methods usually rely on heuristically generated graph patterns, which may introduce unreliable relationships to hurt the matching performance. In this paper, we propose a joint \emph{graph learning and matching} network, named GLAM, to explore reliable graph structures for boosting graph matching. GLAM adopts a pure attention-based framework for both graph learning and graph matching. Specifically, it employs two types of attention mechanisms, self-attention and cross-attention for the task. The self-attention discovers the relationships between features and to further update feature representations over the learnt structures; and the cross-attention computes cross-graph correlations between the two feature sets to be matched for feature reconstruction. Moreover, the final matching solution is directly derived from the output of the cross-attention layer, without employing a specific matching decision module. The proposed method is evaluated on three popular visual matching benchmarks (Pascal VOC, Willow Object and SPair-71k), and it outperforms previous state-of-the-art graph matching methods by significant margins on all benchmarks. Furthermore, the graph patterns learnt by our model are validated to be able to remarkably enhance previous deep graph matching methods by replacing their handcrafted graph structures with the learnt ones.
AGKD-BML: Defense Against Adversarial Attack by Attention Guided Knowledge Distillation and Bi-directional Metric Learning
Aug 13, 2021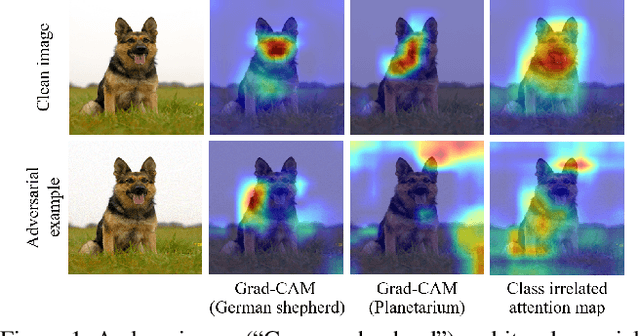
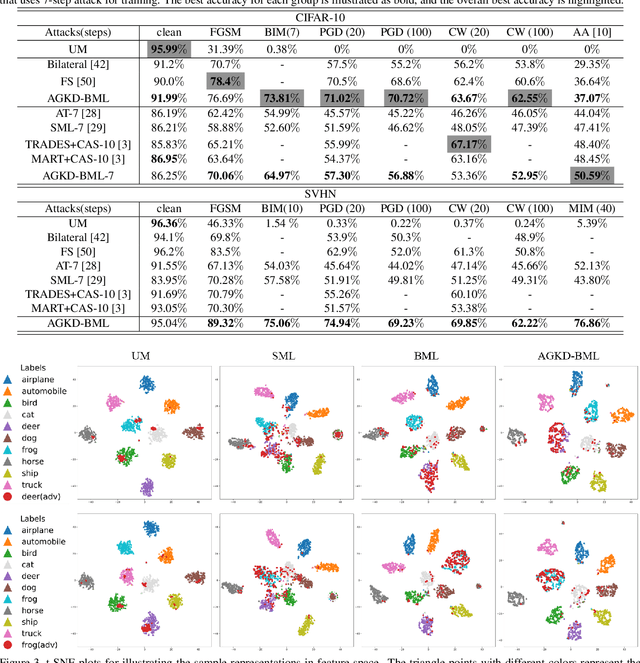
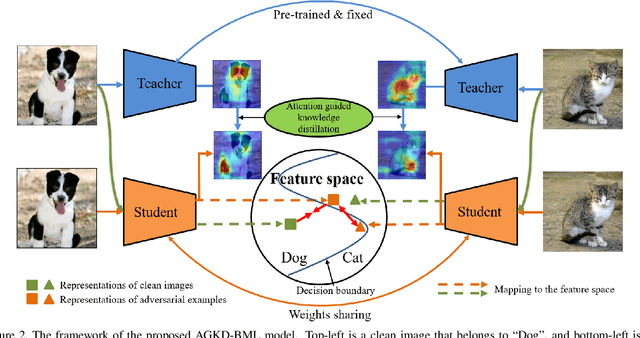
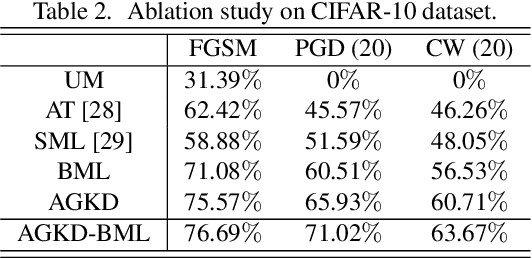
While deep neural networks have shown impressive performance in many tasks, they are fragile to carefully designed adversarial attacks. We propose a novel adversarial training-based model by Attention Guided Knowledge Distillation and Bi-directional Metric Learning (AGKD-BML). The attention knowledge is obtained from a weight-fixed model trained on a clean dataset, referred to as a teacher model, and transferred to a model that is under training on adversarial examples (AEs), referred to as a student model. In this way, the student model is able to focus on the correct region, as well as correcting the intermediate features corrupted by AEs to eventually improve the model accuracy. Moreover, to efficiently regularize the representation in feature space, we