 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multi-speaker Multi-style Voice Cloning Challenge 2021
Apr 05, 2021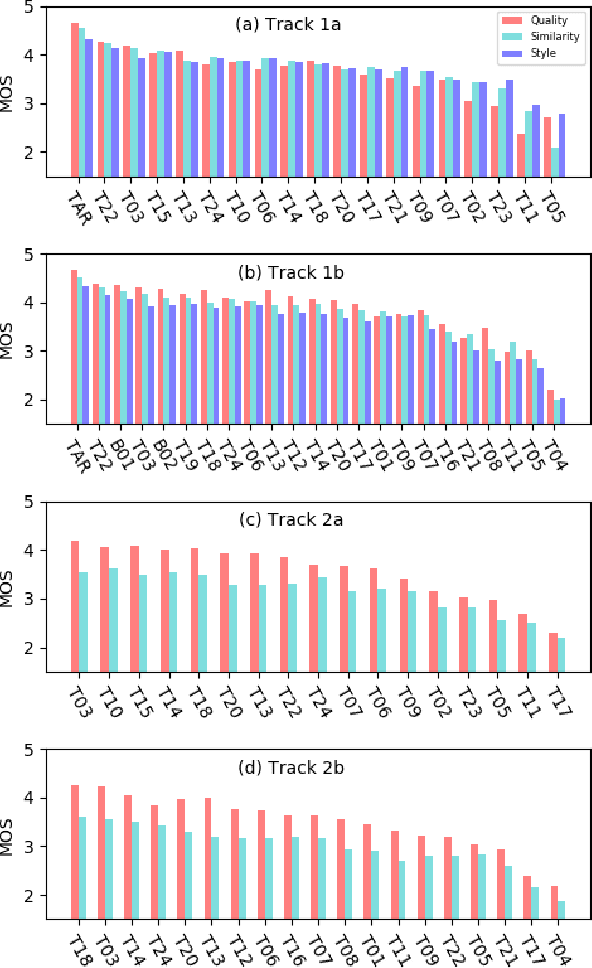
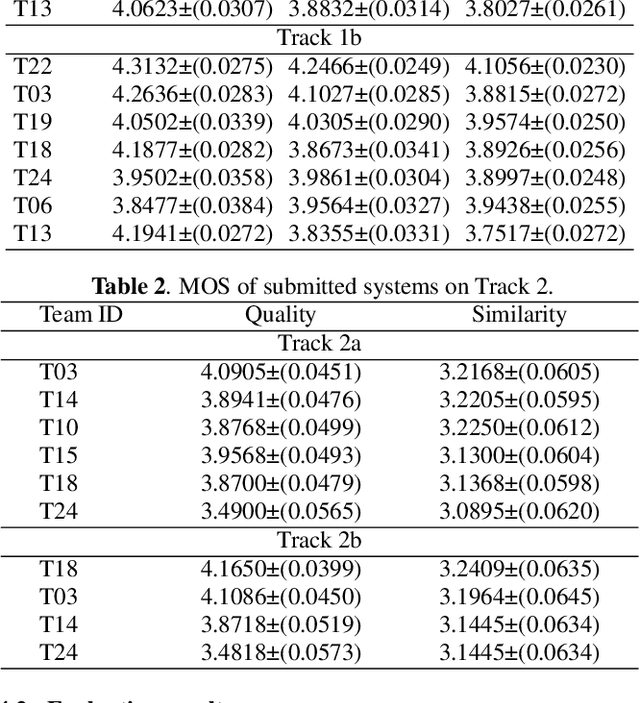
The Multi-speaker Multi-style Voice Cloning Challenge (M2VoC) aims to provide a common sizable dataset as well as a fair testbed for the benchmarking of the popular voice cloning task. Specifically, we formulate the challenge to adapt an average TTS model to the stylistic target voice with limited data from target speaker, evaluated by speaker identity and style similarity. The challenge consists of two tracks, namely few-shot track and one-shot track, where the participants are required to clone multiple target voices with 100 and 5 samples respectively. There are also two sub-tracks in each track. For sub-track a, to fairly compare different strategies, the participants are allowed to use only the training data provided by the organizer strictly. For sub-track b, the participants are allowed to use any data publicly available. In this paper, we present a detailed explanation on the tasks and data used in the challenge, followed by a summary of submitted systems and evaluation results.
