 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Pretrained Models to Thousands More Languages via Lexicon-based Adaptation
Apr 06, 2022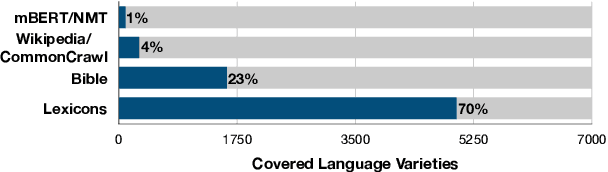

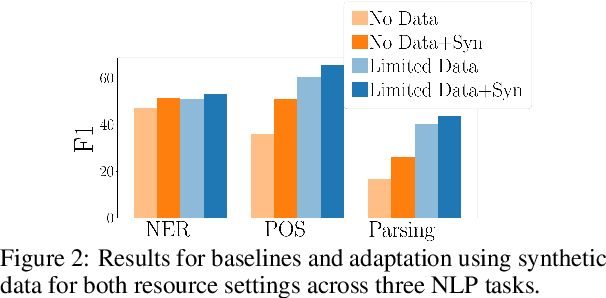
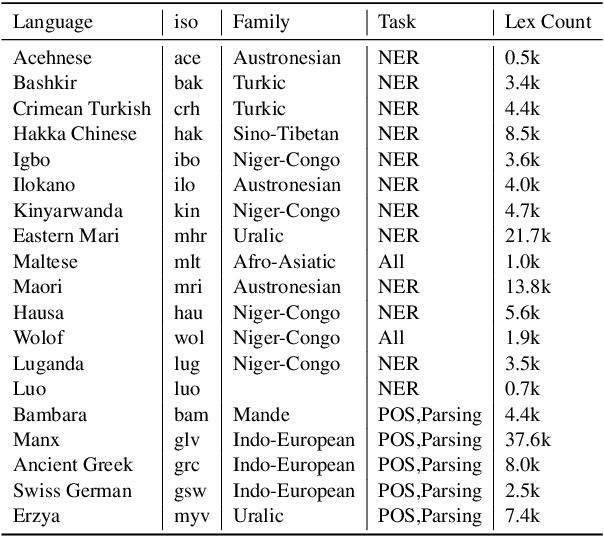
The performance of multilingual pretrained models is highly dependent on the availability of monolingual or parallel text present in a target language. Thus, the majority of the world's languages cannot benefit from recent progress in NLP as they have no or limited textual data. To expand possibilities of using NLP technology in these under-represented languages, we systematically study strategies that relax the reliance on conventional language resources through the use of bilingual lexicons, an alternative resource with much better language coverage. We analyze different strategies to synthesize textual or labeled data using lexicons, and how this data can be combined with monolingual or parallel text when available. For 19 under-represented languages across 3 tasks, our methods lead to consistent improvements of up to 5 and 15 points with and without extra monolingual text respectively. Overall, our study highlights how NLP methods can be adapted to thousands more languages that are under-served by current technology
BRIO: Bringing Order to Abstractive Summarization
Mar 31, 2022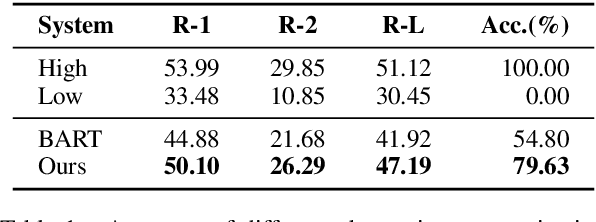
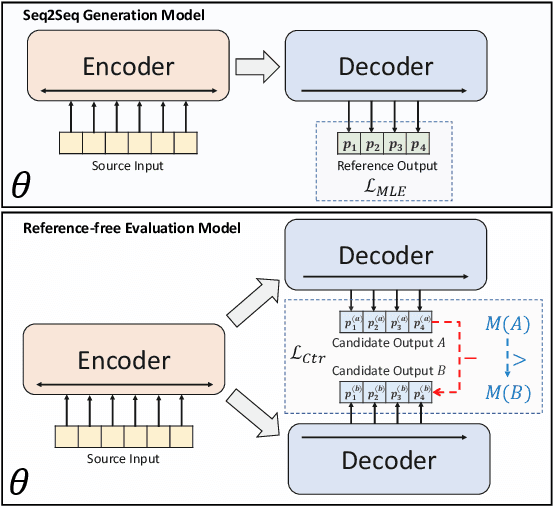
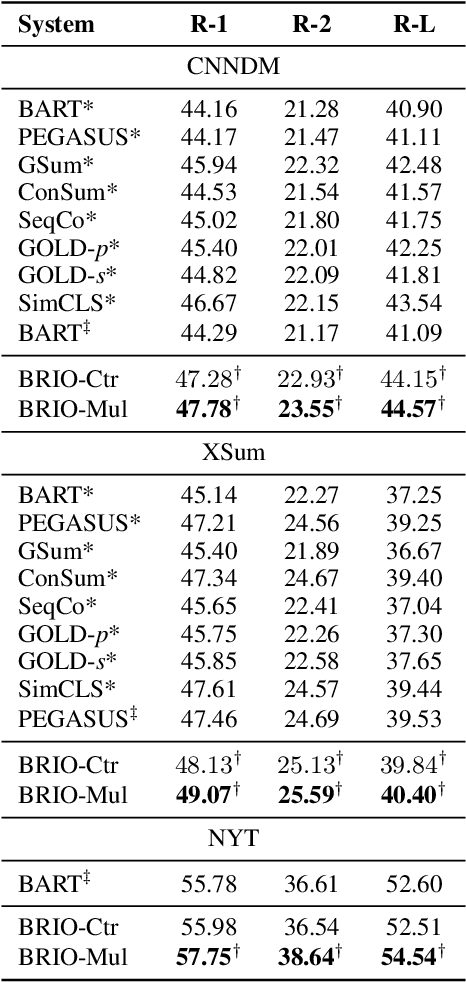
