 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Locomotion Skills with Hierarchical Reinforcement Learning
Sep 26, 2019
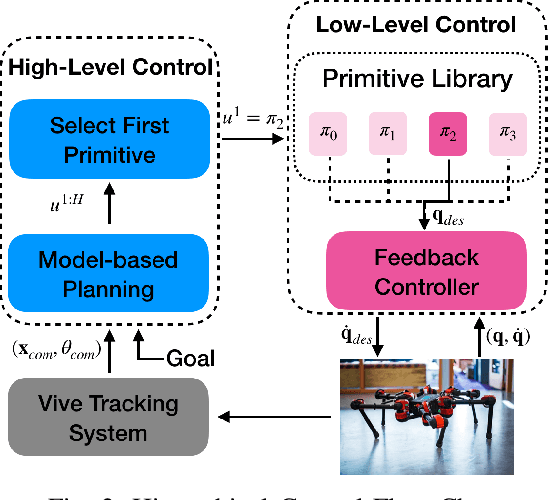
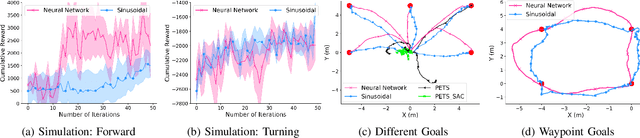
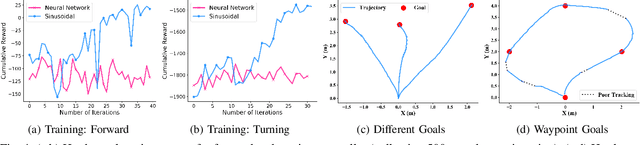
Learning to locomote to arbitrary goals on hardware remains a challenging problem for reinforcement learning. In this paper, we present a hierarchical learning framework that improves sample-efficiency and generalizability of locomotion skills on real-world robots. Our approach divides the problem of goal-oriented locomotion into two sub-problems: learning diverse primitives skills, and using model-based planning to sequence these skills. We parametrize our primitives as cyclic movements, improving sample-efficiency of learning on a 18 degrees of freedom robot. Then, we learn coarse dynamics models over primitive cycles and use them in a model predictive control framework. This allows us to learn to walk to arbitrary goals up to 12m away, after about two hours of training from scratch on hardware. Our results on a Daisy hexapod hardware and simulation demonstrate the efficacy of our approach at reaching distant targets, in different environments and with sensory noise.
Meta-Learning via Learned Loss
Jun 12, 2019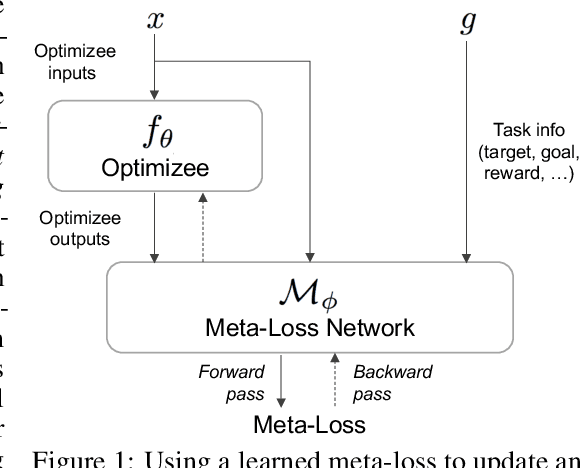
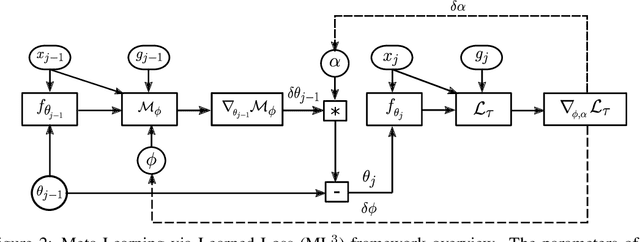
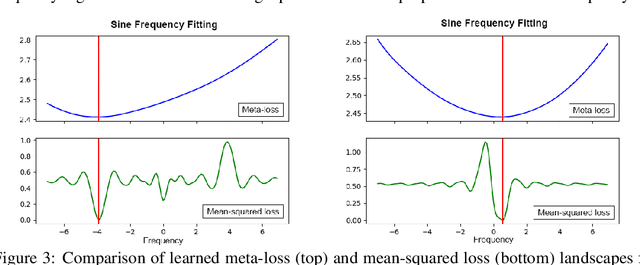
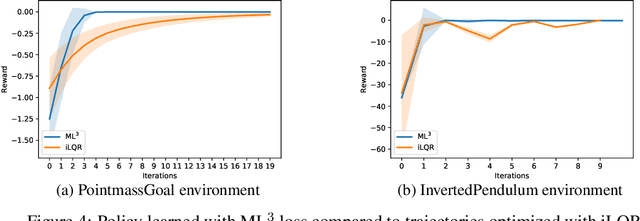
We present a meta-learning approach based on learning an adaptive, high-dimensional loss function that can generalize across multiple tasks and different model architectures. We develop a fully differentiable pipeline for learning a loss function targeted at maximizing the performance of an optimizee trained using this loss function. We observe that the loss landscape produced by our learned loss significantly improves upon the original task-specific loss. We evaluate our method on supervised and reinforcement learning tasks. Furthermore, we show that our pipeline is able to operate in sparse reward and self-supervised reinforcement learning scenarios.