Can Targeted Adversarial Examples Transfer When the Source and Target Models Have No Label Space Overlap?
Mar 17, 2021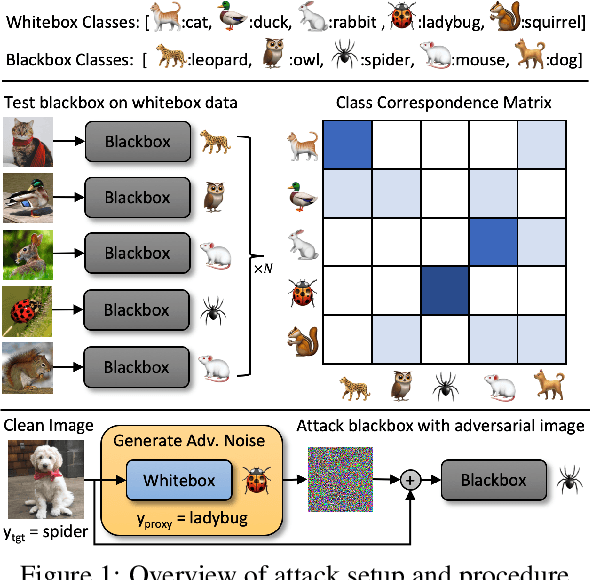
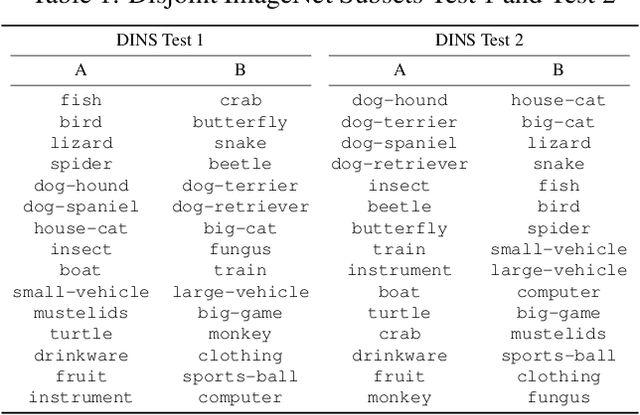
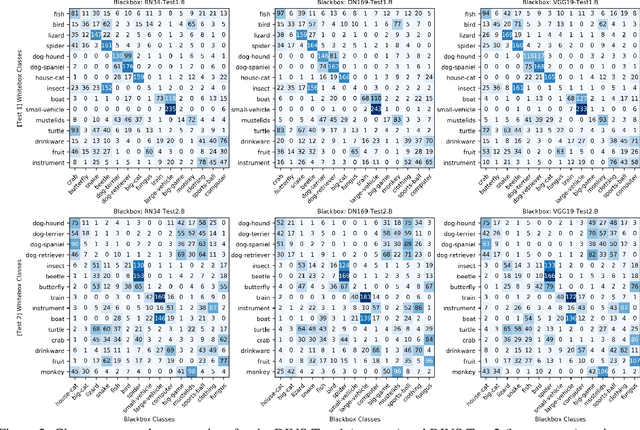
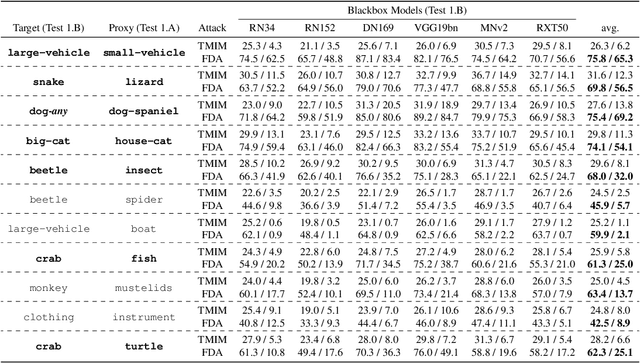
We design blackbox transfer-based targeted adversarial attacks for an environment where the attacker's source model and the target blackbox model may have disjoint label spaces and training datasets. This scenario significantly differs from the "standard" blackbox setting, and warrants a unique approach to the attacking process. Our methodology begins with the construction of a class correspondence matrix between the whitebox and blackbox label sets. During the online phase of the attack, we then leverage representations of highly related proxy classes from the whitebox distribution to fool the blackbox model into predicting the desired target class. Our attacks are evaluated in three complex and challenging test environments where the source and target models have varying degrees of conceptual overlap amongst their unique categories. Ultimately, we find that it is indeed possible to construct targeted transfer-based adversarial attacks between models that have non-overlapping label spaces! We also analyze the sensitivity of attack success to properties of the clean data. Finally, we show that our transfer attacks serve as powerful adversarial priors when integrated with query-based methods, markedly boosting query efficiency and adversarial success.
