 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXTREME-R: Towards More Challenging and Nuanced Multilingual Evaluation
Apr 15, 2021
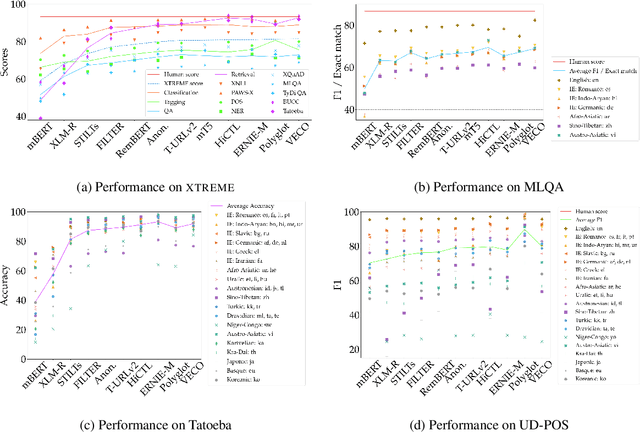
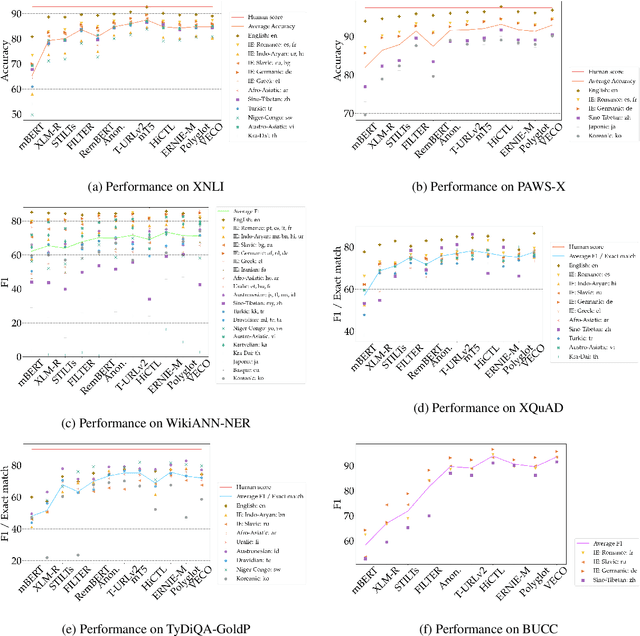
Machine learning has brought striking advances in multilingual natural language processing capabilities over the past year. For example, the latest techniques have improved the state-of-the-art performance on the XTREME multilingual benchmark by more than 13 points. While a sizeable gap to human-level performance remains, improvements have been easier to achieve in some tasks than in others. This paper analyzes the current state of cross-lingual transfer learning and summarizes some lessons learned. In order to catalyze meaningful progress, we extend XTREME to XTREME-R, which consists of an improved set of ten natural language understanding tasks, including challenging language-agnostic retrieval tasks, and covers 50 typologically diverse languages. In addition, we provide a massively multilingual diagnostic suite and fine-grained multi-dataset evaluation capabilities through an interactive public leaderboard to gain a better understanding of such models.
