 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuplex Self-Aligning Resonant Beam Communications and Power Transfer with Coupled Spatially Distributed Laser Resonator
May 08, 2025



Sustainable energy supply and high-speed communications are two significant needs for mobile electronic devices. This paper introduces a self-aligning resonant beam system for simultaneous light information and power transfer (SLIPT), employing a novel coupled spatially distributed resonator (CSDR). The system utilizes a resonant beam for efficient power delivery and a second-harmonic beam for concurrent data transmission, inherently minimizing echo interference and enabling bidirectional communication. Through comprehensive analyses, we investigate the CSDR's stable region, beam evolution, and power characteristics in relation to working distance and device parameters. Numerical simulations validate the CSDR-SLIPT system's feasibility by identifying a stable beam waist location for achieving accurate mode-match coupling between two spatially distributed resonant cavities and demonstrating its operational range and efficient power delivery across varying distances. The research reveals the system's benefits in terms of both safety and energy transmission efficiency. We also demonstrate the trade-off among the reflectivities of the cavity mirrors in the CSDR. These findings offer valuable design insights for resonant beam systems, advancing SLIPT with significant potential for remote device connectivity.
SepALM: Audio Language Models Are Error Correctors for Robust Speech Separation
May 06, 2025While contemporary speech separation technologies adeptly process lengthy mixed audio waveforms, they are frequently challenged by the intricacies of real-world environments, including noisy and reverberant settings, which can result in artifacts or distortions in the separated speech. To overcome these limitations, we introduce SepALM, a pioneering approach that employs audio language models (ALMs) to rectify and re-synthesize speech within the text domain following preliminary separation. SepALM comprises four core components: a separator, a corrector, a synthesizer, and an aligner. By integrating an ALM-based end-to-end error correction mechanism, we mitigate the risk of error accumulation and circumvent the optimization hurdles typically encountered in conventional methods that amalgamate automatic speech recognition (ASR) with large language models (LLMs). Additionally, we have developed Chain-of-Thought (CoT) prompting and knowledge distillation techniques to facilitate the reasoning and training processes of the ALM. Our experiments substantiate that SepALM not only elevates the precision of speech separation but also markedly bolsters adaptability in novel acoustic environments.
HoloDx: Knowledge- and Data-Driven Multimodal Diagnosis of Alzheimer's Disease
Apr 27, 2025



Accurate diagnosis of Alzheimer's disease (AD) requires effectively integrating multimodal data and clinical expertise. However, existing methods often struggle to fully utilize multimodal information and lack structured mechanisms to incorporate dynamic domain knowledge. To address these limitations, we propose HoloDx, a knowledge- and data-driven framework that enhances AD diagnosis by aligning domain knowledge with multimodal clinical data. HoloDx incorporates a knowledge injection module with a knowledge-aware gated cross-attention, allowing the model to dynamically integrate domain-specific insights from both large language models (LLMs) and clinical expertise. Also, a memory injection module with a designed prototypical memory attention enables the model to retain and retrieve subject-specific information, ensuring consistency in decision-making. By jointly leveraging these mechanisms, HoloDx enhances interpretability, improves robustness, and effectively aligns prior knowledge with current subject data. Evaluations on five AD datasets demonstrate that HoloDx outperforms state-of-the-art methods, achieving superior diagnostic accuracy and strong generalization across diverse cohorts. The source code will be released upon publication acceptance.
Regret-aware Re-ranking for Guaranteeing Two-sided Fairness and Accuracy in Recommender Systems
Apr 20, 2025



