 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR: Focused Attention Is All You Need for Generative Recommendation
Dec 17, 2025Recently, transformer-based generative recommendation has garnered significant attention for user behavior modeling. However, it often requires discretizing items into multi-code representations (e.g., typically four code tokens or more), which sharply increases the length of the original item sequence. This expansion poses challenges to transformer-based models for modeling user behavior sequences with inherent noises, since they tend to overallocate attention to irrelevant or noisy context. To mitigate this issue, we propose FAIR, the first generative recommendation framework with focused attention, which enhances attention scores to relevant context while suppressing those to irrelevant ones. Specifically, we propose (1) a focused attention mechanism integrated into the standard Transformer, which learns two separate sets of Q and K attention weights and computes their difference as the final attention scores to eliminate attention noise while focusing on relevant contexts; (2) a noise-robustness objective, which encourages the model to maintain stable attention patterns under stochastic perturbations, preventing undesirable shifts toward irrelevant context due to noise; and (3) a mutual information maximization objective, which guides the model to identify contexts that are most informative for next-item prediction. We validate the effectiveness of FAIR on four public benchmarks, demonstrating its superior performance compared to existing methods.
Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
A Contextual-Aware Position Encoding for Sequential Recommendation
Feb 13, 2025



Sequential recommendation (SR), which encodes user activity to predict the next action, has emerged as a widely adopted strategy in developing commercial personalized recommendation systems. A critical component of modern SR models is the attention mechanism, which synthesizes users' historical activities. This mechanism is typically order-invariant and generally relies on position encoding (PE). Conventional SR models simply assign a learnable vector to each position, resulting in only modest gains compared to traditional recommendation models. Moreover, limited research has been conducted on position encoding tailored for sequential recommendation, leaving a significant gap in addressing its unique requirements. To bridge this gap, we propose a novel Contextual-Aware Position Encoding method for sequential recommendation, abbreviated as CAPE. To the best of our knowledge, CAPE is the first PE method specifically designed for sequential recommendation. Comprehensive experiments conducted on benchmark SR datasets demonstrate that CAPE consistently enhances multiple mainstream backbone models and achieves state-of-the-art performance, across small and large scale model size. Furthermore, we deployed CAPE in an industrial setting on a real-world commercial platform, clearly showcasing the effectiveness of our approach. Our source code is available at https://github.com/yjdy/CAPE.
A Parameter Update Balancing Algorithm for Multi-task Ranking Models in Recommendation Systems
Oct 08, 2024



Multi-task ranking models have become essential for modern real-world recommendation systems. While most recommendation researches focus on designing sophisticated models for specific scenarios, achieving performance improvement for multi-task ranking models across various scenarios still remains a significant challenge. Training all tasks naively can result in inconsistent learning, highlighting the need for the development of multi-task optimization (MTO) methods to tackle this challenge. Conventional methods assume that the optimal joint gradient on shared parameters leads to optimal parameter updates. However, the actual update on model parameters may deviates significantly from gradients when using momentum based optimizers such as Adam, and we design and execute statistical experiments to support the observation. In this paper, we propose a novel Parameter Update Balancing algorithm for multi-task optimization, denoted as PUB. In contrast to traditional MTO method which are based on gradient level tasks fusion or loss level tasks fusion, PUB is the first work to optimize multiple tasks through parameter update balancing. Comprehensive experiments on benchmark multi-task ranking datasets demonstrate that PUB consistently improves several multi-task backbones and achieves state-of-the-art performance. Additionally, experiments on benchmark computer vision datasets show the great potential of PUB in various multi-task learning scenarios. Furthermore, we deployed our method for an industrial evaluation on the real-world commercial platform, HUAWEI AppGallery, where PUB significantly enhances the online multi-task ranking model, efficiently managing the primary traffic of a crucial channel.
Counteracting Duration Bias in Video Recommendation via Counterfactual Watch Time
Jun 12, 2024



In video recommendation, an ongoing effort is to satisfy users' personalized information needs by leveraging their logged watch time. However, watch time prediction suffers from duration bias, hindering its ability to reflect users' interests accurately. Existing label-correction approaches attempt to uncover user interests through grouping and normalizing observed watch time according to video duration. Although effective to some extent, we found that these approaches regard completely played records (i.e., a user watches the entire video) as equally high interest, which deviates from what we observed on real datasets: users have varied explicit feedback proportion when completely playing videos. In this paper, we introduce the counterfactual watch time(CWT), the potential watch time a user would spend on the video if its duration is sufficiently long. Analysis shows that the duration bias is caused by the truncation of CWT due to the video duration limitation, which usually occurs on those completely played records. Besides, a Counterfactual Watch Model (CWM) is proposed, revealing that CWT equals the time users get the maximum benefit from video recommender systems. Moreover, a cost-based transform function is defined to transform the CWT into the estimation of user interest, and the model can be learned by optimizing a counterfactual likelihood function defined over observed user watch times. Extensive experiments on three real video recommendation datasets and online A/B testing demonstrated that CWM effectively enhanced video recommendation accuracy and counteracted the duration bias.
Recall-Augmented Ranking: Enhancing Click-Through Rate Prediction Accuracy with Cross-Stage Data
Apr 15, 2024



