 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAISHELL-NER: Named Entity Recognition from Chinese Speech
Feb 17, 2022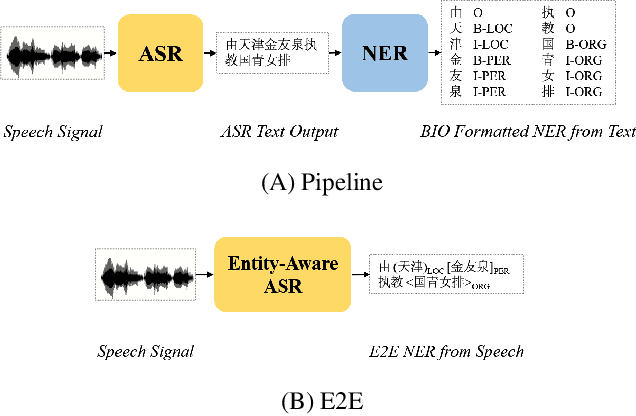
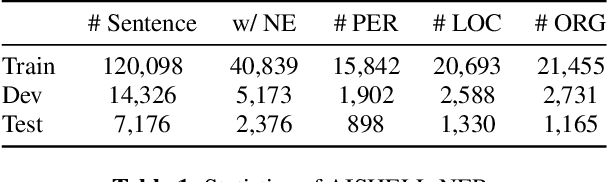
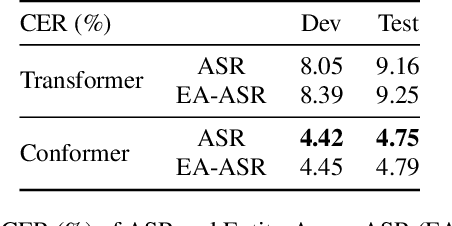
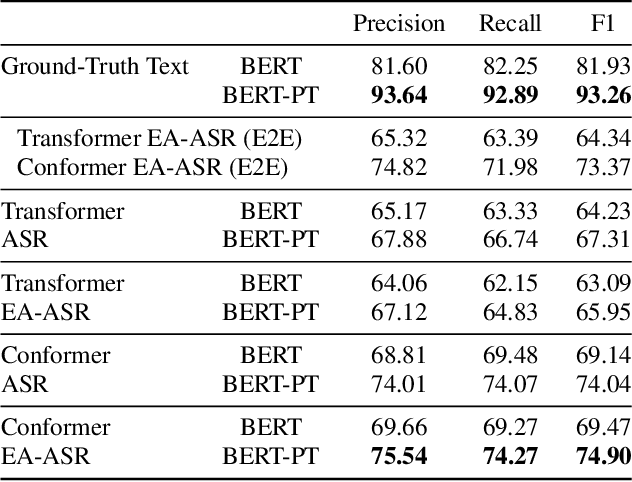
Named Entity Recognition (NER) from speech is among Spoken Language Understanding (SLU) tasks, aiming to extract semantic information from the speech signal. NER from speech is usually made through a two-step pipeline that consists of (1) processing the audio using an Automatic Speech Recognition (ASR) system and (2) applying an NER tagger to the ASR outputs. Recent works have shown the capability of the End-to-End (E2E) approach for NER from English and French speech, which is essentially entity-aware ASR. However, due to the many homophones and polyphones that exist in Chinese, NER from Chinese speech is effectively a more challenging task. In this paper, we introduce a new dataset AISEHLL-NER for NER from Chinese speech. Extensive experiments are conducted to explore the performance of several state-of-the-art methods. The results demonstrate that the performance could be improved by combining entity-aware ASR and pretrained NER tagger, which can be easily applied to the modern SLU pipeline. The dataset is publicly available at github.com/Alibaba-NLP/AISHELL-NER.