The Untapped Potential of Off-the-Shelf Convolutional Neural Networks
Mar 17, 2021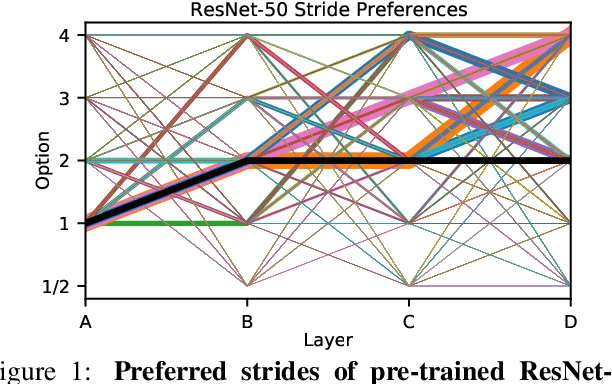
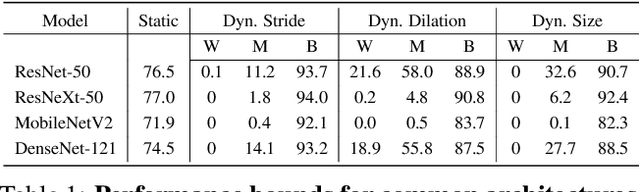
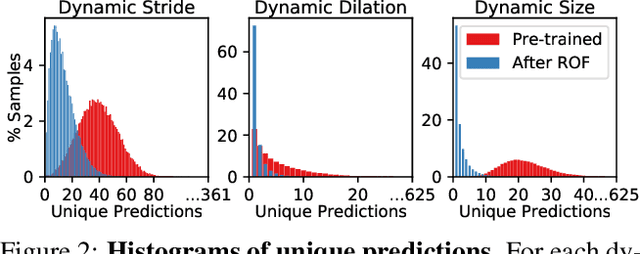
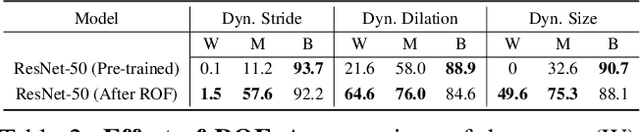
Over recent years, a myriad of novel convolutional network architectures have been developed to advance state-of-the-art performance on challenging recognition tasks. As computational resources improve, a great deal of effort has been placed in efficiently scaling up existing designs and generating new architectures with Neural Architecture Search (NAS) algorithms. While network topology has proven to be a critical factor for model performance, we show that significant gains are being left on the table by keeping topology static at inference-time. Due to challenges such as scale variation, we should not expect static models configured to perform well across a training dataset to be optimally configured to handle all test data. In this work, we seek to expose the exciting potential of inference-time-dynamic models. By allowing just four layers to dynamically change configuration at inference-time, we show that existing off-the-shelf models like ResNet-50 are capable of over 95% accuracy on ImageNet. This level of performance currently exceeds that of models with over 20x more parameters and significantly more complex training procedures.
