 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Graph Condensation from the Causal Perspective
Jan 29, 2026The increasing scale of graph datasets has significantly improved the performance of graph representation learning methods, but it has also introduced substantial training challenges. Graph dataset condensation techniques have emerged to compress large datasets into smaller yet information-rich datasets, while maintaining similar test performance. However, these methods strictly require downstream applications to match the original dataset and task, which often fails in cross-task and cross-domain scenarios. To address these challenges, we propose a novel causal-invariance-based and transferable graph dataset condensation method, named \textbf{TGCC}, providing effective and transferable condensed datasets. Specifically, to preserve domain-invariant knowledge, we first extract domain causal-invariant features from the spatial domain of the graph using causal interventions. Then, to fully capture the structural and feature information of the original graph, we perform enhanced condensation operations. Finally, through spectral-domain enhanced contrastive learning, we inject the causal-invariant features into the condensed graph, ensuring that the compressed graph retains the causal information of the original graph. Experimental results on five public datasets and our novel \textbf{FinReport} dataset demonstrate that TGCC achieves up to a 13.41\% improvement in cross-task and cross-domain complex scenarios compared to existing methods, and achieves state-of-the-art performance on 5 out of 6 datasets in the single dataset and task scenario.
Melody Is All You Need For Music Generation
Sep 30, 2024


We present the Melody Guided Music Generation (MMGen) model, the first novel approach using melody to guide the music generation that, despite a pretty simple method and extremely limited resources, achieves excellent performance. Specifically, we first align the melody with audio waveforms and their associated descriptions using the multimodal alignment module. Subsequently, we condition the diffusion module on the learned melody representations. This allows MMGen to generate music that matches the style of the provided audio while also producing music that reflects the content of the given text description. To address the scarcity of high-quality data, we construct a multi-modal dataset, MusicSet, which includes melody, text, and audio, and will be made publicly available. We conduct extensive experiments which demonstrate the superiority of the proposed model both in terms of experimental metrics and actual performance quality.
Graph Dimension Attention Networks for Enterprise Credit Assessment
Jul 16, 2024



Enterprise credit assessment is critical for evaluating financial risk, and Graph Neural Networks (GNNs), with their advanced capability to model inter-entity relationships, are a natural tool to get a deeper understanding of these financial networks. However, existing GNN-based methodologies predominantly emphasize entity-level attention mechanisms for contagion risk aggregation, often overlooking the heterogeneous importance of different feature dimensions, thus falling short in adequately modeling credit risk levels. To address this issue, we propose a novel architecture named Graph Dimension Attention Network (GDAN), which incorporates a dimension-level attention mechanism to capture fine-grained risk-related characteristics. Furthermore, we explore the interpretability of the GNN-based method in financial scenarios and propose a simple but effective data-centric explainer for GDAN, called GDAN-DistShift. DistShift provides edge-level interpretability by quantifying distribution shifts during the message-passing process. Moreover, we collected a real-world, multi-source Enterprise Credit Assessment Dataset (ECAD) and have made it accessible to the research community since high-quality datasets are lacking in this field. Extensive experiments conducted on ECAD demonstrate the effectiveness of our methods. In addition, we ran GDAN on the well-known datasets SMEsD and DBLP, also with excellent results.
Towards Optimal Customized Architecture for Heterogeneous Federated Learning with Contrastive Cloud-Edge Model Decoupling
Mar 04, 2024



Federated learning, as a promising distributed learning paradigm, enables collaborative training of a global model across multiple network edge clients without the need for central data collecting. However, the heterogeneity of edge data distribution drags the model towards the local minima, which can be distant from the global optimum. Such heterogeneity often leads to slow convergence and substantial communication overhead. To address these issues, we propose a novel federated learning framework called FedCMD, a model decoupling tailored to the Cloud-edge supported federated learning that separates deep neural networks into a body for capturing shared representations in Cloud and a personalized head for migrating data heterogeneity. Our motivation is that, by the deep investigation of the performance of selecting different neural network layers as the personalized head, we found rigidly assigning the last layer as the personalized head in current studies is not always optimal. Instead, it is necessary to dynamically select the personalized layer that maximizes the training performance by taking the representation difference between neighbor layers into account. To find the optimal personalized layer, we utilize the low-dimensional representation of each layer to contrast feature distribution transfer and introduce a Wasserstein-based layer selection method, aimed at identifying the best-match layer for personalization. Additionally, a weighted global aggregation algorithm is proposed based on the selected personalized layer for the practical application of FedCMD. Extensive experiments on ten benchmarks demonstrate the efficiency and superior performance of our solution compared with nine state-of-the-art solutions. All code and results are available at https://github.com/elegy112138/FedCMD.