Curious iLQR: Resolving Uncertainty in Model-based RL
Apr 15, 2019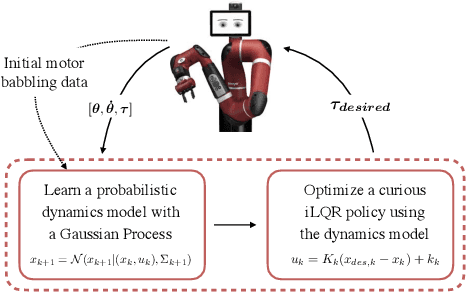
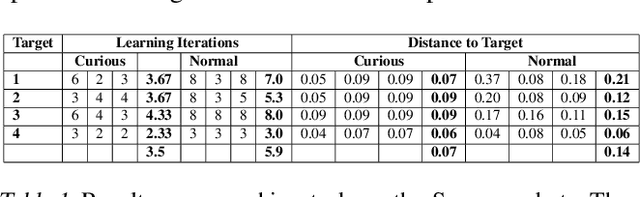
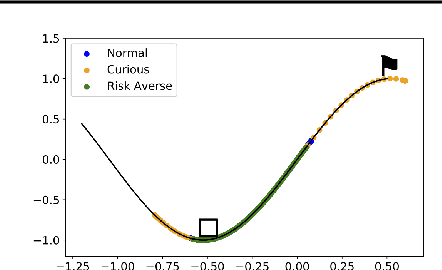
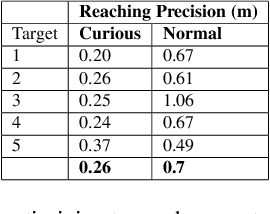
Curiosity as a means to explore during reinforcement learning problems has recently become very popular. However, very little progress has been made in utilizing curiosity for learning control. In this work, we propose a model-based reinforcement learning (MBRL) framework that combines Bayesian modeling of the system dynamics with curious iLQR, a risk-seeking iterative LQR approach. During trajectory optimization the curious iLQR attempts to minimize both the task-dependent cost and the uncertainty in the dynamics model. We scale this approach to perform reaching tasks on 7-DoF manipulators, to perform both simulation and real robot reaching experiments. Our experiments consistently show that MBRL with curious iLQR more easily overcomes bad initial dynamics models and reaches desired joint configurations more reliably and with less system rollouts.