Multilingual Multimodal Pre-training for Zero-Shot Cross-Lingual Transfer of Vision-Language Models
Apr 15, 2021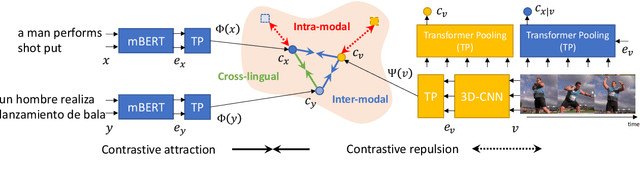

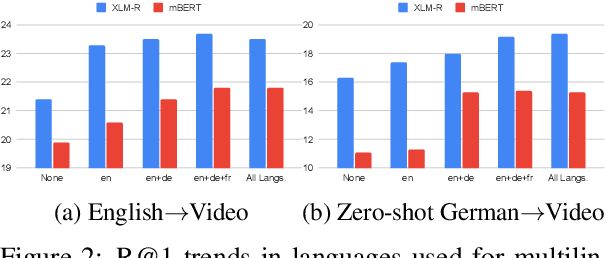
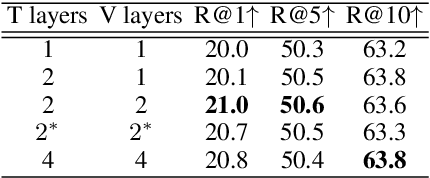
This paper studies zero-shot cross-lingual transfer of vision-language models. Specifically, we focus on multilingual text-to-video search and propose a Transformer-based model that learns contextualized multilingual multimodal embeddings. Under a zero-shot setting, we empirically demonstrate that performance degrades significantly when we query the multilingual text-video model with non-English sentences. To address this problem, we introduce a multilingual multimodal pre-training strategy, and collect a new multilingual instructional video dataset (MultiHowTo100M) for pre-training. Experiments on VTT show that our method significantly improves video search in non-English languages without additional annotations. Furthermore, when multilingual annotations are available, our method outperforms recent baselines by a large margin in multilingual text-to-video search on VTT and VATEX; as well as in multilingual text-to-image search on Multi30K. Our model and Multi-HowTo100M is available at http://github.com/berniebear/Multi-HT100M.
EXPLAINABOARD: An Explainable Leaderboard for NLP
Apr 13, 2021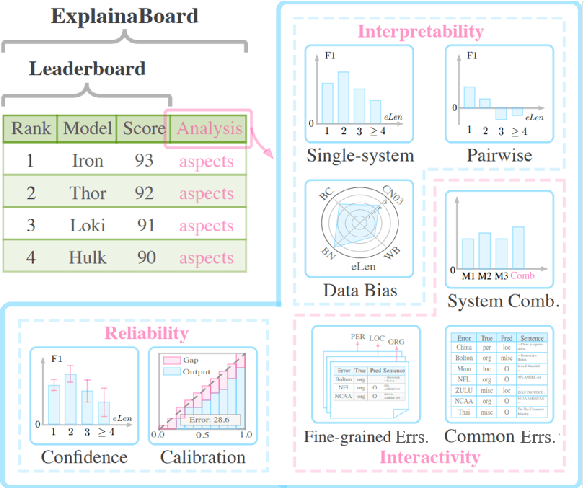
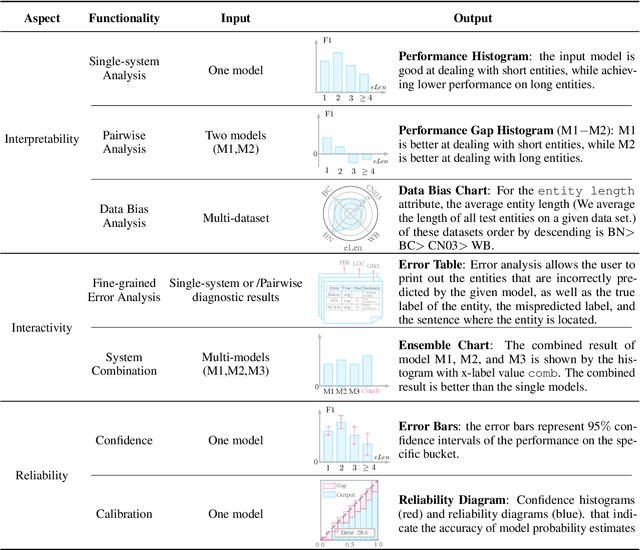
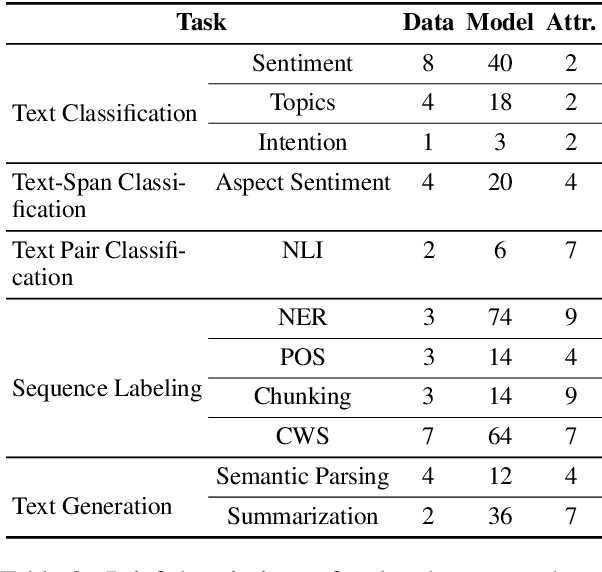
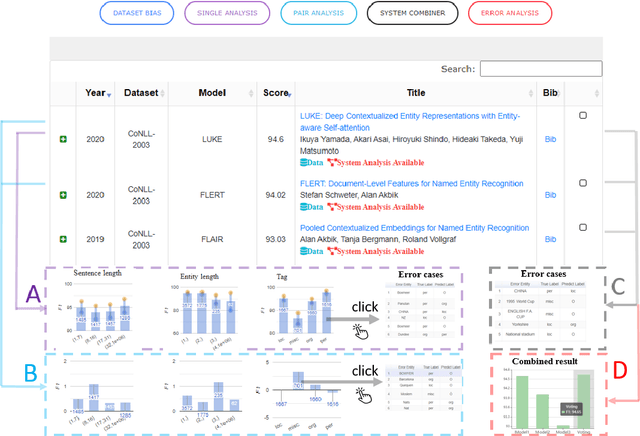
With the rapid development of NLP research, leaderboards have emerged as one tool to track the performance of various systems on various NLP tasks. They are effective in this goal to some extent, but generally present a rather simplistic one-dimensional view of the submitted systems, communicated only through holistic accuracy numbers. In this paper, we present a new conceptualization and implementation of NLP evaluation: the ExplainaBoard, which in addition to inheriting