propose a bidirectional metric learning. Specifically, given a clean image, it is first attacked to its most confusing class to get the forward AE. A clean image in the most confusing class is then randomly picked and attacked back to the original class to get the backward AE. A triplet loss is then used to shorten the representation distance between original image and its AE, while enlarge that between the forward and backward AEs. We conduct extensive adversarial robustness experiments on two widely used datasets with different attacks. Our proposed AGKD-BML model consistently outperforms the state-of-the-art approaches. The code of AGKD-BML will be available at: https://github.com/hongw579/AGKD-BML.
RINDNet: Edge Detection for Discontinuity in Reflectance, Illumination, Normal and Depth
Aug 02, 2021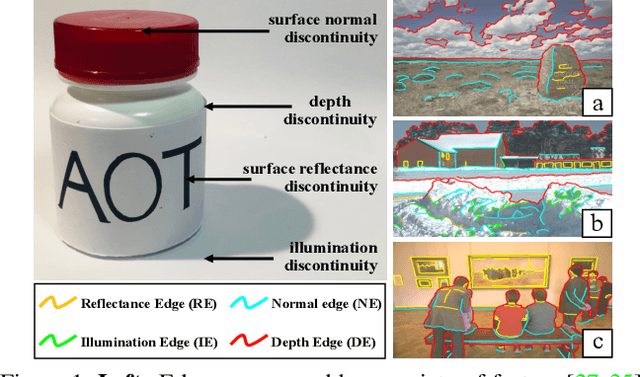
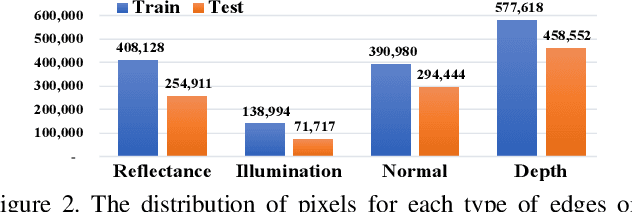

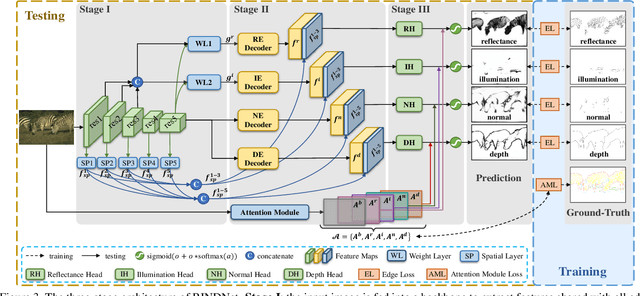
As a fundamental building block in computer vision, edges can be categorised into four types according to the discontinuity in surface-Reflectance, Illumination, surface-Normal or Depth. While great progress has been made in detecting generic or individual types of edges, it remains under-explored to comprehensively study all four edge types together. In this paper, we propose a novel neural network solution, RINDNet, to jointly detect all four types of edges. Taking into consideration the distinct attributes of each type of edges and the relationship between them, RINDNet learns effective representations for each of them and works in three stages. In stage I, RINDNet uses a common backbone to extract features shared by all edges. Then in stage II it branches to prepare discriminative features for each edge type by the corresponding decoder. In stage III, an independent decision head for each type aggregates the features from previous stages to predict the initial results. Additionally, an attention module learns attention maps for all types to capture the underlying relations between them, and these maps are combined with initial results to generate the final edge detection results. For training and evaluation, we construct the first public benchmark, BSDS-RIND, with all four types of edges carefully annotated. In our experiments, RINDNet yields promising results in comparison with state-of-the-art methods. Additional analysis is presented in supplementary material.
