 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized Federated Learning with Gradient Tracking over Time-Varying Directed Networks
Sep 25, 2024



We investigate the problem of agent-to-agent interaction in decentralized (federated) learning over time-varying directed graphs, and, in doing so, propose a consensus-based algorithm called DSGTm-TV. The proposed algorithm incorporates gradient tracking and heavy-ball momentum to distributively optimize a global objective function, while preserving local data privacy. Under DSGTm-TV, agents will update local model parameters and gradient estimates using information exchange with neighboring agents enabled through row- and column-stochastic mixing matrices, which we show guarantee both consensus and optimality. Our analysis establishes that DSGTm-TV exhibits linear convergence to the exact global optimum when exact gradient information is available, and converges in expectation to a neighborhood of the global optimum when employing stochastic gradients. Moreover, in contrast to existing methods, DSGTm-TV preserves convergence for networks with uncoordinated stepsizes and momentum parameters, for which we provide explicit bounds. These results enable agents to operate in a fully decentralized manner, independently optimizing their local hyper-parameters. We demonstrate the efficacy of our approach via comparisons with state-of-the-art baselines on real-world image classification and natural language processing tasks.
Near-Field Multipath MIMO Channel Model for Imperfect Surface Reflection
Sep 25, 2024



Near-field (NF) communications is receiving renewed attention in the context of passive reconfigurable intelligent surfaces (RISs) due to their potentially extremely large dimensions. Although line-of-sight (LOS) links are expected to be dominant in NF scenarios, it is not a priori obvious whether or not the impact of non-LOS components can be neglected. Furthermore, despite being weaker than the LOS link, non-LOS links may be required to achieve multiplexing gains in multi-user multiple-input multiple-output (MIMO) scenarios. In this paper, we develop a generalized statistical NF model for RIS-assisted MIMO systems that extends the widely adopted point-scattering model to account for imperfect reflections at large surfaces like walls, ceilings, and the ground. Our simulation results confirm the accuracy of the proposed model and reveal that in various practical scenarios, the impact of non-LOS components is indeed non-negligible, and thus, needs to be carefully taken into consideration.
DiffSG: A Generative Solver for Network Optimization with Diffusion Model
Aug 13, 2024



Diffusion generative models, famous for their performance in image generation, are popular in various cross-domain applications. However, their use in the communication community has been mostly limited to auxiliary tasks like data modeling and feature extraction. These models hold greater promise for fundamental problems in network optimization compared to traditional machine learning methods. Discriminative deep learning often falls short due to its single-step input-output mapping and lack of global awareness of the solution space, especially given the complexity of network optimization's objective functions. In contrast, diffusion generative models can consider a broader range of solutions and exhibit stronger generalization by learning parameters that describe the distribution of the underlying solution space, with higher probabilities assigned to better solutions. We propose a new framework Diffusion Model-based Solution Generation (DiffSG), which leverages the intrinsic distribution learning capabilities of diffusion generative models to learn high-quality solution distributions based on given inputs. The optimal solution within this distribution is highly probable, allowing it to be effectively reached through repeated sampling. We validate the performance of DiffSG on several typical network optimization problems, including mixed-integer non-linear programming, convex optimization, and hierarchical non-convex optimization. Our results show that DiffSG outperforms existing baselines. In summary, we demonstrate the potential of diffusion generative models in tackling complex network optimization problems and outline a promising path for their broader application in the communication community.
Large Models for Aerial Edges: An Edge-Cloud Model Evolution and Communication Paradigm
Aug 09, 2024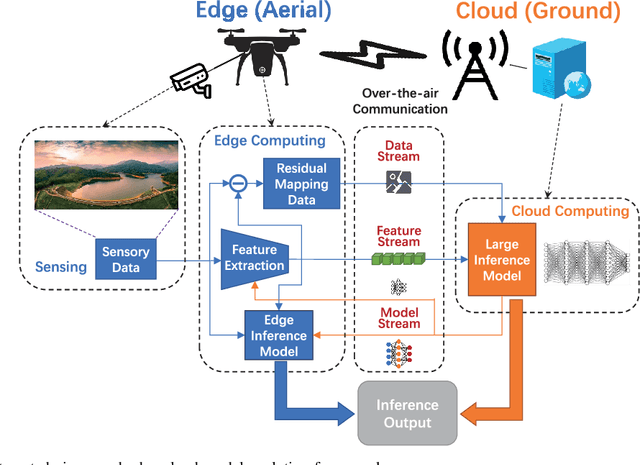
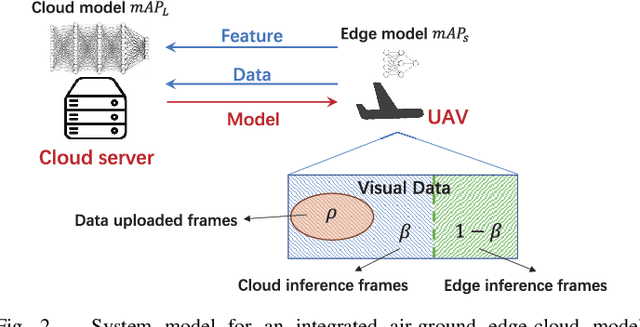
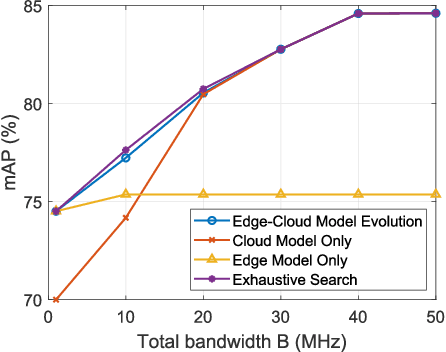
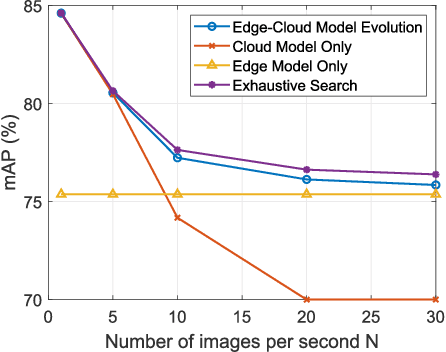
The future sixth-generation (6G) of wireless networks is expected to surpass its predecessors by offering ubiquitous coverage through integrated air-ground facility deployments in both communication and computing domains. In this network, aerial facilities, such as unmanned aerial vehicles (UAVs), conduct artificial intelligence (AI) computations based on multi-modal data to support diverse applications including surveillance and environment construction. However, these multi-domain inference and content generation tasks require large AI models, demanding powerful computing capabilities, thus posing significant challenges for UAVs. To tackle this problem, we propose an integrated edge-cloud model evolution framework, where UAVs serve as edge nodes for data collection and edge model computation. Through wireless channels, UAVs collaborate with ground cloud servers, providing cloud model computation and model updating for edge UAVs. With limited wireless communication bandwidth, the proposed framework faces the challenge of information exchange scheduling between the edge UAVs and the cloud server. To tackle this, we present joint task allocation, transmission resource allocation, transmission data quantization design, and edge model update design to enhance the inference accuracy of the integrated air-ground edge-cloud model evolution framework by mean average precision (mAP) maximization. A closed-form lower bound on the mAP of the proposed framework is derived, and the solution to the mAP maximization problem is optimized accordingly. Simulations, based on results from vision-based classification experiments, consistently demonstrate that the mAP of the proposed framework outperforms both a centralized cloud model framework and a distributed edge model framework across various communication bandwidths and data sizes.
FAST-GSC: Fast and Adaptive Semantic Transmission for Generative Semantic Communication
Jul 22, 2024