Bankruptcy Prediction via Mixing Intra-Risk and Spillover-Risk
Feb 12, 2022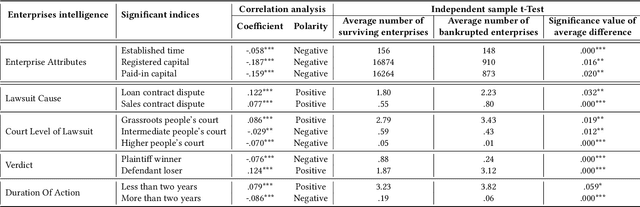
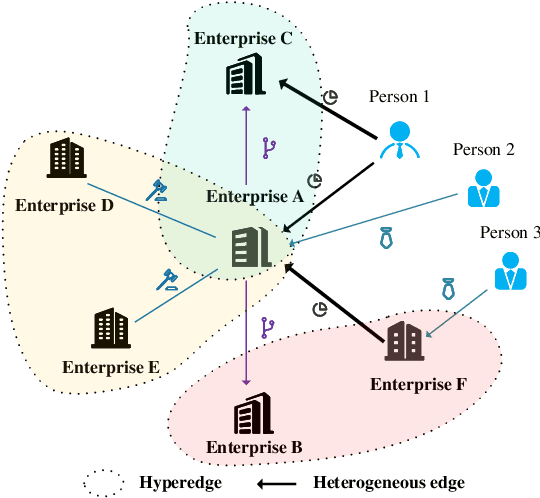
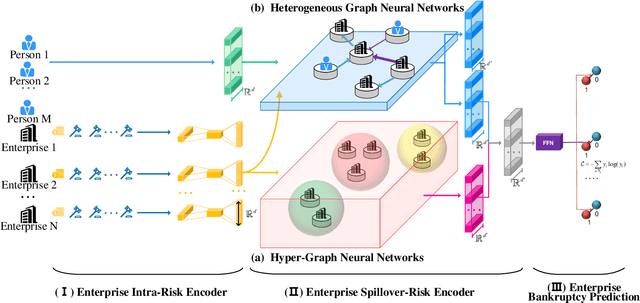
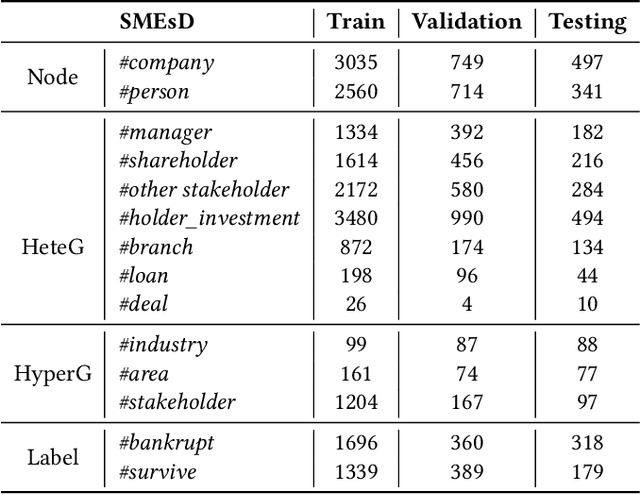
Bankruptcy risk prediction for Small and Medium-sized Enterprises (SMEs) is a crucial step for financial institutions to make the loan decision and identify region economics's early warning. However, previous studies in both finance and AI research fields only consider either the intra-risk or the spillover-risk, ignoring their interactions and their combinatorial effect for simplicity. This paper for the first time considers both risks simultaneously and their joint effect in bankruptcy prediction. Specifically, we first propose an enterprise intra-risk encoder with LSTM based on enterprise risk statistical significance indicators from its basic business information and litigation information for its intra-risk learning. Afterward, we propose an enterprise spillover-risk encoder based on enterprise relational information from the enterprise knowledge graph for its spillover-risk embedding. In particular, the spillover-risk encoder is equipped with both the newly proposed Hyper-Graph Neural Networks (Hyper-GNNs) and Heterogeneous Graph Neural Networks (Heter-GNNs), which is able to model spillover risk from two different aspects, i.e. common risk factors based on hyperedges and direct diffusion risk from the neighbors, respectively. With the two kinds of encoders, a unified framework is designed to simultaneously capture intra-risk and spillover-risk for bankruptcy prediction. To evaluate our model, we collect multi-sources SMEs real-world data and build a novel benchmark dataset SMEsD. We provide open access to the dataset, which is expected to promote the financial risk analysis research further. Experiments on SMEsD against nine SOTA baselines demonstrate the effectiveness of the proposed model for bankruptcy prediction.
