 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecPipe: Co-designing Models and Hardware to Jointly Optimize Recommendation Quality and Performance
May 22, 2021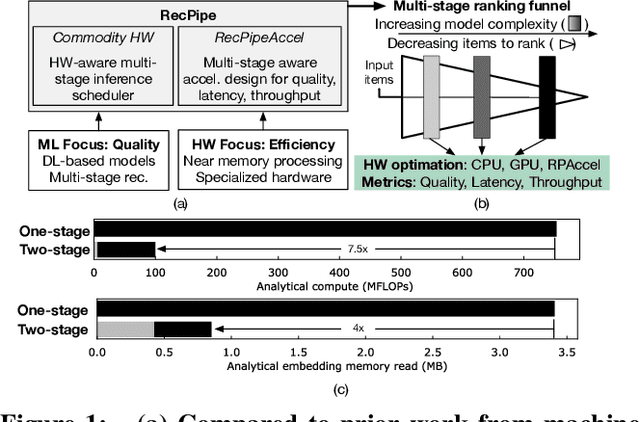

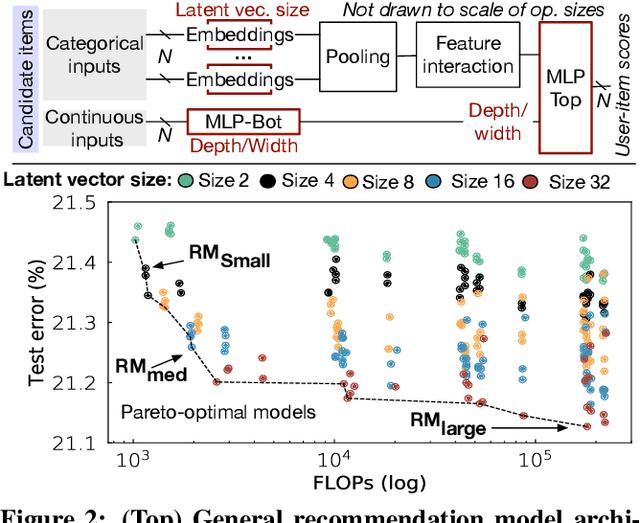
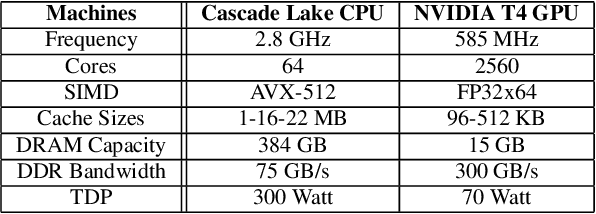
Deep learning recommendation systems must provide high quality, personalized content under strict tail-latency targets and high system loads. This paper presents RecPipe, a system to jointly optimize recommendation quality and inference performance. Central to RecPipe is decomposing recommendation models into multi-stage pipelines to maintain quality while reducing compute complexity and exposing distinct parallelism opportunities. RecPipe implements an inference scheduler to map multi-stage recommendation engines onto commodity, heterogeneous platforms (e.g., CPUs, GPUs).While the hardware-aware scheduling improves ranking efficiency, the commodity platforms suffer from many limitations requiring specialized hardware. Thus, we design RecPipeAccel (RPAccel), a custom accelerator that jointly optimizes quality, tail-latency, and system throughput. RPAc-cel is designed specifically to exploit the distinct design space opened via RecPipe. In particular, RPAccel processes queries in sub-batches to pipeline recommendation stages, implements dual static and dynamic embedding caches, a set of top-k filtering units, and a reconfigurable systolic array. Com-pared to prior-art and at iso-quality, we demonstrate that RPAccel improves latency and throughput by 3x and 6x.
