 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular Quasi-Dense 3D Object Tracking
Mar 12, 2021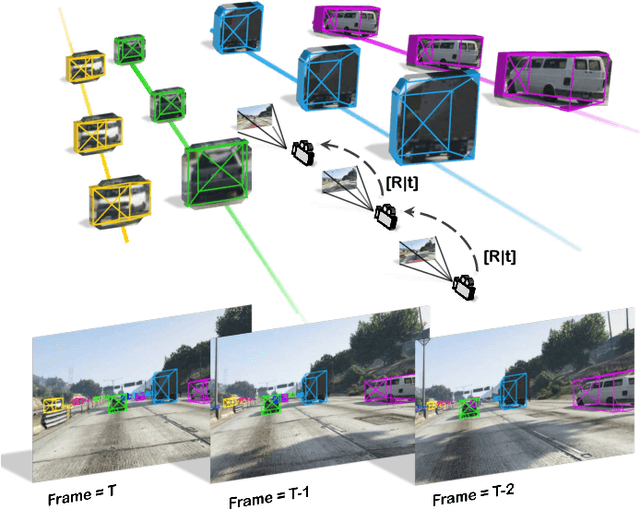
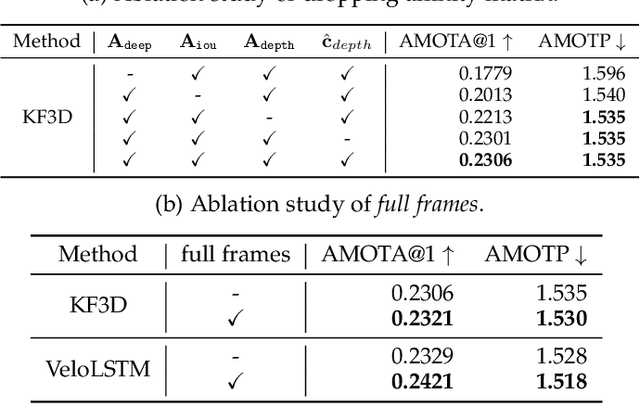
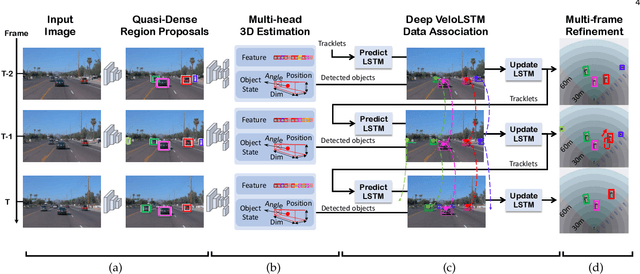
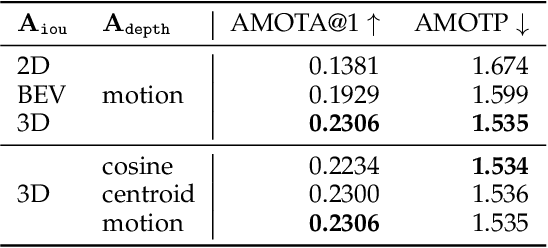
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.