A Case for 3D Integrated System Design for Neuromorphic Computing & AI Applications
Mar 02, 2021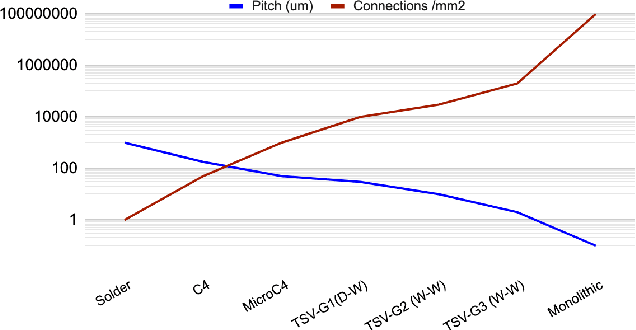
Over the last decade, artificial intelligence has found many applications areas in the society. As AI solutions have become more sophistication and the use cases grew, they highlighted the need to address performance and energy efficiency challenges faced during the implementation process. To address these challenges, there has been growing interest in neuromorphic chips. Neuromorphic computing relies on non von Neumann architectures as well as novel devices, circuits and manufacturing technologies to mimic the human brain. Among such technologies, 3D integration is an important enabler for AI hardware and the continuation of the scaling laws. In this paper, we overview the unique opportunities 3D integration provides in neuromorphic chip design, discuss the emerging opportunities in next generation neuromorphic architectures and review the obstacles. Neuromorphic architectures, which relied on the brain for inspiration and emulation purposes, face grand challenges due to the limited understanding of the functionality and the architecture of the human brain. Yet, high-levels of investments are dedicated to develop neuromorphic chips. We argue that 3D integration not only provides strategic advantages to the cost-effective and flexible design of neuromorphic chips, it may provide design flexibility in incorporating advanced capabilities to further benefits the designs in the future.
BSQ: Exploring Bit-Level Sparsity for Mixed-Precision Neural Network Quantization
Feb 20, 2021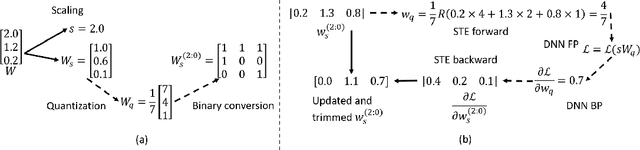

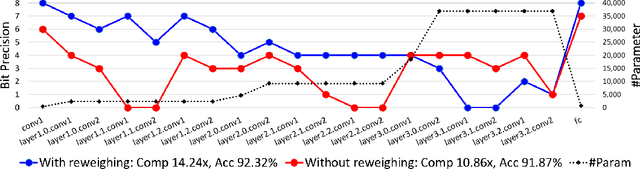
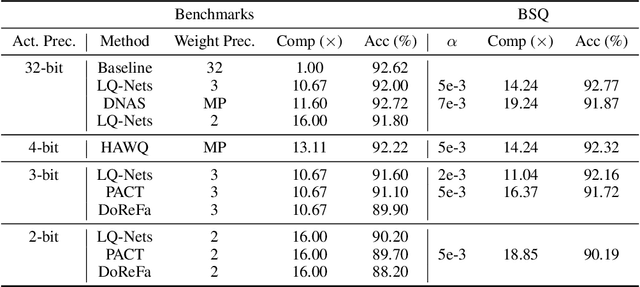
Mixed-precision quantization can potentially achieve the optimal tradeoff between performance and compression rate of deep neural networks, and thus, have been widely investigated. However, it lacks a systematic method to determine the exact quantization scheme. Previous methods either examine only a small manually-designed search space or utilize a cumbersome neural architecture search to explore the vast search space. These approaches cannot lead to an optimal quantization scheme efficiently. This work proposes bit-level sparsity quantization (BSQ) to tackle the mixed-precision quantization from a new angle of inducing bit-level sparsity. We consider each bit of quantized weights as an independent trainable variable and introduce a differentiable bit-sparsity regularizer. BSQ can induce all-zero bits across a group of weight elements and realize the dynamic precision reduction, leading to a mixed-precision quantization scheme of the original model. Our method enables the exploration of the full mixed-precision space with a single gradient-based optimization process, with only one hyperparameter to tradeoff the performance and compression. BSQ achieves both higher accuracy and higher bit reduction on various model architectures on the CIFAR-10 and ImageNet datasets comparing to previous methods.
