 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDually Supervised Feature Pyramid for Object Detection and Segmentation
Dec 13, 2019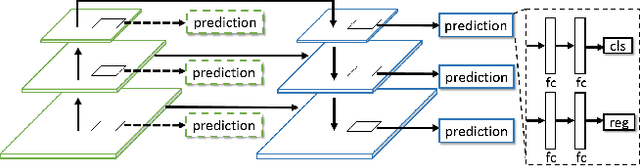
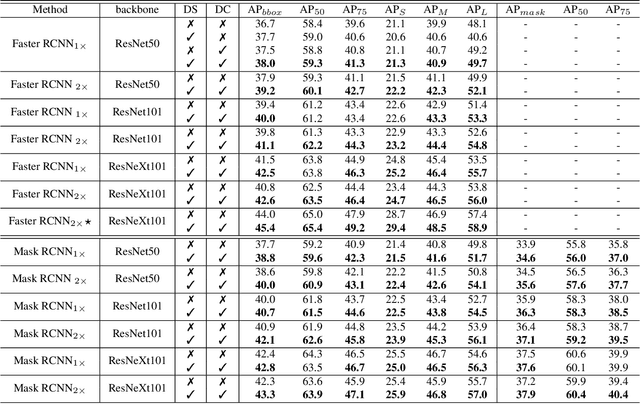
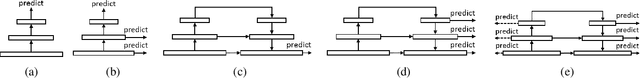
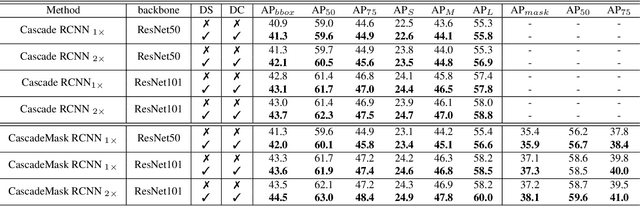
Feature pyramid architecture has been broadly adopted in object detection and segmentation to deal with multi-scale problem. However, in this paper we show that the capacity of the architecture has not been fully explored due to the inadequate utilization of the supervision information. Such insufficient utilization is caused by the supervision signal degradation in back propagation. Thus inspired, we propose a dually supervised method, named dually supervised FPN (DSFPN), to enhance the supervision signal when training the feature pyramid network (FPN). In particular, DSFPN is constructed by attaching extra prediction (i.e., detection or segmentation) heads to the bottom-up subnet of FPN. Hence, the features can be optimized by the additional heads before being forwarded to subsequent networks. Further, the auxiliary heads can serve as a regularization term to facilitate the model training. In addition, to strengthen the capability of the detection heads in DSFPN for handling two inhomogeneous tasks, i.e., classification and regression, the originally shared hidden feature space is separated by decoupling classification and regression subnets. To demonstrate the generalizability, effectiveness, and efficiency of the proposed method, DSFPN is integrated into four representative detectors (Faster RCNN, Mask RCNN, Cascade RCNN, and Cascade Mask RCNN) and assessed on the MS COCO dataset. Promising precision improvement, state-of-the-art performance, and negligible additional computational cost are demonstrated through extensive experiments. Code will be provided.
