 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuanbin Li
WMFormer++: Nested Transformer for Visible Watermark Removal via Implict Joint Learning
Aug 22, 2023
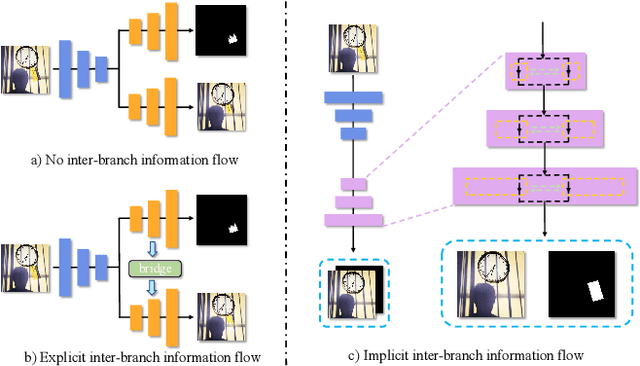
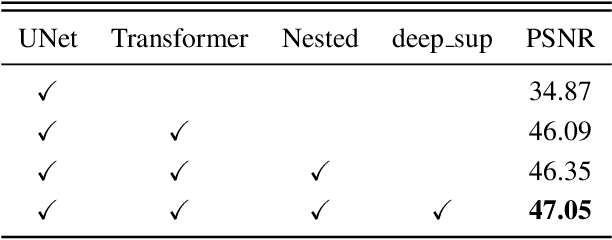

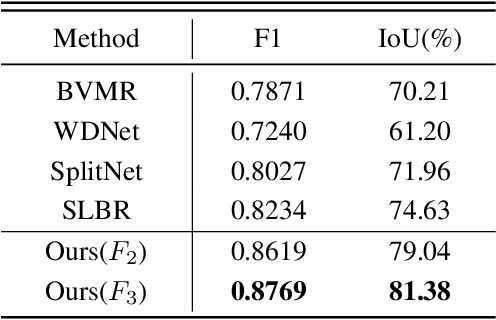
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches--one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach's remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Divide and Adapt: Active Domain Adaptation via Customized Learning
Jul 21, 2023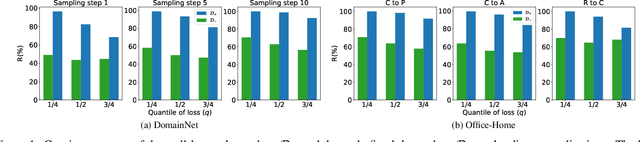
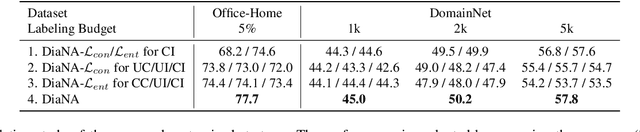

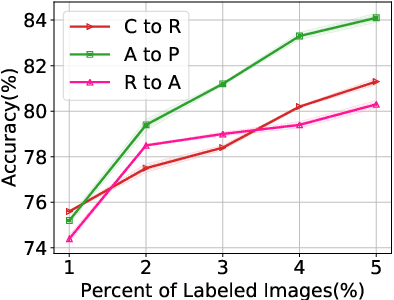
Active domain adaptation (ADA) aims to improve the model adaptation performance by incorporating active learning (AL) techniques to label a maximally-informative subset of target samples. Conventional AL methods do not consider the existence of domain shift, and hence, fail to identify the truly valuable samples in the context of domain adaptation. To accommodate active learning and domain adaption, the two naturally different tasks, in a collaborative framework, we advocate that a customized learning strategy for the target data is the key to the success of ADA solutions. We present Divide-and-Adapt (DiaNA), a new ADA framework that partitions the target instances into four categories with stratified transferable properties. With a novel data subdivision protocol based on uncertainty and domainness, DiaNA can accurately recognize the most gainful samples. While sending the informative instances for annotation, DiaNA employs tailored learning strategies for the remaining categories. Furthermore, we propose an informativeness score that unifies the data partitioning criteria. This enables the use of a Gaussian mixture model (GMM) to automatically sample unlabeled data into the proposed four categories. Thanks to the "divideand-adapt" spirit, DiaNA can handle data with large variations of domain gap. In addition, we show that DiaNA can generalize to different domain adaptation settings, such as unsupervised domain adaptation (UDA), semi-supervised domain adaptation (SSDA), source-free domain adaptation (SFDA), etc.