the functionality of the standard leaderboard, also allows researchers to (i) diagnose strengths and weaknesses of a single system (e.g. what is the best-performing system bad at?) (ii) interpret relationships between multiple systems. (e.g. where does system A outperform system B? What if we combine systems A, B, C?) and (iii) examine prediction results closely (e.g. what are common errors made by multiple systems or and in what contexts do particular errors occur?). ExplainaBoard has been deployed at \url{http://explainaboard.nlpedia.ai/}, and we have additionally released our interpretable evaluation code at \url{https://github.com/neulab/ExplainaBoard} and output files from more than 300 systems, 40 datasets, and 9 tasks to motivate the "output-driven" research in the future.
Multi-view Subword Regularization
Apr 06, 2021
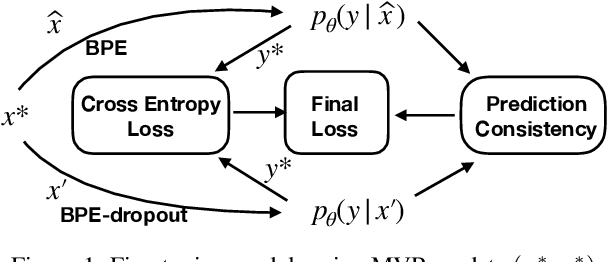
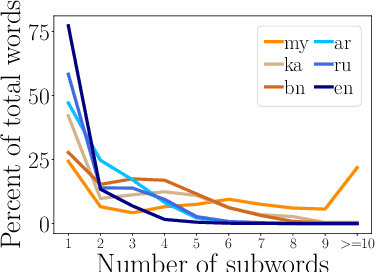
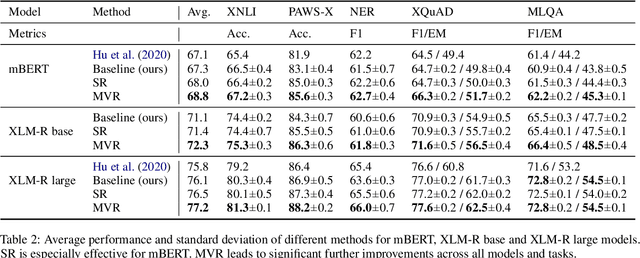
Multilingual pretrained representations generally rely on subword segmentation algorithms to create a shared multilingual vocabulary. However, standard heuristic algorithms often lead to sub-optimal segmentation, especially for languages with limited amounts of data. In this paper, we take two major steps towards alleviating this problem. First, we demonstrate empirically that applying existing subword regularization methods(Kudo, 2018; Provilkov et al., 2020) during fine-tuning of pre-trained multilingual representations improves the effectiveness of cross-lingual transfer. Second, to take full advantage of different possible input segmentations, we propose Multi-view Subword Regularization (MVR), a method that enforces the consistency between predictions of using inputs tokenized by the standard and probabilistic segmentations. Results on the XTREME multilingual benchmark(Hu et al., 2020) show that MVR brings consistent improvements of up to 2.5 points over using standard segmentation algorithms.