LaFIn: Generative Landmark Guided Face Inpainting
Nov 26, 2019
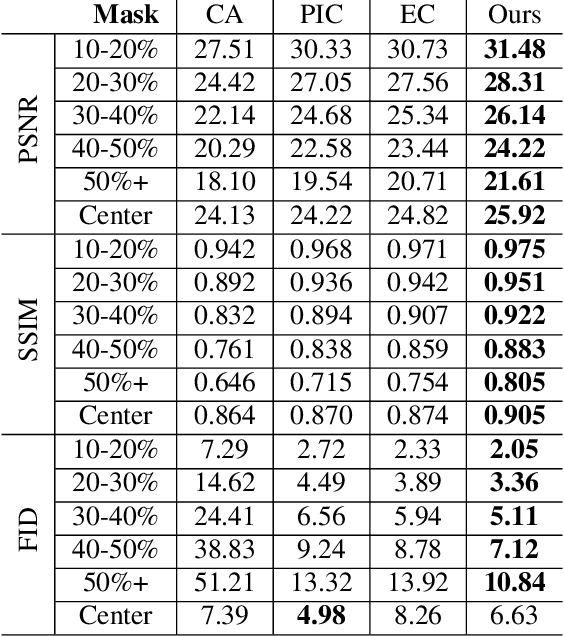
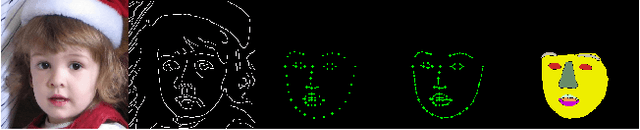
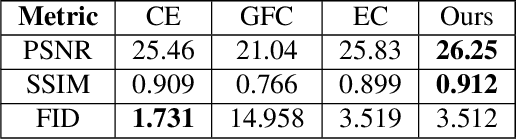
It is challenging to inpaint face images in the wild, due to the large variation of appearance, such as different poses, expressions and occlusions. A good inpainting algorithm should guarantee the realism of output, including the topological structure among eyes, nose and mouth, as well as the attribute consistency on pose, gender, ethnicity, expression, etc. This paper studies an effective deep learning based strategy to deal with these issues, which comprises of a facial landmark predicting subnet and an image inpainting subnet. Concretely, given partial observation, the landmark predictor aims to provide the structural information (e.g. topological relationship and expression) of incomplete faces, while the inpaintor is to generate plausible appearance (e.g. gender and ethnicity) conditioned on the predicted landmarks. Experiments on the CelebA-HQ and CelebA datasets are conducted to reveal the efficacy of our design and, to demonstrate its superiority over state-of-the-art alternatives both qualitatively and quantitatively. In addition, we assume that high-quality completed faces together with their landmarks can be utilized as augmented data to further improve the performance of (any) landmark predictor, which is corroborated by experimental results on the 300W and WFLW datasets.
TracKlinic: Diagnosis of Challenge Factors in Visual Tracking
Nov 25, 2019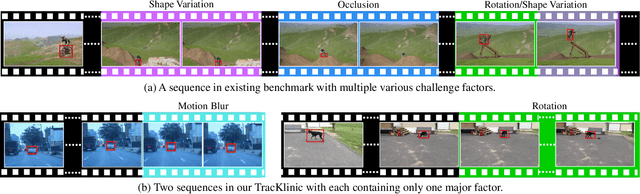
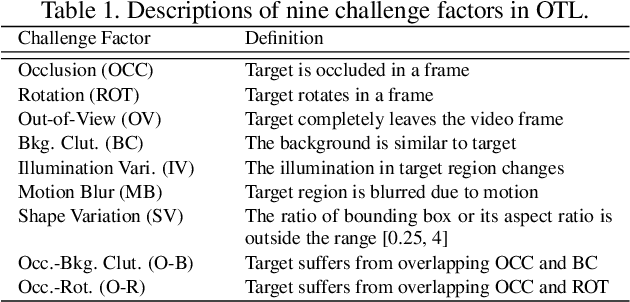
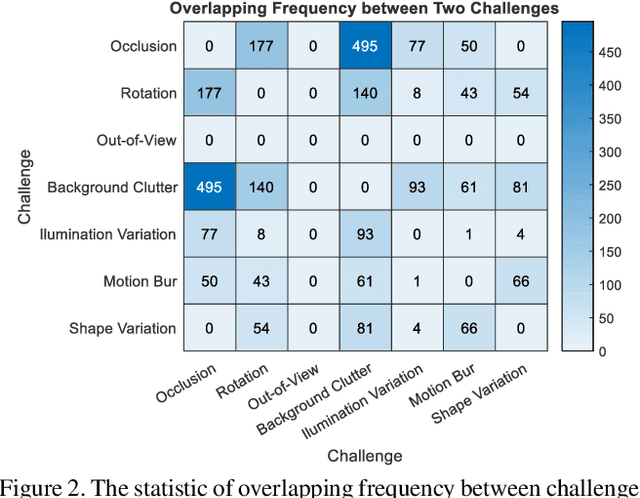
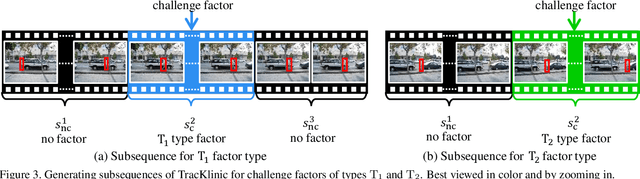
