 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixReorg: Cross-Modal Mixed Patch Reorganization is a Good Mask Learner for Open-World Semantic Segmentation
Aug 09, 2023



Recently, semantic segmentation models trained with image-level text supervision have shown promising results in challenging open-world scenarios. However, these models still face difficulties in learning fine-grained semantic alignment at the pixel level and predicting accurate object masks. To address this issue, we propose MixReorg, a novel and straightforward pre-training paradigm for semantic segmentation that enhances a model's ability to reorganize patches mixed across images, exploring both local visual relevance and global semantic coherence. Our approach involves generating fine-grained patch-text pairs data by mixing image patches while preserving the correspondence between patches and text. The model is then trained to minimize the segmentation loss of the mixed images and the two contrastive losses of the original and restored features. With MixReorg as a mask learner, conventional text-supervised semantic segmentation models can achieve highly generalizable pixel-semantic alignment ability, which is crucial for open-world segmentation. After training with large-scale image-text data, MixReorg models can be applied directly to segment visual objects of arbitrary categories, without the need for further fine-tuning. Our proposed framework demonstrates strong performance on popular zero-shot semantic segmentation benchmarks, outperforming GroupViT by significant margins of 5.0%, 6.2%, 2.5%, and 3.4% mIoU on PASCAL VOC2012, PASCAL Context, MS COCO, and ADE20K, respectively.
Language-free Compositional Action Generation via Decoupling Refinement
Jul 07, 2023Composing simple elements into complex concepts is crucial yet challenging, especially for 3D action generation. Existing methods largely rely on extensive neural language annotations to discern composable latent semantics, a process that is often costly and labor-intensive. In this study, we introduce a novel framework to generate compositional actions without reliance on language auxiliaries. Our approach consists of three main components: Action Coupling, Conditional Action Generation, and Decoupling Refinement. Action Coupling utilizes an energy model to extract the attention masks of each sub-action, subsequently integrating two actions using these attentions to generate pseudo-training examples. Then, we employ a conditional generative model, CVAE, to learn a latent space, facilitating the diverse generation. Finally, we propose Decoupling Refinement, which leverages a self-supervised pre-trained model MAE to ensure semantic consistency between the sub-actions and compositional actions. This refinement process involves rendering generated 3D actions into 2D space, decoupling these images into two sub-segments, using the MAE model to restore the complete image from sub-segments, and constraining the recovered images to match images rendered from raw sub-actions. Due to the lack of existing datasets containing both sub-actions and compositional actions, we created two new datasets, named HumanAct-C and UESTC-C, and present a corresponding evaluation metric. Both qualitative and quantitative assessments are conducted to show our efficacy.
LiDAR-NeRF: Novel LiDAR View Synthesis via Neural Radiance Fields
Apr 20, 2023We introduce a new task, novel view synthesis for LiDAR sensors. While traditional model-based LiDAR simulators with style-transfer neural networks can be applied to render novel views, they fall short in producing accurate and realistic LiDAR patterns, because the renderers they rely on exploit game engines, which are not differentiable. We address this by formulating, to the best of our knowledge, the first differentiable LiDAR renderer, and propose an end-to-end framework, LiDAR-NeRF, leveraging a neural radiance field (NeRF) to enable jointly learning the geometry and the attributes of 3D points. To evaluate the effectiveness of our approach, we establish an object-centric multi-view LiDAR dataset, dubbed NeRF-MVL. It contains observations of objects from 9 categories seen from 360-degree viewpoints captured with multiple LiDAR sensors. Our extensive experiments on the scene-level KITTI-360 dataset, and on our object-level NeRF-MVL show that our LiDAR- NeRF surpasses the model-based algorithms significantly.