CBNetV2: A Composite Backbone Network Architecture for Object Detection
Jul 29, 2021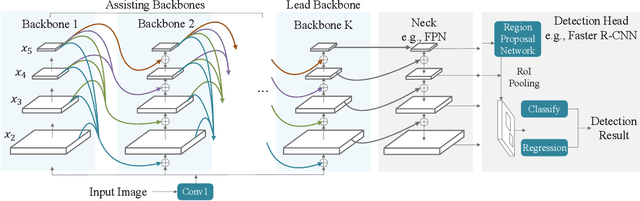
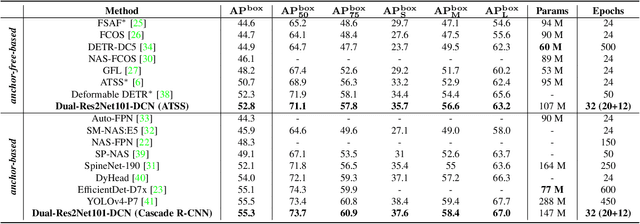
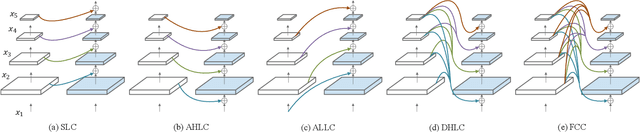
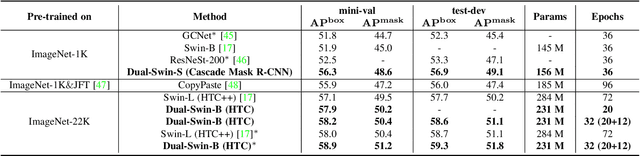
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.
VisDrone-CC2020: The Vision Meets Drone Crowd Counting Challenge Results
Jul 19, 2021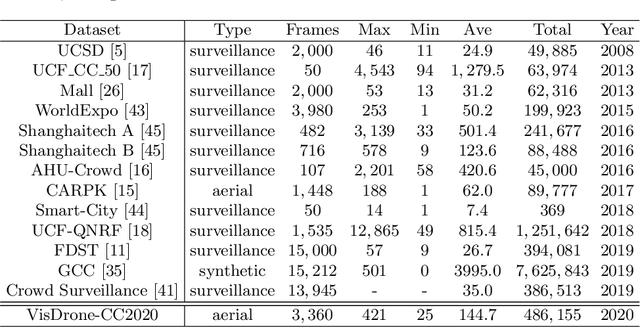

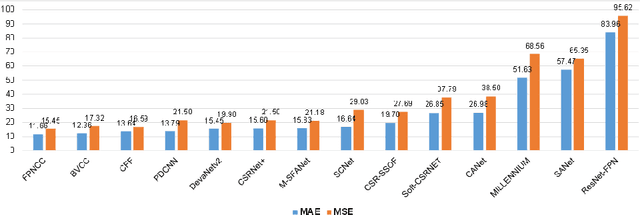
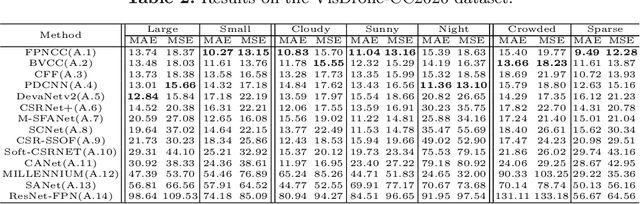
Crowd counting on the drone platform is an interesting topic in computer vision, which brings new challenges such as small object inference, background clutter and wide viewpoint. However, there are few algorithms focusing on crowd counting on the drone-captured data due to the lack of comprehensive datasets. To this end, we collect a large-scale dataset and organize the Vision Meets Drone Crowd Counting Challenge (VisDrone-CC2020) in conjunction with the 16th European Conference on Computer Vision (ECCV 2020) to promote the developments in the related fields. The collected dataset is formed by $3,360$ images, including $2,460$ images for training, and $900$ images for testing. Specifically, we manually annotate persons with points in each video frame. There are $14$ algorithms from $15$ institutes submitted to the VisDrone-CC2020 Challenge. We provide a detailed analysis of the evaluation results and conclude the challenge. More information can be found at the website: \url{http://www.aiskyeye.com/}.
