 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFriendNet: Detection-Friendly Dehazing Network
Mar 07, 2024



Adverse weather conditions often impair the quality of captured images, inevitably inducing cutting-edge object detection models for advanced driver assistance systems (ADAS) and autonomous driving. In this paper, we raise an intriguing question: can the combination of image restoration and object detection enhance detection performance in adverse weather conditions? To answer it, we propose an effective architecture that bridges image dehazing and object detection together via guidance information and task-driven learning to achieve detection-friendly dehazing, termed FriendNet. FriendNet aims to deliver both high-quality perception and high detection capacity. Different from existing efforts that intuitively treat image dehazing as pre-processing, FriendNet establishes a positive correlation between these two tasks. Clean features generated by the dehazing network potentially contribute to improvements in object detection performance. Conversely, object detection crucially guides the learning process of the image dehazing network under the task-driven learning scheme. We shed light on how downstream tasks can guide upstream dehazing processes, considering both network architecture and learning objectives. We design Guidance Fusion Block (GFB) and Guidance Attention Block (GAB) to facilitate the integration of detection information into the network. Furthermore, the incorporation of the detection task loss aids in refining the optimization process. Additionally, we introduce a new Physics-aware Feature Enhancement Block (PFEB), which integrates physics-based priors to enhance the feature extraction and representation capabilities. Extensive experiments on synthetic and real-world datasets demonstrate the superiority of our method over state-of-the-art methods on both image quality and detection precision. Our source code is available at https://github.com/fanyihua0309/FriendNet.
Parameter-Efficient Fine-Tuning Methods for Pretrained Language Models: A Critical Review and Assessment
Dec 19, 2023With the continuous growth in the number of parameters of transformer-based pretrained language models (PLMs), particularly the emergence of large language models (LLMs) with billions of parameters, many natural language processing (NLP) tasks have demonstrated remarkable success. However, the enormous size and computational demands of these models pose significant challenges for adapting them to specific downstream tasks, especially in environments with limited computational resources. Parameter Efficient Fine-Tuning (PEFT) offers an effective solution by reducing the number of fine-tuning parameters and memory usage while achieving comparable performance to full fine-tuning. The demands for fine-tuning PLMs, especially LLMs, have led to a surge in the development of PEFT methods, as depicted in Fig. 1. In this paper, we present a comprehensive and systematic review of PEFT methods for PLMs. We summarize these PEFT methods, discuss their applications, and outline future directions. Furthermore, we conduct experiments using several representative PEFT methods to better understand their effectiveness in parameter efficiency and memory efficiency. By offering insights into the latest advancements and practical applications, this survey serves as an invaluable resource for researchers and practitioners seeking to navigate the challenges and opportunities presented by PEFT in the context of PLMs.
Cross-BERT for Point Cloud Pretraining
Dec 08, 2023



Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
Recurrent Attention Networks for Long-text Modeling
Jun 12, 2023Self-attention-based models have achieved remarkable progress in short-text mining. However, the quadratic computational complexities restrict their application in long text processing. Prior works have adopted the chunking strategy to divide long documents into chunks and stack a self-attention backbone with the recurrent structure to extract semantic representation. Such an approach disables parallelization of the attention mechanism, significantly increasing the training cost and raising hardware requirements. Revisiting the self-attention mechanism and the recurrent structure, this paper proposes a novel long-document encoding model, Recurrent Attention Network (RAN), to enable the recurrent operation of self-attention. Combining the advantages from both sides, the well-designed RAN is capable of extracting global semantics in both token-level and document-level representations, making it inherently compatible with both sequential and classification tasks, respectively. Furthermore, RAN is computationally scalable as it supports parallelization on long document processing. Extensive experiments demonstrate the long-text encoding ability of the proposed RAN model on both classification and sequential tasks, showing its potential for a wide range of applications.
Search By Image: Deeply Exploring Beneficial Features for Beauty Product Retrieval
Mar 24, 2023Searching by image is popular yet still challenging due to the extensive interference arose from i) data variations (e.g., background, pose, visual angle, brightness) of real-world captured images and ii) similar images in the query dataset. This paper studies a practically meaningful problem of beauty product retrieval (BPR) by neural networks. We broadly extract different types of image features, and raise an intriguing question that whether these features are beneficial to i) suppress data variations of real-world captured images, and ii) distinguish one image from others which look very similar but are intrinsically different beauty products in the dataset, therefore leading to an enhanced capability of BPR. To answer it, we present a novel variable-attention neural network to understand the combination of multiple features (termed VM-Net) of beauty product images. Considering that there are few publicly released training datasets for BPR, we establish a new dataset with more than one million images classified into more than 20K categories to improve both the generalization and anti-interference abilities of VM-Net and other methods. We verify the performance of VM-Net and its competitors on the benchmark dataset Perfect-500K, where VM-Net shows clear improvements over the competitors in terms of MAP@7. The source code and dataset will be released upon publication.