Improving Adversarial Robustness in Weight-quantized Neural Networks
Jan 23, 2021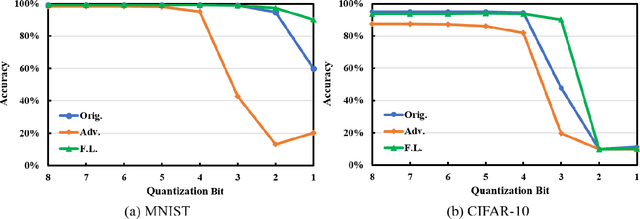
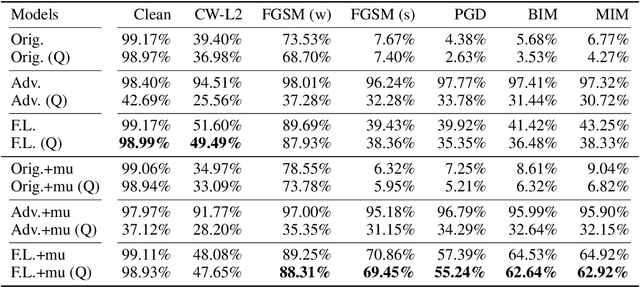
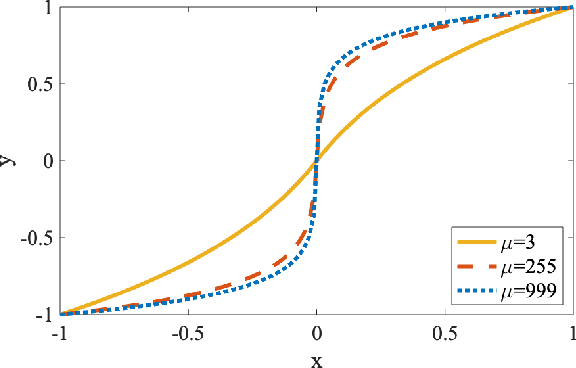
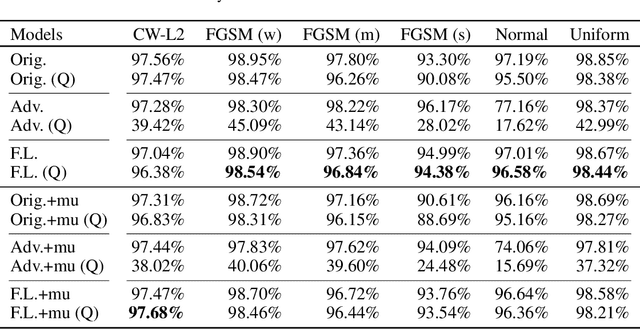
Neural networks are getting deeper and more computation-intensive nowadays. Quantization is a useful technique in deploying neural networks on hardware platforms and saving computation costs with negligible performance loss. However, recent research reveals that neural network models, no matter full-precision or quantized, are vulnerable to adversarial attacks. In this work, we analyze both adversarial and quantization losses and then introduce criteria to evaluate them. We propose a boundary-based retraining method to mitigate adversarial and quantization losses together and adopt a nonlinear mapping method to defend against white-box gradient-based adversarial attacks. The evaluations demonstrate that our method can better restore accuracy after quantization than other baseline methods on both black-box and white-box adversarial attacks. The results also show that adversarial training suffers quantization loss and does not cooperate well with other training methods.