Traditional Classification Neural Networks are Good Generators: They are Competitive with DDPMs and GANs
Dec 08, 2022Classifiers and generators have long been separated. We break down this separation and showcase that conventional neural network classifiers can generate high-quality images of a large number of categories, being comparable to the state-of-the-art generative models (e.g., DDPMs and GANs). We achieve this by computing the partial derivative of the classification loss function with respect to the input to optimize the input to produce an image. Since it is widely known that directly optimizing the inputs is similar to targeted adversarial attacks incapable of generating human-meaningful images, we propose a mask-based stochastic reconstruction module to make the gradients semantic-aware to synthesize plausible images. We further propose a progressive-resolution technique to guarantee fidelity, which produces photorealistic images. Furthermore, we introduce a distance metric loss and a non-trivial distribution loss to ensure classification neural networks can synthesize diverse and high-fidelity images. Using traditional neural network classifiers, we can generate good-quality images of 256$\times$256 resolution on ImageNet. Intriguingly, our method is also applicable to text-to-image generation by regarding image-text foundation models as generalized classifiers. Proving that classifiers have learned the data distribution and are ready for image generation has far-reaching implications, for classifiers are much easier to train than generative models like DDPMs and GANs. We don't even need to train classification models because tons of public ones are available for download. Also, this holds great potential for the interpretability and robustness of classifiers. Project page is at \url{https://classifier-as-generator.github.io/}.
Structure-Preserving 3D Garment Modeling with Neural Sewing Machines
Nov 12, 2022



3D Garment modeling is a critical and challenging topic in the area of computer vision and graphics, with increasing attention focused on garment representation learning, garment reconstruction, and controllable garment manipulation, whereas existing methods were constrained to model garments under specific categories or with relatively simple topologies. In this paper, we propose a novel Neural Sewing Machine (NSM), a learning-based framework for structure-preserving 3D garment modeling, which is capable of learning representations for garments with diverse shapes and topologies and is successfully applied to 3D garment reconstruction and controllable manipulation. To model generic garments, we first obtain sewing pattern embedding via a unified sewing pattern encoding module, as the sewing pattern can accurately describe the intrinsic structure and the topology of