Quantifying and Maximizing the Benefits of Back-End Noise Adaption on Attention-Based Speech Recognition Models
May 03, 2021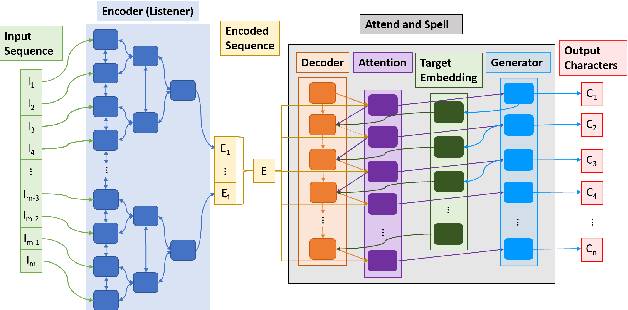

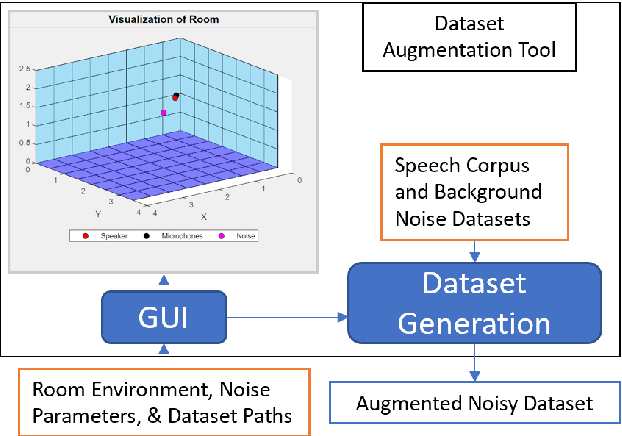
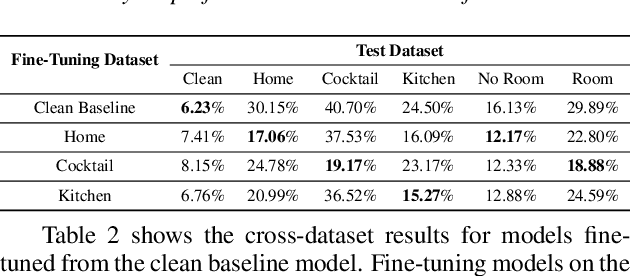
This work analyzes how attention-based Bidirectional Long Short-Term Memory (BLSTM) models adapt to noise-augmented speech. We identify crucial components for noise adaptation in BLSTM models by freezing model components during fine-tuning. We first freeze larger model subnetworks and then pursue a fine-grained freezing approach in the encoder after identifying its importance for noise adaptation. The first encoder layer is shown to be crucial for noise adaptation, and the weights are shown to be more important than the other layers. Appreciable accuracy benefits are identified when fine-tuning on a target noisy environment from a model pretrained with noisy speech relative to fine-tuning from a model pretrained with only clean speech when tested on the target noisy environment. For this analysis, we produce our own dataset augmentation tool and it is open-sourced to encourage future efforts in exploring noise adaptation in ASR.
Machine Learning-Based Automated Design Space Exploration for Autonomous Aerial Robots
Feb 05, 2021
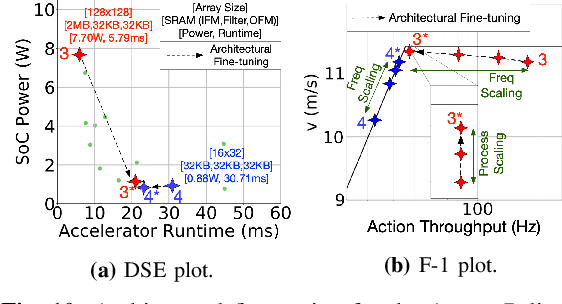
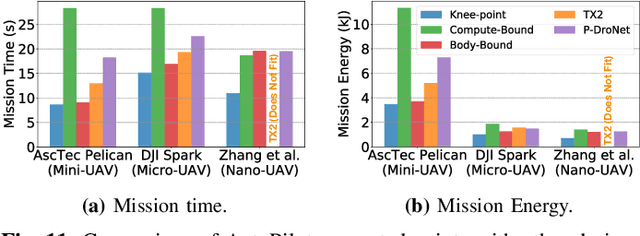

Building domain-specific architectures for autonomous aerial robots is challenging due to a lack of systematic methodology for designing onboard compute. We introduce a novel performance model called the F-1 roofline to help architects understand how to build a balanced computing system for autonomous aerial robots considering both its cyber (sensor rate, compute performance) and physical components (body-dynamics) that affect the performance of the machine. We use F-1 to characterize commonly used learning-based autonomy algorithms with onboard platforms to demonstrate the need for cyber-physical co-design. To navigate the cyber-physical design space automatically, we subsequently introduce AutoPilot. This push-button framework automates the co-design of cyber-physical components for aerial robots from a high-level specification guided by the F-1 model. AutoPilot uses Bayesian optimization to automatically co-design the autonomy algorithm and hardware accelerator while considering various cyber-physical parameters to generate an optimal design under different task level complexities for different robots and sensor framerates. As a result, designs generated by AutoPilot, on average, lower mission time up to 2x over baseline approaches, conserving battery energy.
