 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoMV: An Automatic Multi-Agent System for Music Video Generation
Dec 13, 2025Music-to-Video (M2V) generation for full-length songs faces significant challenges. Existing methods produce short, disjointed clips, failing to align visuals with musical structure, beats, or lyrics, and lack temporal consistency. We propose AutoMV, a multi-agent system that generates full music videos (MVs) directly from a song. AutoMV first applies music processing tools to extract musical attributes, such as structure, vocal tracks, and time-aligned lyrics, and constructs these features as contextual inputs for following agents. The screenwriter Agent and director Agent then use this information to design short script, define character profiles in a shared external bank, and specify camera instructions. Subsequently, these agents call the image generator for keyframes and different video generators for "story" or "singer" scenes. A Verifier Agent evaluates their output, enabling multi-agent collaboration to produce a coherent longform MV. To evaluate M2V generation, we further propose a benchmark with four high-level categories (Music Content, Technical, Post-production, Art) and twelve ine-grained criteria. This benchmark was applied to compare commercial products, AutoMV, and human-directed MVs with expert human raters: AutoMV outperforms current baselines significantly across all four categories, narrowing the gap to professional MVs. Finally, we investigate using large multimodal models as automatic MV judges; while promising, they still lag behind human expert, highlighting room for future work.
LaVA-Man: Learning Visual Action Representations for Robot Manipulation
Aug 26, 2025Visual-textual understanding is essential for language-guided robot manipulation. Recent works leverage pre-trained vision-language models to measure the similarity between encoded visual observations and textual instructions, and then train a model to map this similarity to robot actions. However, this two-step approach limits the model to capture the relationship between visual observations and textual instructions, leading to reduced precision in manipulation tasks. We propose to learn visual-textual associations through a self-supervised pretext task: reconstructing a masked goal image conditioned on an input image and textual instructions. This formulation allows the model to learn visual-action representations without robot action supervision. The learned representations can then be fine-tuned for manipulation tasks with only a few demonstrations. We also introduce the \textit{Omni-Object Pick-and-Place} dataset, which consists of annotated robot tabletop manipulation episodes, including 180 object classes and 3,200 instances with corresponding textual instructions. This dataset enables the model to acquire diverse object priors and allows for a more comprehensive evaluation of its generalisation capability across object instances. Experimental results on the five benchmarks, including both simulated and real-robot validations, demonstrate that our method outperforms prior art.
CCTNet: A Circular Convolutional Transformer Network for LiDAR-based Place Recognition Handling Movable Objects Occlusion
May 17, 2024



Place recognition is a fundamental task for robotic application, allowing robots to perform loop closure detection within simultaneous localization and mapping (SLAM), and achieve relocalization on prior maps. Current range image-based networks use single-column convolution to maintain feature invariance to shifts in image columns caused by LiDAR viewpoint change.However, this raises the issues such as "restricted receptive fields" and "excessive focus on local regions", degrading the performance of networks. To address the aforementioned issues, we propose a lightweight circular convolutional Transformer network denoted as CCTNet, which boosts performance by capturing structural information in point clouds and facilitating crossdimensional interaction of spatial and channel information. Initially, a Circular Convolution Module (CCM) is introduced, expanding the network's perceptual field while maintaining feature consistency across varying LiDAR perspectives. Then, a Range Transformer Module (RTM) is proposed, which enhances place recognition accuracy in scenarios with movable objects by employing a combination of channel and spatial attention mechanisms. Furthermore, we propose an Overlap-based loss function, transforming the place recognition task from a binary loop closure classification into a regression problem linked to the overlap between LiDAR frames. Through extensive experiments on the KITTI and Ford Campus datasets, CCTNet surpasses comparable methods, achieving Recall@1 of 0.924 and 0.965, and Recall@1% of 0.990 and 0.993 on the test set, showcasing a superior performance. Results on the selfcollected dataset further demonstrate the proposed method's potential for practical implementation in complex scenarios to handle movable objects, showing improved generalization in various datasets.
Improving Generalization of Deep Networks for Estimating Physical Properties of Containers and Fillings
Mar 02, 2022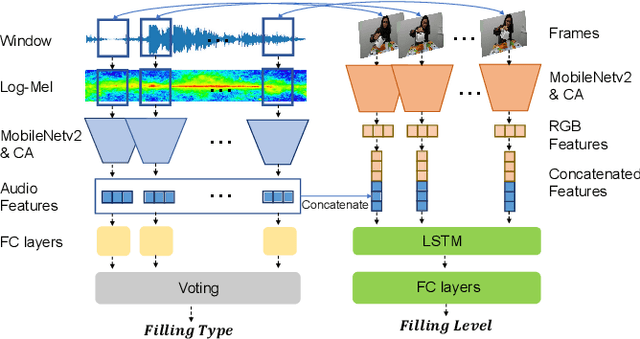
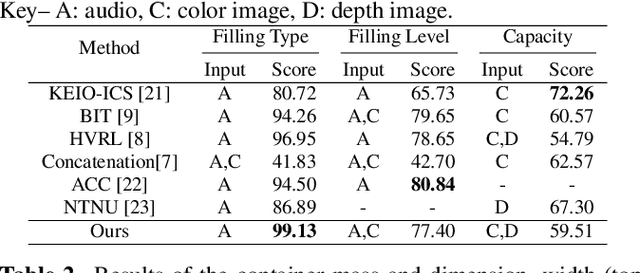
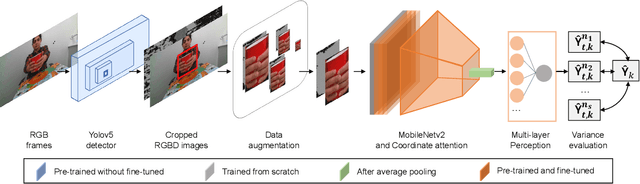

We present methods to estimate the physical properties of household containers and their fillings manipulated by humans. We use a lightweight, pre-trained convolutional neural network with coordinate attention as a backbone model of the pipelines to accurately locate the object of interest and estimate the physical properties in the CORSMAL Containers Manipulation (CCM) dataset. We address the filling type classification with audio data and then combine this information from audio with video modalities to address the filling level classification. For the container capacity, dimension, and mass estimation, we present a data augmentation and consistency measurement to alleviate the over-fitting issue in the CCM dataset caused by the limited number of containers. We augment the training data using an object-of-interest-based re-scaling that increases the variety of physical values of the containers. We then perform the consistency measurement to choose a model with low prediction variance in the same containers under different scenes, which ensures the generalization ability of the model. Our method improves the generalization ability of the models to estimate the property of the containers that were not previously seen in the training.