Generic visual tracking is difficult due to many challenge factors (e.g., occlusion, blur, etc.). Each of these factors may cause serious problems for a tracking algorithm, and when they work together can make things even more complicated. Despite a great amount of efforts devoted to understanding the behavior of tracking algorithms, reliable and quantifiable ways for studying the per factor tracking behavior remain barely available. Addressing this issue, in this paper we contribute to the community a tracking diagnosis toolkit, TracKlinic, for diagnosis of challenge factors of tracking algorithms. TracKlinic consists of two novel components focusing on the data and analysis aspects, respectively. For the data component, we carefully prepare a set of 2,390 annotated videos, each involving one and only one major challenge factor. When analyzing an algorithm for a specific challenge factor, such one-factor-per-sequence rule greatly inhibits the disturbance from other factors and consequently leads to more faithful analysis. For the analysis component, given the tracking results on all sequences, it investigates the behavior of the tracker under each individual factor and generates the report automatically. With TracKlinic, a thorough study is conducted on ten state-of-the-art trackers on nine challenge factors (including two compound ones). The results suggest that, heavy shape variation and occlusion are the two most challenging factors faced by most trackers. Besides, out-of-view, though does not happen frequently, is often fatal. By sharing TracKlinic, we expect to make it much easier for diagnosing tracking algorithms, and to thus facilitate developing better ones.
Improving Human Annotation in Single Object Tracking
Nov 07, 2019

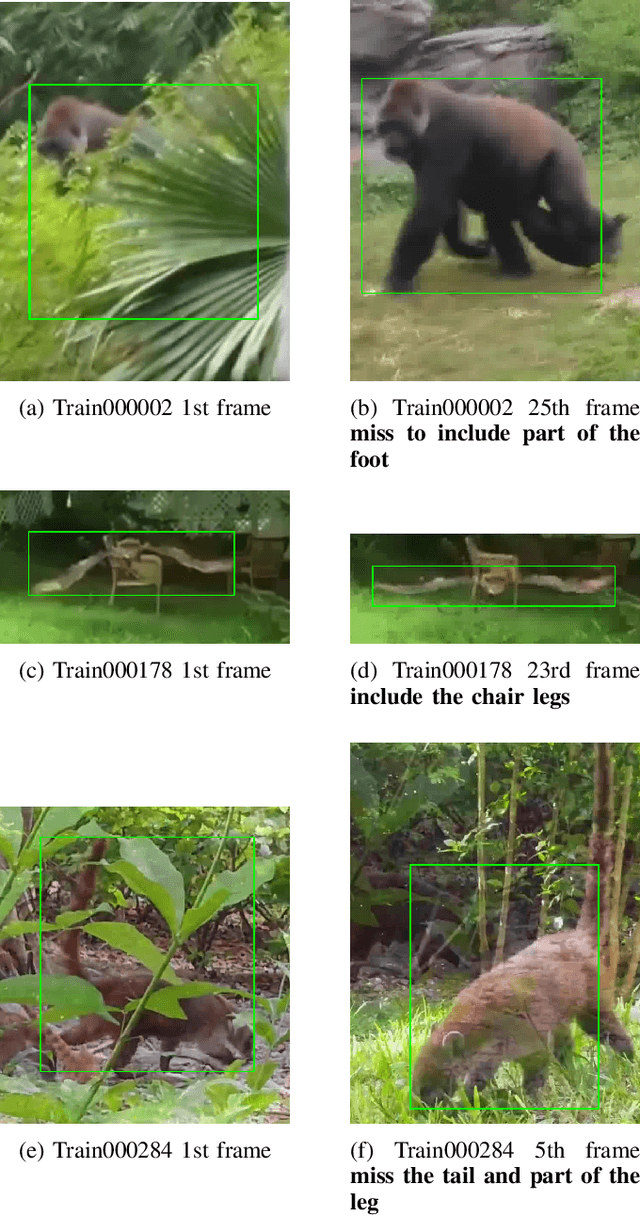
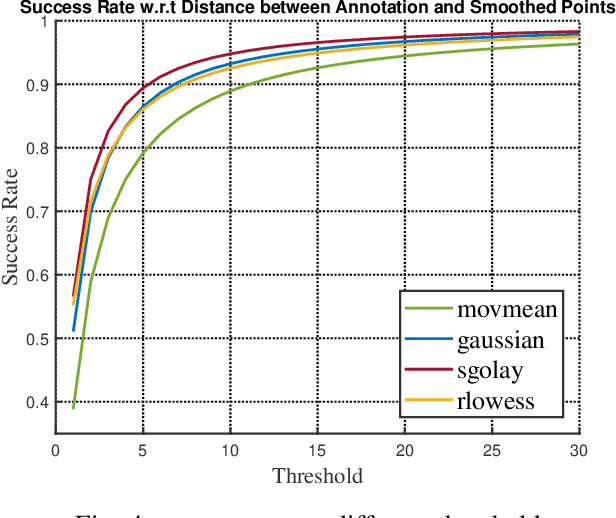
Human annotation is always considered as ground truth in video object tracking tasks. It is used in both training and evaluation purposes. Thus, ensuring its high quality is an important task for the success of trackers and evaluations between them. In this paper, we give a qualitative and quantitative analysis of the existing human annotations. We show that human annotation tends to be non-smooth and is