Phoneme Recognition through Fine Tuning of Phonetic Representations: a Case Study on Luhya Language Varieties
Apr 04, 2021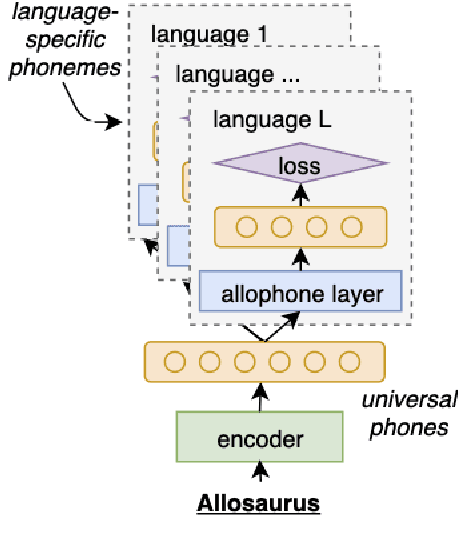
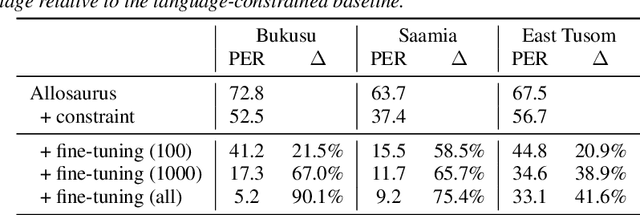
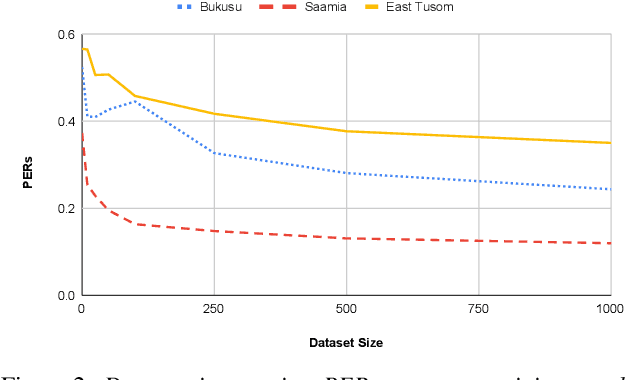
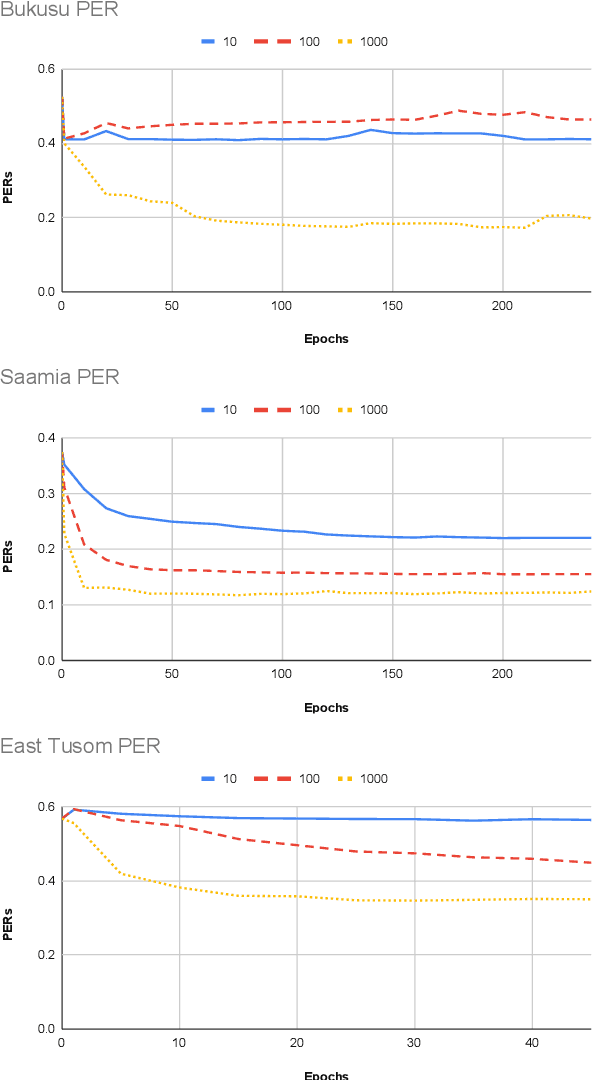
Models pre-trained on multiple languages have shown significant promise for improving speech recognition, particularly for low-resource languages. In this work, we focus on phoneme recognition using Allosaurus, a method for multilingual recognition based on phonetic annotation, which incorporates phonological knowledge through a language-dependent allophone layer that associates a universal narrow phone-set with the phonemes that appear in each language. To evaluate in a challenging real-world scenario, we curate phone recognition datasets for Bukusu and Saamia, two varieties of the Luhya language cluster of western Kenya and eastern Uganda. To our knowledge, these datasets are the first of their kind. We carry out similar experiments on the dataset of an endangered Tangkhulic language, East Tusom, a Tibeto-Burman language variety spoken mostly in India. We explore both zero-shot and few-shot recognition by fine-tuning using datasets of varying sizes (10 to 1000 utterances). We find that fine-tuning of Allosaurus, even with just 100 utterances, leads to significant improvements in phone error rates.
Modeling the Second Player in Distributionally Robust Optimization