Advancing Visual Grounding with Scene Knowledge: Benchmark and Method
Jul 21, 2023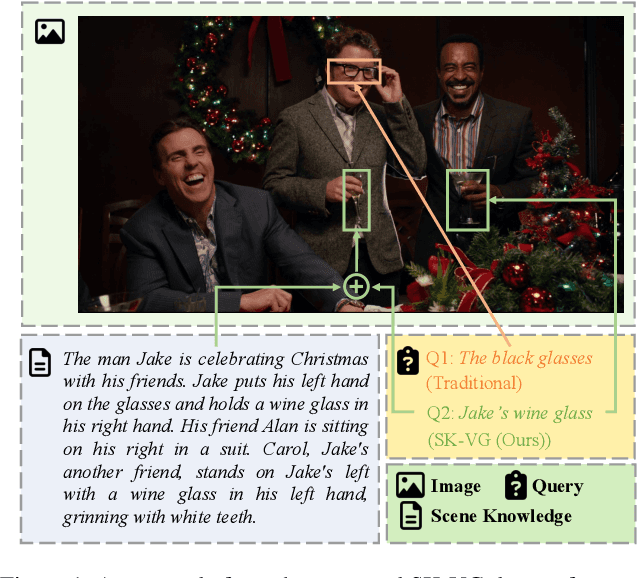

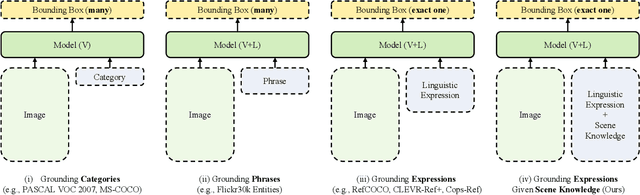
Visual grounding (VG) aims to establish fine-grained alignment between vision and language. Ideally, it can be a testbed for vision-and-language models to evaluate their understanding of the images and texts and their reasoning abilities over their joint space. However, most existing VG datasets are constructed using simple description texts, which do not require sufficient reasoning over the images and texts. This has been demonstrated in a recent study~\cite{luo2022goes}, where a simple LSTM-based text encoder without pretraining can achieve state-of-the-art performance on mainstream VG datasets. Therefore, in this paper, we propose a novel benchmark of \underline{S}cene \underline{K}nowledge-guided \underline{V}isual \underline{G}rounding (SK-VG), where the image content and referring expressions are not sufficient to ground the target objects, forcing the models to have a reasoning ability on the long-form scene knowledge. To perform this task, we propose two approaches to accept the triple-type input, where the former embeds knowledge into the image features before the image-query interaction; the latter leverages linguistic structure to assist in computing the image-text matching. We conduct