Prompt-Learning for Fine-Grained Entity Typing
Aug 24, 2021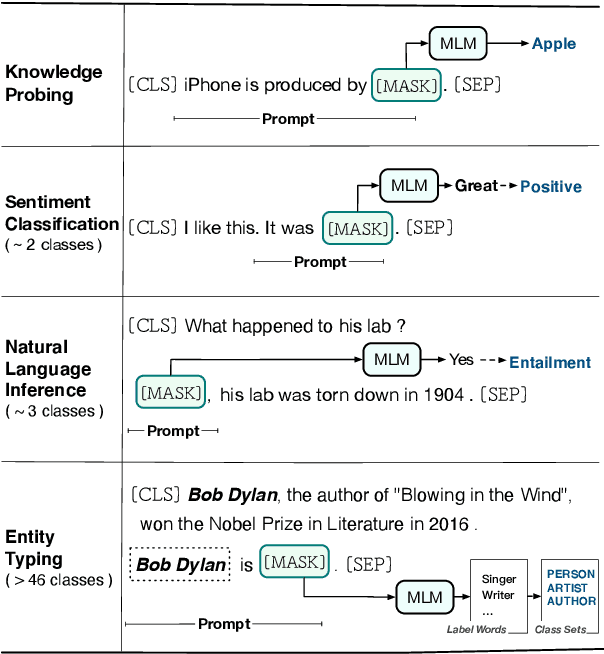


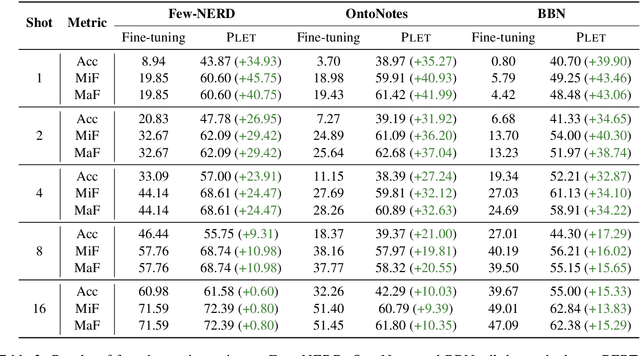
As an effective approach to tune pre-trained language models (PLMs) for specific tasks, prompt-learning has recently attracted much attention from researchers. By using \textit{cloze}-style language prompts to stimulate the versatile knowledge of PLMs, prompt-learning can achieve promising results on a series of NLP tasks, such as natural language inference, sentiment classification, and knowledge probing. In this work, we investigate the application of prompt-learning on fine-grained entity typing in fully supervised, few-shot and zero-shot scenarios. We first develop a simple and effective prompt-learning pipeline by constructing entity-oriented verbalizers and templates and conducting masked language modeling. Further, to tackle the zero-shot regime, we propose a self-supervised strategy that carries out distribution-level optimization in prompt-learning to automatically summarize the information of entity types. Extensive experiments on three fine-grained entity typing benchmarks (with up to 86 classes) under fully supervised, few-shot and zero-shot settings show that prompt-learning methods significantly outperform fine-tuning baselines, especially when the training data is insufficient.
