 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Cable-Driven Robot for Non-Destructive Leafy Plant Monitoring and Mass Estimation using Structure from Motion
Sep 19, 2022
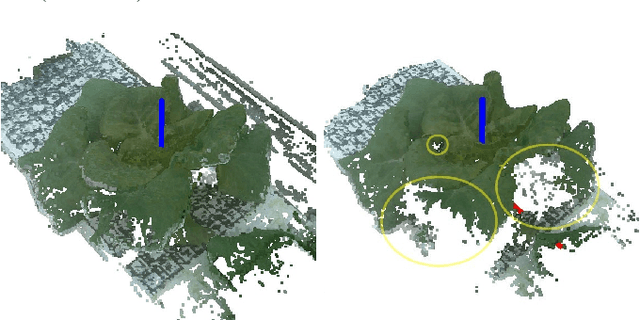


We propose a novel hybrid cable-based robot with manipulator and camera for high-accuracy, medium-throughput plant monitoring in a vertical hydroponic farm and, as an example application, demonstrate non-destructive plant mass estimation. Plant monitoring with high temporal and spatial resolution is important to both farmers and researchers to detect anomalies and develop predictive models for plant growth. The availability of high-quality, off-the-shelf structure-from-motion (SfM) and photogrammetry packages has enabled a vibrant community of roboticists to apply computer vision for non-destructive plant monitoring. While existing approaches tend to focus on either high-throughput (e.g. satellite, unmanned aerial vehicle (UAV), vehicle-mounted, conveyor-belt imagery) or high-accuracy/robustness to occlusions (e.g. turn-table scanner or robot arm), we propose a middle-ground that achieves high accuracy with a medium-throughput, highly automated robot. Our design pairs the workspace scalability of a cable-driven parallel robot (CDPR) with the dexterity of a 4 degree-of-freedom (DoF) robot arm to autonomously image many plants from a variety of viewpoints. We describe our robot design and demonstrate it experimentally by collecting daily photographs of 54 plants from 64 viewpoints each. We show that our approach can produce scientifically useful measurements, operate fully autonomously after initial calibration, and produce better reconstructions and plant property estimates than those of over-canopy methods (e.g. UAV). As example applications, we show that our system can successfully estimate plant mass with a Mean Absolute Error (MAE) of 0.586g and, when used to perform hypothesis testing on the relationship between mass and age, produces p-values comparable to ground-truth data (p=0.0020 and p=0.0016, respectively).