Exploring Cross-Image Pixel Contrast for Semantic Segmentation
Feb 11, 2021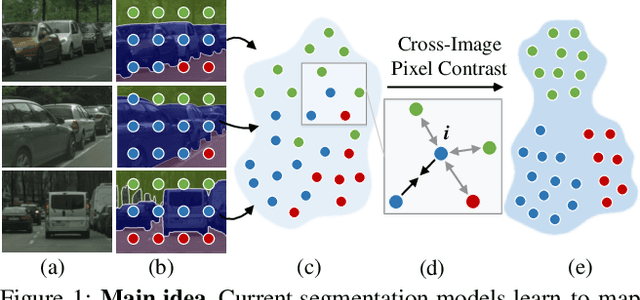
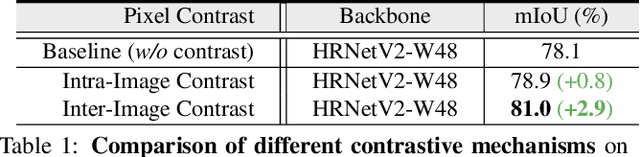
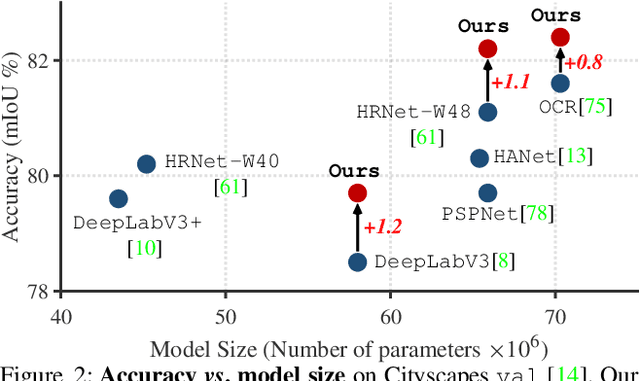

Current semantic segmentation methods focus only on mining "local" context, i.e., dependencies between pixels within individual images, by context-aggregation modules (e.g., dilated convolution, neural attention) or structure-aware optimization criteria (e.g., IoU-like loss). However, they ignore "global" context of the training data, i.e., rich semantic relations between pixels across different images. Inspired by the recent advance in unsupervised contrastive representation learning, we propose a pixel-wise contrastive framework for semantic segmentation in the fully supervised setting. The core idea is to enforce pixel embeddings belonging to a same semantic class to be more similar than embeddings from different classes. It raises a pixel-wise metric learning paradigm for semantic segmentation, by explicitly exploring the structures of labeled pixels, which were rarely explored before. Our method can be effortlessly incorporated into existing segmentation frameworks without extra overhead during testing. We experimentally show that, with famous segmentation models (i.e., DeepLabV3, HRNet, OCR) and backbones (i.e., ResNet, HR-Net), our method brings consistent performance improvements across diverse datasets (i.e., Cityscapes, PASCAL-Context, COCO-Stuff). We expect this work will encourage our community to rethink the current de facto training paradigm in fully supervised semantic segmentation.
Instance-Aware Predictive Navigation in Multi-Agent Environments
Jan 14, 2021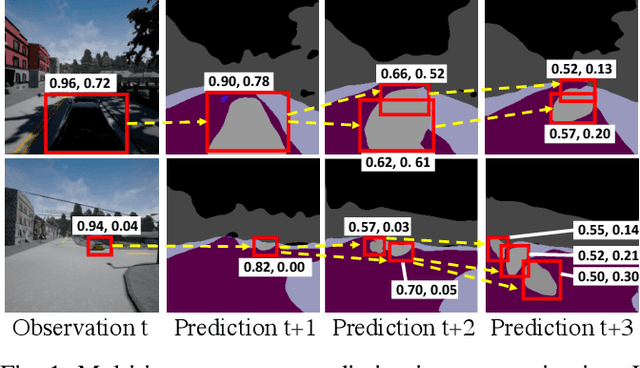
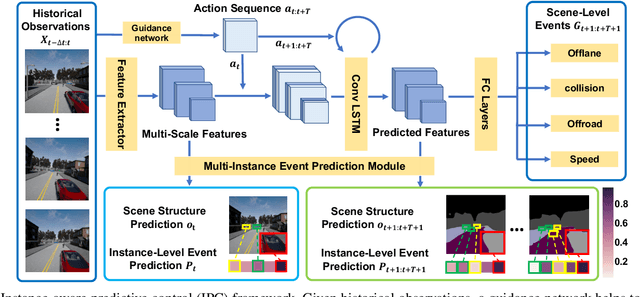

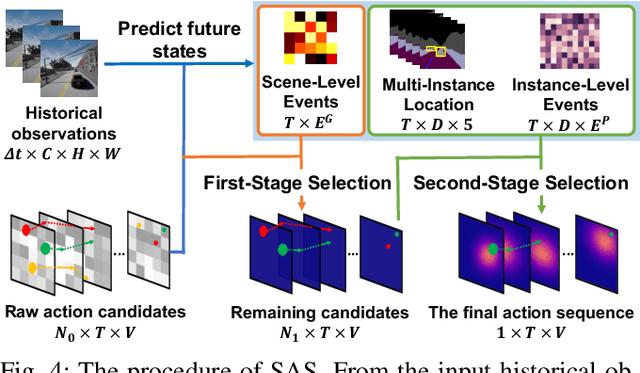