Mar 31, 2021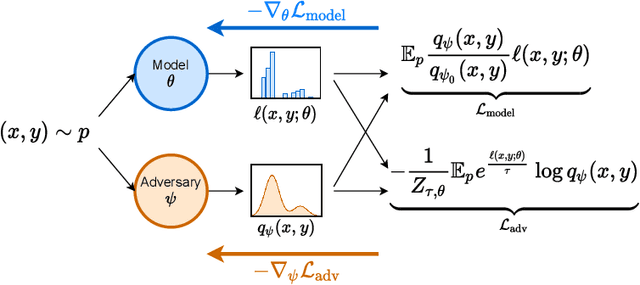

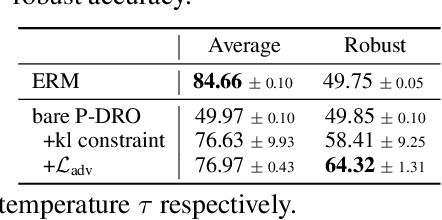
Distributionally robust optimization (DRO) provides a framework for training machine learning models that are able to perform well on a collection of related data distributions (the "uncertainty set"). This is done by solving a min-max game: the model is trained to minimize its maximum expected loss among all distributions in the uncertainty set. While careful design of the uncertainty set is critical to the success of the DRO procedure, previous work has been limited to relatively simple alternatives that keep the min-max optimization problem exactly tractable, such as $f$-divergence balls. In this paper, we argue instead for the use of neural generative models to characterize the worst-case distribution, allowing for more flexible and problem-specific selection of the uncertainty set. However, while simple conceptually, this approach poses a number of implementation and optimization challenges. To circumvent these issues, we propose a relaxation of the KL-constrained inner maximization objective that makes the DRO problem more amenable to gradient-based optimization of large scale generative models, and develop model selection heuristics to guide hyper-parameter search. On both toy settings and realistic NLP tasks, we find that the proposed approach yields models that are more robust than comparable baselines.