the 3D garment. Then we use a 3D garment decoder to decode the sewing pattern embedding into a 3D garment using the UV-position maps with masks. To preserve the intrinsic structure of the predicted 3D garment, we introduce an inner-panel structure-preserving loss, an inter-panel structure-preserving loss, and a surface-normal loss in the learning process of our framework. We evaluate NSM on the public 3D garment dataset with sewing patterns with diverse garment shapes and categories. Extensive experiments demonstrate that the proposed NSM is capable of representing 3D garments under diverse garment shapes and topologies, realistically reconstructing 3D garments from 2D images with the preserved structure, and accurately manipulating the 3D garment categories, shapes, and topologies, outperforming the state-of-the-art methods by a clear margin.
Learning Self-Regularized Adversarial Views for Self-Supervised Vision Transformers
Oct 16, 2022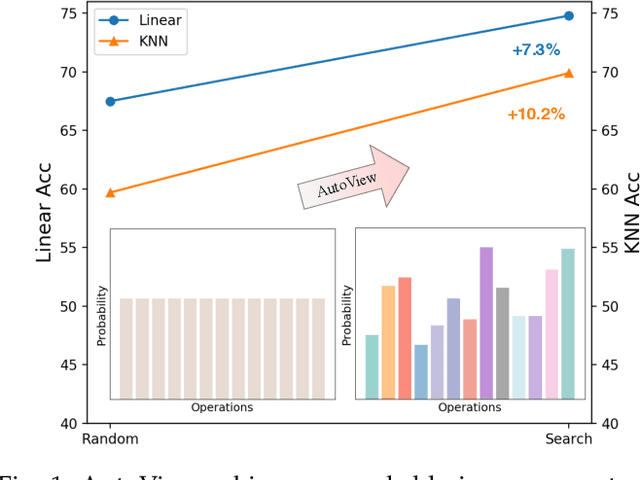
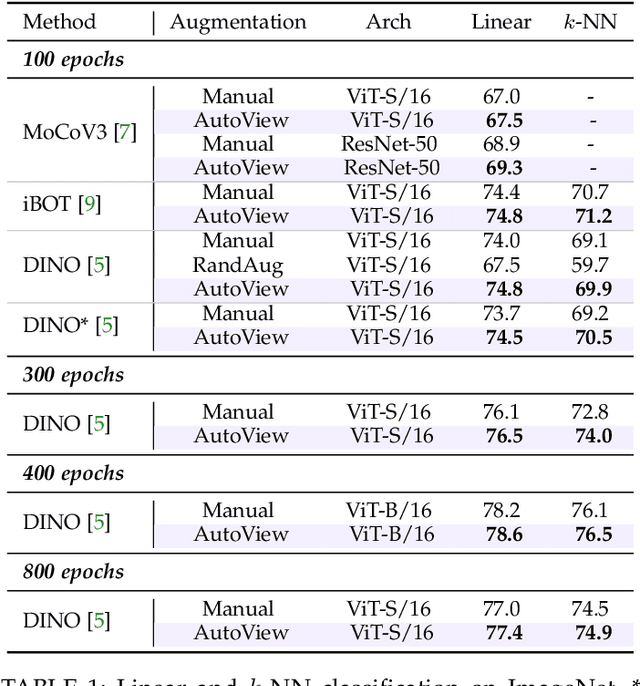
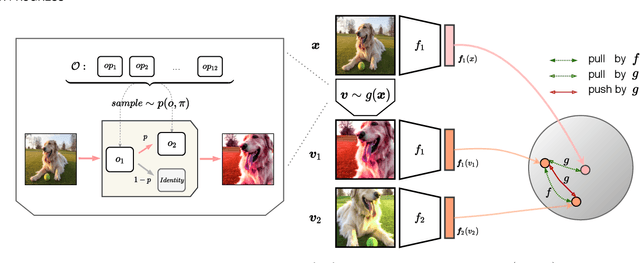

Automatic data augmentation (AutoAugment) strategies are indispensable in supervised data-efficient training protocols of vision transformers, and have led to state-of-the-art results in supervised learning. Despite the success, its development and application on self-supervised vision transformers have been hindered by several barriers, including the high search cost, the lack of supervision, and the unsuitable search space. In this work, we propose AutoView, a self-regularized adversarial AutoAugment method, to learn views for self-supervised vision transformers, by addressing the above barriers. First, we reduce the search cost of AutoView to nearly zero by learning views and network parameters simultaneously in a single forward-backward step, minimizing and maximizing the mutual information among different augmented views, respectively. Then, to avoid information collapse caused by the lack of label supervision, we propose a self-regularized loss term to guarantee the information propagation. Additionally, we present a curated augmentation policy search space for self-supervised learning, by modifying the generally used search space designed for supervised learning. On ImageNet, our AutoView achieves remarkable improvement over RandAug baseline (+10.2% k-NN accuracy), and consistently outperforms sota manually tuned view policy by a clear margin (up to +1.3% k-NN accuracy). Extensive experiments show that AutoView pretraining also benefits downstream tasks (+1.2% mAcc on ADE20K Semantic Segmentation and +2.8% mAP on revisited Oxford Image Retrieval benchmark) and improves model robustness (+2.3% Top-1 Acc on ImageNet-A and +1.0% AUPR on ImageNet-O). Code and models will be available at https://github.com/Trent-tangtao/AutoView.