extensive experiments to analyze the above methods and show that the proposed approaches achieve promising results but still leave room for improvement, including performance and interpretability. The dataset and code are available at \url{https://github.com/zhjohnchan/SK-VG}.
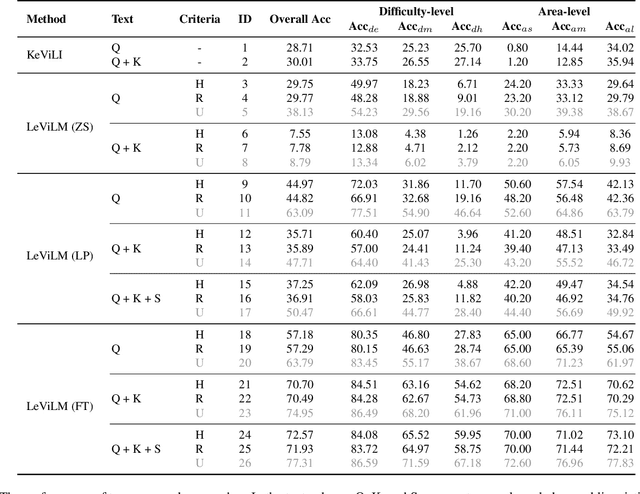
Bridging Vision and Language Encoders: Parameter-Efficient Tuning for Referring Image Segmentation
Jul 21, 2023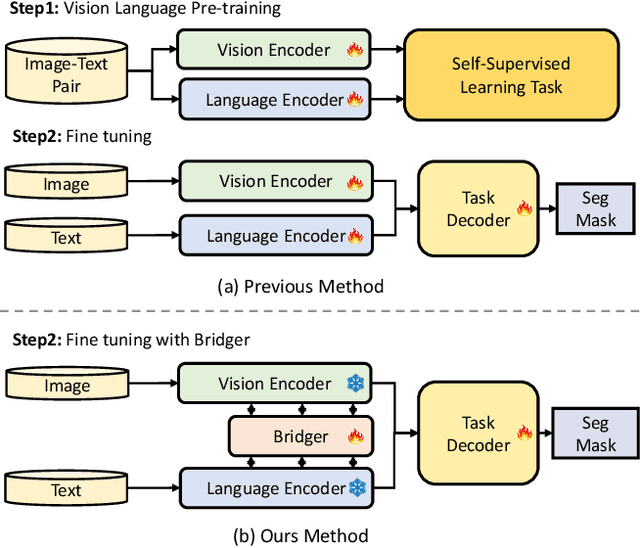
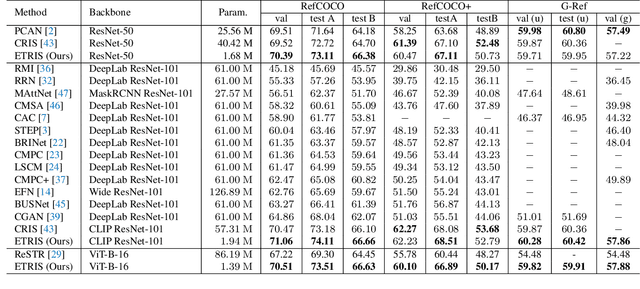
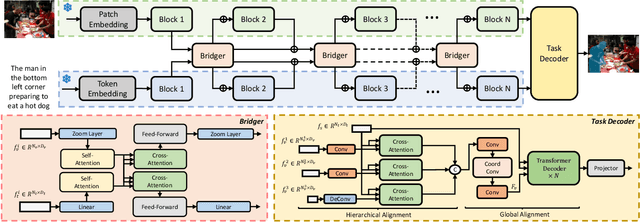
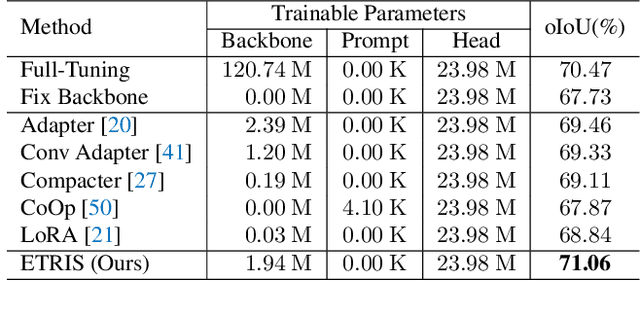
Parameter Efficient Tuning (PET) has gained attention for reducing the number of parameters while maintaining performance and providing better hardware resource savings, but few studies investigate dense prediction tasks and interaction between modalities. In this paper, we do an investigation of efficient tuning problems on referring image segmentation. We propose a novel adapter called Bridger to facilitate cross-modal information exchange and inject task-specific information into the pre-trained model. We also design a lightweight decoder for image segmentation. Our approach achieves comparable or superior performance with only 1.61\% to 3.38\% backbone parameter updates, evaluated on challenging benchmarks. The code is available at \url{https://github.com/kkakkkka/ETRIS}.