Few-NERD: A Few-Shot Named Entity Recognition Dataset
Jun 02, 2021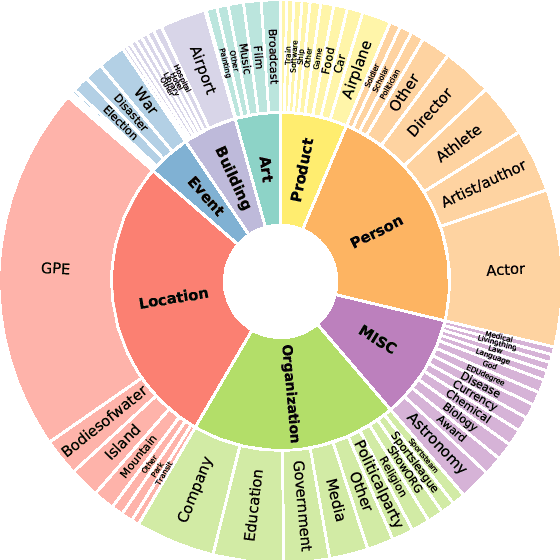

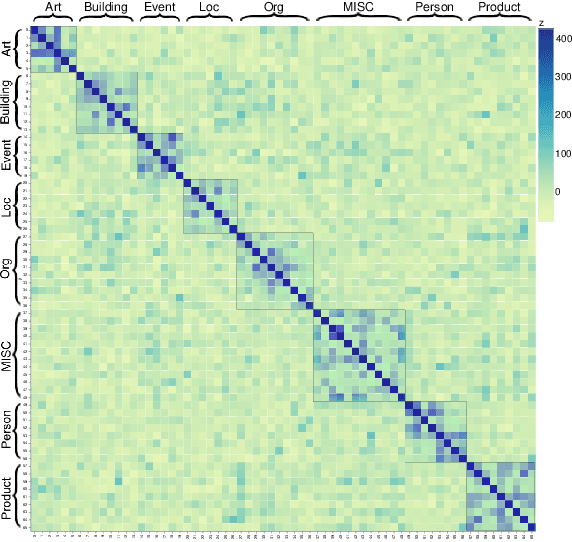
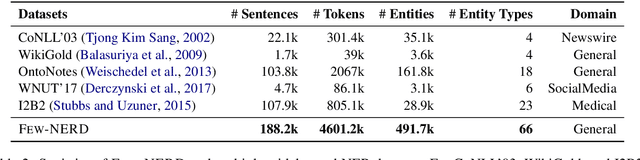
Recently, considerable literature has grown up around the theme of few-shot named entity recognition (NER), but little published benchmark data specifically focused on the practical and challenging task. Current approaches collect existing supervised NER datasets and re-organize them to the few-shot setting for empirical study. These strategies conventionally aim to recognize coarse-grained entity types with few examples, while in practice, most unseen entity types are fine-grained. In this paper, we present Few-NERD, a large-scale human-annotated few-shot NER dataset with a hierarchy of 8 coarse-grained and 66 fine-grained entity types. Few-NERD consists of 188,238 sentences from Wikipedia, 4,601,160 words are included and each is annotated as context or a part of a two-level entity type. To the best of our knowledge, this is the first few-shot NER dataset and the largest human-crafted NER dataset. We construct benchmark tasks with different emphases to comprehensively assess the generalization capability of models. Extensive empirical results and analysis show that Few-NERD is challenging and the problem requires further research. We make Few-NERD public at https://ningding97.github.io/fewnerd/.
Crowdsourcing Learning as Domain Adaptation: A Case Study on Named Entity Recognition
May 31, 2021
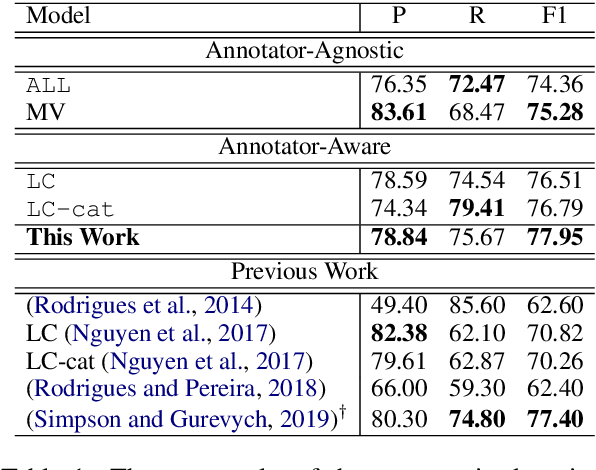
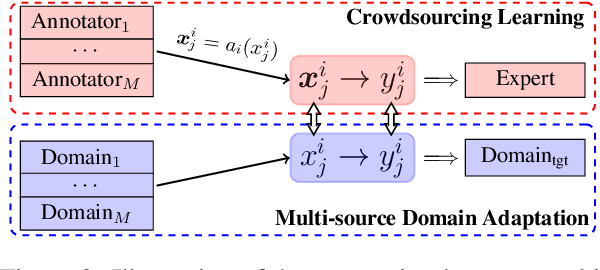
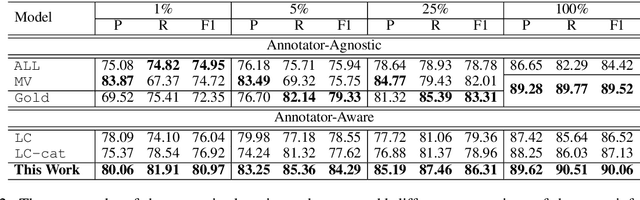
Crowdsourcing is regarded as one prospective solution for effective supervised learning, aiming to build large-scale annotated training data by crowd workers. Previous studies focus on reducing the influences from the noises of the crowdsourced annotations for supervised models. We take a different point in this work, regarding all crowdsourced annotations as gold-standard with respect to the individual annotators. In this way, we find that crowdsourcing could be highly similar to domain adaptation, and then the recent advances of cross-domain methods can be almost directly applied to crowdsourcing. Here we take named entity recognition (NER) as a study case, suggesting an annotator-aware