prone to partial visibility and deformation. We propose a smoothing trajectory strategy with the ability to handle moving scenes. We use a two-step adaptive image alignment algorithm to find the canonical view of the video sequence. We then use different techniques to smooth the trajectories at certain degree. Once we convert back to the original image coordination, we can compare with the human annotation. With the experimental results, we can get more consistent trajectories. At a certain degree, it can also slightly improve the trained model. If go beyond a certain threshold, the smoothing error will start eating up the benefit. Overall, our method could help extrapolate the missing annotation frames or identify and correct human annotation outliers as well as help improve the training data quality.
CBNet: A Novel Composite Backbone Network Architecture for Object Detection
Sep 09, 2019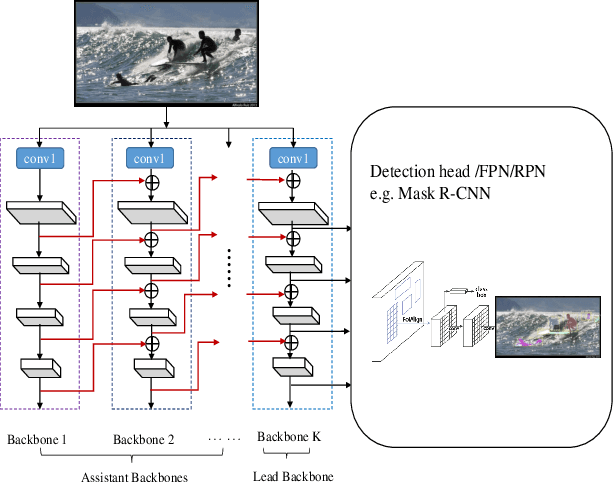
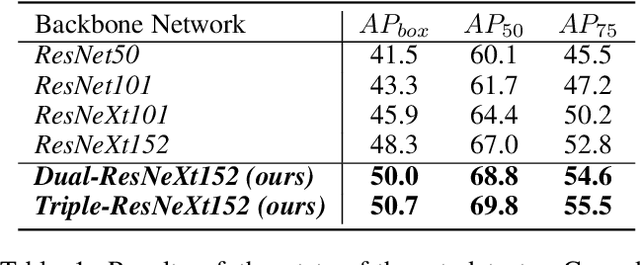
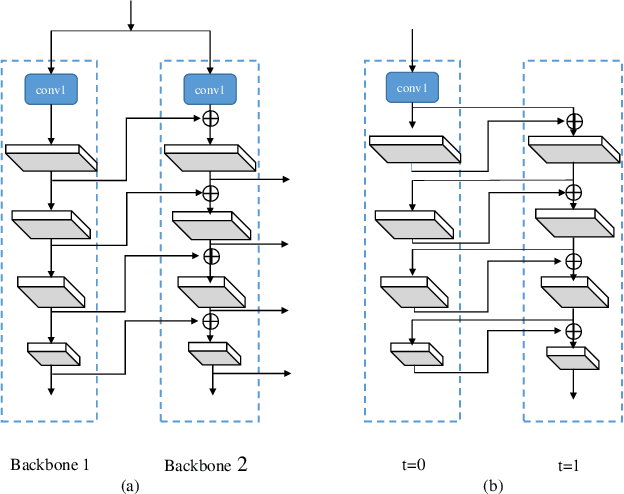
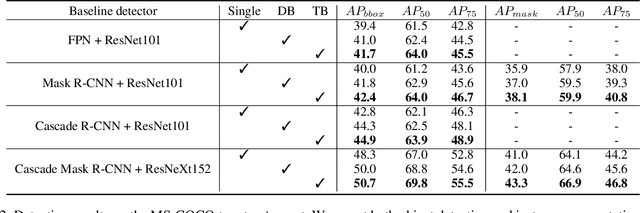
In existing CNN based detectors, the backbone network is a very important component for basic feature extraction, and the performance of the detectors highly depends on it. In this paper, we aim to achieve better detection performance by building a more powerful backbone from existing backbones like ResNet and ResNeXt. Specifically, we propose a novel strategy for assembling multiple identical backbones by composite connections between the adjacent backbones, to form a more powerful backbone named Composite Backbone Network (CBNet). In this way, CBNet iteratively feeds the output features of the previous backbone, namely high-level features, as part of input features to the succeeding backbone, in a stage-by-stage fashion, and finally the feature maps of the last backbone (named Lead Backbone) are used for object detection. We show that CBNet can be very easily integrated into most state-of-the-art detectors and