RainDiffusion:When Unsupervised Learning Meets Diffusion Models for Real-world Image Deraining
Jan 23, 2023



What will happen when unsupervised learning meets diffusion models for real-world image deraining? To answer it, we propose RainDiffusion, the first unsupervised image deraining paradigm based on diffusion models. Beyond the traditional unsupervised wisdom of image deraining, RainDiffusion introduces stable training of unpaired real-world data instead of weakly adversarial training. RainDiffusion consists of two cooperative branches: Non-diffusive Translation Branch (NTB) and Diffusive Translation Branch (DTB). NTB exploits a cycle-consistent architecture to bypass the difficulty in unpaired training of standard diffusion models by generating initial clean/rainy image pairs. DTB leverages two conditional diffusion modules to progressively refine the desired output with initial image pairs and diffusive generative prior, to obtain a better generalization ability of deraining and rain generation. Rain-Diffusion is a non adversarial training paradigm, serving as a new standard bar for real-world image deraining. Extensive experiments confirm the superiority of our RainDiffusion over un/semi-supervised methods and show its competitive advantages over fully-supervised ones.
PointSee: Image Enhances Point Cloud
Nov 03, 2022



There is a trend to fuse multi-modal information for 3D object detection (3OD). However, the challenging problems of low lightweightness, poor flexibility of plug-and-play, and inaccurate alignment of features are still not well-solved, when designing multi-modal fusion newtorks. We propose PointSee, a lightweight, flexible and effective multi-modal fusion solution to facilitate various 3OD networks by semantic feature enhancement of LiDAR point clouds assembled with scene images. Beyond the existing wisdom of 3OD, PointSee consists of a hidden module (HM) and a seen module (SM): HM decorates LiDAR point clouds using 2D image information in an offline fusion manner, leading to minimal or even no adaptations of existing 3OD networks; SM further enriches the LiDAR point clouds by acquiring point-wise representative semantic features, leading to enhanced performance of existing 3OD networks. Besides the new architecture of PointSee, we propose a simple yet efficient training strategy, to ease the potential inaccurate regressions of 2D object detection networks. Extensive experiments on the popular outdoor/indoor benchmarks show numerical improvements of our PointSee over twenty-two state-of-the-arts.
GeoGCN: Geometric Dual-domain Graph Convolution Network for Point Cloud Denoising
Oct 28, 2022We propose GeoGCN, a novel geometric dual-domain graph convolution network for point cloud denoising (PCD). Beyond the traditional wisdom of PCD, to fully exploit the geometric information of point clouds, we define two kinds of surface normals, one is called Real Normal (RN), and the other is Virtual Normal (VN). RN preserves the local details of noisy point clouds while VN avoids the global shape shrinkage during denoising. GeoGCN is a new PCD paradigm that, 1) first regresses point positions by spatialbased GCN with the help of VNs, 2) then estimates initial RNs by performing Principal Component Analysis on the regressed points, and 3) finally regresses fine RNs by normalbased GCN. Unlike existing PCD methods, GeoGCN not only exploits two kinds of geometry expertise (i.e., RN and VN) but also benefits from training data. Experiments validate that GeoGCN outperforms SOTAs in terms of both noise-robustness and local-and-global feature preservation.