In multi-stakeholder recommender systems (RS), users and providers operate as two crucial and interdependent roles, whose interests must be well-balanced. Prior research, including our work BankFair, has demonstrated the importance of guaranteeing both provider fairness and user accuracy to meet their interests. However, when they balance the two objectives, another critical factor emerges in RS: individual fairness, which manifests as a significant disparity in individual recommendation accuracy, with some users receiving high accuracy while others are left with notably low accuracy. This oversight severely harms the interests of users and exacerbates social polarization. How to guarantee individual fairness while ensuring user accuracy and provider fairness remains an unsolved problem. To bridge this gap, in this paper, we propose our method BankFair+. Specifically, BankFair+ extends BankFair with two steps: (1) introducing a non-linear function from regret theory to ensure individual fairness while enhancing user accuracy; (2) formulating the re-ranking process as a regret-aware fuzzy programming problem to meet the interests of both individual user and provider, therefore balancing the trade-off between individual fairness and provider fairness. Experiments on two real-world recommendation datasets demonstrate that BankFair+ outperforms all baselines regarding individual fairness, user accuracy, and provider fairness.
Robust Offline Imitation Learning Through State-level Trajectory Stitching
Mar 28, 2025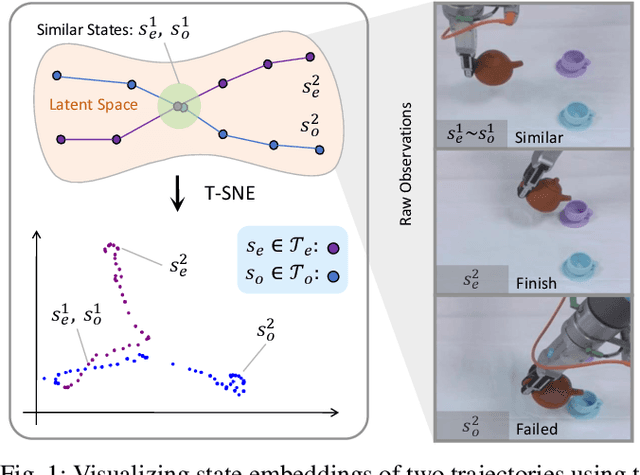

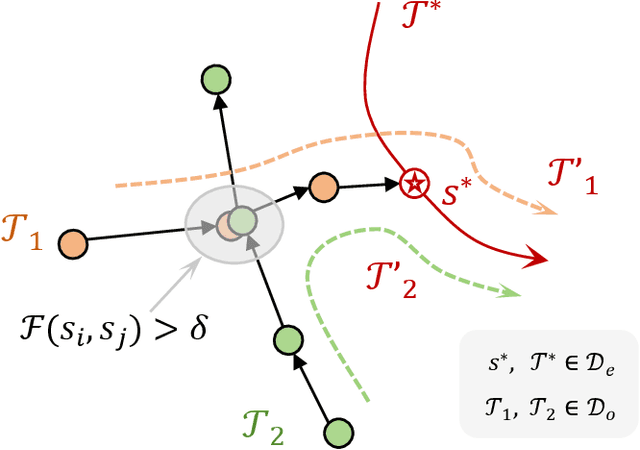

Imitation learning (IL) has proven effective for enabling robots to acquire visuomotor skills through expert demonstrations. However, traditional IL methods are limited by their reliance on high-quality, often scarce, expert data, and suffer from covariate shift. To address these challenges, recent advances in offline IL have incorporated suboptimal, unlabeled datasets into the training. In this paper, we propose a novel approach to enhance policy learning from mixed-quality offline datasets by leveraging task-relevant trajectory fragments and rich environmental dynamics. Specifically, we introduce a state-based search framework that stitches state-action pairs from imperfect demonstrations, generating more diverse and informative training trajectories. Experimental results on standard IL benchmarks and real-world robotic tasks showcase that our proposed method significantly improves both generalization and performance.
The Emperor's New Clothes in Benchmarking? A Rigorous Examination of Mitigation Strategies for LLM Benchmark Data Contamination
Mar 20, 2025



Benchmark Data Contamination (BDC)-the inclusion of benchmark testing samples in the training set-has raised increasing concerns in Large Language Model (LLM) evaluation, leading to falsely inflated performance estimates and undermining evaluation reliability. To address this, researchers have proposed various mitigation strategies to update existing benchmarks, including modifying original questions or generating new ones based on them. However, a rigorous examination of the effectiveness of these mitigation strategies remains lacking. In this paper, we design a systematic and controlled pipeline along with two novel metrics-fidelity and contamination resistance-to provide a fine-grained and comprehensive assessment of existing BDC mitigation strategies. Previous assessment methods, such as accuracy drop and accuracy matching, focus solely on aggregate accuracy, often leading to incomplete or misleading conclusions. Our metrics address this limitation by emphasizing question-level evaluation result matching. Extensive experiments with 10 LLMs, 5 benchmarks, 20 BDC mitigation strategies, and 2 contamination scenarios reveal that no existing strategy significantly improves resistance over the vanilla case (i.e., no benchmark update) across all benchmarks, and none effectively balances fidelity and contamination resistance. These findings underscore the urgent need for designing more effective BDC mitigation strategies. Our code repository is available at https://github.com/ASTRAL-Group/BDC_mitigation_assessment.
Perplexity Trap: PLM-Based Retrievers Overrate Low Perplexity Documents
Mar 11, 2025