The rapidly evolving field of generative artificial intelligence technology has introduced innovative approaches for developing semantic communication (SemCom) frameworks, leading to the emergence of a new paradigm-generative SemCom (GSC). However, the complex processes involved in semantic extraction and generative inference may result in considerable latency in resource-constrained scenarios. To tackle these issues, we introduce a new GSC framework that involves fast and adaptive semantic transmission (FAST-GSC). This framework incorporates one innovative communication mechanism and two enhancement strategies at the transmitter and receiver, respectively. Aiming to reduce task latency, our communication mechanism enables fast semantic transmission by parallelizing the processes of semantic extraction at the transmitter and inference at the receiver. Preliminary evaluations indicate that while this mechanism effectively reduces task latency, it could potentially compromise task performance. To address this issue, we propose two additional methods for enhancement. First, at the transmitter, we employ reinforcement learning to discern the intrinsic temporal dependencies among the semantic units and design their extraction and transmission sequence accordingly. Second, at the receiver, we design a semantic difference calculation module and propose a sequential conditional denoising approach to alleviate the stringent immediacy requirement for the reception of semantic features. Extensive experiments demonstrate that our proposed architecture achieves a performance score comparable to the conventional GSC architecture while realizing a 52% reduction in residual task latency that extends beyond the fixed inference duration.
Building Resilience in Wireless Communication Systems With a Secret-Key Budget
Jul 16, 2024



Resilience and power consumption are two important performance metrics for many modern communication systems, and it is therefore important to define, analyze, and optimize them. In this work, we consider a wireless communication system with secret-key generation, in which the secret-key bits are added to and used from a pool of available key bits. We propose novel physical layer resilience metrics for the survivability of such systems. In addition, we propose multiple power allocation schemes and analyze their trade-off between resilience and power consumption. In particular, we investigate and compare constant power allocation, an adaptive analytical algorithm, and a reinforcement learning-based solution. It is shown how the transmit power can be minimized such that a specified resilience is guaranteed. These results can be used directly by designers of such systems to optimize the system parameters for the desired performance in terms of reliability, security, and resilience.
Hybrid NOMA Assisted OFDMA Uplink Transmission
Jul 04, 2024