representation learning model that inspired by the domain adaptation methods which attempt to capture effective domain-aware features. We investigate both unsupervised and supervised crowdsourcing learning, assuming that no or only small-scale expert annotations are available. Experimental results on a benchmark crowdsourced NER dataset show that our method is highly effective, leading to a new state-of-the-art performance. In addition, under the supervised setting, we can achieve impressive performance gains with only a very small scale of expert annotations.
Probing BERT in Hyperbolic Spaces
Apr 08, 2021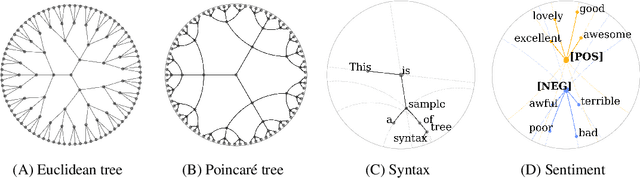
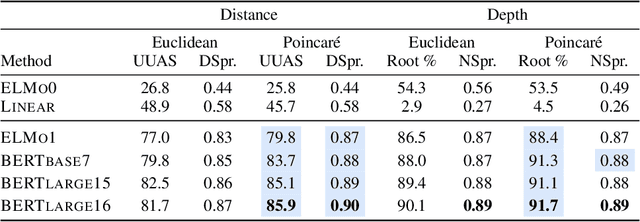
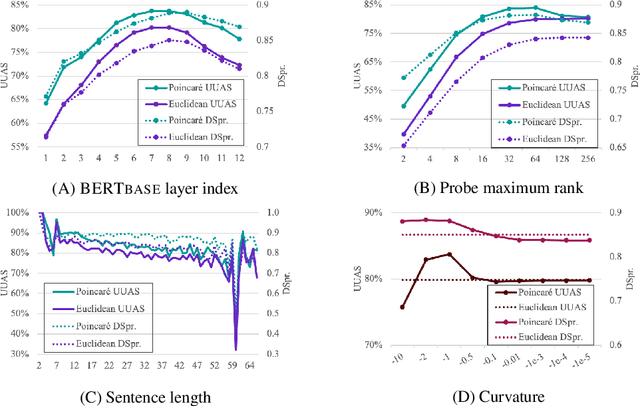

Recently, a variety of probing tasks are proposed to discover linguistic properties learned in contextualized word embeddings. Many of these works implicitly assume these embeddings lay in certain metric spaces, typically the Euclidean space. This work considers a family of geometrically special spaces, the hyperbolic spaces, that exhibit better inductive biases for hierarchical structures and may better reveal linguistic hierarchies encoded in contextualized representations. We introduce a Poincare probe, a structural probe projecting these embeddings into a Poincare subspace with explicitly defined hierarchies. We focus on two probing objectives: (a) dependency trees where the hierarchy is defined as head-dependent structures; (b) lexical sentiments where the hierarchy is defined as the polarity of words (positivity and negativity). We argue that a key desideratum of a probe is its sensitivity to the existence of linguistic structures. We apply our probes on BERT, a typical contextualized embedding model. In a syntactic subspace, our probe better recovers tree structures than Euclidean probes, revealing the possibility that the geometry of BERT syntax may not necessarily be Euclidean. In a sentiment subspace, we reveal two possible meta-embeddings for positive and negative sentiments and show how lexically-controlled contextualization would change the geometric localization of embeddings. We demonstrate the findings with our Poincare probe via extensive experiments and visualization. Our results can be reproduced at https://github.com/FranxYao/PoincareProbe.