Understanding Weight Similarity of Neural Networks via Chain Normalization Rule and Hypothesis-Training-Testing
Aug 08, 2022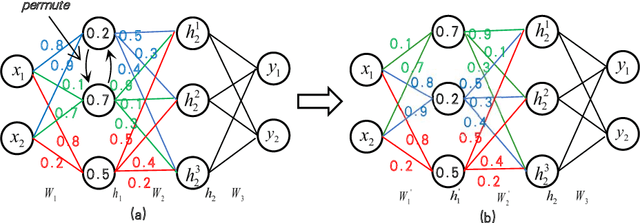
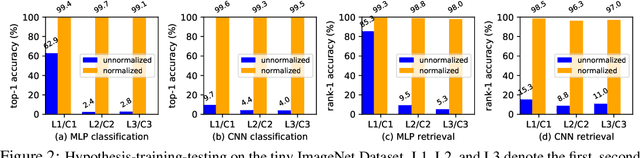

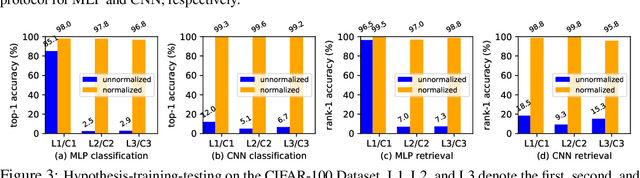
We present a weight similarity measure method that can quantify the weight similarity of non-convex neural networks. To understand the weight similarity of different trained models, we propose to extract the feature representation from the weights of neural networks. We first normalize the weights of neural networks by introducing a chain normalization rule, which is used for weight representation learning and weight similarity measure. We extend the traditional hypothesis-testing method to a hypothesis-training-testing statistical inference method to validate the hypothesis on the weight similarity of neural networks. With the chain normalization rule and the new statistical inference, we study the weight similarity measure on Multi-Layer Perceptron (MLP), Convolutional Neural Network (CNN), and Recurrent Neural Network (RNN), and find that the weights of an identical neural network optimized with the Stochastic Gradient Descent (SGD) algorithm converge to a similar local solution in a metric space. The weight similarity measure provides more insight into the local solutions of neural networks. Experiments on several datasets consistently validate the hypothesis of weight similarity measure.
Beyond Fixation: Dynamic Window Visual Transformer
Apr 08, 2022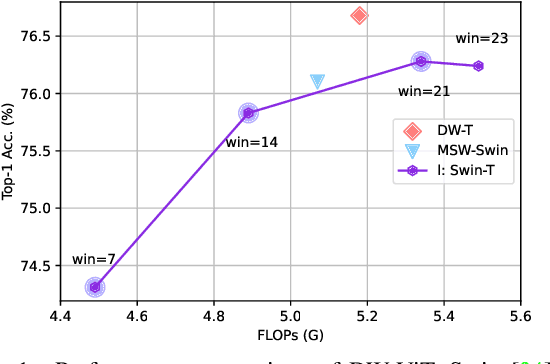
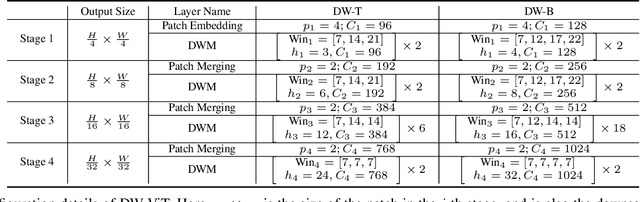
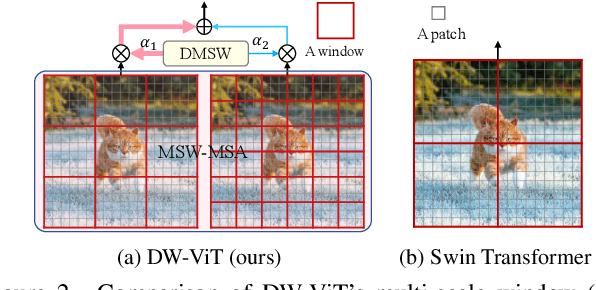
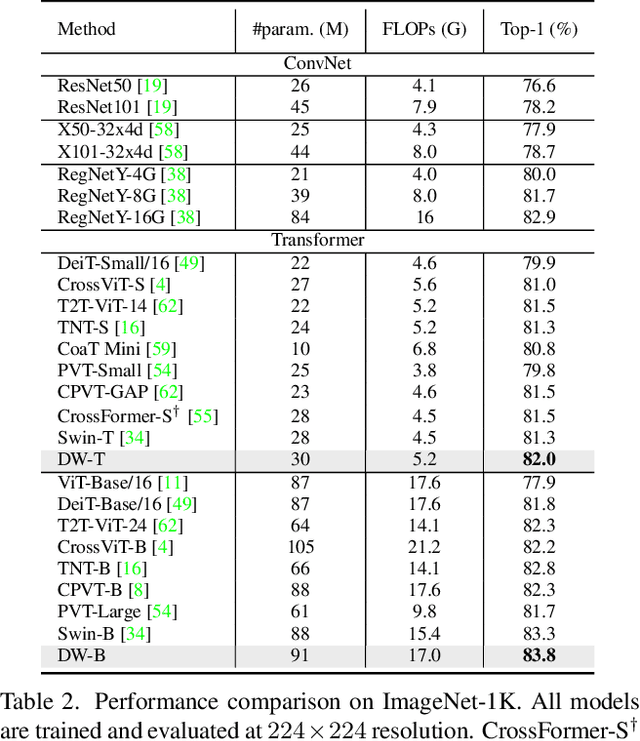
Recently, a surge of interest in visual transformers is to reduce the computational cost by limiting the calculation of self-attention to a local window. Most current work uses a fixed single-scale window for modeling by default, ignoring the impact of window size on model performance. However, this may limit the modeling potential of these window-based models for multi-scale information. In this paper, we propose a novel method, named Dynamic Window Vision Transformer (DW-ViT). The dynamic window strategy proposed by DW-ViT goes beyond the