RecSSD: Near Data Processing for Solid State Drive Based Recommendation Inference
Jan 29, 2021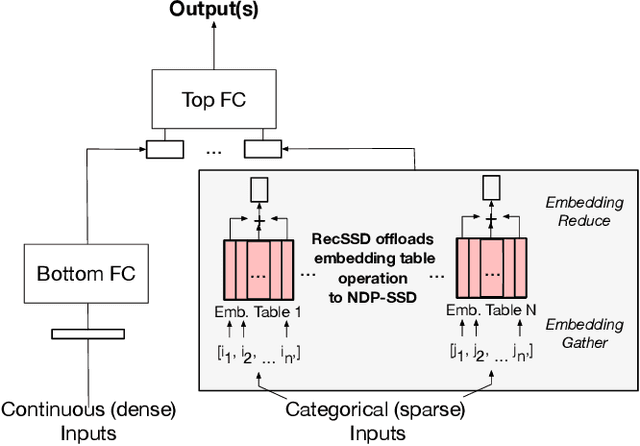
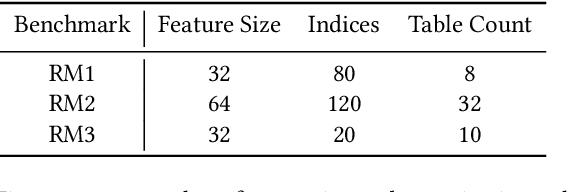
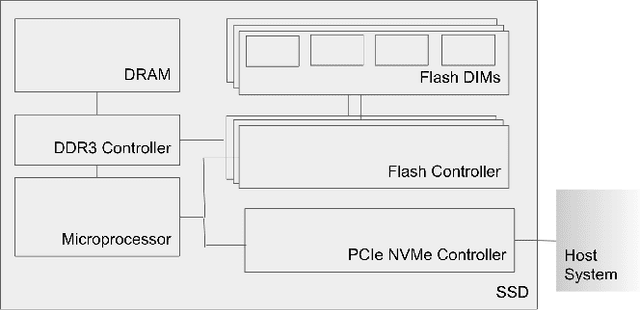
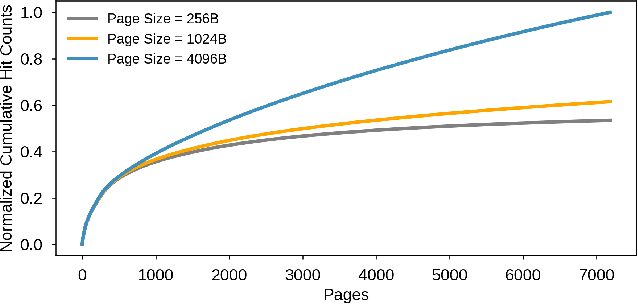
Neural personalized recommendation models are used across a wide variety of datacenter applications including search, social media, and entertainment. State-of-the-art models comprise large embedding tables that have billions of parameters requiring large memory capacities. Unfortunately, large and fast DRAM-based memories levy high infrastructure costs. Conventional SSD-based storage solutions offer an order of magnitude larger capacity, but have worse read latency and bandwidth, degrading inference performance. RecSSD is a near data processing based SSD memory system customized for neural recommendation inference that reduces end-to-end model inference latency by 2X compared to using COTS SSDs across eight industry-representative models.