Improved Distribution Matching for Dataset Condensation
Jul 19, 2023
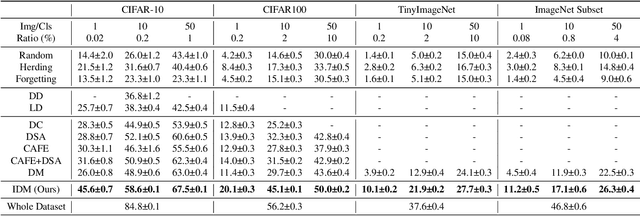
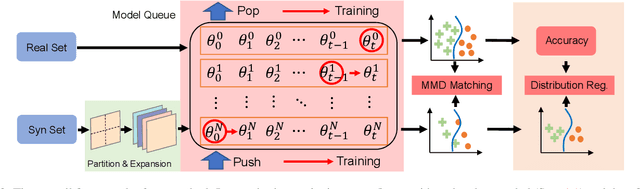
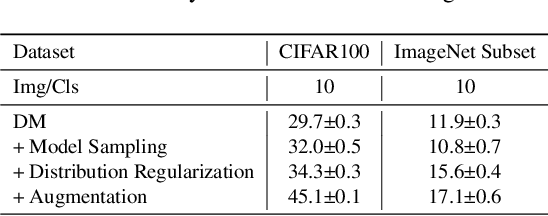
Dataset Condensation aims to condense a large dataset into a smaller one while maintaining its ability to train a well-performing model, thus reducing the storage cost and training effort in deep learning applications. However, conventional dataset condensation methods are optimization-oriented and condense the dataset by performing gradient or parameter matching during model optimization, which is computationally intensive even on small datasets and models. In this paper, we propose a novel dataset condensation method based on distribution matching, which is more efficient and promising. Specifically, we identify two important shortcomings of naive distribution matching (i.e., imbalanced feature numbers and unvalidated embeddings for distance computation) and address them with three novel techniques (i.e., partitioning and expansion augmentation, efficient and enriched model sampling, and class-aware distribution regularization). Our simple yet effective method outperforms most previous optimization-oriented methods with much fewer computational resources, thereby scaling data condensation to larger datasets and models. Extensive experiments demonstrate the effectiveness of our method. Codes are available at https://github.com/uitrbn/IDM
SkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training
Jul 17, 2023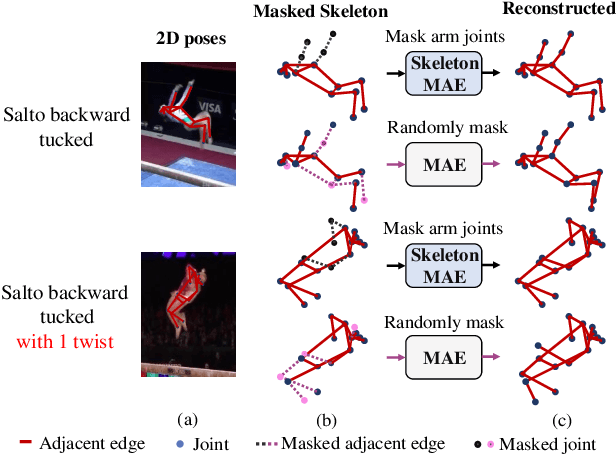
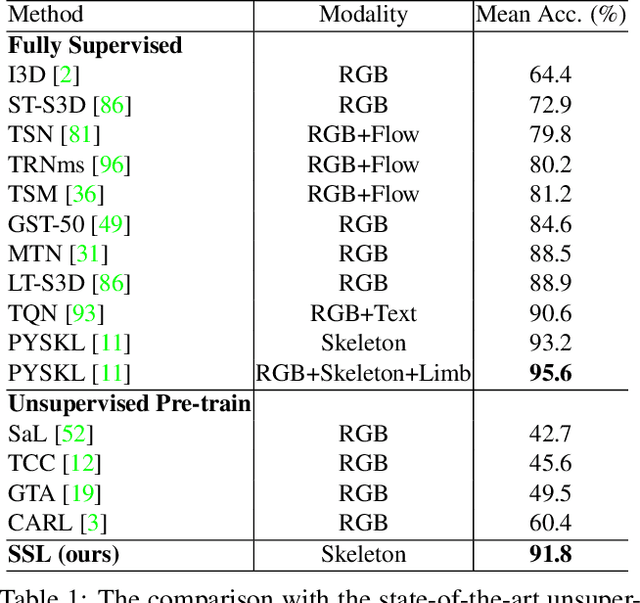
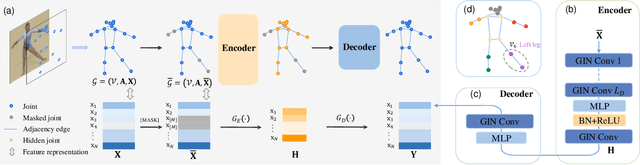
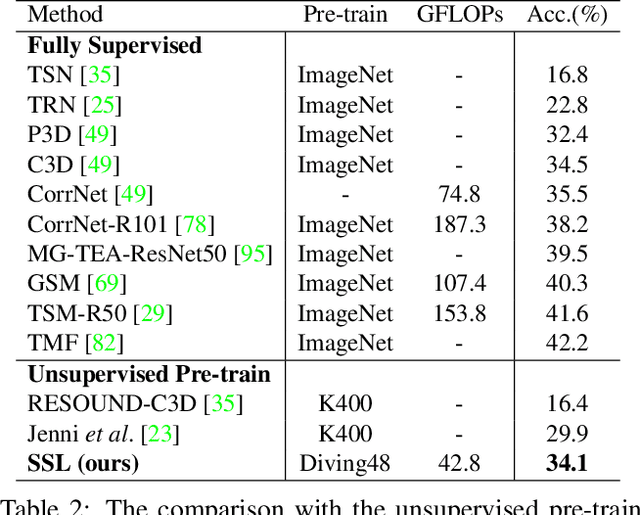
Skeleton sequence representation learning has shown great advantages for action recognition due to its promising ability to model human joints and topology. However, the current methods usually require sufficient labeled data for training computationally expensive models, which is labor-intensive and time-consuming. Moreover, these methods ignore how to utilize the fine-grained dependencies among different skeleton joints to pre-train an efficient skeleton sequence learning model that can generalize well across different datasets. In this paper, we propose an efficient skeleton sequence learning framework, named Skeleton Sequence Learning (SSL). To comprehensively capture the human pose and obtain discriminative skeleton sequence representation, we build an asymmetric graph-based encoder-decoder