Learning Bi-typed Multi-relational Heterogeneous Graph via Dual Hierarchical Attention Networks
Jan 25, 2022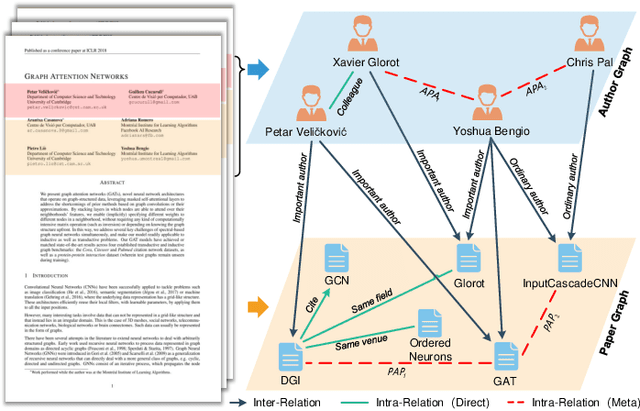
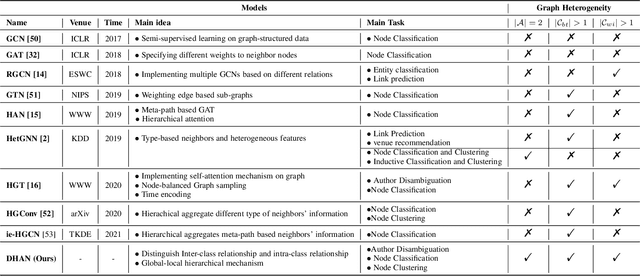
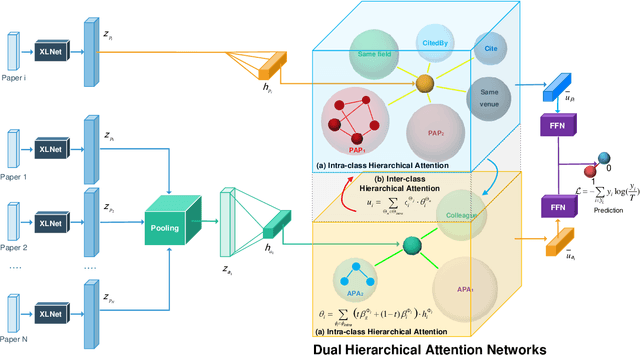

Bi-type multi-relational heterogeneous graph (BMHG) is one of the most common graphs in practice, for example, academic networks, e-commerce user behavior graph and enterprise knowledge graph. It is a critical and challenge problem on how to learn the numerical representation for each node to characterize subtle structures. However, most previous studies treat all node relations in BMHG as the same class of relation without distinguishing the different characteristics between the intra-class relations and inter-class relations of the bi-typed nodes, causing the loss of significant structure information. To address this issue, we propose a novel Dual Hierarchical Attention Networks (DHAN) based on the bi-typed multi-relational heterogeneous graphs to learn comprehensive node representations with the intra-class and inter-class attention-based encoder under a hierarchical mechanism. Specifically, the former encoder aggregates information from the same type of nodes, while the latter aggregates node representations from its different types of neighbors. Moreover, to sufficiently model node multi-relational information in BMHG, we adopt a newly proposed hierarchical mechanism. By doing so, the proposed dual hierarchical attention operations enable our model to fully capture the complex structures of the bi-typed multi-relational heterogeneous graphs. Experimental results on various tasks against the state-of-the-arts sufficiently confirm the capability of DHAN in learning node representations on the BMHGs.