A Hierarchical Bayesian Linear Regression Model with Local Features for Stochastic Dynamics Approximation
Aug 01, 2018
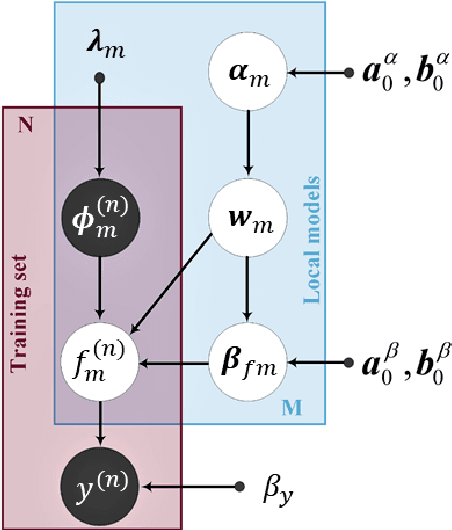
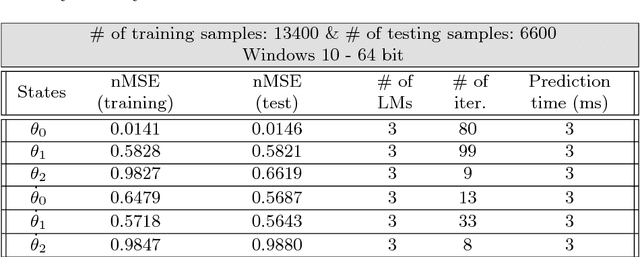
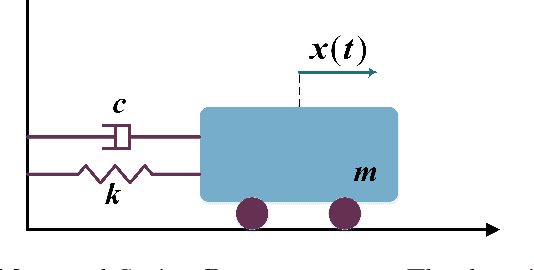
One of the challenges in model-based control of stochastic dynamical systems is that the state transition dynamics are involved, and it is not easy or efficient to make good-quality predictions of the states. Moreover, there are not many representational models for the majority of autonomous systems, as it is not easy to build a compact model that captures the entire dynamical subtleties and uncertainties. In this work, we present a hierarchical Bayesian linear regression model with local features to learn the dynamics of a micro-robotic system as well as two simpler examples, consisting of a stochastic mass-spring damper and a stochastic double inverted pendulum on a cart. The model is hierarchical since we assume non-stationary priors for the model parameters. These non-stationary priors make the model more flexible by imposing priors on the priors of the model. To solve the maximum likelihood (ML) problem for this hierarchical model, we use the variational expectation maximization (EM) algorithm, and enhance the procedure by introducing hidden target variables. The algorithm yields parsimonious model structures, and consistently provides fast and accurate predictions for all our examples involving large training and test sets. This demonstrates the effectiveness of the method in learning stochastic dynamics, which makes it suitable for future use in a paradigm, such as model-based reinforcement learning, to compute optimal control policies in real time.
Using Simulation to Improve Sample-Efficiency of Bayesian Optimization for Bipedal Robots
May 07, 2018
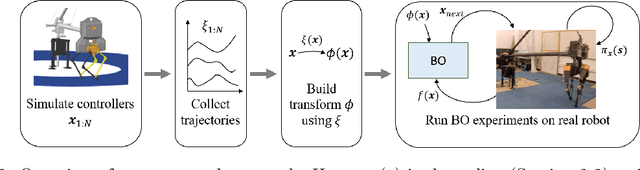
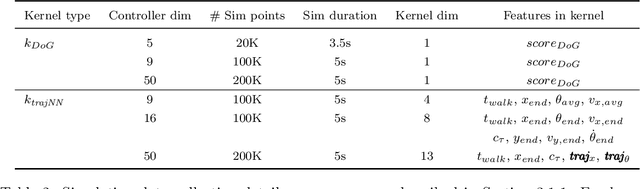

Learning for control can acquire controllers for novel robotic tasks, paving the path for autonomous agents. Such controllers can be expert-designed policies, which typically require tuning of parameters for each task scenario. In this context, Bayesian optimization (BO) has emerged as a promising approach for automatically tuning controllers. However, when performing BO on hardware for high-dimensional policies, sample-efficiency can be an issue. Here, we develop an approach that utilizes simulation to map the original parameter space into a domain-informed space. During BO, similarity between controllers is now calculated in this transformed space. Experiments on the ATRIAS robot hardware and another bipedal robot simulation show that our approach succeeds at sample-efficiently learning controllers for multiple robots. Another question arises: What if the simulation significantly differs from hardware? To answer this, we create increasingly approximate simulators and study the effect of increasing simulation-hardware mismatch on the performance of Bayesian optimization. We also compare our approach to other approaches from literature, and find it to be more reliable, especially in cases of high mismatch. Our experiments show that our approach succeeds across different controller types, bipedal robot models and simulator fidelity levels, making it applicable to a wide range of bipedal locomotion problems.