pre-training architecture named SkeletonMAE, which embeds skeleton joint sequence into Graph Convolutional Network (GCN) and reconstructs the masked skeleton joints and edges based on the prior human topology knowledge. Then, the pre-trained SkeletonMAE encoder is integrated with the Spatial-Temporal Representation Learning (STRL) module to build the SSL framework. Extensive experimental results show that our SSL generalizes well across different datasets and outperforms the state-of-the-art self-supervised skeleton-based action recognition methods on FineGym, Diving48, NTU 60 and NTU 120 datasets. Additionally, we obtain comparable performance to some fully supervised methods. The code is avaliable at https://github.com/HongYan1123/SkeletonMAE.
Semi-DETR: Semi-Supervised Object Detection with Detection Transformers
Jul 16, 2023

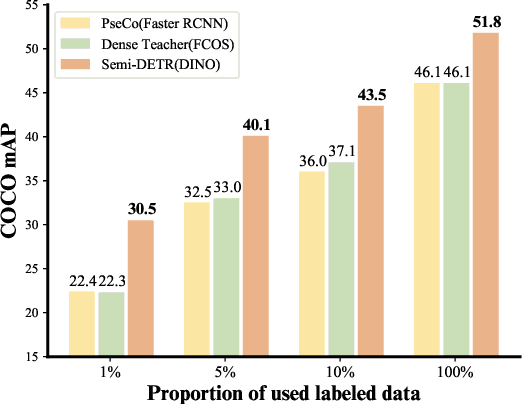
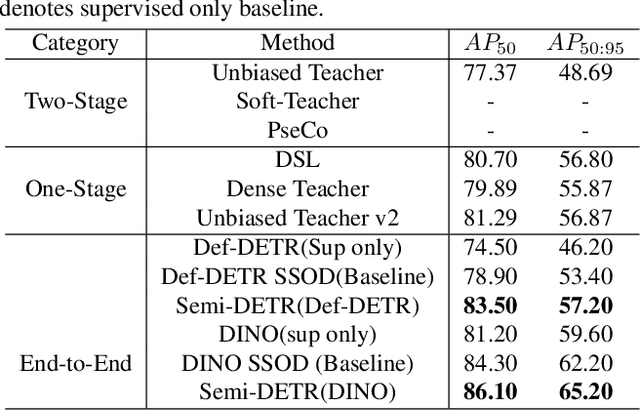
We analyze the DETR-based framework on semi-supervised object detection (SSOD) and observe that (1) the one-to-one assignment strategy generates incorrect matching when the pseudo ground-truth bounding box is inaccurate, leading to training inefficiency; (2) DETR-based detectors lack deterministic correspondence between the input query and its prediction output, which hinders the applicability of the consistency-based regularization widely used in current SSOD methods. We present Semi-DETR, the first transformer-based end-to-end semi-supervised object detector, to tackle these problems. Specifically, we propose a Stage-wise Hybrid Matching strategy that combines the one-to-many assignment and one-to-one assignment strategies to improve the training efficiency of the first stage and thus provide high-quality pseudo labels for the training of the second stage. Besides, we introduce a Crossview Query Consistency method to learn the semantic feature invariance of object queries from different views while avoiding the need to find deterministic query correspondence. Furthermore, we propose a Cost-based Pseudo Label Mining module to dynamically mine more pseudo boxes based on the matching cost of pseudo ground truth bounding boxes for consistency training. Extensive experiments on all SSOD settings of both COCO and Pascal VOC benchmark datasets show that our Semi-DETR method outperforms all state-of-the-art methods by clear margins. The PaddlePaddle version code1 is at https://github.com/PaddlePaddle/PaddleDetection/tree/develop/configs/semi_det/semi_detr.