EdgeBERT: Optimizing On-Chip Inference for Multi-Task NLP
Dec 01, 2020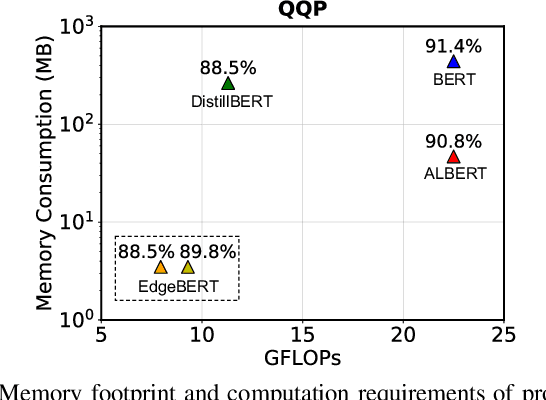
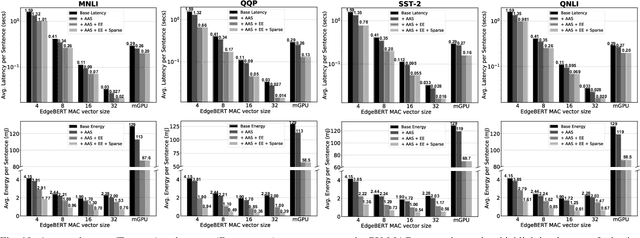
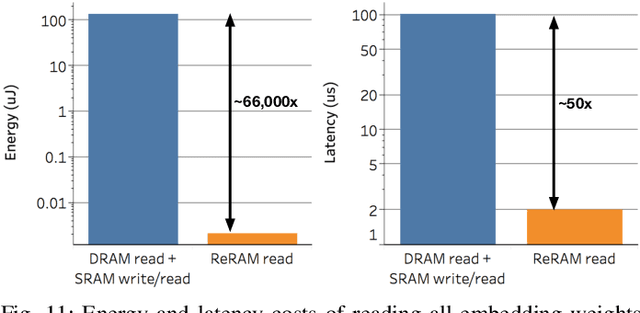
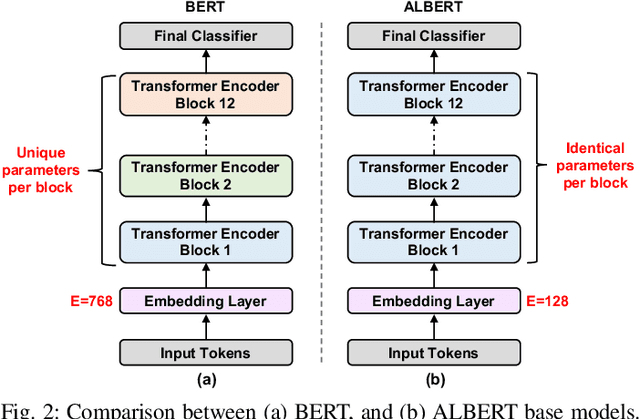
Transformer-based language models such as BERT provide significant accuracy improvement to a multitude of natural language processing (NLP) tasks. However, their hefty computational and memory demands make them challenging to deploy to resource-constrained edge platforms with strict latency requirements. We present EdgeBERT an in-depth and principled algorithm and hardware design methodology to achieve minimal latency and energy consumption on multi-task NLP inference. Compared to the ALBERT baseline, we achieve up to 2.4x and 13.4x inference latency and memory savings, respectively, with less than 1%-pt drop in accuracy on several GLUE benchmarks by employing a calibrated combination of 1) entropy-based early stopping, 2) adaptive attention span, 3) movement and magnitude pruning, and 4) floating-point quantization. Furthermore, in order to maximize the benefits of these algorithms in always-on and intermediate edge computing settings, we specialize a scalable hardware architecture wherein floating-point bit encodings of the shareable multi-task embedding parameters are stored in high-density non-volatile memory. Altogether, EdgeBERT enables fully on-chip inference acceleration of NLP workloads with 5.2x, and 157x lower energy than that of an un-optimized accelerator and CUDA adaptations on an Nvidia Jetson Tegra X2 mobile GPU, respectively.