In this work, we aim to achieve efficient end-to-end learning of driving policies in dynamic multi-agent environments. Predicting and anticipating future events at the object level are critical for making informed driving decisions. We propose an Instance-Aware Predictive Control (IPC) approach, which forecasts interactions between agents as well as future scene structures. We adopt a novel multi-instance event prediction module to estimate the possible interaction among agents in the ego-centric view, conditioned on the selected action sequence of the ego-vehicle. To decide the action at each step, we seek the action sequence that can lead to safe future states based on the prediction module outputs by repeatedly sampling likely action sequences. We design a sequential action sampling strategy to better leverage predicted states on both scene-level and instance-level. Our method establishes a new state of the art in the challenging CARLA multi-agent driving simulation environments without expert demonstration, giving better explainability and sample efficiency.
Quasi-Dense Instance Similarity Learning
Jun 11, 2020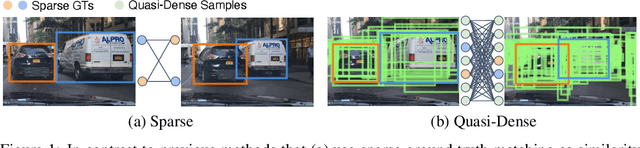

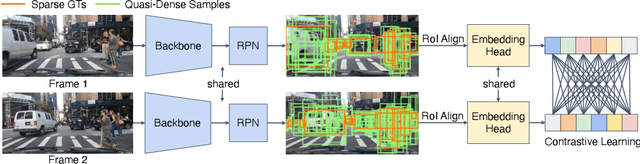
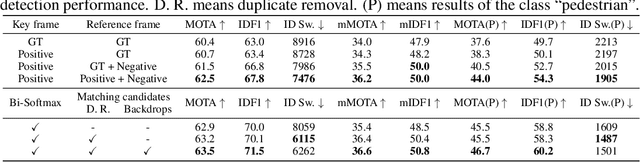
Similarity metrics for instances have drawn much attention, due to their importance for computer vision problems such as object tracking. However, existing methods regard object similarity learning as a post-hoc stage after object detection and only use sparse ground truth matching as the training objective. This process ignores the majority of the regions on the images. In this paper, we present a simple yet effective quasi-dense matching method to learn instance similarity from hundreds of region proposals in a pair of images. In the resulting feature space, a simple nearest neighbor search can distinguish different instances without bells and whistles. When applied to joint object detection and tracking, our method can outperform existing methods without using location or motion heuristics, yielding almost 10 points higher MOTA on BDD100K and Waymo tracking datasets. Our method is also competitive on one-shot object detection, which further shows the effectiveness of quasi-dense matching for category-level metric learning. The code will be available at https://github.com/sysmm/quasi-dense.