Stock Movement Prediction Based on Bi-typed Hybrid-relational Market Knowledge Graph via Dual Attention Networks
Jan 24, 2022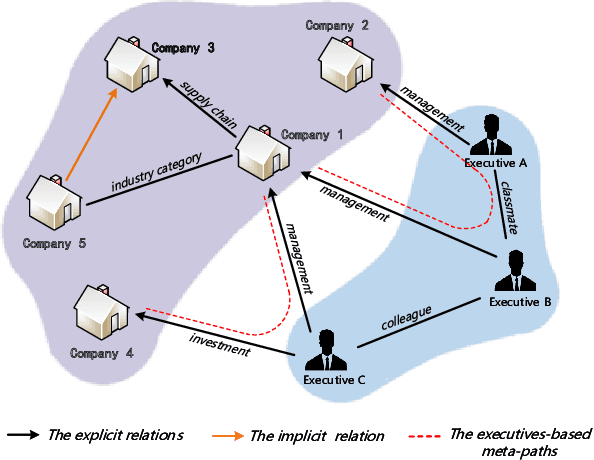
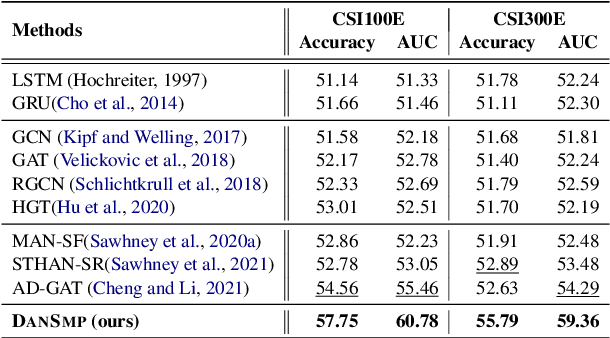
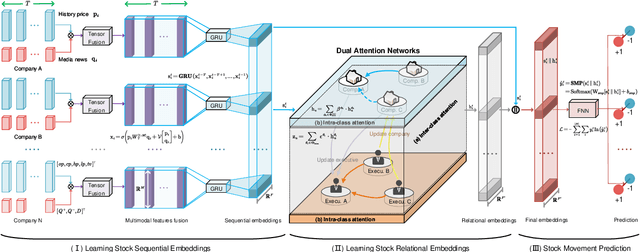
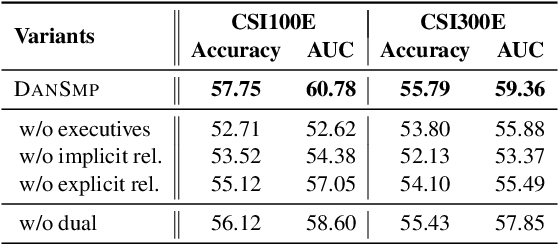
Stock Movement Prediction (SMP) aims at predicting listed companies' stock future price trend, which is a challenging task due to the volatile nature of financial markets. Recent financial studies show that the momentum spillover effect plays a significant role in stock fluctuation. However, previous studies typically only learn the simple connection information among related companies, which inevitably fail to model complex relations of listed companies in the real financial market. To address this issue, we first construct a more comprehensive Market Knowledge Graph (MKG) which contains bi-typed entities including listed companies and their associated executives, and hybrid-relations including the explicit relations and implicit relations. Afterward, we propose DanSmp, a novel Dual Attention Networks to learn the momentum spillover signals based upon the constructed MKG for stock prediction. The empirical experiments on our constructed datasets against nine SOTA baselines demonstrate that the proposed DanSmp is capable of improving stock prediction with the constructed MKG.
Predicting Hourly Demand in Station-free Bike-sharing Systems with Video-level Data
Sep 23, 2020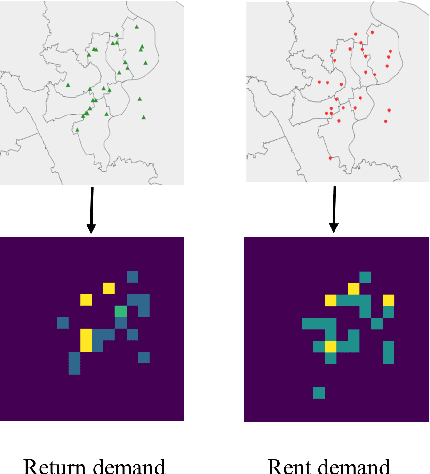
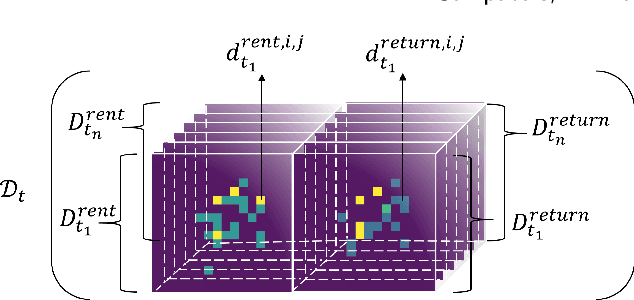
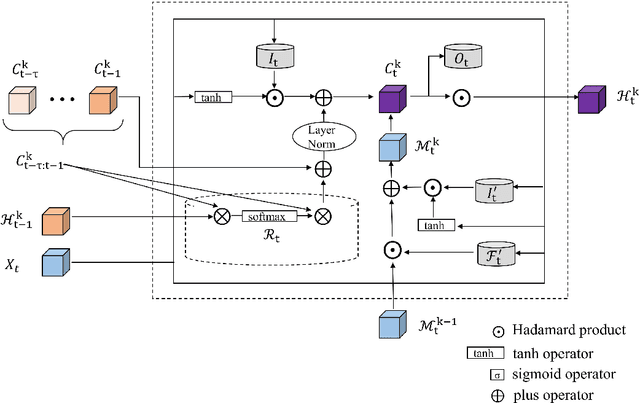
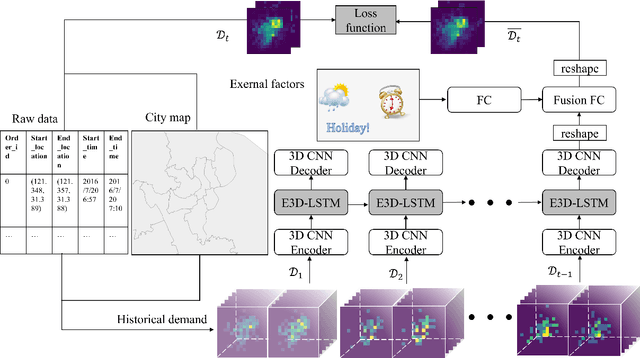
Temporal and spatial features are both important for predicting the demands in the bike-sharing systems. Many relevant experiments in the literature support this. Meanwhile, it is observed that the data structure of spatial features with vector form is weaker in space than the videos, which have natural spatial structure. Therefore, to obtain more spatial features, this study introduces city map to generate GPS demand videos while employing a novel algorithm : eidetic 3D convolutional