Click-through rate (CTR) prediction plays an indispensable role in online platforms. Numerous models have been proposed to capture users' shifting preferences by leveraging user behavior sequences. However, these historical sequences often suffer from severe homogeneity and scarcity compared to the extensive item pool. Relying solely on such sequences for user representations is inherently restrictive, as user interests extend beyond the scope of items they have previously engaged with. To address this challenge, we propose a data-driven approach to enrich user representations. We recognize user profiling and recall items as two ideal data sources within the cross-stage framework, encompassing the u2u (user-to-user) and i2i (item-to-item) aspects respectively. In this paper, we propose a novel architecture named Recall-Augmented Ranking (RAR). RAR consists of two key sub-modules, which synergistically gather information from a vast pool of look-alike users and recall items, resulting in enriched user representations. Notably, RAR is orthogonal to many existing CTR models, allowing for consistent performance improvements in a plug-and-play manner. Extensive experiments are conducted, which verify the efficacy and compatibility of RAR against the SOTA methods.
Uncovering User Interest from Biased and Noised Watch Time in Video Recommendation
Aug 16, 2023



In the video recommendation, watch time is commonly adopted as an indicator of user interest. However, watch time is not only influenced by the matching of users' interests but also by other factors, such as duration bias and noisy watching. Duration bias refers to the tendency for users to spend more time on videos with longer durations, regardless of their actual interest level. Noisy watching, on the other hand, describes users taking time to determine whether they like a video or not, which can result in users spending time watching videos they do not like. Consequently, the existence of duration bias and noisy watching make watch time an inadequate label for indicating user interest. Furthermore, current methods primarily address duration bias and ignore the impact of noisy watching, which may limit their effectiveness in uncovering user interest from watch time. In this study, we first analyze the generation mechanism of users' watch time from a unified causal viewpoint. Specifically, we considered the watch time as a mixture of the user's actual interest level, the duration-biased watch time, and the noisy watch time. To mitigate both the duration bias and noisy watching, we propose Debiased and Denoised watch time Correction (D$^2$Co), which can be divided into two steps: First, we employ a duration-wise Gaussian Mixture Model plus frequency-weighted moving average for estimating the bias and noise terms; then we utilize a sensitivity-controlled correction function to separate the user interest from the watch time, which is robust to the estimation error of bias and noise terms. The experiments on two public video recommendation datasets and online A/B testing indicate the effectiveness of the proposed method.
ReLoop2: Building Self-Adaptive Recommendation Models via Responsive Error Compensation Loop
Jun 22, 2023Industrial recommender systems face the challenge of operating in non-stationary environments, where data distribution shifts arise from evolving user behaviors over time. To tackle this challenge, a common approach is to periodically re-train or incrementally update deployed deep models with newly observed data, resulting in a continual training process. However, the conventional learning paradigm of neural networks relies on iterative gradient-based updates with a small learning rate, making it slow for large recommendation models to adapt. In this paper, we introduce ReLoop2, a self-correcting learning loop that facilitates fast model adaptation in online recommender systems through responsive error compensation. Inspired by the slow-fast complementary learning system observed in human brains, we propose an error memory module that directly stores error samples from incoming data streams. These stored samples are subsequently leveraged to compensate for model prediction errors during testing, particularly under distribution shifts. The error memory module is designed with fast access capabilities and undergoes continual refreshing with newly observed data samples during the model serving phase to support fast model adaptation. We evaluate the effectiveness of ReLoop2 on three open benchmark datasets as well as a real-world production dataset. The results demonstrate the potential of ReLoop2 in enhancing the responsiveness and adaptiveness of recommender systems operating in non-stationary environments.
FinalMLP: An Enhanced Two-Stream MLP Model for CTR Prediction
Apr 06, 2023