Frustratingly Simple Few-Shot Object Detection
Mar 16, 2020
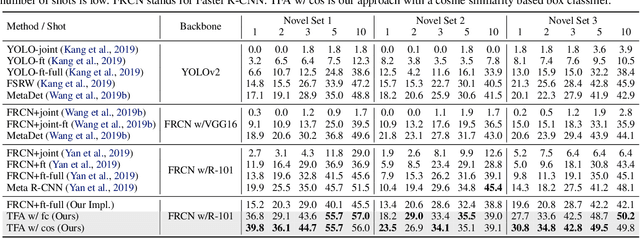
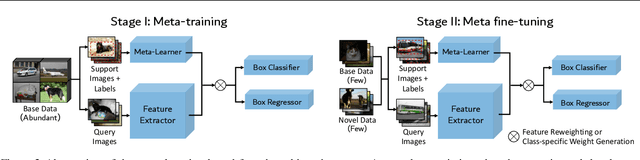
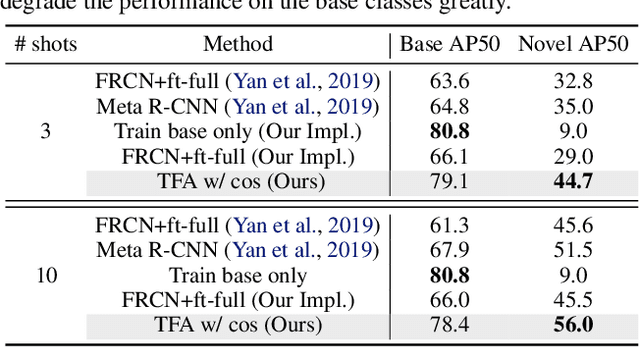
Detecting rare objects from a few examples is an emerging problem. Prior works show meta-learning is a promising approach. But, fine-tuning techniques have drawn scant attention. We find that fine-tuning only the last layer of existing detectors on rare classes is crucial to the few-shot object detection task. Such a simple approach outperforms the meta-learning methods by roughly 2~20 points on current benchmarks and sometimes even doubles the accuracy of the prior methods. However, the high variance in the few samples often leads to the unreliability of existing benchmarks. We revise the evaluation protocols by sampling multiple groups of training examples to obtain stable comparisons and build new benchmarks based on three datasets: PASCAL VOC, COCO and LVIS. Again, our fine-tuning approach establishes a new state of the art on the revised benchmarks. The code as well as the pretrained models are available at https://github.com/ucbdrive/few-shot-object-detection.
Task-Aware Deep Sampling for Feature Generation
Jun 11, 2019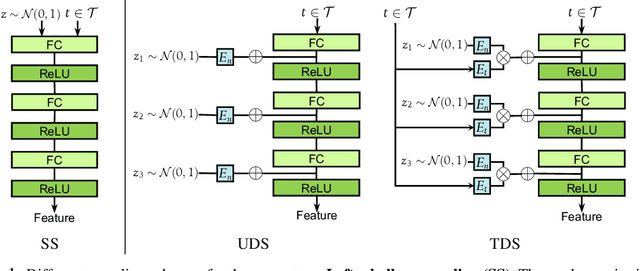
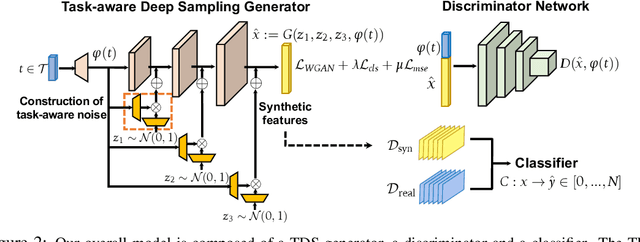
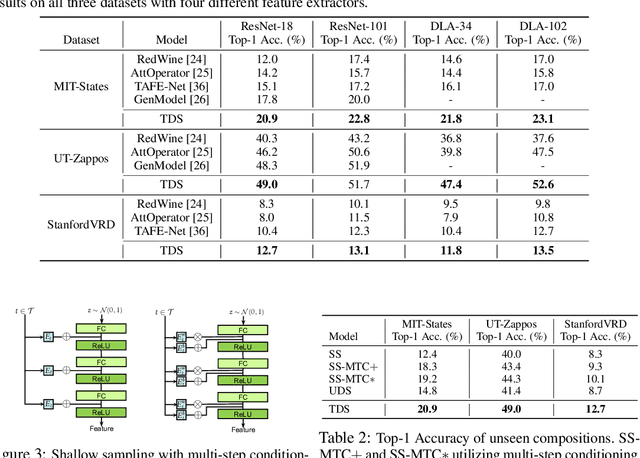

The human ability to imagine the variety of appearances of novel objects based on past experience is crucial for quickly learning novel visual concepts based on few examples. Endowing machines with a similar ability to generate feature distributions for new visual concepts is key to sample-efficient model generalization. In this work, we propose a novel generator architecture suitable for feature generation in the zero-shot setting. We introduce task-aware deep sampling (TDS) which injects task-aware noise layer-by-layer in the generator, in contrast to existing shallow sampling (SS) schemes where random noise is only sampled once at the input layer of the generator. We propose a sample efficient learning model composed of a TDS generator, a discriminator and a classifier (e.g., a soft-max classifier). We find that our model achieves state-of-the-art results on the compositional zero-shot learning benchmarks as well as improving upon the established benchmarks in conventional zero-shot learning with a faster convergence rate.