Previous studies have found that PLM-based retrieval models exhibit a preference for LLM-generated content, assigning higher relevance scores to these documents even when their semantic quality is comparable to human-written ones. This phenomenon, known as source bias, threatens the sustainable development of the information access ecosystem. However, the underlying causes of source bias remain unexplored. In this paper, we explain the process of information retrieval with a causal graph and discover that PLM-based retrievers learn perplexity features for relevance estimation, causing source bias by ranking the documents with low perplexity higher. Theoretical analysis further reveals that the phenomenon stems from the positive correlation between the gradients of the loss functions in language modeling task and retrieval task. Based on the analysis, a causal-inspired inference-time debiasing method is proposed, called Causal Diagnosis and Correction (CDC). CDC first diagnoses the bias effect of the perplexity and then separates the bias effect from the overall estimated relevance score. Experimental results across three domains demonstrate the superior debiasing effectiveness of CDC, emphasizing the validity of our proposed explanatory framework. Source codes are available at https://github.com/WhyDwelledOnAi/Perplexity-Trap.
Catching Spinning Table Tennis Balls in Simulation with End-to-End Curriculum Reinforcement Learning
Mar 03, 2025



The game of table tennis is renowned for its extremely high spin rate, but most table tennis robots today struggle to handle balls with such rapid spin. To address this issue, we have contributed a series of methods, including: 1. Curriculum Reinforcement Learning (RL): This method helps the table tennis robot learn to play table tennis progressively from easy to difficult tasks. 2. Analysis of Spinning Table Tennis Ball Collisions: We have conducted a physics-based analysis to generate more realistic trajectories of spinning table tennis balls after collision. 3. Definition of Trajectory States: The definition of trajectory states aids in setting up the reward function. 4. Selection of Valid Rally Trajectories: We have introduced a valid rally trajectory selection scheme to ensure that the robot's training is not influenced by abnormal trajectories. 5. Reality-to-Simulation (Real2Sim) Transfer: This scheme is employed to validate the trained robot's ability to handle spinning balls in real-world scenarios. With Real2Sim, the deployment costs for robotic reinforcement learning can be further reduced. Moreover, the trajectory-state-based reward function is not limited to table tennis robots; it can be generalized to a wide range of cyclical tasks. To validate our robot's ability to handle spinning balls, the Real2Sim experiments were conducted. For the specific video link of the experiment, please refer to the supplementary materials.
Inference Computation Scaling for Feature Augmentation in Recommendation Systems
Feb 22, 2025Large language models have become a powerful method for feature augmentation in recommendation systems. However, existing approaches relying on quick inference often suffer from incomplete feature coverage and insufficient specificity in feature descriptions, limiting their ability to capture fine-grained user preferences and undermining overall performance. Motivated by the recent success of inference scaling in math and coding tasks, we explore whether scaling inference can address these limitations and enhance feature quality. Our experiments show that scaling inference leads to significant improvements in recommendation performance, with a 12% increase in NDCG@10. The gains can be attributed to two key factors: feature quantity and specificity. In particular, models using extended Chain-of-Thought (CoT) reasoning generate a greater number of detailed and precise features, offering deeper insights into user preferences and overcoming the limitations of quick inference. We further investigate the factors influencing feature quantity, revealing that model choice and search strategy play critical roles in generating a richer and more diverse feature set. This is the first work to apply inference scaling to feature augmentation in recommendation systems, bridging advances in reasoning tasks to enhance personalized recommendation.
Uncertainty-Aware Graph Structure Learning
Feb 19, 2025



Graph Neural Networks (GNNs) have become a prominent approach for learning from graph-structured data. However, their effectiveness can be significantly compromised when the graph structure is suboptimal. To address this issue, Graph Structure Learning (GSL) has emerged as a promising technique that refines node connections adaptively. Nevertheless, we identify two key limitations in existing GSL methods: 1) Most methods primarily focus on node similarity to construct relationships, while overlooking the quality of node information. Blindly connecting low-quality nodes and aggregating their ambiguous information can degrade the performance of other nodes. 2) The constructed graph structures are often constrained to be symmetric, which may limit the model's flexibility and effectiveness. To overcome these limitations, we propose an Uncertainty-aware Graph Structure Learning (UnGSL) strategy. UnGSL estimates the uncertainty of node information and utilizes it to adjust the strength of directional connections, where the influence of nodes with high uncertainty is adaptively reduced. Importantly, UnGSL serves as a plug-in module that can be seamlessly integrated into existing GSL methods with minimal additional computational cost. In our experiments, we implement UnGSL into six representative GSL methods, demonstrating consistent performance improvements.