Evaluating the Morphosyntactic Well-formedness of Generated Texts
Mar 30, 2021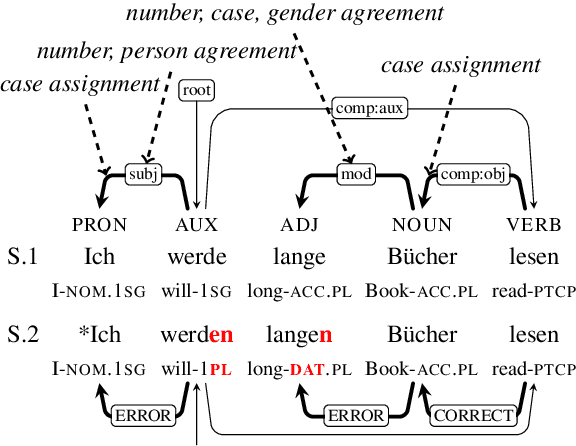

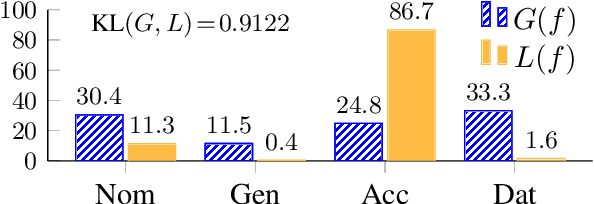

Text generation systems are ubiquitous in natural language processing applications. However, evaluation of these systems remains a challenge, especially in multilingual settings. In this paper, we propose L'AMBRE -- a metric to evaluate the morphosyntactic well-formedness of text using its dependency parse and morphosyntactic rules of the language. We present a way to automatically extract various rules governing morphosyntax directly from dependency treebanks. To tackle the noisy outputs from text generation systems, we propose a simple methodology to train robust parsers. We show the effectiveness of our metric on the task of machine translation through a diachronic study of systems translating into morphologically-rich languages.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021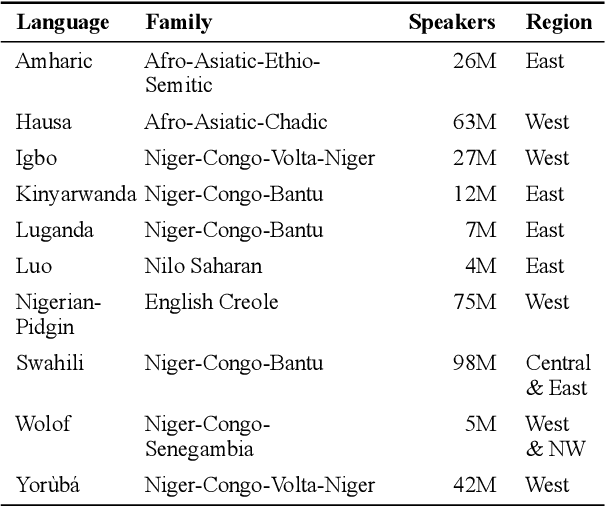

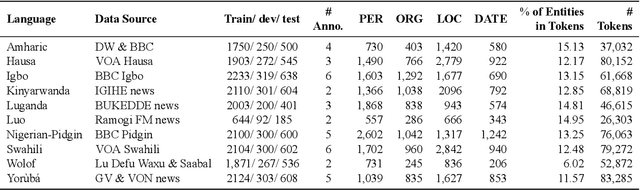
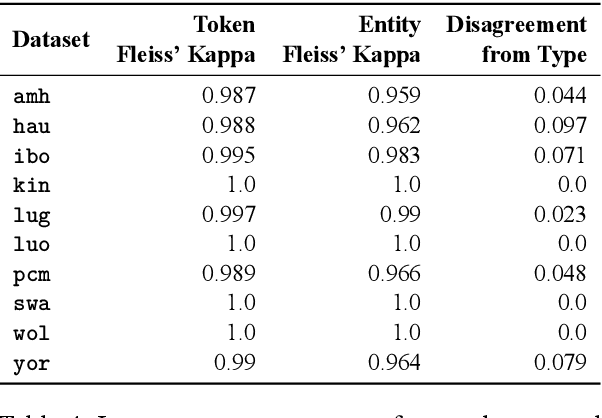
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Meta Back-translation
Feb 15, 2021
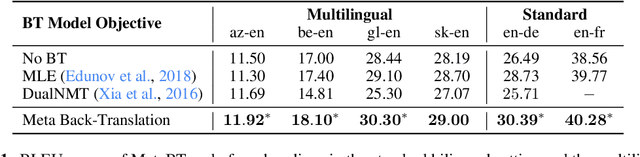
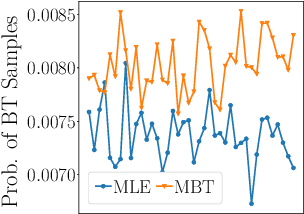

Back-translation is an effective strategy to improve the performance of Neural Machine Translation~(NMT) by generating pseudo-parallel data. However, several recent works have found that better translation quality of the pseudo-parallel data does not necessarily lead to better final translation models, while lower-quality but more diverse data often yields stronger results. In this paper, we propose a novel method to generate pseudo-parallel data from a pre-trained back-translation model. Our method is a meta-learning algorithm which adapts a pre-trained back-translation model so that the pseudo-parallel data it generates would train a forward-translation model to do well on a validation set. In our evaluations in both the standard datasets WMT En-De'14 and WMT En-Fr'14, as well as a multilingual translation setting, our method leads to significant improvements over strong baselines. Our code will be made available.