Universal Semi-supervised Model Adaptation via Collaborative Consistency Training
Jul 07, 2023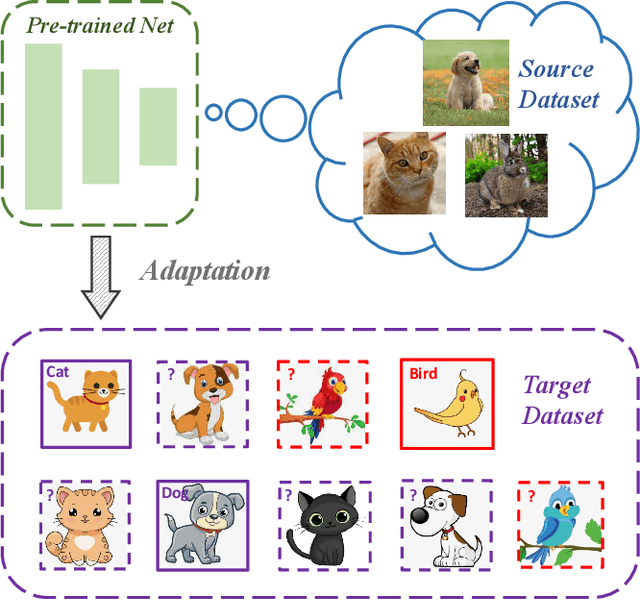
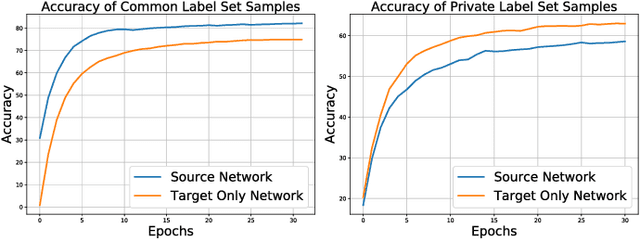

In this paper, we introduce a realistic and challenging domain adaptation problem called Universal Semi-supervised Model Adaptation (USMA), which i) requires only a pre-trained source model, ii) allows the source and target domain to have different label sets, i.e., they share a common label set and hold their own private label set, and iii) requires only a few labeled samples in each class of the target domain. To address USMA, we propose a collaborative consistency training framework that regularizes the prediction consistency between two models, i.e., a pre-trained source model and its variant pre-trained with target data only, and combines their complementary strengths to learn a more powerful model. The rationale of our framework stems from the observation that the source model performs better on common categories than the target-only model, while on target-private categories, the target-only model performs better. We also propose a two-perspective, i.e., sample-wise and class-wise, consistency regularization to improve the training. Experimental results demonstrate the effectiveness of our method on several benchmark datasets.