SPCNet: Stepwise Point Cloud Completion Network
Sep 05, 2022
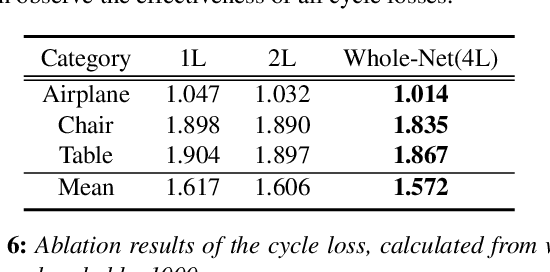
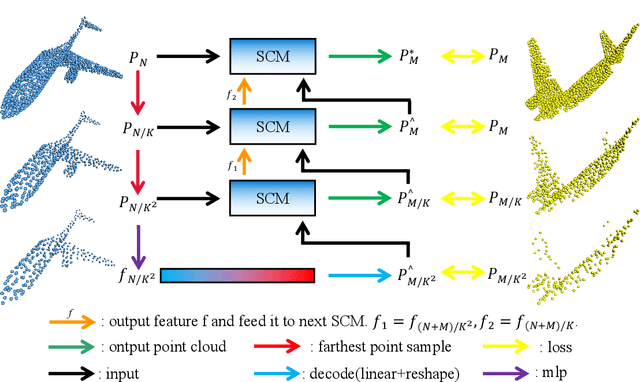
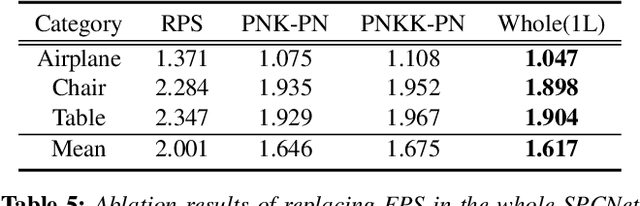
How will you repair a physical object with large missings? You may first recover its global yet coarse shape and stepwise increase its local details. We are motivated to imitate the above physical repair procedure to address the point cloud completion task. We propose a novel stepwise point cloud completion network (SPCNet) for various 3D models with large missings. SPCNet has a hierarchical bottom-to-up network architecture. It fulfills shape completion in an iterative manner, which 1) first infers the global feature of the coarse result; 2) then infers the local feature with the aid of global feature; and 3) finally infers the detailed result with the help of local feature and coarse result. Beyond the wisdom of simulating the physical repair, we newly design a cycle loss %based training strategy to enhance the generalization and robustness of SPCNet. Extensive experiments clearly show the superiority of our SPCNet over the state-of-the-art methods on 3D point clouds with large missings.
TogetherNet: Bridging Image Restoration and Object Detection Together via Dynamic Enhancement Learning
Sep 03, 2022
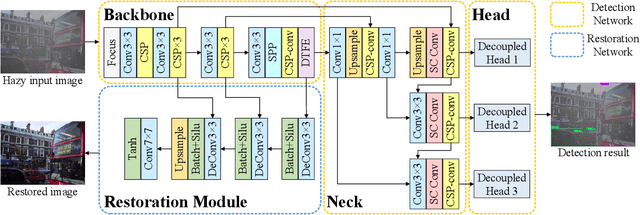
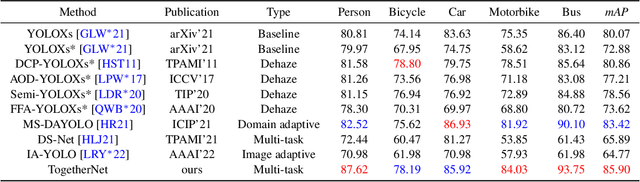
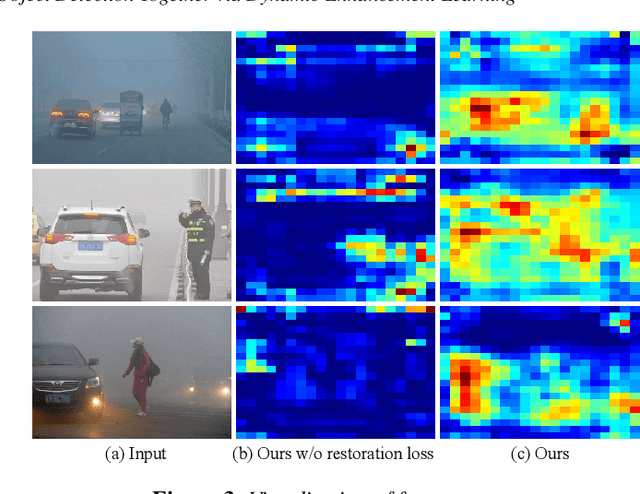
Adverse weather conditions such as haze, rain, and snow often impair the quality of captured images, causing detection networks trained on normal images to generalize poorly in these scenarios. In this paper, we raise an intriguing question - if the combination of image restoration and object detection, can boost the performance of cutting-edge detectors in adverse weather conditions. To answer it, we propose an effective yet unified detection paradigm that bridges these two subtasks together via dynamic enhancement learning to discern objects in adverse weather conditions, called TogetherNet. Different from existing efforts that intuitively apply image dehazing/deraining as a pre-processing step, TogetherNet considers a multi-task joint learning problem. Following the joint learning scheme, clean features produced by the restoration network can be shared to learn better object detection in the detection network, thus helping TogetherNet enhance the detection capacity in adverse weather conditions. Besides the joint learning architecture, we design a new Dynamic Transformer Feature Enhancement module to improve the feature extraction and representation capabilities of TogetherNet. Extensive experiments on both synthetic and real-world datasets demonstrate that our TogetherNet outperforms the state-of-the-art detection approaches by a large margin both quantitatively and qualitatively. Source code is available at https://github.com/yz-wang/TogetherNet.