Online Learning of a Memory for Learning Rates
Mar 23, 2018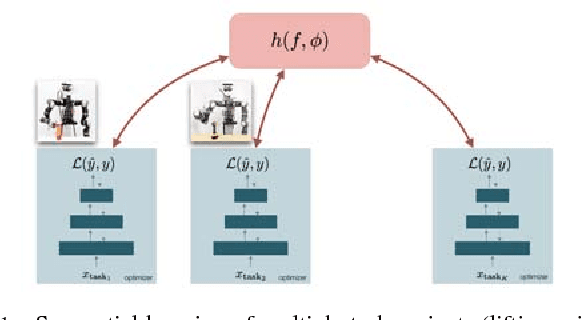
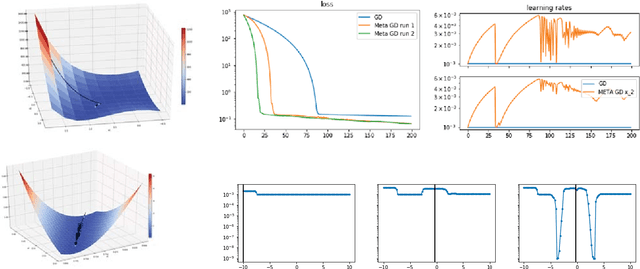

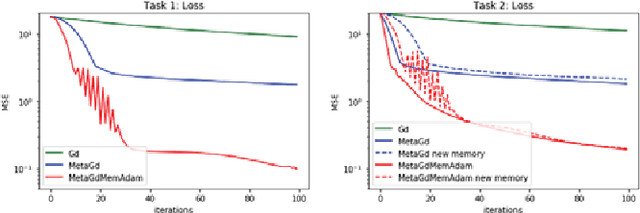
The promise of learning to learn for robotics rests on the hope that by extracting some information about the learning process itself we can speed up subsequent similar learning tasks. Here, we introduce a computationally efficient online meta-learning algorithm that builds and optimizes a memory model of the optimal learning rate landscape from previously observed gradient behaviors. While performing task specific optimization, this memory of learning rates predicts how to scale currently observed gradients. After applying the gradient scaling our meta-learner updates its internal memory based on the observed effect its prediction had. Our meta-learner can be combined with any gradient-based optimizer, learns on the fly and can be transferred to new optimization tasks. In our evaluations we show that our meta-learning algorithm speeds up learning of MNIST classification and a variety of learning control tasks, either in batch or online learning settings.
Learning Sensor Feedback Models from Demonstrations via Phase-Modulated Neural Networks
Mar 15, 2018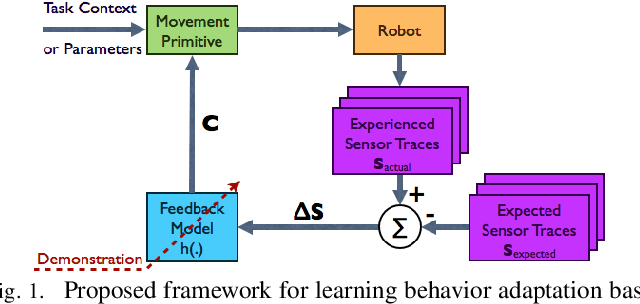
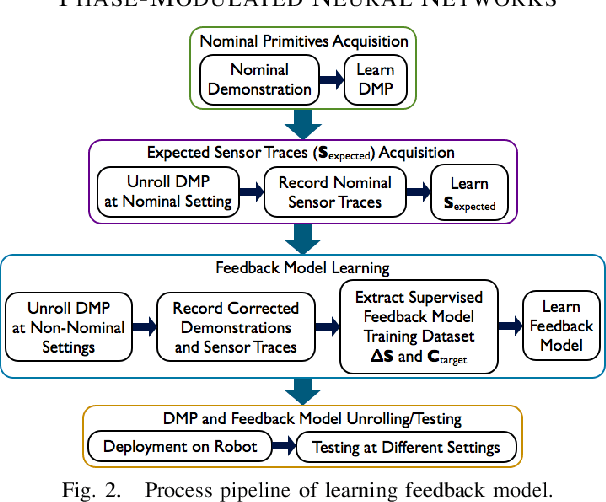
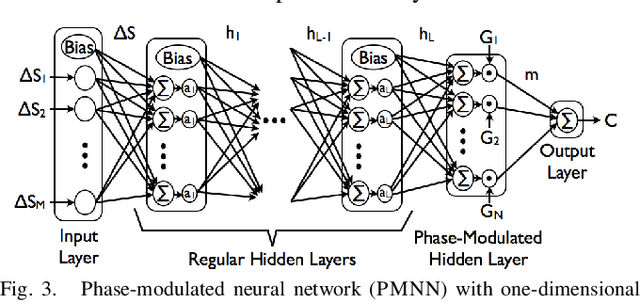
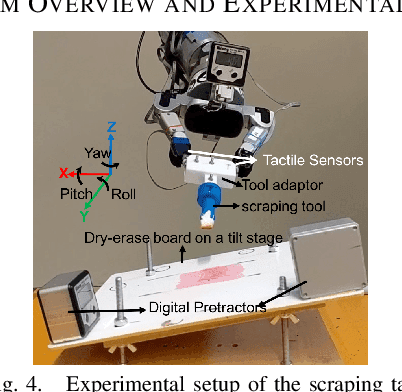
In order to robustly execute a task under environmental uncertainty, a robot needs to be able to reactively adapt to changes arising in its environment. The environment changes are usually reflected in deviation from expected sensory traces. These deviations in sensory traces can be used to drive the motion adaptation, and for this purpose, a feedback model is required. The feedback model maps the deviations in sensory traces to the motion plan adaptation. In this paper, we develop a general data-driven framework for learning a feedback model from demonstrations. We utilize a variant of a radial basis function network structure --with movement phases as kernel