SMAUG: End-to-End Full-Stack Simulation Infrastructure for Deep Learning Workloads
Dec 11, 2019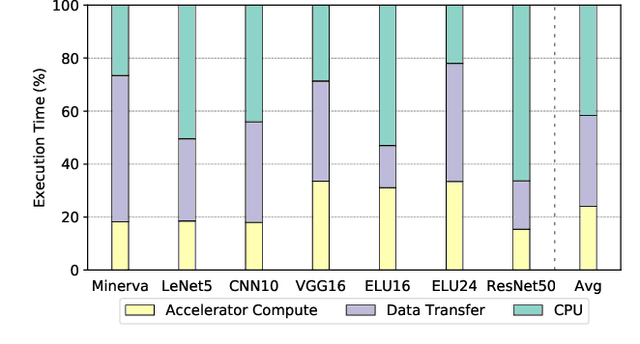
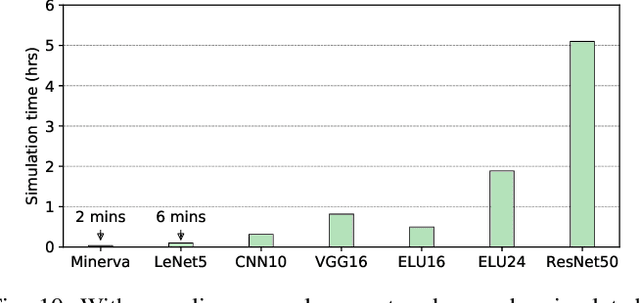
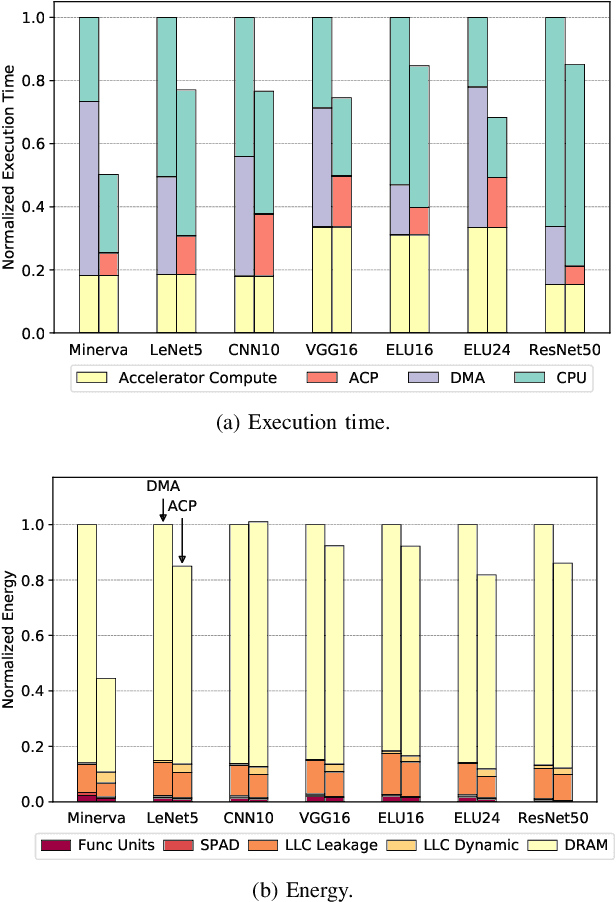
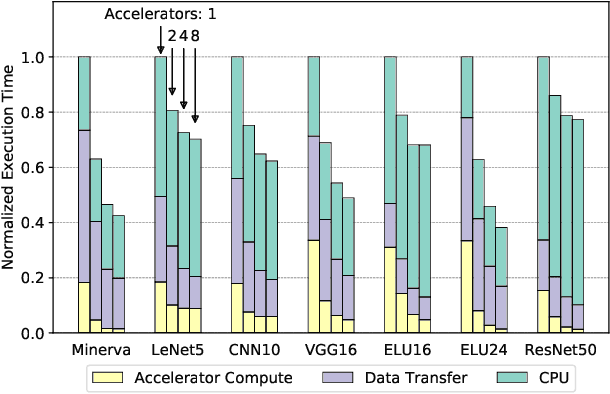
In recent years, there has been tremendous advances in hardware acceleration of deep neural networks. However, most of the research has focused on optimizing accelerator microarchitecture for higher performance and energy efficiency on a per-layer basis. We find that for overall single-batch inference latency, the accelerator may only make up 25-40%, with the rest spent on data movement and in the deep learning software framework. Thus far, it has been very difficult to study end-to-end DNN performance during early stage design (before RTL is available) because there are no existing DNN frameworks that support end-to-end simulation with easy custom hardware accelerator integration. To address this gap in research infrastructure, we present SMAUG, the first DNN framework that is purpose-built for simulation of end-to-end deep learning applications. SMAUG offers researchers a wide range of capabilities for evaluating DNN workloads, from diverse network topologies to easy accelerator modeling and SoC integration. To demonstrate the power and value of SMAUG, we present case studies that show how we can optimize overall performance and energy efficiency for up to 1.8-5x speedup over a baseline system, without changing any part of the accelerator microarchitecture, as well as show how SMAUG can tune an SoC for a camera-powered deep learning pipeline.