significantly improve their performances. For example, it boosts the mAP of FPN, Mask R-CNN and Cascade R-CNN on the COCO dataset by about 1.5 to 3.0 percent. Meanwhile, experimental results show that the instance segmentation results can also be improved. Specially, by simply integrating the proposed CBNet into the baseline detector Cascade Mask R-CNN, we achieve a new state-of-the-art result on COCO dataset (mAP of 53.3) with single model, which demonstrates great effectiveness of the proposed CBNet architecture. Code will be made available on https://github.com/PKUbahuangliuhe/CBNet.
CompenNet++: End-to-end Full Projector Compensation
Aug 17, 2019

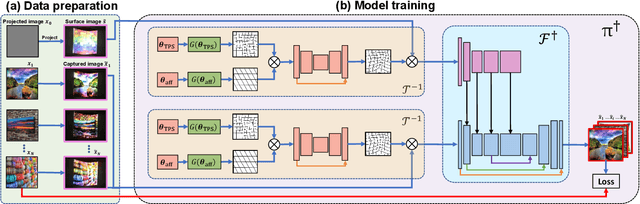

Full projector compensation aims to modify a projector input image such that it can compensate for both geometric and photometric disturbance of the projection surface. Traditional methods usually solve the two parts separately, although they are known to correlate with each other. In this paper, we propose the first end-to-end solution, named CompenNet++, to solve the two problems jointly. Our work non-trivially extends CompenNet, which was recently proposed for photometric compensation with promising performance. First, we propose a novel geometric correction subnet, which is designed with a cascaded coarse-to-fine structure to learn the sampling grid directly from photometric sampling images. Second, by concatenating the geometric correction subset with CompenNet, CompenNet++ accomplishes full projector compensation and is end-to-end trainable. Third, after training, we significantly simplify both geometric and photometric compensation parts, and hence largely improves the running time efficiency. Moreover, we construct the first setup-independent full compensation benchmark to facilitate the study on this topic. In our thorough experiments, our method shows clear advantages over previous arts with promising compensation quality and meanwhile being practically convenient.