long short-term memory network named E3D-LSTM to process the video-level data in bike-sharing system. The spatio-temporal correlations and feature importance are experimented and visualized to validate the significance of spatial and temporal features. Despite the deep learning model is powerful in non-linear fitting ability, statistic model has better interpretation. This study adopts ensemble learning, which is a popular policy, to improve the performance and decrease variance. In this paper, we propose a novel model stacked by deep learning and statistical models, named the fusion multi-channel eidetic 3D convolutional long short-term memory network(FM-E3DCL-Net), to better process temporal and spatial features on the dataset about 100,000 transactions within one month in Shanghai of Mobike company. Furthermore, other factors like weather, holiday and time intervals are proved useful in addition to historical demand, since they decrease the root mean squared error (RMSE) by 29.4%. On this basis, the ensemble learning further decreases RMSE by 6.6%.
Distributed Linguistic Representations in Decision Making: Taxonomy, Key Elements and Applications, and Challenges in Data Science and Explainable Artificial Intelligence
Aug 07, 2020
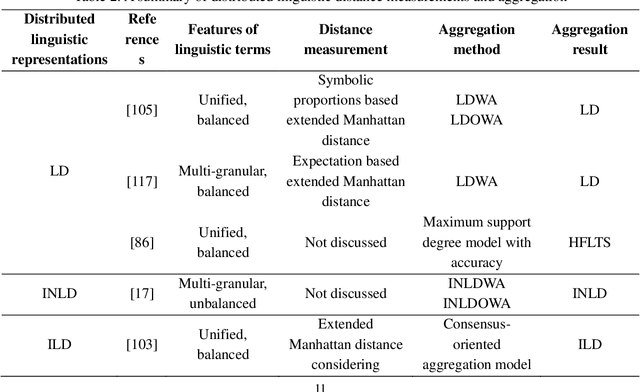
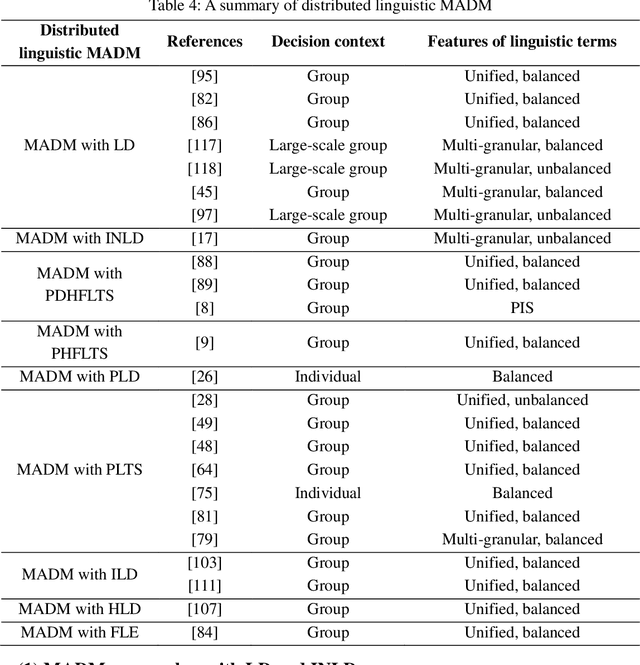
Distributed linguistic representations are powerful tools for modelling the uncertainty and complexity of preference information in linguistic decision making. To provide a comprehensive perspective on the development of distributed linguistic representations in decision making, we present the taxonomy of existing distributed linguistic representations. Then, we review the key elements of distributed linguistic information processing in decision making, including the distance measurement, aggregation methods, distributed linguistic preference relations, and distributed linguistic multiple attribute decision making models. Next, we provide a discussion on ongoing challenges and future research directions from the perspective of data science and explainable artificial intelligence.