A binary-activation, multi-level weight RNN and training algorithm for processing-in-memory inference with eNVM
Dec 03, 2019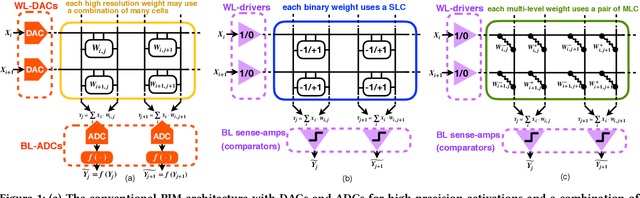
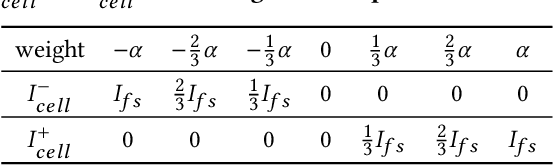
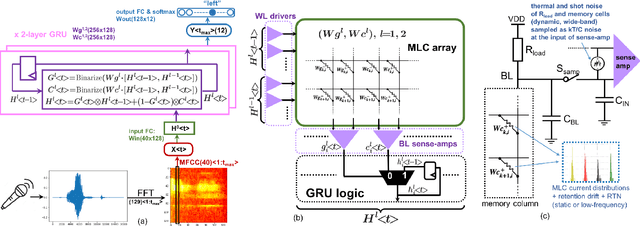

We present a new algorithm for training neural networks with binary activations and multi-level weights, which enables efficient processing-in-memory circuits with eNVM. Binary activations obviate costly DACs and ADCs. Multi-level weights leverage multi-level eNVM cells. Compared with previous quantization algorithms, our method not only works for feed-forward networks including fully-connected and convolutional, but also achieves higher accuracy and noise resilience for recurrent networks. In particular, we present a RNN trigger-word detection PIM accelerator, whose modeling results demonstrate high performance using our new training algorithm.