On Provable Backdoor Defense in Collaborative Learning
Jan 19, 2021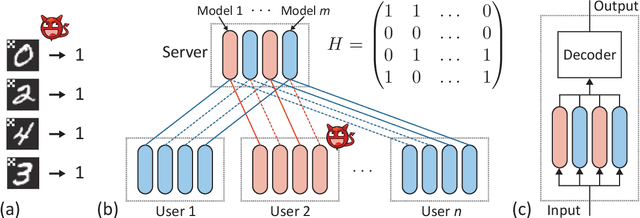
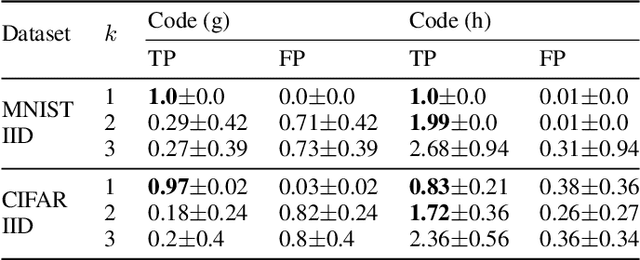


As collaborative learning allows joint training of a model using multiple sources of data, the security problem has been a central concern. Malicious users can upload poisoned data to prevent the model's convergence or inject hidden backdoors. The so-called backdoor attacks are especially difficult to detect since the model behaves normally on standard test data but gives wrong outputs when triggered by certain backdoor keys. Although Byzantine-tolerant training algorithms provide convergence guarantee, provable defense against backdoor attacks remains largely unsolved. Methods based on randomized smoothing can only correct a small number of corrupted pixels or labels; methods based on subset aggregation cause a severe drop in classification accuracy due to low data utilization. We propose a novel framework that generalizes existing subset aggregation methods. The framework shows that the subset selection process, a deciding factor for subset aggregation methods, can be viewed as a code design problem. We derive the theoretical bound of data utilization ratio and provide optimal code construction. Experiments on non-IID versions of MNIST and CIFAR-10 show that our method with optimal codes significantly outperforms baselines using non-overlapping partition and random selection. Additionally, integration with existing coding theory results shows that special codes can track the location of the attackers. Such capability provides new countermeasures to backdoor attacks.
Provable Defense against Privacy Leakage in Federated Learning from Representation Perspective
Dec 08, 2020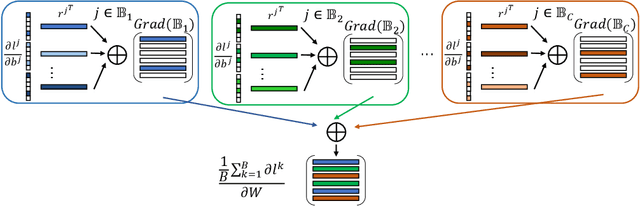
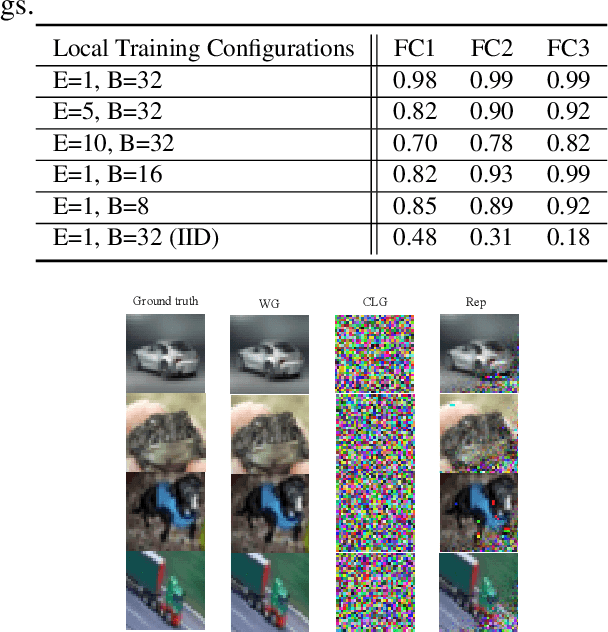
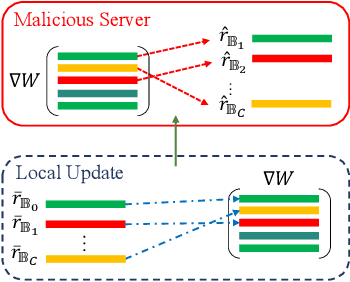
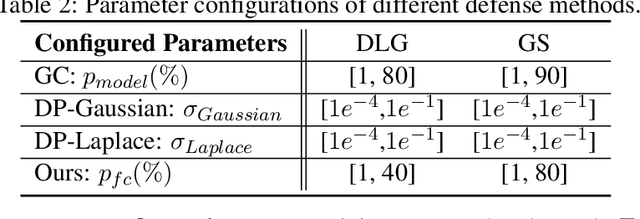
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. However, recent works demonstrated that sharing model updates makes FL vulnerable to inference attacks. In this work, we show our key observation that the data representation leakage from gradients is the essential cause of privacy leakage in FL. We also provide an analysis of this observation to explain how the data presentation is leaked. Based on this observation, we propose a defense against model inversion attack in FL. The key idea of our defense is learning to perturb data representation such that the quality of the reconstructed data is severely degraded, while FL performance is maintained. In addition, we derive certified robustness guarantee to FL and convergence guarantee to FedAvg, after applying our defense. To evaluate our defense, we conduct experiments on MNIST and CIFAR10 for defending against the DLG attack and GS attack. Without sacrificing accuracy, the results demonstrate that our proposed defense can increase the mean squared error between the reconstructed data and the raw data by as much as more than 160X for both DLG attack and GS attack, compared with baseline defense methods. The privacy of the FL system is significantly improved.