TAFE-Net: Task-Aware Feature Embeddings for Low Shot Learning
Apr 11, 2019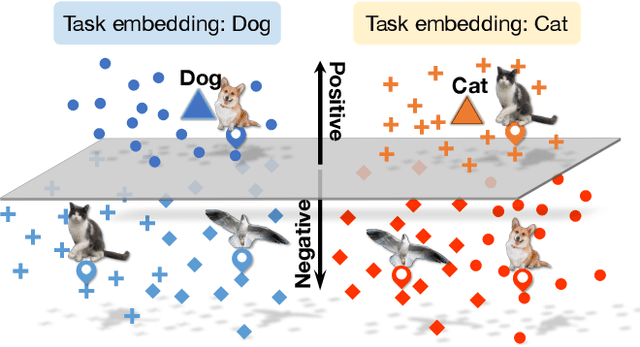
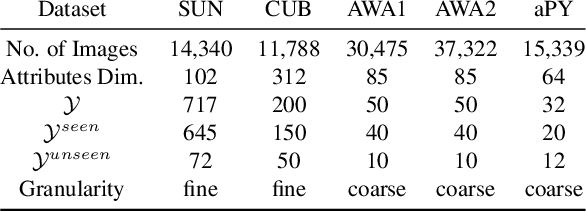
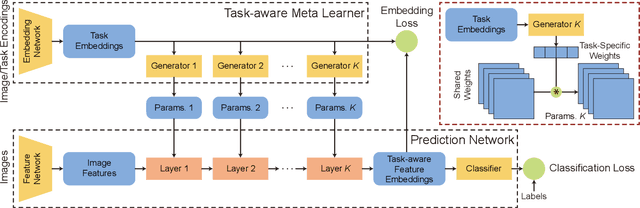
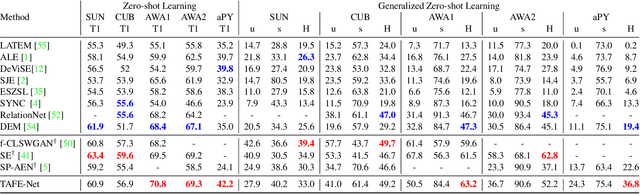
Learning good feature embeddings for images often requires substantial training data. As a consequence, in settings where training data is limited (e.g., few-shot and zero-shot learning), we are typically forced to use a generic feature embedding across various tasks. Ideally, we want to construct feature embeddings that are tuned for the given task. In this work, we propose Task-Aware Feature Embedding Networks (TAFE-Nets) to learn how to adapt the image representation to a new task in a meta learning fashion. Our network is composed of a meta learner and a prediction network. Based on a task input, the meta learner generates parameters for the feature layers in the prediction network so that the feature embedding can be accurately adjusted for that task. We show that TAFE-Net is highly effective in generalizing to new tasks or concepts and evaluate the TAFE-Net on a range of benchmarks in zero-shot and few-shot learning. Our model matches or exceeds the state-of-the-art on all tasks. In particular, our approach improves the prediction accuracy of unseen attribute-object pairs by 4 to 15 points on the challenging visual attribute-object composition task.