Proprioceptive State Estimation of Legged Robots with Kinematic Chain Modeling
Sep 12, 2022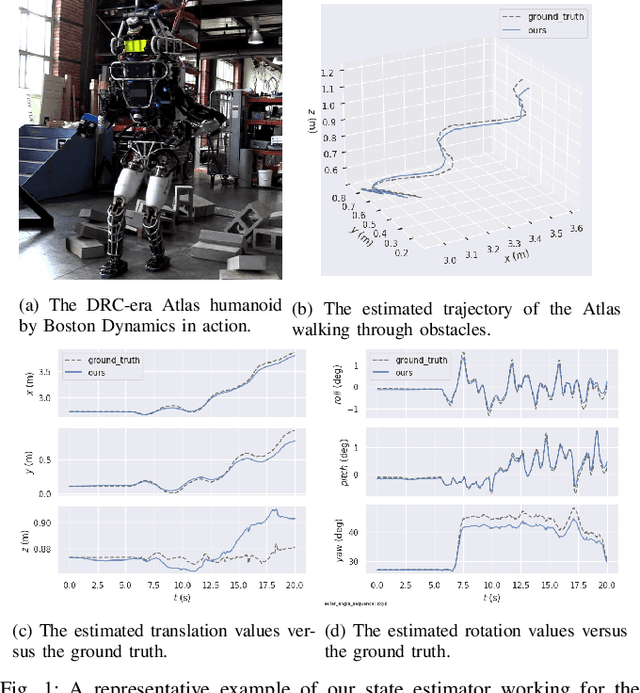
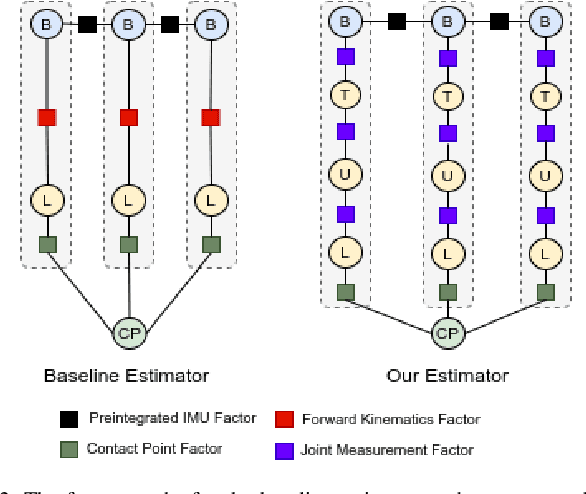
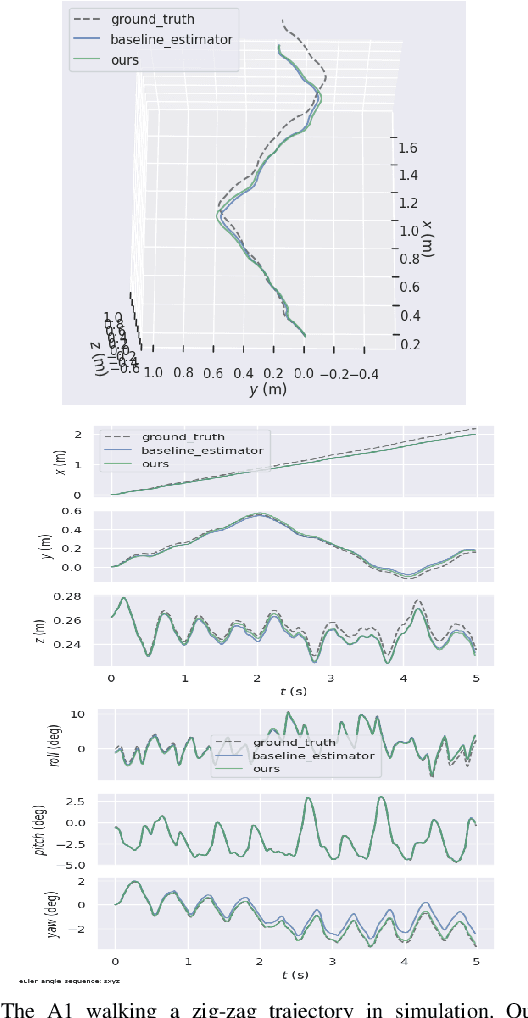
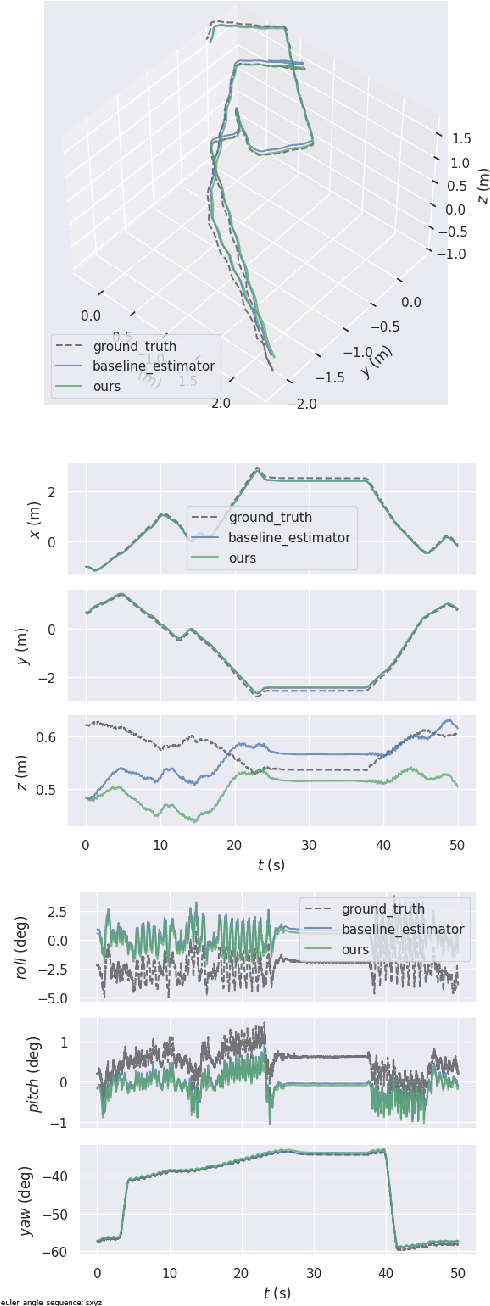
Legged robot locomotion is a challenging task due to a myriad of sub-problems, such as the hybrid dynamics of foot contact and the effects of the desired gait on the terrain. Accurate and efficient state estimation of the floating base and the feet joints can help alleviate much of these issues by providing feedback information to robot controllers. Current state estimation methods are highly reliant on a conjunction of visual and inertial measurements to provide real-time estimates, thus being handicapped in perceptually poor environments. In this work, we show that by leveraging the kinematic chain model of the robot via a factor graph formulation, we can perform state estimation of the base and the leg joints using primarily proprioceptive inertial data. We perform state estimation using a combination of preintegrated IMU measurements, forward kinematic computations, and contact detections in a factor-graph based framework, allowing our state estimate to be constrained by the robot model. Experimental results in simulation and on hardware show that our approach out-performs current proprioceptive state estimation methods by 27% on average, while being generalizable to a variety of legged robot platforms. We demonstrate our results both quantitatively and qualitatively on a wide variety of trajectories.