Abstractive summarization models are commonly trained using maximum likelihood estimation, which assumes a deterministic (one-point) target distribution in which an ideal model will assign all the probability mass to the reference summary. This assumption may lead to performance degradation during inference, where the model needs to compare several system-generated (candidate) summaries that have deviated from the reference summary. To address this problem, we propose a novel training paradigm which assumes a non-deterministic distribution so that different candidate summaries are assigned probability mass according to their quality. Our method achieves a new state-of-the-art result on the CNN/DailyMail (47.78 ROUGE-1) and XSum (49.07 ROUGE-1) datasets. Further analysis also shows that our model can estimate probabilities of candidate summaries that are more correlated with their level of quality.
AUTOLEX: An Automatic Framework for Linguistic Exploration
Mar 25, 2022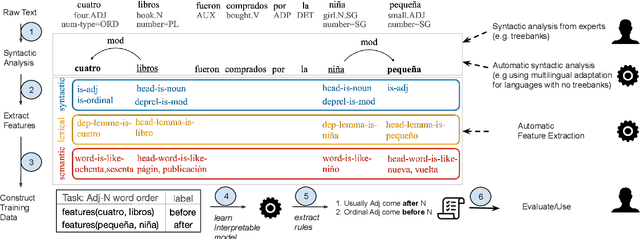
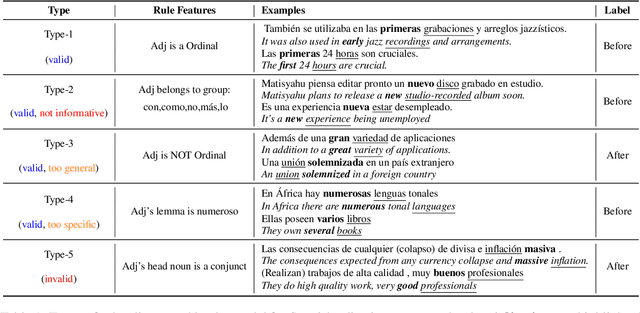
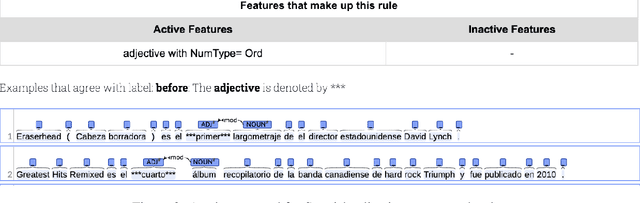
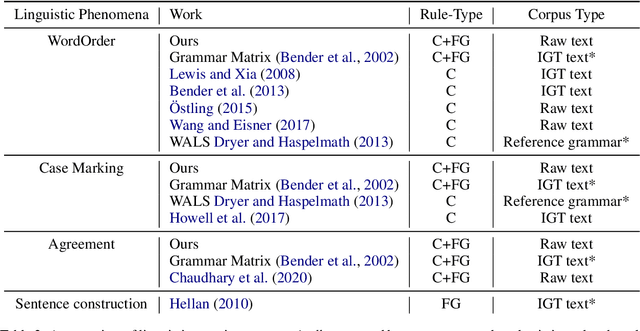
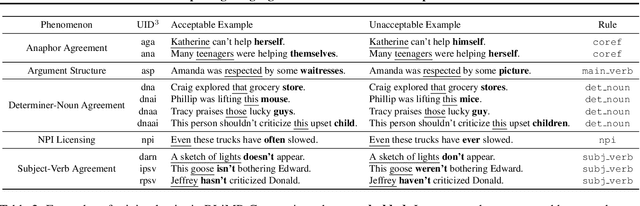
Each language has its own complex systems of word, phrase, and sentence construction, the guiding principles of which are often summarized in grammar descriptions for the consumption of linguists or language learners. However, manual creation of such descriptions is a fraught process, as creating descriptions which describe the language in "its own terms" without bias or error requires both a deep understanding of the language at hand and linguistics as a whole. We propose an automatic framework AutoLEX that aims to ease linguists' discovery and extraction of concise descriptions of linguistic phenomena. Specifically, we apply