Prototypical Representation Learning for Relation Extraction
Mar 22, 2021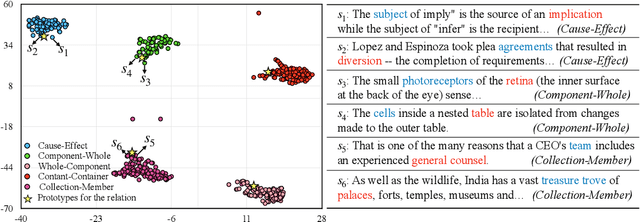
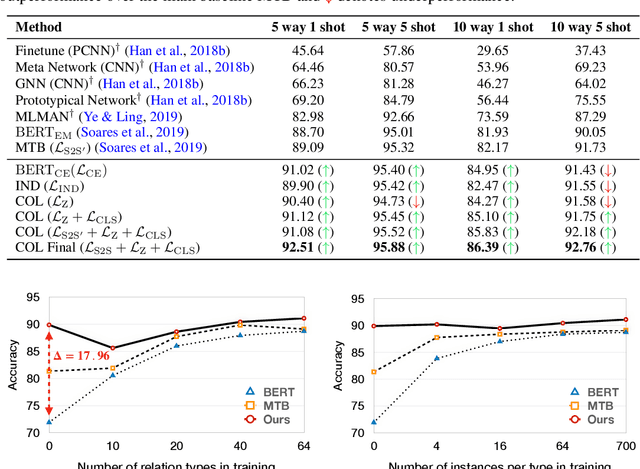
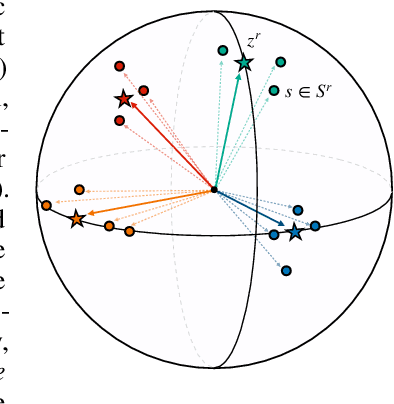
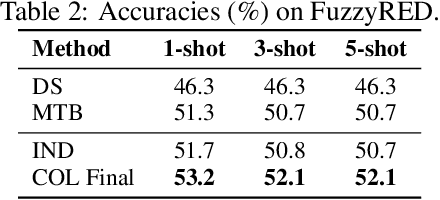
Recognizing relations between entities is a pivotal task of relational learning. Learning relation representations from distantly-labeled datasets is difficult because of the abundant label noise and complicated expressions in human language. This paper aims to learn predictive, interpretable, and robust relation representations from distantly-labeled data that are effective in different settings, including supervised, distantly supervised, and few-shot learning. Instead of solely relying on the supervision from noisy labels, we propose to learn prototypes for each relation from contextual information to best explore the intrinsic semantics of relations. Prototypes are representations in the feature space abstracting the essential semantics of relations between entities in sentences. We learn prototypes based on objectives with clear geometric interpretation, where the prototypes are unit vectors uniformly dispersed in a unit ball, and statement embeddings are centered at the end of their corresponding prototype vectors on the surface of the ball. This approach allows us to learn meaningful, interpretable prototypes for the final classification. Results on several relation learning tasks show that our model significantly outperforms the previous state-of-the-art models. We further demonstrate the robustness of the encoder and the interpretability of prototypes with extensive experiments.