im2nerf: Image to Neural Radiance Field in the Wild
Sep 08, 2022
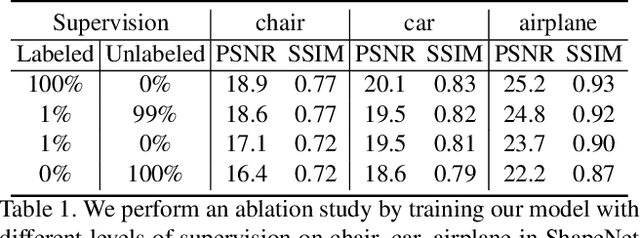
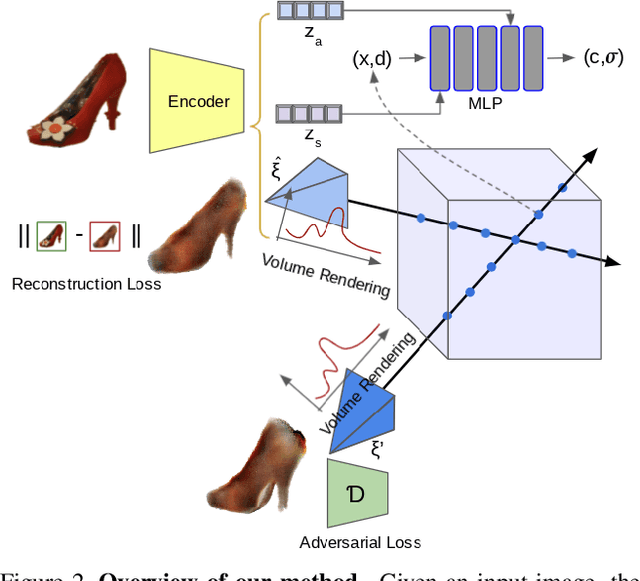
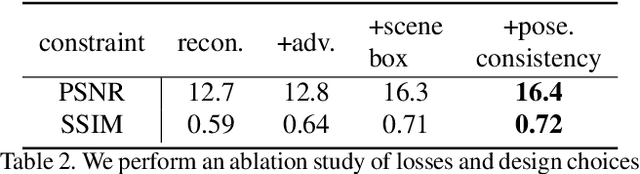
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly under-constrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.