GraphFL: A Federated Learning Framework for Semi-Supervised Node Classification on Graphs
Dec 08, 2020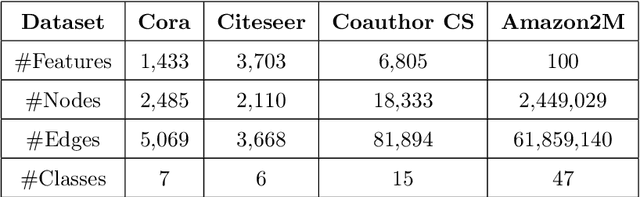
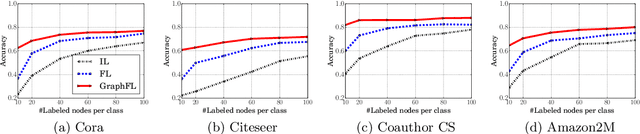
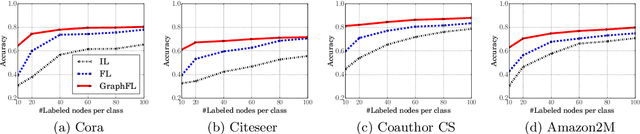
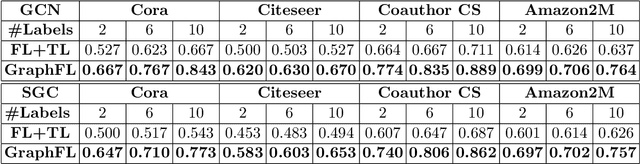
Graph-based semi-supervised node classification (GraphSSC) has wide applications, ranging from networking and security to data mining and machine learning, etc. However, existing centralized GraphSSC methods are impractical to solve many real-world graph-based problems, as collecting the entire graph and labeling a reasonable number of labels is time-consuming and costly, and data privacy may be also violated. Federated learning (FL) is an emerging learning paradigm that enables collaborative learning among multiple clients, which can mitigate the issue of label scarcity and protect data privacy as well. Therefore, performing GraphSSC under the FL setting is a promising solution to solve real-world graph-based problems. However, existing FL methods 1) perform poorly when data across clients are non-IID, 2) cannot handle data with new label domains, and 3) cannot leverage unlabeled data, while all these issues naturally happen in real-world graph-based problems. To address the above issues, we propose the first FL framework, namely GraphFL, for semi-supervised node classification on graphs. Our framework is motivated by meta-learning methods. Specifically, we propose two GraphFL methods to respectively address the non-IID issue in graph data and handle the tasks with new label domains. Furthermore, we design a self-training method to leverage unlabeled graph data. We adopt representative graph neural networks as GraphSSC methods and evaluate GraphFL on multiple graph datasets. Experimental results demonstrate that GraphFL significantly outperforms the compared FL baseline and GraphFL with self-training can obtain better performance.