Click-through rate (CTR) prediction is one of the fundamental tasks for online advertising and recommendation. While multi-layer perceptron (MLP) serves as a core component in many deep CTR prediction models, it has been widely recognized that applying a vanilla MLP network alone is inefficient in learning multiplicative feature interactions. As such, many two-stream interaction models (e.g., DeepFM and DCN) have been proposed by integrating an MLP network with another dedicated network for enhanced CTR prediction. As the MLP stream learns feature interactions implicitly, existing research focuses mainly on enhancing explicit feature interactions in the complementary stream. In contrast, our empirical study shows that a well-tuned two-stream MLP model that simply combines two MLPs can even achieve surprisingly good performance, which has never been reported before by existing work. Based on this observation, we further propose feature selection and interaction aggregation layers that can be easily plugged to make an enhanced two-stream MLP model, FinalMLP. In this way, it not only enables differentiated feature inputs but also effectively fuses stream-level interactions across two streams. Our evaluation results on four open benchmark datasets as well as an online A/B test in our industrial system show that FinalMLP achieves better performance than many sophisticated two-stream CTR models. Our source code will be available at MindSpore/models and FuxiCTR/model_zoo.
BARS: Towards Open Benchmarking for Recommender Systems
Jun 01, 2022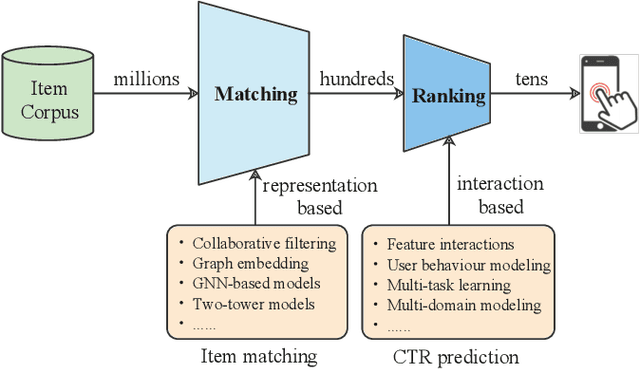
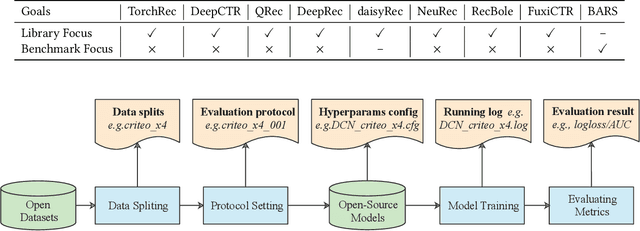
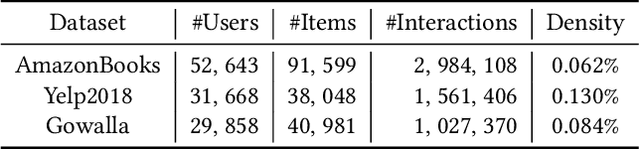
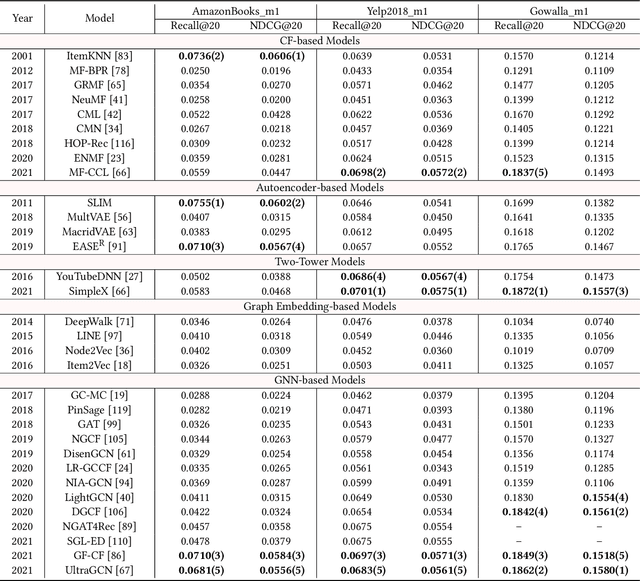
The past two decades have witnessed the rapid development of personalized recommendation techniques. Despite the significant progress made in both research and practice of recommender systems, to date, there is a lack of a widely-recognized benchmarking standard in this field. Many of the existing studies perform model evaluations and comparisons in an ad-hoc manner, for example, by employing their own private data splits or using a different experimental setting. However, such conventions not only increase the difficulty in reproducing existing studies, but also lead to inconsistent experimental results among them. This largely limits the credibility and practical value of research results in this field. To tackle these issues, we present an initiative project aimed for open benchmarking for recommender systems. In contrast to some earlier attempts towards this goal, we take one further step by setting up a standardized benchmarking pipeline for reproducible research, which integrates all the details about datasets, source code, hyper-parameter settings, running logs, and evaluation results. The benchmark is designed with comprehensiveness and sustainability in mind. It spans both matching and ranking tasks, and also allows anyone to easily follow and contribute. We believe that our benchmark could not only reduce the redundant efforts of researchers to re-implement or re-run existing baselines, but also drive more solid and reproducible research on recommender systems.