Locally Optimal Estimation and Control of Cable Driven Parallel Robots using Time Varying Linear Quadratic Gaussian Control
Aug 01, 2022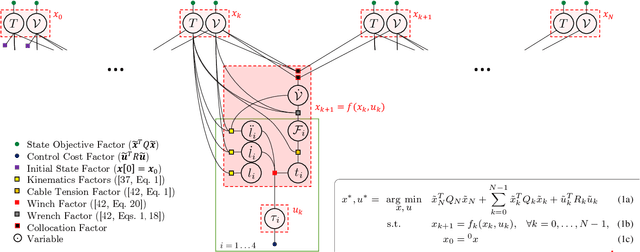
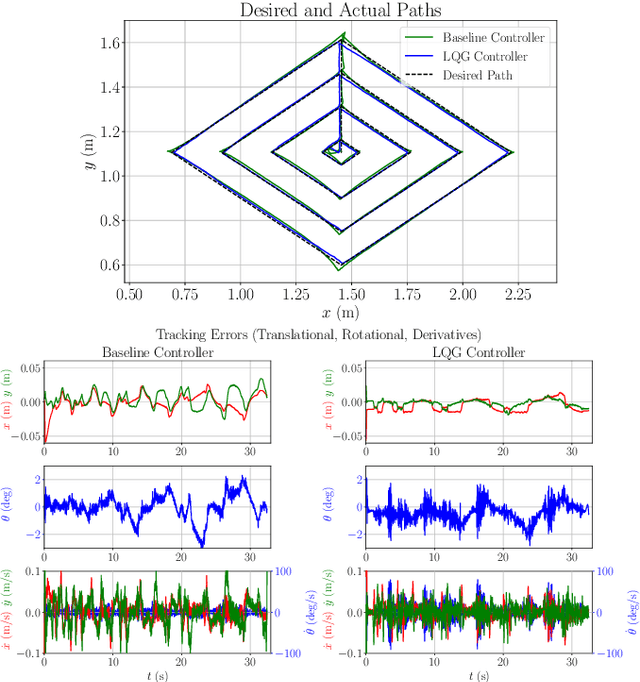
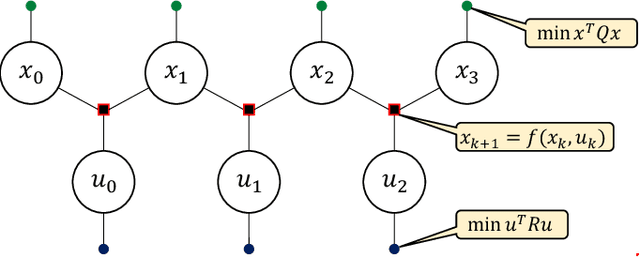
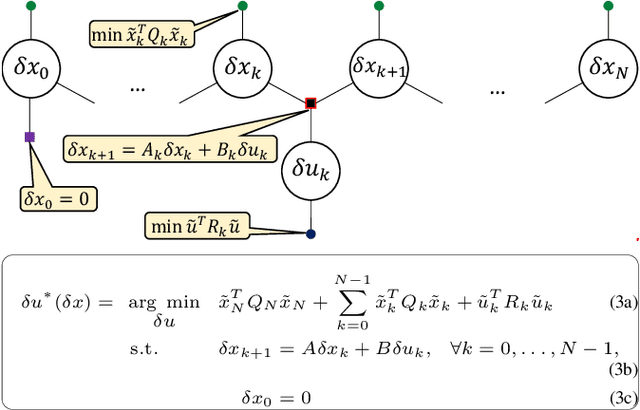
We present a locally optimal tracking controller for Cable Driven Parallel Robot (CDPR) control based on a time-varying Linear Quadratic Gaussian (TV-LQG) controller. In contrast to many methods which use fixed feedback gains, our time-varying controller computes the optimal gains depending on the location in the workspace and the future trajectory. Meanwhile, we rely heavily on offline computation to reduce the burden of online implementation and feasibility checking. Following the growing popularity of probabilistic graphical models for optimal control, we use factor graphs as a tool to formulate our controller for their efficiency, intuitiveness, and modularity. The topology of a factor graph encodes the relevant structural properties of equations in a way that facilitates insight and efficient computation using sparse linear algebra solvers. We first use factor graph optimization to compute a nominal trajectory, then linearize the graph and apply variable elimination to compute the locally optimal, time varying linear feedback gains. Next, we leverage the factor graph formulation to compute the locally optimal, time-varying Kalman Filter gains, and finally combine the locally optimal linear control and estimation laws to form a TV-LQG controller. We compare the tracking accuracy of our TV-LQG controller to a state-of-the-art dual-space feed-forward controller on a 2.9m x 2.3m, 4-cable planar robot and demonstrate improved tracking accuracies of 0.8{\deg} and 11.6mm root mean square error in rotation and translation respectively.
Panoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022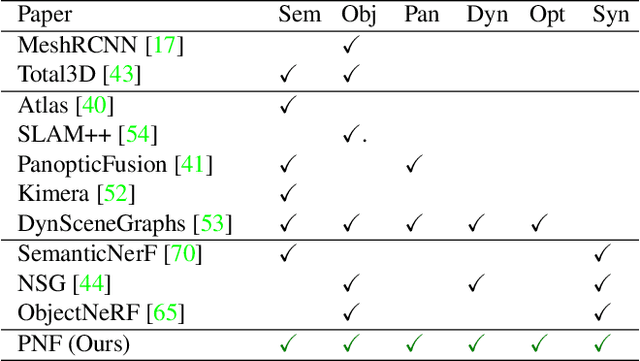
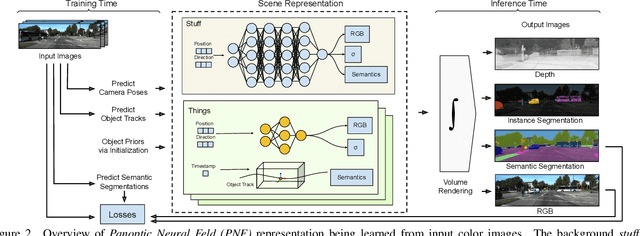
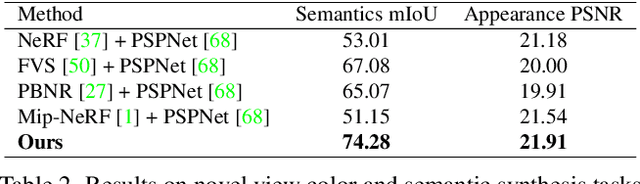
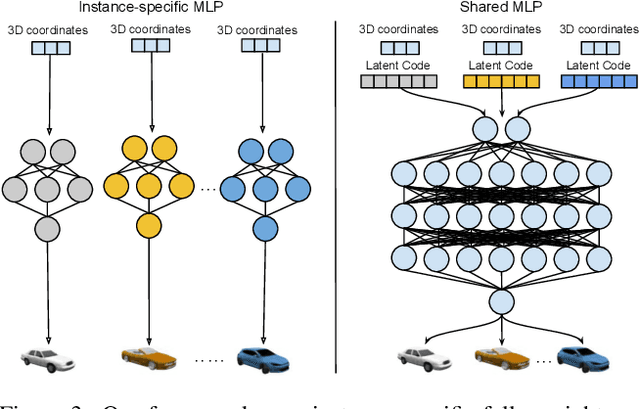
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
Simultaneous Control and Trajectory Estimation for Collision Avoidance of Autonomous Robotic Spacecraft Systems
Apr 28, 2022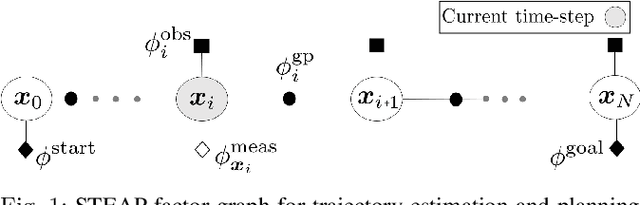
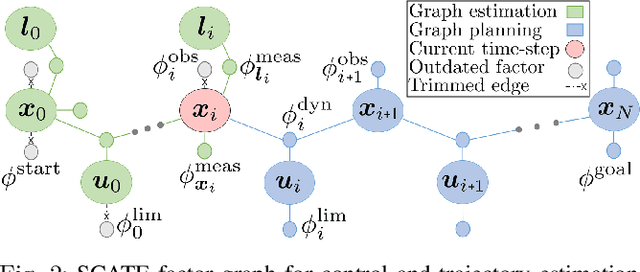
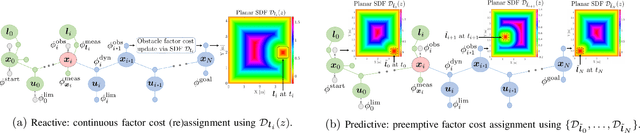

We propose factor graph optimization for simultaneous planning, control, and trajectory estimation for collision-free navigation of autonomous systems in environments with moving objects. The proposed online probabilistic motion planning and trajectory estimation navigation technique generates optimal collision-free state and control trajectories for autonomous vehicles when the obstacle motion model is both unknown and known. We evaluate the utility of the algorithm to support future autonomous robotic space missions.