Hybrid Camera Pose Estimation with Online Partitioning
Aug 05, 2019
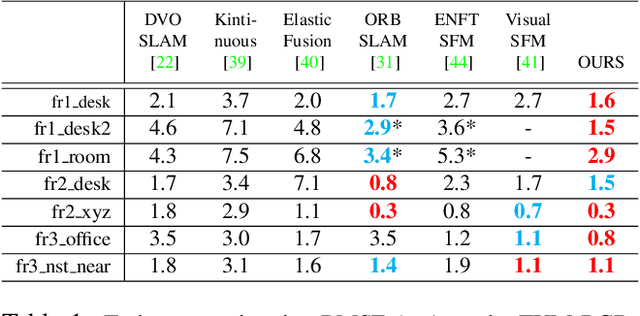
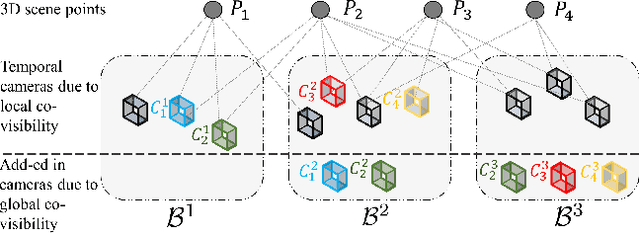
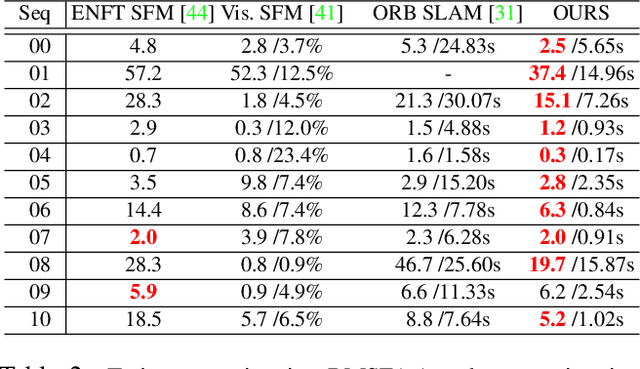
This paper presents a hybrid real-time camera pose estimation framework with a novel partitioning scheme and introduces motion averaging to on-line monocular systems. Breaking through the limitations of fixed-size temporal partitioning in most conventional pose estimation mechanisms, the proposed approach significantly improves the accuracy of local bundle adjustment by gathering spatially-strongly-connected cameras into each block. With the dynamic initialization using intermediate computation values, our proposed self-adaptive Levenberg-Marquardt solver achieves a quadratic convergence rate to further enhance the efficiency of the local optimization. Moreover, the dense data association between blocks by virtue of our co-visibility-based partitioning enables us to explore and implement motion averaging to efficiently align the blocks globally, updating camera motion estimations on-the-fly. Experiment results on benchmarks convincingly demonstrate the practicality and robustness of our proposed approach by outperforming conventional bundle adjustment by orders of magnitude.
Graph Attribute Aggregation Network with Progressive Margin Folding
May 14, 2019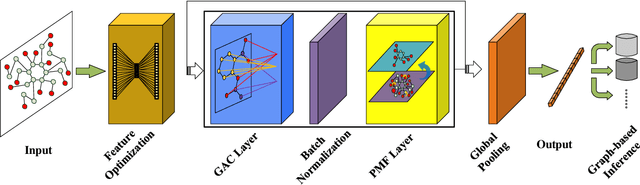
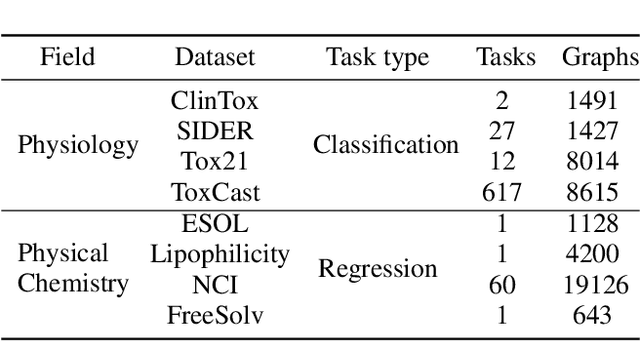
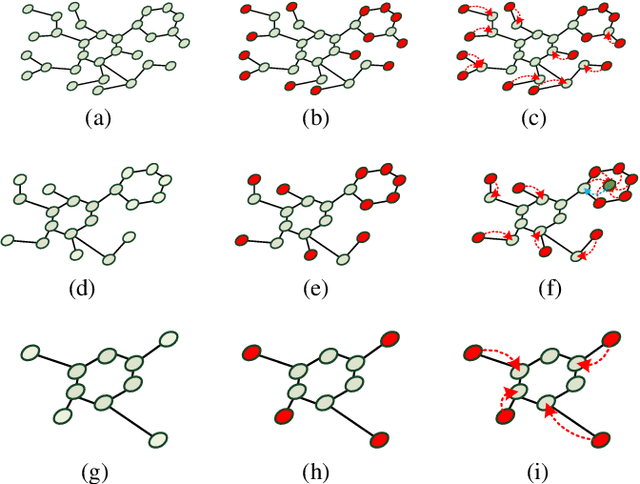
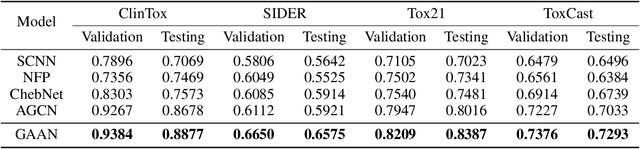
Graph convolutional neural networks (GCNNs) have been attracting increasing research attention due to its great potential in inference over graph structures. However, insufficient effort has been devoted to the aggregation methods between different convolution graph layers. In this paper, we introduce a graph attribute aggregation network (GAAN) architecture. Different from the conventional pooling operations, a graph-transformation-based aggregation strategy, progressive margin folding, PMF, is proposed for integrating graph features. By distinguishing internal and margin elements, we provide an approach for implementing the folding iteratively. And a mechanism