MLPerf Training Benchmark
Oct 30, 2019
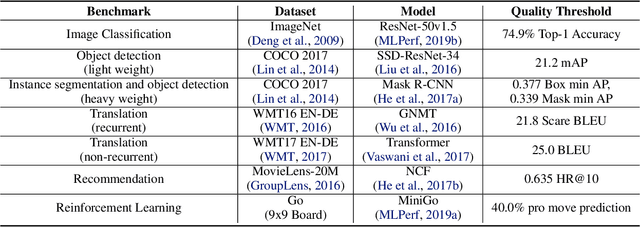
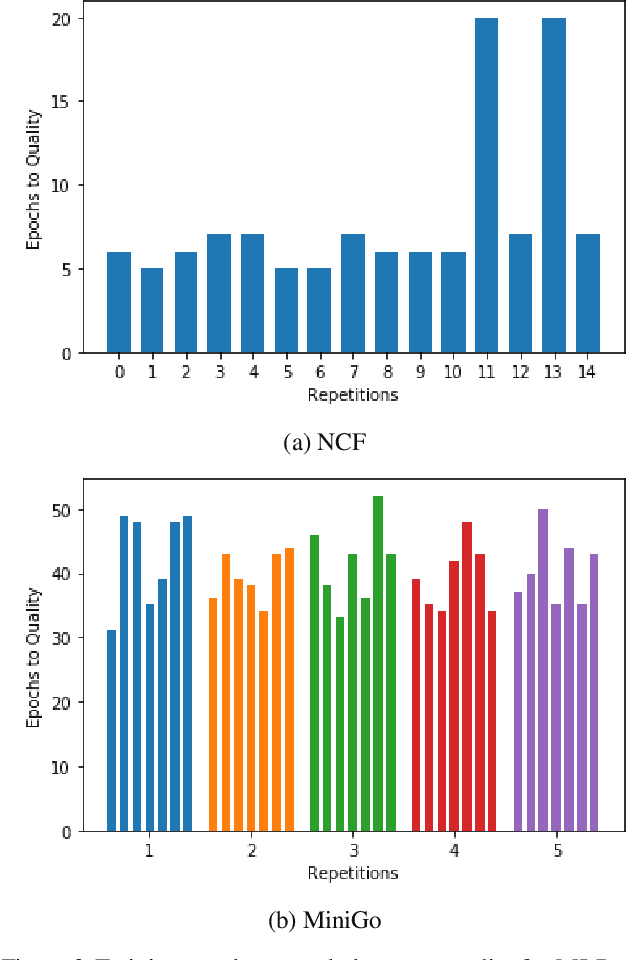
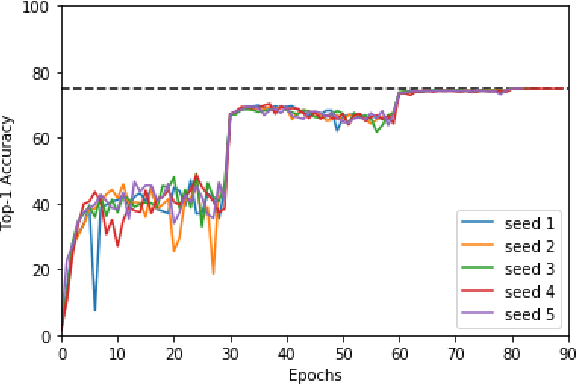
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
AdaptivFloat: A Floating-point based Data Type for Resilient Deep Learning Inference
Oct 15, 2019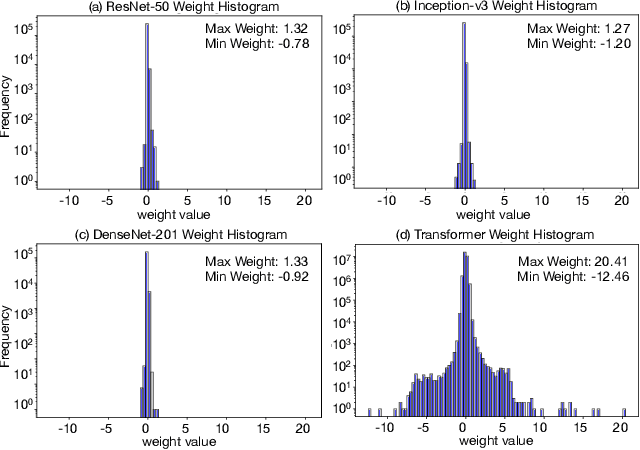

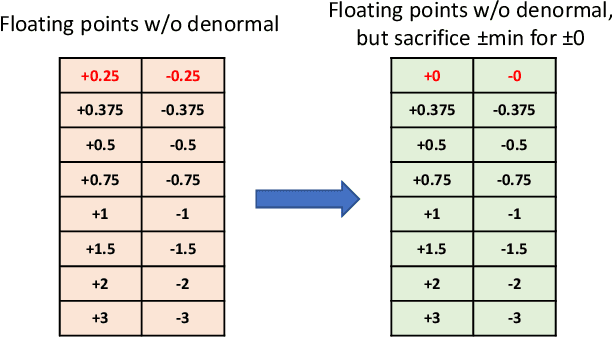
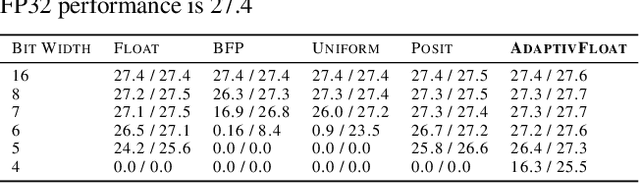
Conventional hardware-friendly quantization methods, such as fixed-point or integer, tend to perform poorly at very low word sizes as their shrinking dynamic ranges cannot adequately capture the wide data distributions commonly seen in sequence transduction models. We present AdaptivFloat, a floating-point inspired number representation format for deep learning that dynamically maximizes and optimally clips its available dynamic range, at a layer granularity, in order to create faithful encoding of neural network parameters. AdaptivFloat consistently produces higher inference accuracies compared to block floating-point, uniform, IEEE-like float or posit encodings at very low precision ($\leq$ 8-bit) across a diverse set of state-of-the-art neural network topologies. And notably, AdaptivFloat is seen surpassing baseline FP32 performance by up to +0.3 in BLEU score and -0.75 in word error rate at weight bit widths that are $\leq$ 8-bit. Experimental