Exploration and Exploitation of Unlabeled Data for Open-Set Semi-Supervised Learning
Jun 30, 2023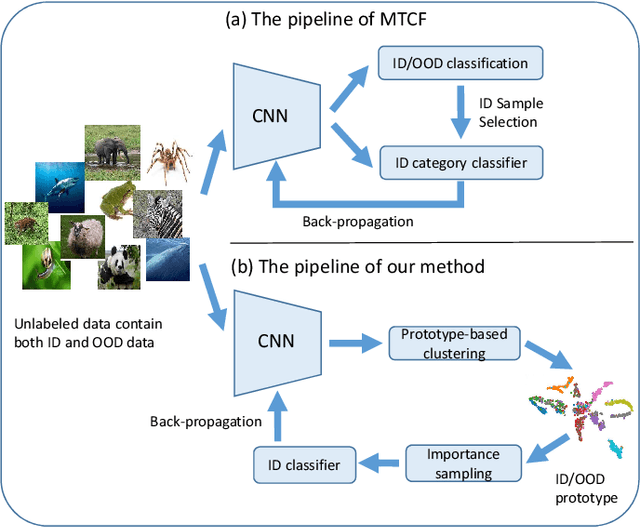
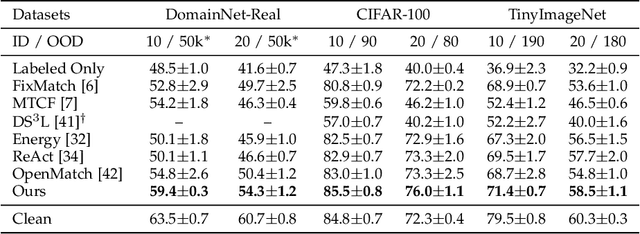
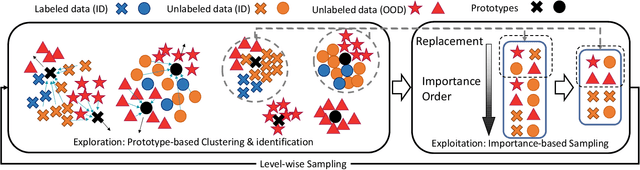

In this paper, we address a complex but practical scenario in semi-supervised learning (SSL) named open-set SSL, where unlabeled data contain both in-distribution (ID) and out-of-distribution (OOD) samples. Unlike previous methods that only consider ID samples to be useful and aim to filter out OOD ones completely during training, we argue that the exploration and exploitation of both ID and OOD samples can benefit SSL. To support our claim, i) we propose a prototype-based clustering and identification algorithm that explores the inherent similarity and difference among samples at feature level and effectively cluster them around several predefined ID and OOD prototypes, thereby enhancing feature learning and facilitating ID/OOD identification; ii) we propose an importance-based sampling method that exploits the difference in importance of each ID and OOD sample to SSL, thereby reducing the sampling bias and improving the training. Our proposed method achieves state-of-the-art in several challenging benchmarks, and improves upon existing SSL methods even when ID samples are totally absent in unlabeled data.
CausalVLR: A Toolbox and Benchmark for Visual-Linguistic Causal Reasoning
Jun 30, 2023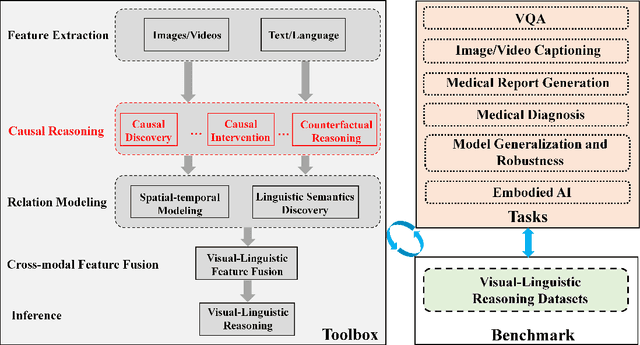
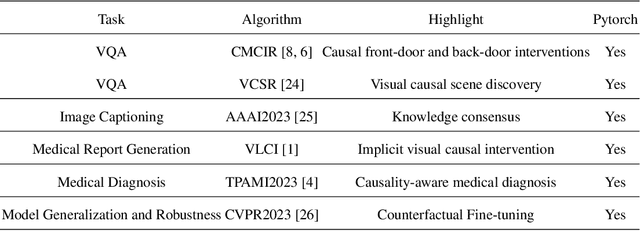
We present CausalVLR (Causal Visual-Linguistic Reasoning), an open-source toolbox containing a rich set of state-of-the-art causal relation discovery and causal inference methods for various visual-linguistic reasoning tasks, such as VQA, image/video captioning, medical report generation, model generalization and robustness, etc. These methods have been included in the toolbox with PyTorch implementations under NVIDIA computing system. It not only includes training and inference codes, but also provides model weights. We believe this toolbox is by far the most complete visual-linguitic causal reasoning toolbox. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to re-implement existing methods and develop their own new causal reasoning methods. Code and models are available at https://github.com/HCPLab-SYSU/Causal-VLReasoning. The project is under active development by HCP-Lab's contributors and we will keep this document updated.