Hybrid non-orthogonal multiple access (NOMA) has recently received significant research interest due to its ability to efficiently use resources from different domains and also its compatibility with various orthogonal multiple access (OMA) based legacy networks. Unlike existing studies on hybrid NOMA that focus on combining NOMA with time-division multiple access (TDMA), this work considers hybrid NOMA assisted orthogonal frequency-division multiple access (OFDMA). In particular, the impact of a unique feature of hybrid NOMA assisted OFDMA, i.e., the availability of users' dynamic channel state information, on the system performance is analyzed from the following two perspectives. From the optimization perspective, analytical results are developed which show that with hybrid NOMA assisted OFDMA, the pure OMA mode is rarely adopted by the users, and the pure NOMA mode could be optimal for minimizing the users' energy consumption, which differs from the hybrid TDMA case. From the statistical perspective, two new performance metrics, namely the power outage probability and the power diversity gain, are developed to quantitatively measure the performance gain of hybrid NOMA over OMA. The developed analytical results also demonstrate the ability of hybrid NOMA to meet the users' diverse energy profiles.
Model-Based Learning for Network Clock Synchronization in Half-Duplex TDMA Networks
Jun 21, 2024



Supporting increasingly higher rates in wireless networks requires highly accurate clock synchronization across the nodes. Motivated by this need, in this work we consider distributed clock synchronization for half-duplex (HD) TDMA wireless networks. We focus on pulse-coupling (PC)-based synchronization as it is practically advantageous for high-speed networks using low-power nodes. Previous works on PC-based synchronization for TDMA networks assumed full-duplex communications, and focused on correcting the clock phase at each node, without synchronizing clocks' frequencies. However, as in the HD regime corrections are temporally sparse, uncompensated clock frequency differences between the nodes result in large phase drifts between updates. Moreover, as the clocks determine the processing rates at the nodes, leaving the clocks' frequencies unsynchronized results in processing rates mismatch between the nodes, leading to a throughput reduction. Our goal in this work is to synchronize both clock frequency and clock phase across the clocks in HD TDMA networks, via distributed processing. The key challenges are the coupling between frequency correction and phase correction, and the lack of a computationally efficient analytical framework for determining the optimal correction signal at the nodes. We address these challenges via a DNN-aided nested loop structure in which the DNN are used for generating the weights applied to the loop input for computing the correction signal. This loop is operated in a sequential manner which decouples frequency and phase compensations, thereby facilitating synchronization of both parameters. Performance evaluation shows that the proposed scheme significantly improves synchronization accuracy compared to the conventional approaches.
Distributed Combinatorial Optimization of Downlink User Assignment in mmWave Cell-free Massive MIMO Using Graph Neural Networks
Jun 09, 2024



Millimeter wave (mmWave) cell-free massive MIMO (CF mMIMO) is a promising solution for future wireless communications. However, its optimization is non-trivial due to the challenging channel characteristics. We show that mmWave CF mMIMO optimization is largely an assignment problem between access points (APs) and users due to the high path loss of mmWave channels, the limited output power of the amplifier, and the almost orthogonal channels between users given a large number of AP antennas. The combinatorial nature of the assignment problem, the requirement for scalability, and the distributed implementation of CF mMIMO make this problem difficult. In this work, we propose an unsupervised machine learning (ML) enabled solution. In particular, a graph neural network (GNN) customized for scalability and distributed implementation is introduced. Moreover, the customized GNN architecture is hierarchically permutation-equivariant (HPE), i.e., if the APs or users of an AP are permuted, the output assignment is automatically permuted in the same way. To address the combinatorial problem, we relax it to a continuous problem, and introduce an information entropy-inspired penalty term. The training objective is then formulated using the augmented Lagrangian method (ALM). The test results show that the realized sum-rate outperforms that of the generalized serial dictatorship (GSD) algorithm and is very close to the upper bound in a small network scenario, while the upper bound is impossible to obtain in a large network scenario.
Privacy Preserving Semi-Decentralized Mean Estimation over Intermittently-Connected Networks
Jun 06, 2024We consider the problem of privately estimating the mean of vectors distributed across different nodes of an unreliable wireless network, where communications between nodes can fail intermittently. We adopt a semi-decentralized setup, wherein to mitigate the impact of intermittently connected links, nodes can collaborate with their neighbors to compute a local consensus, which they relay to a central server. In such a setting, the communications between any pair of nodes must ensure that the privacy of the nodes is rigorously maintained to prevent unauthorized information leakage. We study the tradeoff between collaborative relaying and privacy leakage due to the data sharing among nodes and, subsequently, propose PriCER: Private Collaborative Estimation via Relaying -- a differentially private collaborative algorithm for mean estimation to optimize this tradeoff. The privacy guarantees of PriCER arise (i) implicitly, by exploiting the inherent stochasticity of the flaky network connections, and (ii) explicitly, by adding Gaussian perturbations to the estimates exchanged by the nodes. Local and central privacy guarantees are provided against eavesdroppers who can observe different signals, such as the communications amongst nodes during local consensus and (possibly multiple) transmissions from the relays to the central server. We substantiate our theoretical findings with numerical simulations. Our implementation is available at https://github.com/rajarshisaha95/private-collaborative-relaying.