Learning Spatiotemporal Features of Ride-sourcing Services with Fusion Convolutional Network
Apr 15, 2019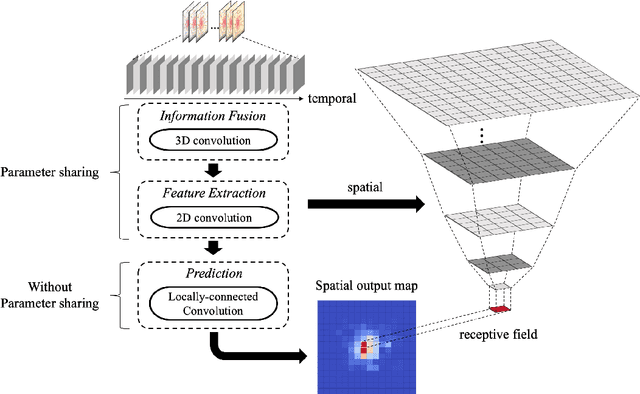
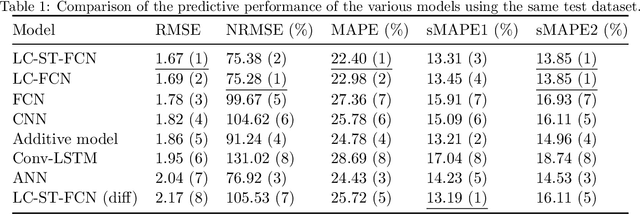
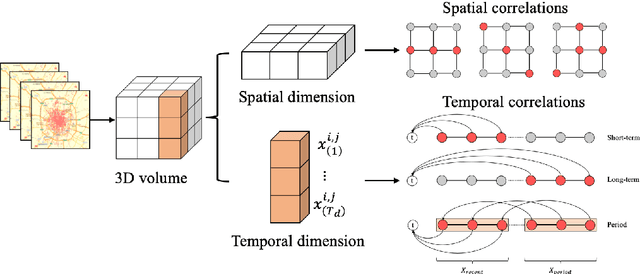

In order to collectively forecast the demand of ride-sourcing services in all regions of a city, convolutional neural networks (CNNs) have been applied with commendable results. However, local statistical differences throughout the geographical layout of the city make the spatial stationarity assumption of the convolution invalid, which limits the performance of CNNs on demand forecasting task. Hence, we propose a novel deep learning framework called LC-ST-FCN (locally-connected spatiotemporal fully-convolutional neural network) that consists of a stack of 3D convolutional layers, 2D (standard) convolutional layers, and locally connected convolutional layers. This fully convolutional architecture maintains the spatial coordinates of the input and no spatial information is lost between layers. Features are fused across layers to define a tunable nonlinear local-to-global-to-local representation, where both global and local statistics can be learned to improve predictive performance. Furthermore, as the local statistics vary from region to region, the arithmetic-mean-based metrics frequently used in spatial stationarity situations cannot effectively evaluate the models. We propose a weighted-arithmetic approach to deal with this situation. In the experiments, a real dataset from a ride-sourcing service platform (DiDiChuxing) is used, which demonstrates the effectiveness and superiority of our proposed model and evaluation method.