Keyphrase Extraction with Dynamic Graph Convolutional Networks and Diversified Inference
Oct 24, 2020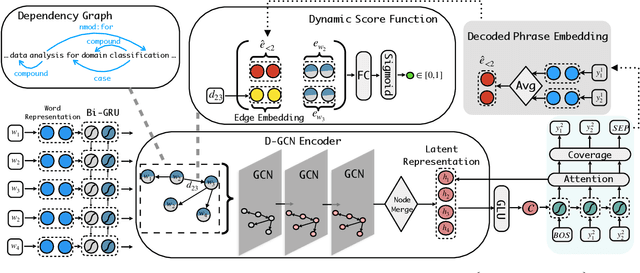
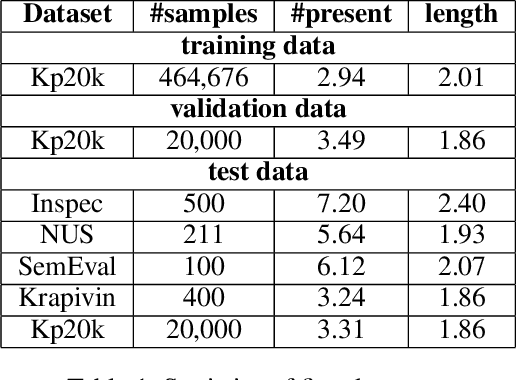
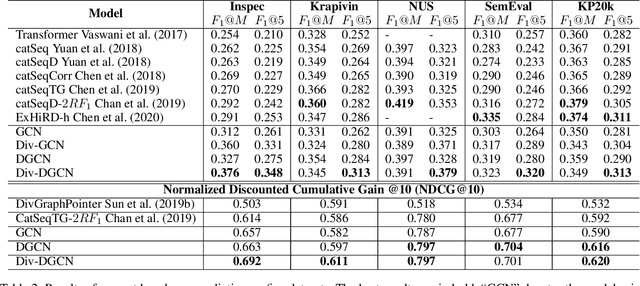
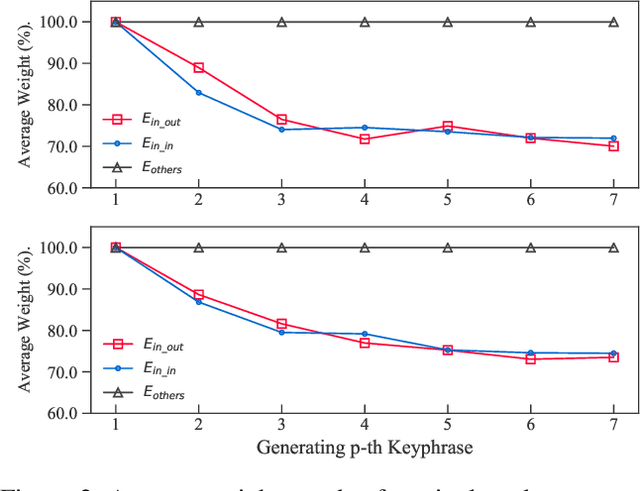
Keyphrase extraction (KE) aims to summarize a set of phrases that accurately express a concept or a topic covered in a given document. Recently, Sequence-to-Sequence (Seq2Seq) based generative framework is widely used in KE task, and it has obtained competitive performance on various benchmarks. The main challenges of Seq2Seq methods lie in acquiring informative latent document representation and better modeling the compositionality of the target keyphrases set, which will directly affect the quality of generated keyphrases. In this paper, we propose to adopt the Dynamic Graph Convolutional Networks (DGCN) to solve the above two problems simultaneously. Concretely, we explore to integrate dependency trees with GCN for latent representation learning. Moreover, the graph structure in our model is dynamically modified during the learning process according to the generated keyphrases. To this end, our approach is able to explicitly learn the relations within the keyphrases collection and guarantee the information interchange between encoder and decoder in both directions. Extensive experiments on various KE benchmark datasets demonstrate the effectiveness of our approach.