this framework to extract descriptions for three phenomena: morphological agreement, case marking, and word order, across several languages. We evaluate the descriptions with the help of language experts and propose a method for automated evaluation when human evaluation is infeasible.
Show Me More Details: Discovering Hierarchies of Procedures from Semi-structured Web Data
Mar 17, 2022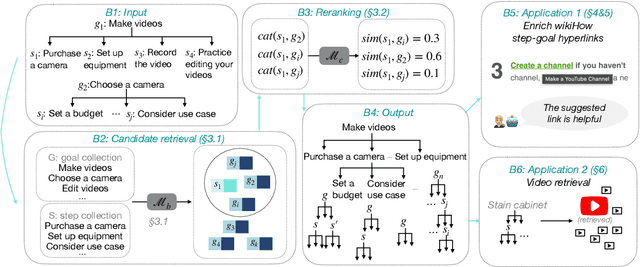
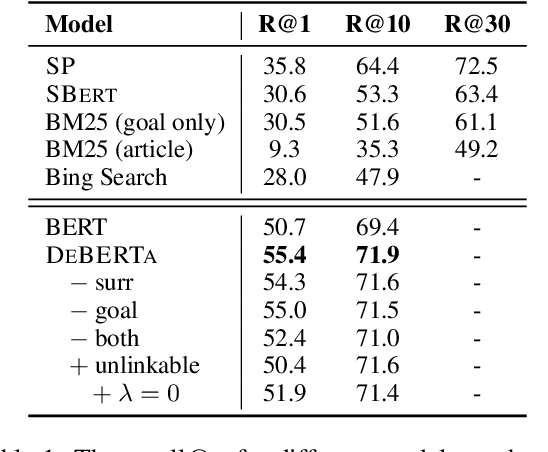

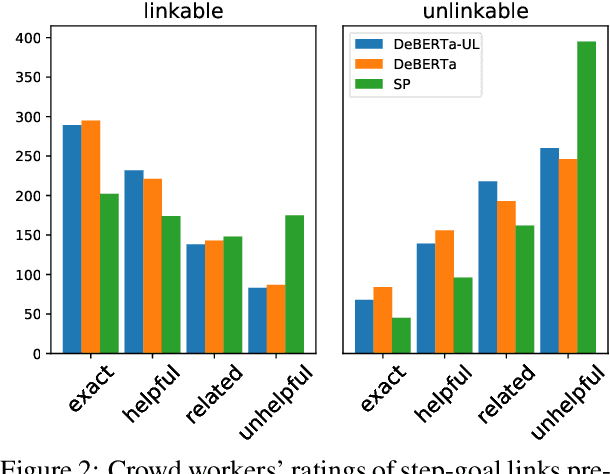
Procedures are inherently hierarchical. To "make videos", one may need to "purchase a camera", which in turn may require one to "set a budget". While such hierarchical knowledge is critical for reasoning about complex procedures, most existing work has treated procedures as shallow structures without modeling the parent-child relation. In this work, we attempt to construct an open-domain hierarchical knowledge-base (KB) of procedures based on wikiHow, a website containing more than 110k instructional articles, each documenting the steps to carry out a complex procedure. To this end, we develop a simple and efficient method that links steps (e.g., "purchase a camera") in an article to other articles with similar goals (e.g., "how to choose a camera"), recursively constructing the KB. Our method significantly outperforms several strong baselines according to automatic evaluation, human judgment, and application to downstream tasks such as instructional video retrieval. A demo with partial data can be found at https://wikihow-hierarchy.github.io. The code and the data are at https://github.com/shuyanzhou/wikihow_hierarchy.