is also devised for preserving the local structures during progressively folding. In addition, a hypergraph-based representation is introduced for transferring the aggregated information between different layers. Our experiments applied to the public molecule datasets demonstrate that the proposed GAAN outperforms the existing GCNN models with significant effectiveness.
Salient Object Detection in the Deep Learning Era: An In-Depth Survey
Apr 19, 2019
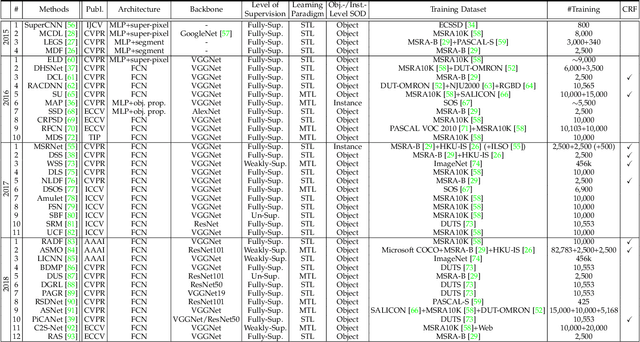
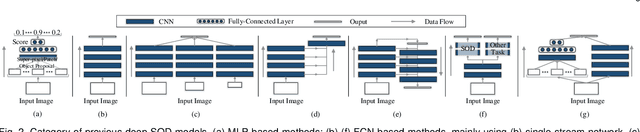
As an important problem in computer vision, salient object detection (SOD) from images has been attracting an increasing amount of research effort over the years. Recent advances in SOD, not surprisingly, are dominantly led by deep learning-based solutions (named deep SOD) and reflected by hundreds of published papers. To facilitate the in-depth understanding of deep SODs, in this paper we provide a comprehensive survey covering various aspects ranging from algorithm taxonomy to unsolved open issues. In particular, we first review deep SOD algorithms from different perspectives including network architecture, level of supervision, learning paradigm and object/instance level detection. Following that, we summarize existing SOD evaluation datasets and metrics. Then, we carefully compile a thorough benchmark results of SOD methods based on previous work, and provide detailed analysis of the comparison results. Moreover, we study the performance of SOD algorithms under different attributes, which have been barely explored previously, by constructing a novel SOD dataset with rich attribute annotations. We further analyze, for the first time in the field, the robustness and transferability of deep SOD models w.r.t. adversarial attacks. We also look into the influence of input perturbations, and the generalization and hardness of existing SOD datasets. Finally, we discuss several open issues and challenges of SOD, and point out possible research directions in future. All the saliency prediction maps, our constructed dataset with annotations, and codes for evaluation are made publicly available at https://github.com/wenguanwang/SODsurvey.