Towards More Fine-grained and Reliable NLP Performance Prediction
Feb 10, 2021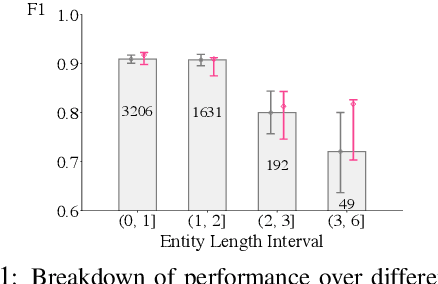
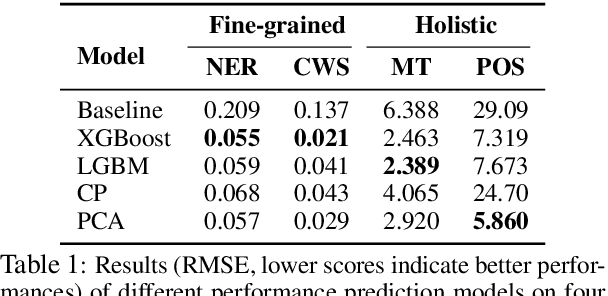
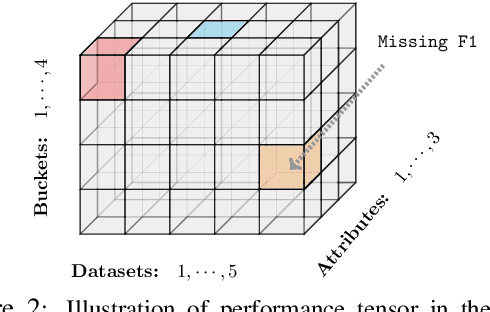
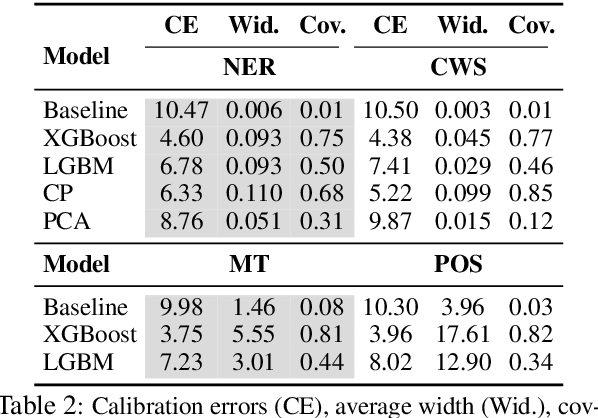
Performance prediction, the task of estimating a system's performance without performing experiments, allows us to reduce the experimental burden caused by the combinatorial explosion of different datasets, languages, tasks, and models. In this paper, we make two contributions to improving performance prediction for NLP tasks. First, we examine performance predictors not only for holistic measures of accuracy like F1 or BLEU but also fine-grained performance measures such as accuracy over individual classes of examples. Second, we propose methods to understand the reliability of a performance prediction model from two angles: confidence intervals and calibration. We perform an analysis of four types of NLP tasks, and both demonstrate the feasibility of fine-grained performance prediction and the necessity to perform reliability analysis for performance prediction methods in the future. We make our code publicly available: \url{https://github.com/neulab/Reliable-NLPPP}