centers-- which can generally be applied to represent any feedback models for movement primitives. To demonstrate the effectiveness of our framework, we test it on the task of scraping on a tilt board. In this task, we are learning a reactive policy in the form of orientation adaptation, based on deviations of tactile sensor traces. As a proof of concept of our method, we provide evaluations on an anthropomorphic robot. A video demonstrating our approach and its results can be seen in https://youtu.be/7Dx5imy1Kcw
A New Data Source for Inverse Dynamics Learning
Oct 06, 2017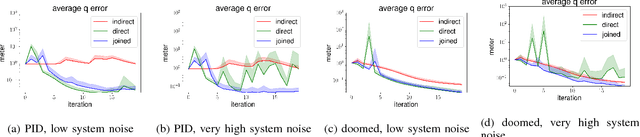
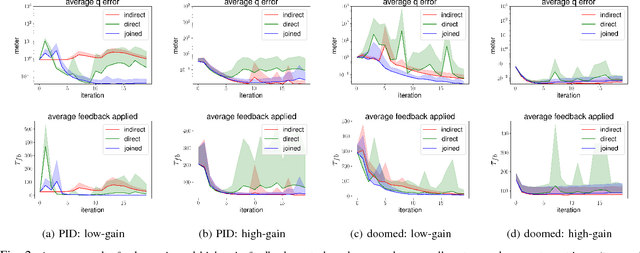

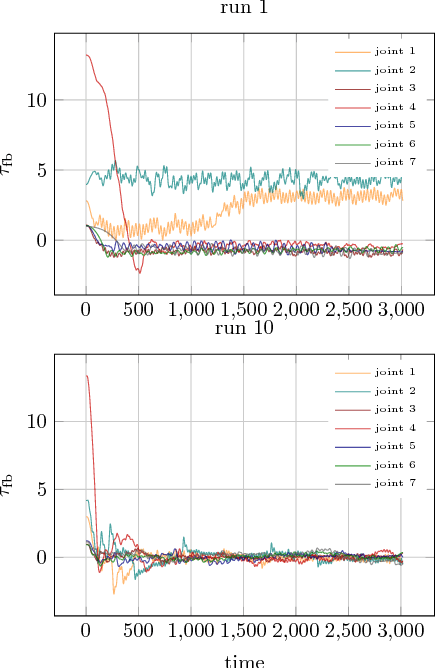
Modern robotics is gravitating toward increasingly collaborative human robot interaction. Tools such as acceleration policies can naturally support the realization of reactive, adaptive, and compliant robots. These tools require us to model the system dynamics accurately -- a difficult task. The fundamental problem remains that simulation and reality diverge--we do not know how to accurately change a robot's state. Thus, recent research on improving inverse dynamics models has been focused on making use of machine learning techniques. Traditional learning techniques train on the actual realized accelerations, instead of the policy's desired accelerations, which is an indirect data source. Here we show how an additional training signal -- measured at the desired accelerations -- can be derived from a feedback control signal. This effectively creates a second data source for learning inverse dynamics models. Furthermore, we show how both the traditional and this new data source, can be used to train task-specific models of the inverse dynamics, when used independently or combined. We analyze the use of both data sources in simulation and demonstrate its effectiveness on a real-world robotic platform. We show that our system incrementally improves the learned inverse dynamics model, and when using both data sources combined converges more consistently and faster.