Probabilistic Tracking with Deep Factors
Dec 02, 2021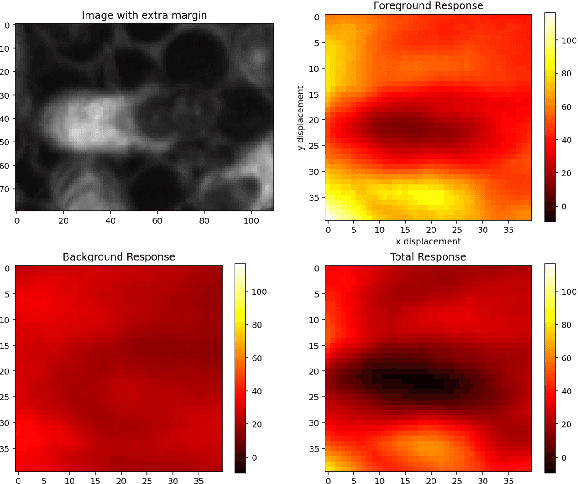

In many applications of computer vision it is important to accurately estimate the trajectory of an object over time by fusing data from a number of sources, of which 2D and 3D imagery is only one. In this paper, we show how to use a deep feature encoding in conjunction with generative densities over the features in a factor-graph based, probabilistic tracking framework. We present a likelihood model that combines a learned feature encoder with generative densities over them, both trained in a supervised manner. We also experiment with directly inferring probability through the use of image classification models that feed into the likelihood formulation. These models are used to implement deep factors that are added to the factor graph to complement other factors that represent domain-specific knowledge such as motion models and/or other prior information. Factors are then optimized together in a non-linear least-squares tracking framework that takes the form of an Extended Kalman Smoother with a Gaussian prior. A key feature of our likelihood model is that it leverages the Lie group properties of the tracked target's pose to apply the feature encoding on an image patch, extracted through a differentiable warp function inspired by spatial transformer networks. To illustrate the proposed approach we evaluate it on a challenging social insect behavior dataset, and show that using deep features does outperform these earlier linear appearance models used in this setting.
Learning Inertial Odometry for Dynamic Legged Robot State Estimation
Nov 01, 2021
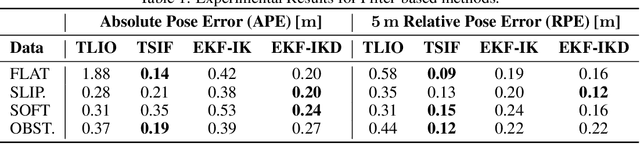
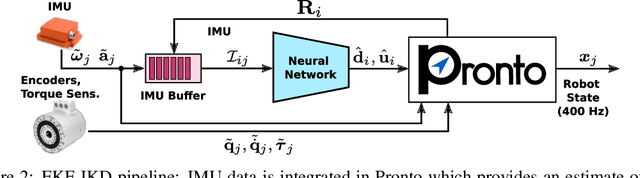
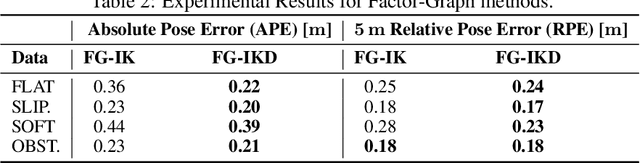
This paper introduces a novel proprioceptive state estimator for legged robots based on a learned displacement measurement from IMU data. Recent research in pedestrian tracking has shown that motion can be inferred from inertial data using convolutional neural networks. A learned inertial displacement measurement can improve state estimation in challenging scenarios where leg odometry is unreliable, such as slipping and compressible terrains. Our work learns to estimate a displacement measurement from IMU data which is then fused with traditional leg odometry. Our approach greatly reduces the drift of proprioceptive state estimation, which is critical for legged robots deployed in vision and lidar denied environments such as foggy sewers or dusty mines. We compared results from an EKF and an incremental fixed-lag factor graph estimator using data from several real robot experiments crossing challenging terrains. Our results show a reduction of relative pose error by 37% in challenging scenarios when compared to a traditional kinematic-inertial estimator without learned measurement. We also demonstrate a 22% reduction in error when used with vision systems in visually degraded environments such as an underground mine.