ScaleNAS: One-Shot Learning of Scale-Aware Representations for Visual Recognition
Nov 30, 2020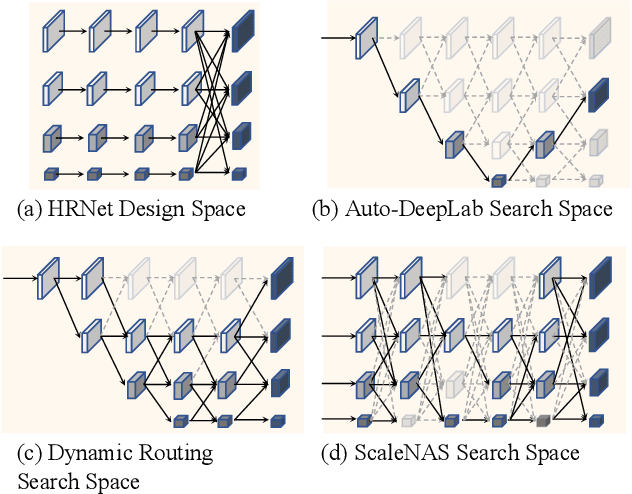
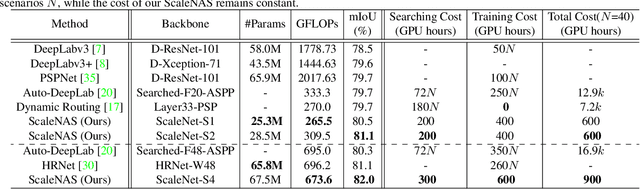
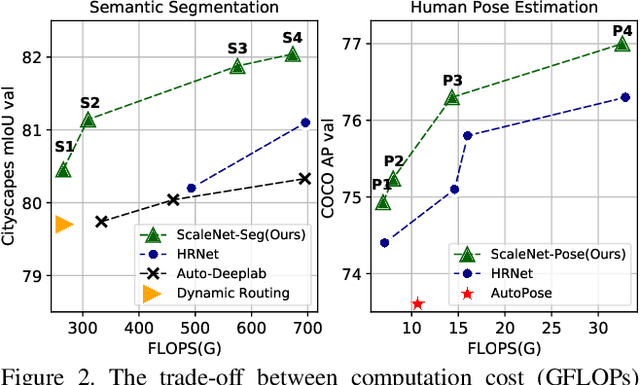
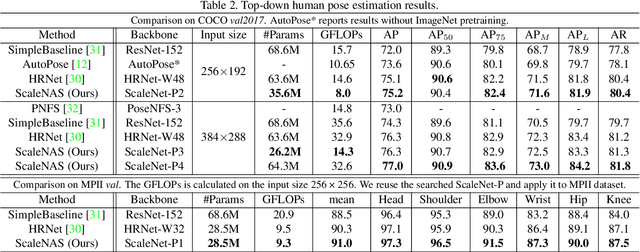
Scale variance among different sizes of body parts and objects is a challenging problem for visual recognition tasks. Existing works usually design dedicated backbone or apply Neural architecture Search(NAS) for each task to tackle this challenge. However, existing works impose significant limitations on the design or search space. To solve these problems, we present ScaleNAS, a one-shot learning method for exploring scale-aware representations. ScaleNAS solves multiple tasks at a time by searching multi-scale feature aggregation. ScaleNAS adopts a flexible search space that allows an arbitrary number of blocks and cross-scale feature fusions. To cope with the high search cost incurred by the flexible space, ScaleNAS employs one-shot learning for multi-scale supernet driven by grouped sampling and evolutionary search. Without further retraining, ScaleNet can be directly deployed for different visual recognition tasks with superior performance. We use ScaleNAS to create high-resolution models for two different tasks, ScaleNet-P for human pose estimation and ScaleNet-S for semantic segmentation. ScaleNet-P and ScaleNet-S outperform existing manually crafted and NAS-based methods in both tasks. When applying ScaleNet-P to bottom-up human pose estimation, it surpasses the state-of-the-art HigherHRNet. In particular, ScaleNet-P4 achieves 71.6% AP on COCO test-dev, achieving new state-of-the-art result.