model that employs a fixed single window setting. To the best of our knowledge, we are the first to use dynamic multi-scale windows to explore the upper limit of the effect of window settings on model performance. In DW-ViT, multi-scale information is obtained by assigning windows of different sizes to different head groups of window multi-head self-attention. Then, the information is dynamically fused by assigning different weights to the multi-scale window branches. We conducted a detailed performance evaluation on three datasets, ImageNet-1K, ADE20K, and COCO. Compared with related state-of-the-art (SoTA) methods, DW-ViT obtains the best performance. Specifically, compared with the current SoTA Swin Transformers \cite{liu2021swin}, DW-ViT has achieved consistent and substantial improvements on all three datasets with similar parameters and computational costs. In addition, DW-ViT exhibits good scalability and can be easily inserted into any window-based visual transformers.
Automated Progressive Learning for Efficient Training of Vision Transformers
Mar 28, 2022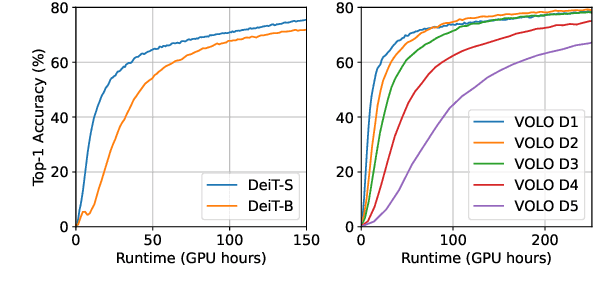
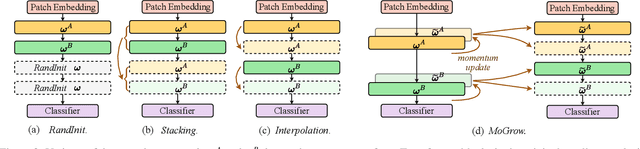
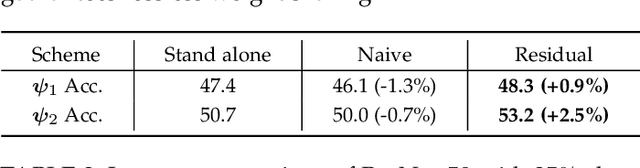
Recent advances in vision Transformers (ViTs) have come with a voracious appetite for computing power, high-lighting the urgent need to develop efficient training methods for ViTs. Progressive learning, a training scheme where the model capacity grows progressively during training, has started showing its ability in efficient training. In this paper, we take a practical step towards efficient training of ViTs by customizing and automating progressive learning. First, we develop a strong manual baseline for progressive learning of ViTs, by introducing momentum growth (MoGrow) to bridge the gap brought by model growth. Then, we propose automated progressive learning (AutoProg), an efficient training scheme that aims to achieve lossless acceleration by automatically increasing the training overload on-the-fly; this is achieved by adaptively deciding whether, where and how much should the model grow during progressive learning. Specifically, we first relax the optimization of the growth schedule to sub-network