Clustered Object Detection in Aerial Images
Apr 16, 2019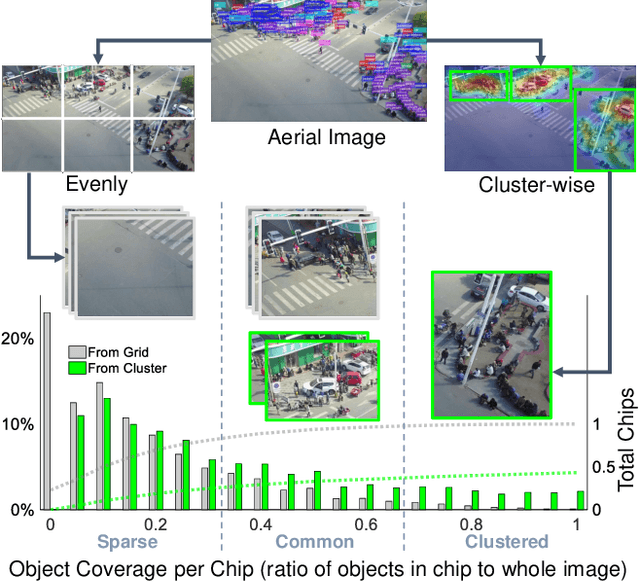
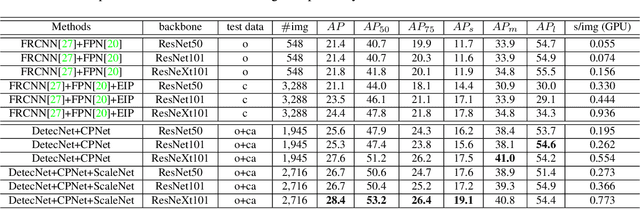
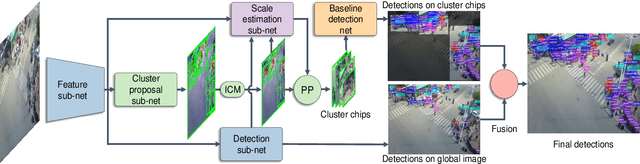
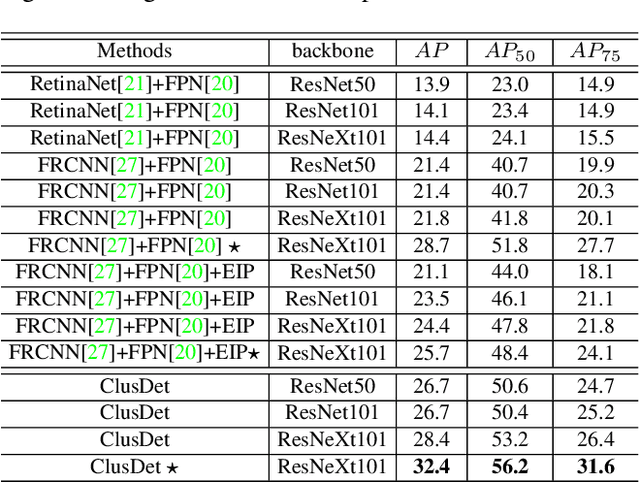
Detecting objects in aerial images is challenging for at least two reasons: (1) target objects like pedestrians are very small in terms of pixels, making them hard to be distinguished from surrounding background; and (2) targets are in general very sparsely and nonuniformly distributed, making the detection very inefficient. In this paper we address both issues inspired by the observation that these targets are often clustered. In particular, we propose a Clustered Detection (ClusDet) network that unifies object cluster and detection in an end-to-end framework. The key components in ClusDet include a cluster proposal sub-network (CPNet), a scale estimation sub-network (ScaleNet), and a dedicated detection network (DetecNet). Given an input image, CPNet produces (object) cluster regions and ScaleNet estimates object scales for these regions. Then, each scale-normalized cluster region and their features are fed into DetecNet for object detection. Compared with previous solutions, ClusDet has several advantages: (1) it greatly reduces the number of blocks for final object detection and hence achieves high running time efficiency, (2) the cluster-based scale estimation is more accurate than previously used single-object based ones, hence effectively improves the detection for small objects, and (3) the final DetecNet is dedicated for clustered regions and implicitly models the prior context information so as to boost detection accuracy. The proposed method is tested on three representative aerial image datasets including VisDrone, UAVDT and DOTA. In all the experiments, ClusDet achieves promising performance in both efficiency and accuracy, in comparison with state-of-the-art detectors.