Real-time Perception meets Reactive Motion Generation
Oct 06, 2017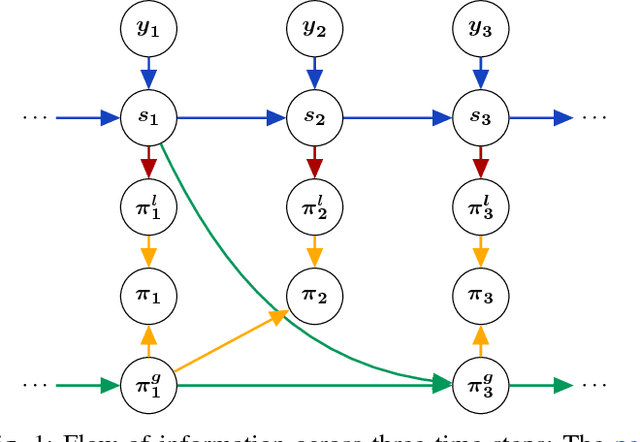



We address the challenging problem of robotic grasping and manipulation in the presence of uncertainty. This uncertainty is due to noisy sensing, inaccurate models and hard-to-predict environment dynamics. We quantify the importance of continuous, real-time perception and its tight integration with reactive motion generation methods in dynamic manipulation scenarios. We compare three different systems that are instantiations of the most common architectures in the field: (i) a traditional sense-plan-act approach that is still widely used, (ii) a myopic controller that only reacts to local environment dynamics and (iii) a reactive planner that integrates feedback control and motion optimization. All architectures rely on the same components for real-time perception and reactive motion generation to allow a quantitative evaluation. We extensively evaluate the systems on a real robotic platform in four scenarios that exhibit either a challenging workspace geometry or a dynamic environment. In 333 experiments, we quantify the robustness and accuracy that is due to integrating real-time feedback at different time scales in a reactive motion generation system. We also report on the lessons learned for system building.
SE3-Pose-Nets: Structured Deep Dynamics Models for Visuomotor Planning and Control
Oct 02, 2017
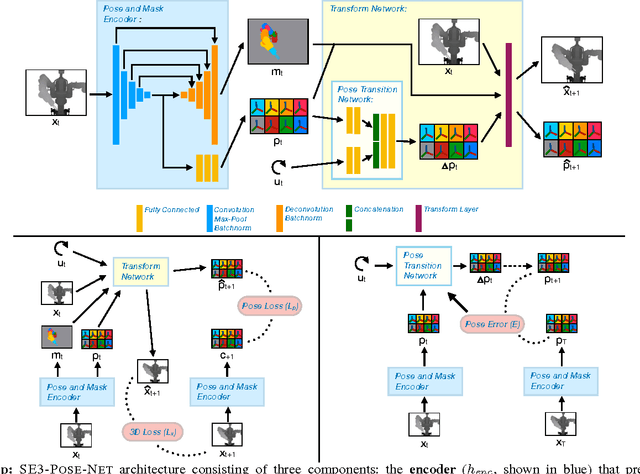
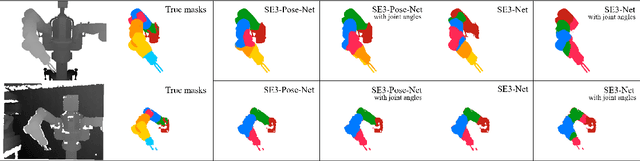
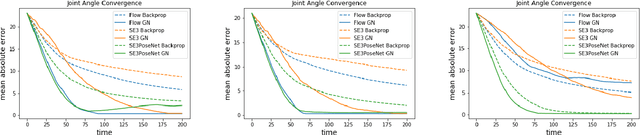
In this work, we present an approach to deep visuomotor control using structured deep dynamics models. Our deep dynamics model, a variant of SE3-Nets, learns a low-dimensional pose embedding for visuomotor control via an encoder-decoder structure. Unlike prior work, our dynamics model is structured: given an input scene, our network explicitly learns to segment salient parts and predict their pose-embedding along with their motion modeled as a change in the pose space due to the applied actions. We train our model using a pair of point clouds separated by an action and show that given supervision only in the form of point-wise data associations between the frames our network is able to learn a meaningful segmentation of the scene along with consistent poses. We further show that our model can be used for closed-loop control directly in the learned low-dimensional pose space, where the actions are computed by minimizing error in the pose space using gradient-based methods, similar to traditional model-based control. We present results on controlling a Baxter robot from raw depth data in simulation and in the real world and compare against two baseline deep networks. Our method runs in real-time, achieves good prediction of scene dynamics and outperforms the baseline methods on multiple control runs. Video results can be found at: https://rse-lab.cs.washington.edu/se3-structured-deep-ctrl/