* The method description of A7 Mutil-Scale Aware based SFANet (M-SFANet) is updated and missing references are added
AutoFormer: Searching Transformers for Visual Recognition
Jul 01, 2021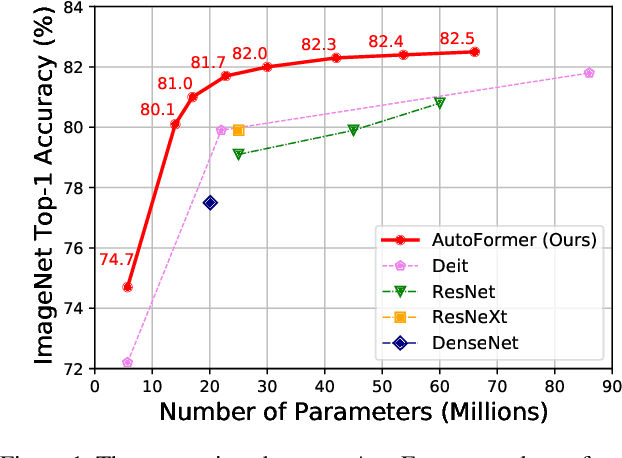
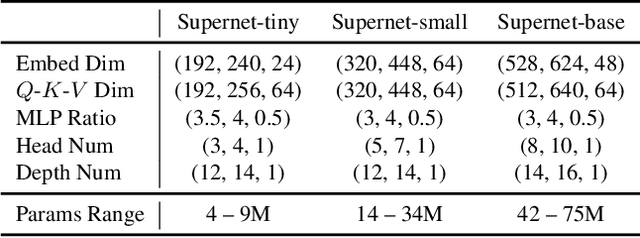
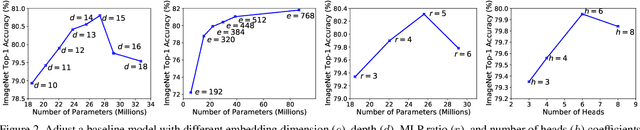

Recently, pure transformer-based models have shown great potentials for vision tasks such as image classification and detection. However, the design of transformer networks is challenging. It has been observed that the depth, embedding dimension, and number of heads can largely affect the performance of vision transformers. Previous models configure these dimensions based upon manual crafting. In this work, we propose a new one-shot architecture search framework, namely AutoFormer, dedicated to vision transformer search. AutoFormer entangles the weights of different blocks in the same layers during supernet training. Benefiting from the strategy, the trained supernet allows thousands of subnets to be very well-trained. Specifically, the performance of these subnets with weights inherited from the supernet is comparable to those retrained from scratch. Besides, the searched models, which we refer to AutoFormers, surpass the recent state-of-the-arts such as ViT and DeiT. In particular, AutoFormer-tiny/small/base achieve 74.7%/81.7%/82.4% top-1 accuracy on ImageNet with 5.7M/22.9M/53.7M parameters, respectively. Lastly, we verify the transferability of AutoFormer by providing the performance on downstream benchmarks and distillation experiments. Code and models are available at https://github.com/microsoft/AutoML.