MCoNaLa: A Benchmark for Code Generation from Multiple Natural Languages
Mar 16, 2022
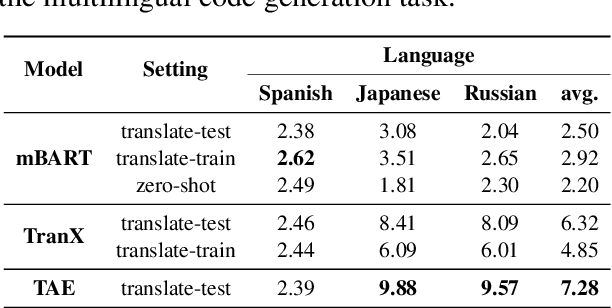

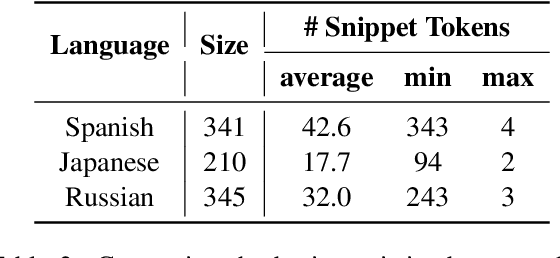
While there has been a recent burgeoning of applications at the intersection of natural and programming languages, such as code generation and code summarization, these applications are usually English-centric. This creates a barrier for program developers who are not proficient in English. To mitigate this gap in technology development across languages, we propose a multilingual dataset, MCoNaLa, to benchmark code generation from natural language commands extending beyond English. Modeled off of the methodology from the English Code/Natural Language Challenge (CoNaLa) dataset, we annotated a total of 896 NL-code pairs in three languages: Spanish, Japanese, and Russian. We present a quantitative evaluation of performance on the MCoNaLa dataset by testing with state-of-the-art code generation systems. While the difficulties vary across these three languages, all systems lag significantly behind their English counterparts, revealing the challenges in adapting code generation to new languages.