Coupling Distant Annotation and Adversarial Training for Cross-Domain Chinese Word Segmentation
Jul 16, 2020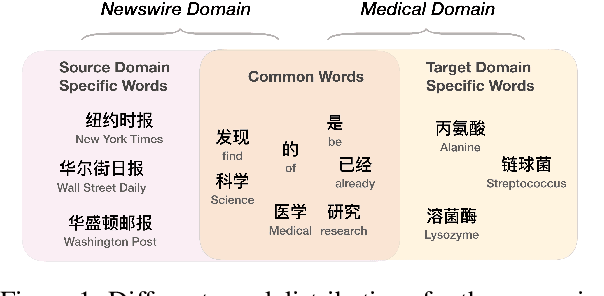
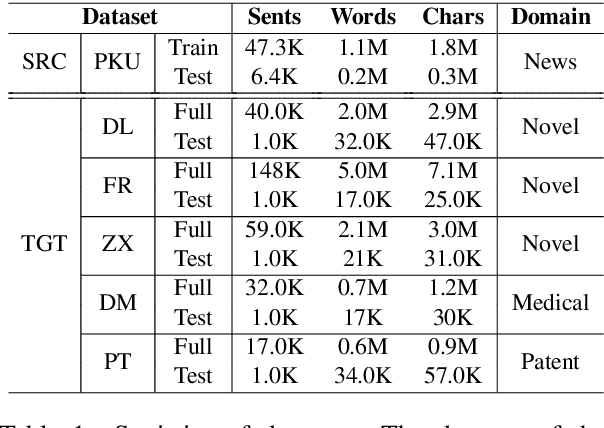
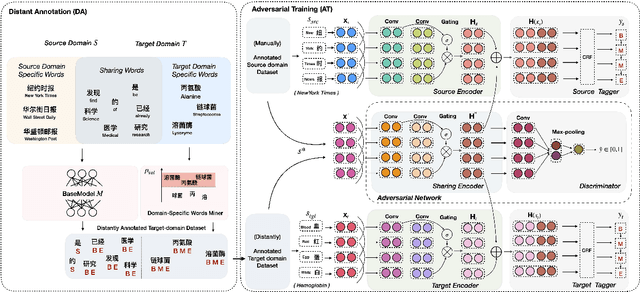
Fully supervised neural approaches have achieved significant progress in the task of Chinese word segmentation (CWS). Nevertheless, the performance of supervised models tends to drop dramatically when they are applied to out-of-domain data. Performance degradation is caused by the distribution gap across domains and the out of vocabulary (OOV) problem. In order to simultaneously alleviate these two issues, this paper proposes to couple distant annotation and adversarial training for cross-domain CWS. For distant annotation, we rethink the essence of "Chinese words" and design an automatic distant annotation mechanism that does not need any supervision or pre-defined dictionaries from the target domain. The approach could effectively explore domain-specific words and distantly annotate the raw texts for the target domain. For adversarial training, we develop a sentence-level training procedure to perform noise reduction and maximum utilization of the source domain information. Experiments on multiple real-world datasets across various domains show the superiority and robustness of our model, significantly outperforming previous state-of-the-art cross-domain CWS methods.