Extended Version of GTGraffiti: Spray Painting Graffiti Art from Human Painting Motions with a Cable Driven Parallel Robot
Sep 16, 2021
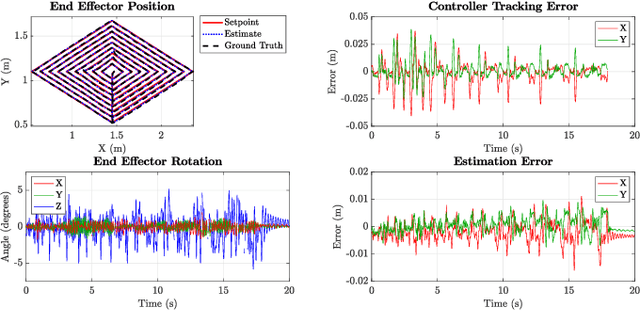


We present GTGraffiti, a graffiti painting system from Georgia Tech that tackles challenges in art, hardware, and human-robot collaboration. The problem of painting graffiti in a human style is particularly challenging and requires a system-level approach because the robotics and art must be designed around each other. The robot must be highly dynamic over a large workspace while the artist must work within the robot's limitations. Our approach consists of three stages: artwork capture, robot hardware, and planning & control. We use motion capture to capture collaborator painting motions which are then composed and processed into a time-varying linear feedback controller for a cable-driven parallel robot (CDPR) to execute. In this work, we will describe the capturing process, the design and construction of a purpose-built CDPR, and the software for turning an artist's vision into control commands. Our work represents an important step towards faithfully recreating human graffiti artwork by demonstrating that we can reproduce artist motions up to 2m/s and 20m/s$^2$ within 9.3mm RMSE to paint artworks. Added material not in the original work is colored in red.
CoDE: Collocation for Demonstration Encoding
May 07, 2021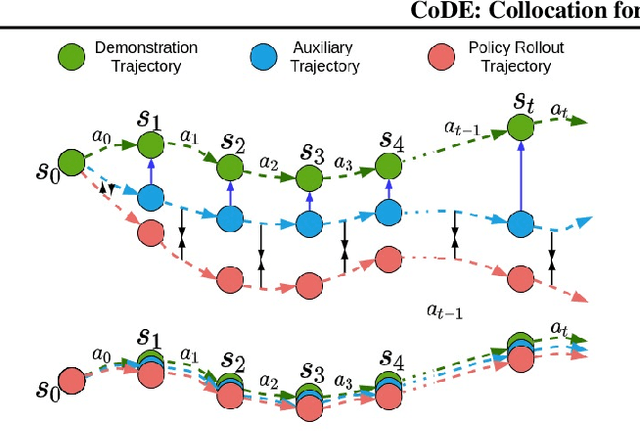
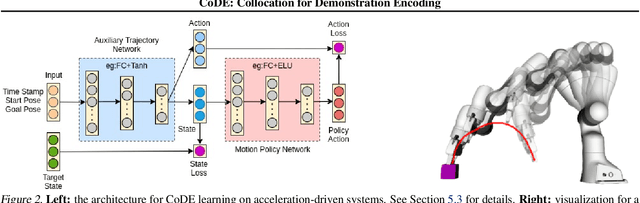
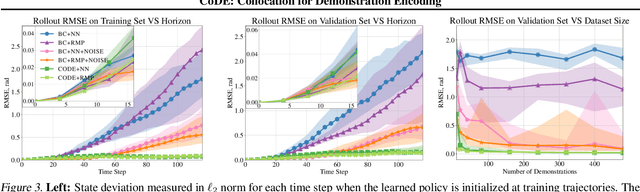
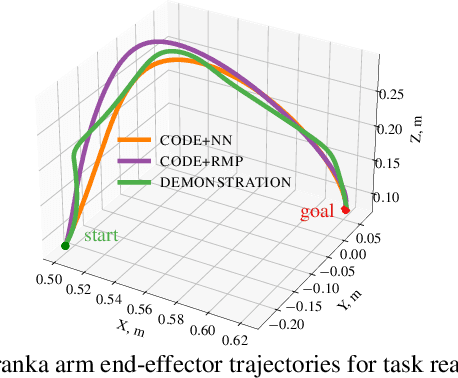
Roboticists frequently turn to Imitation learning (IL) for data efficient policy learning. Many IL methods, canonicalized by the seminal work on Dataset Aggregation (DAgger), combat distributional shift issues with older Behavior Cloning (BC) methods by introducing oracle experts. Unfortunately, access to oracle experts is often unrealistic in practice; data frequently comes from manual offline methods such as lead-through or teleoperation. We present a data-efficient imitation learning technique called Collocation for Demonstration Encoding (CoDE) that operates on only a fixed set of trajectory demonstrations by modeling learning as empirical risk minimization. We circumvent problematic back-propagation through time problems by introducing an auxiliary trajectory network taking inspiration from collocation techniques in optimal control. Our method generalizes well and is much more data efficient than standard BC methods. We present experiments on a 7-degree-of-freedom (DoF) robotic manipulator learning behavior shaping policies for efficient tabletop operation.