A Systematic Evaluation of Large Language Models of Code
Mar 01, 2022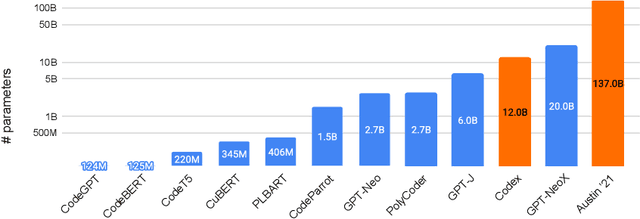
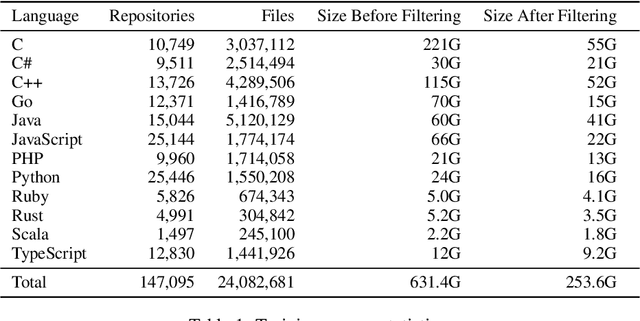

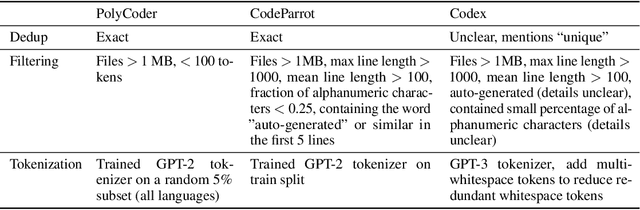
Large language models (LMs) of code have recently shown tremendous promise in completing code and synthesizing code from natural language descriptions. However, the current state-of-the-art code LMs (e.g., Codex (Chen et al., 2021)) are not publicly available, leaving many questions about their model and data design decisions. We aim to fill in some of these blanks through a systematic evaluation of the largest existing models: Codex, GPT-J, GPT-Neo, GPT-NeoX-20B, and CodeParrot, across various programming languages. Although Codex itself is not open-source, we find that existing open-source models do achieve close results in some programming languages, although targeted mainly for natural language modeling. We further identify an important missing piece in the form of a large open-source model trained exclusively on a multi-lingual corpus of code. We release a new model, PolyCoder, with 2.7B parameters based on the GPT-2 architecture, which was trained on 249GB of code across 12 programming languages on a single machine. In the C programming language, PolyCoder outperforms all models including Codex. Our trained models are open-source and publicly available at https://github.com/VHellendoorn/Code-LMs, which enables future research and application in this area.
DataLab: A Platform for Data Analysis and Intervention
Feb 25, 2022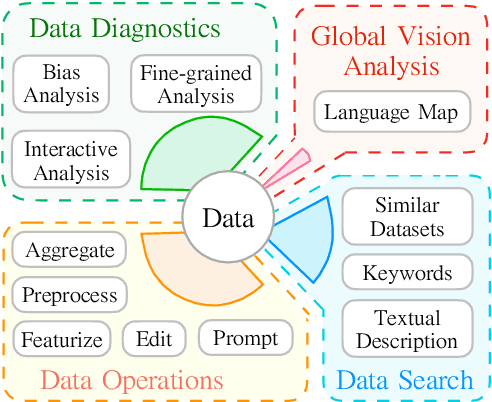
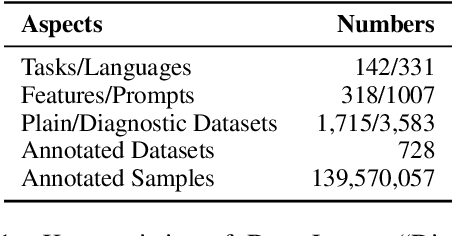
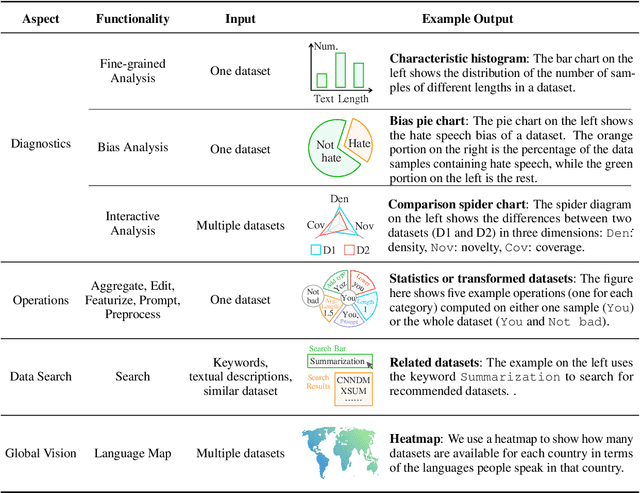
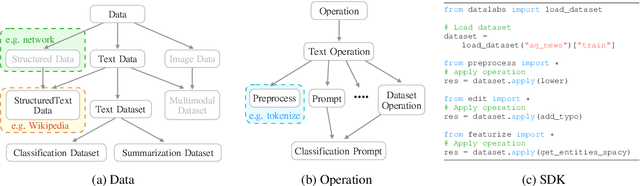
Despite data's crucial role in machine learning, most existing tools and research tend to focus on systems on top of existing data rather than how to interpret and manipulate data. In this paper, we propose DataLab, a unified data-oriented platform that not only allows users to interactively analyze the characteristics of data, but also provides a standardized interface for different data processing operations. Additionally, in view of the ongoing proliferation of datasets, \toolname has features for dataset recommendation and global vision analysis that help researchers form a better view of the data ecosystem. So far, DataLab covers 1,715 datasets and 3,583 of its transformed version (e.g., hyponyms replacement), where 728 datasets support various analyses (e.g., with respect to gender bias) with the help of 140M samples annotated by 318 feature functions. DataLab is under active development and will be supported going forward. We have released a web platform, web API, Python SDK, PyPI published package and online documentation, which hopefully, can meet the diverse needs of researchers.