architecture optimization problem, then propose one-shot estimation of the sub-network performance via an elastic supernet. The searching overhead is reduced to minimal by recycling the parameters of the supernet. Extensive experiments of efficient training on ImageNet with two representative ViT models, DeiT and VOLO, demonstrate that AutoProg can accelerate ViTs training by up to 85.1% with no performance drop. Code: https://github.com/changlin31/AutoProg
DS-Net++: Dynamic Weight Slicing for Efficient Inference in CNNs and Transformers
Sep 21, 2021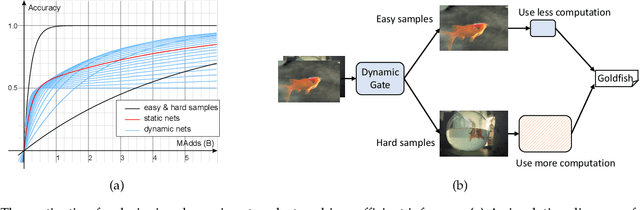
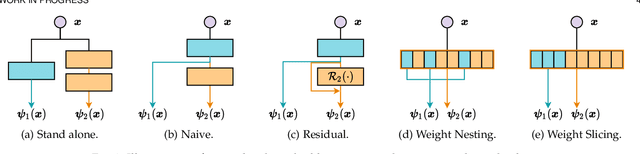
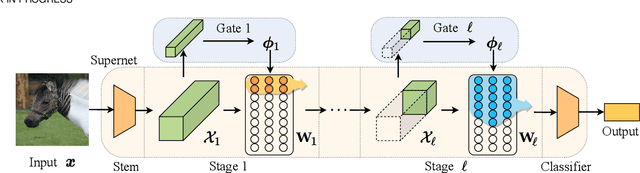
Dynamic networks have shown their promising capability in reducing theoretical computation complexity by adapting their architectures to the input during inference. However, their practical runtime usually lags behind the theoretical acceleration due to inefficient sparsity. Here, we explore a hardware-efficient dynamic inference regime, named dynamic weight slicing, which adaptively slice a part of network parameters for inputs with diverse difficulty levels, while keeping parameters stored statically and contiguously in hardware to prevent the extra burden of sparse computation. Based on this scheme, we present dynamic slimmable network (DS-Net) and dynamic slice-able network (DS-Net++) by input-dependently adjusting filter numbers of CNNs and multiple dimensions in both CNNs and transformers, respectively. To ensure sub-network generality and routing fairness, we propose a disentangled two-stage optimization scheme with training techniques such as in-place bootstrapping (IB), multi-view consistency (MvCo) and sandwich gate sparsification (SGS) to train supernet and gate separately. Extensive experiments on 4 datasets and 3 different network architectures demonstrate our method consistently outperforms state-of-the-art static and dynamic model compression methods by a large margin (up to 6.6%). Typically, DS-Net++ achieves 2-4x computation reduction and 1.62x real-world acceleration over MobileNet, ResNet-50 and Vision Transformer, with minimal accuracy drops (0.1-0.3%) on ImageNet. Code release: https://github.com/changlin31/DS-Net