results on a deep neural network (DNN) hardware accelerator, exploiting AdaptivFloat logic in its computational datapath, demonstrate per-operation energy and area that is 0.9$\times$ and 1.14$\times$, respectively, that of equivalent bit width integer-based accelerator variants.
Benchmarking TPU, GPU, and CPU Platforms for Deep Learning
Aug 06, 2019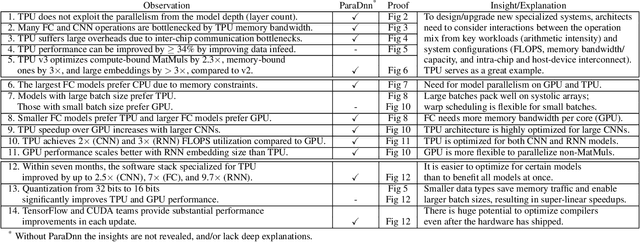
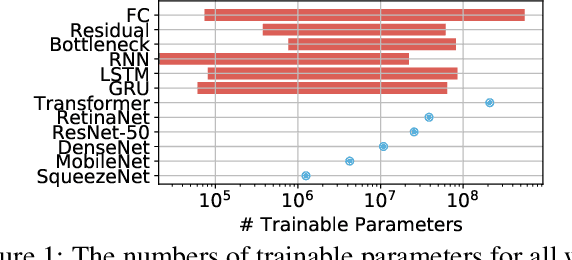
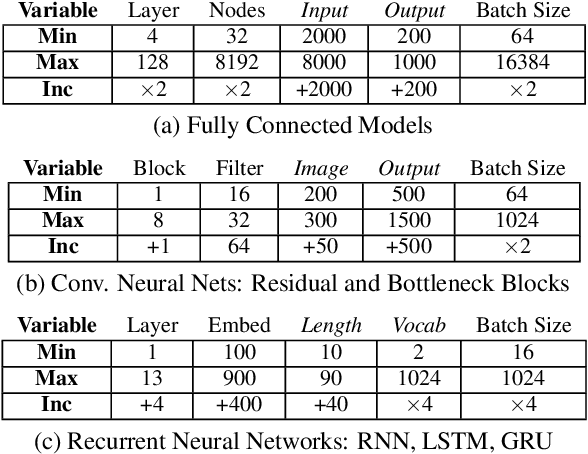

Training deep learning models is compute-intensive and there is an industry-wide trend towards hardware specialization to improve performance. To systematically benchmark deep learning platforms, we introduce ParaDnn, a parameterized benchmark suite for deep learning that generates end-to-end models for fully connected (FC), convolutional (CNN), and recurrent (RNN) neural networks. Along with six real-world models, we benchmark Google's Cloud TPU v2/v3, NVIDIA's V100 GPU, and an Intel Skylake CPU platform. We take a deep dive into TPU architecture, reveal its bottlenecks, and highlight valuable lessons learned for future specialized system design. We also provide a thorough comparison of the platforms and find that each has unique strengths for some types of models. Finally, we quantify the rapid performance improvements that specialized software stacks provide for the TPU and GPU platforms.