Interpreting Language Models with Contrastive Explanations
Feb 21, 2022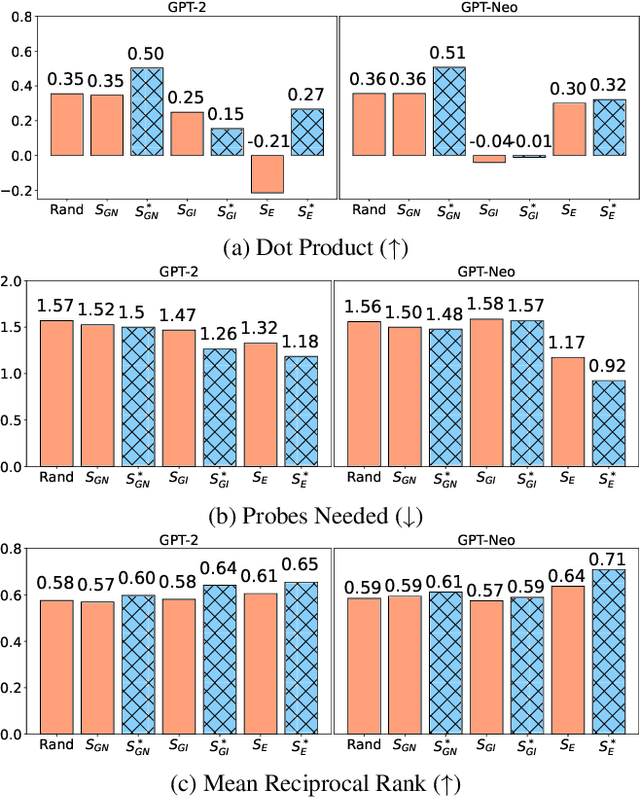
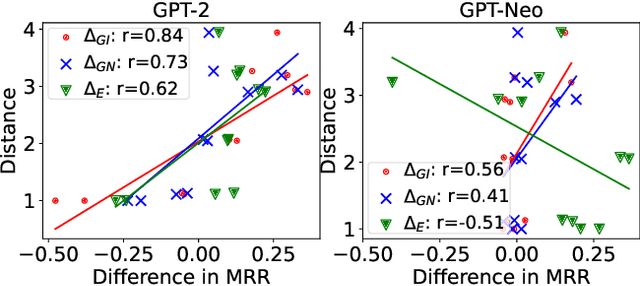

Model interpretability methods are often used to explain NLP model decisions on tasks such as text classification, where the output space is relatively small. However, when applied to language generation, where the output space often consists of tens of thousands of tokens, these methods are unable to provide informative explanations. Language models must consider various features to predict a token, such as its part of speech, number, tense, or semantics. Existing explanation methods conflate evidence for all these features into a single explanation, which is less interpretable for human understanding. To disentangle the different decisions in language modeling, we focus on explaining language models contrastively: we look for salient input tokens that explain why the model predicted one token instead of another. We demonstrate that contrastive explanations are quantifiably better than non-contrastive explanations in verifying major grammatical phenomena, and that they significantly improve contrastive model simulatability for human observers. We also identify groups of contrastive decisions where the model uses similar evidence, and we are able to characterize what input tokens models use during various language generation decisions.
Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
Jan 28, 2022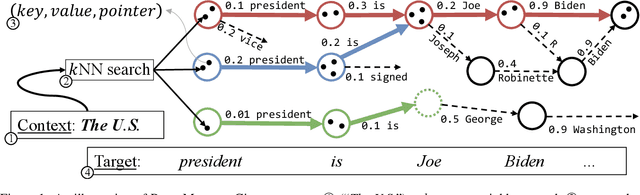
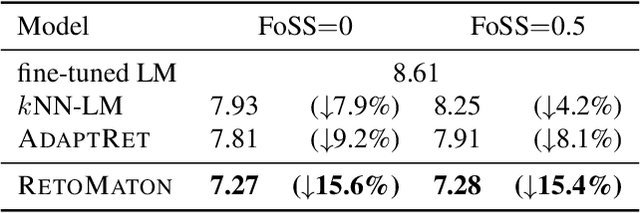
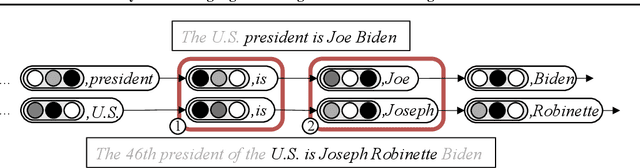

Retrieval-based language models (R-LM) model the probability of natural language text by combining a standard language model (LM) with examples retrieved from an external datastore at test time. While effective, a major bottleneck of using these models in practice is the computationally costly datastore search, which can be performed as frequently as every time step. In this paper, we present RetoMaton -- retrieval automaton -- which approximates the datastore search, based on (1) clustering of entries into "states", and (2) state transitions from previous entries. This effectively results in a weighted finite automaton built on top of the datastore, instead of representing the datastore as a flat list. The creation of the automaton is unsupervised, and a RetoMaton can be constructed from any text collection: either the original training corpus or from another domain. Traversing this automaton at inference time, in parallel to the LM inference, reduces its perplexity, or alternatively saves up to 83% of the nearest neighbor searches over kNN-LM (Khandelwal et al., 2020), without hurting perplexity.
Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations
Dec 17, 2021

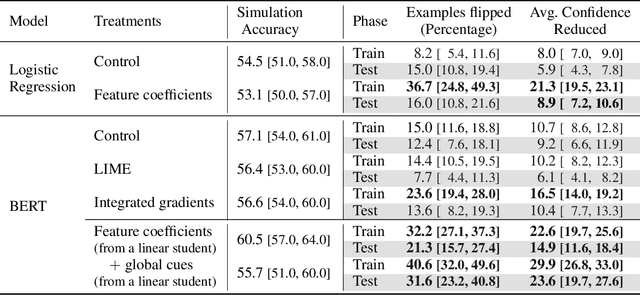
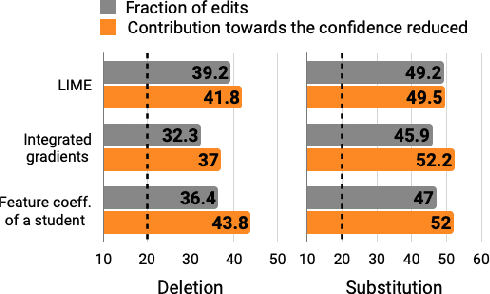
In attempts to "explain" predictions of machine learning models, researchers have proposed hundreds of techniques for attributing predictions to features that are deemed important. While these attributions are often claimed to hold the potential to improve human "understanding" of the models, surprisingly little work explicitly evaluates progress towards this aspiration. In this paper, we conduct a crowdsourcing study, where participants interact with deception detection models that have been trained to distinguish between genuine and fake hotel reviews. They are challenged both to simulate the model on fresh reviews, and to edit reviews with the goal of lowering the probability of the originally predicted class. Successful manipulations would lead to an adversarial example. During the training (but not the test) phase, input spans are highlighted to communicate salience. Through our evaluation, we observe that for a linear bag-of-words model, participants with access to the feature coefficients during training are able to cause a larger reduction in model confidence in the testing phase when compared to the no-explanation control. For the BERT-based classifier, popular local explanations do not improve their ability to reduce the model confidence over the no-explanation case. Remarkably, when the explanation for the BERT model is given by the (global) attributions of a linear model trained to imitate the BERT model, people can effectively manipulate the model.