Deep Object-Centric Policies for Autonomous Driving
Mar 01, 2019
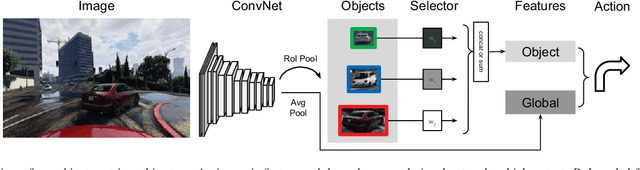

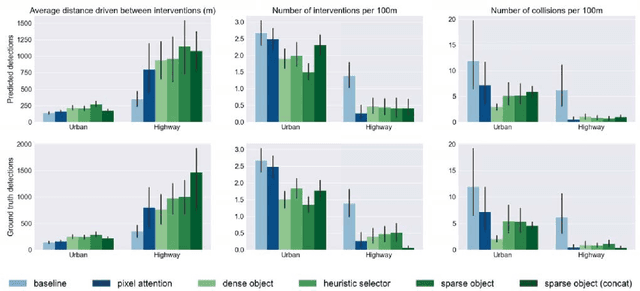
While learning visuomotor skills in an end-to-end manner is appealing, deep neural networks are often uninterpretable and fail in surprising ways. For robotics tasks, such as autonomous driving, models that explicitly represent objects may be more robust to new scenes and provide intuitive visualizations. We describe a taxonomy of "object-centric" models which leverage both object instances and end-to-end learning. In the Grand Theft Auto V simulator, we show that object-centric models outperform object-agnostic methods in scenes with other vehicles and pedestrians, even with an imperfect detector. We also demonstrate that our architectures perform well on real-world environments by evaluating on the Berkeley DeepDrive Video dataset, where an object-centric model outperforms object-agnostic models in the low-data regimes.
Hierarchical Discrete Distribution Decomposition for Match Density Estimation
Dec 29, 2018
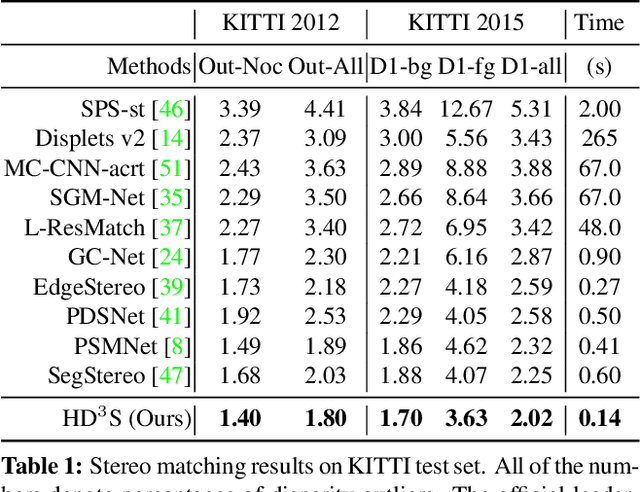
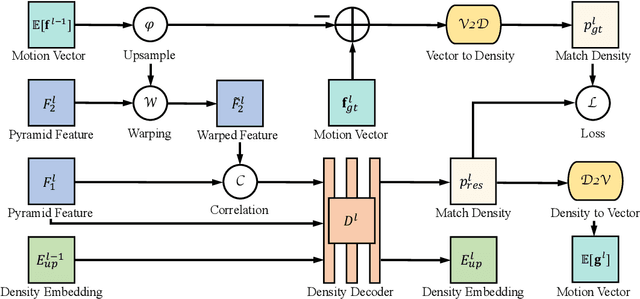
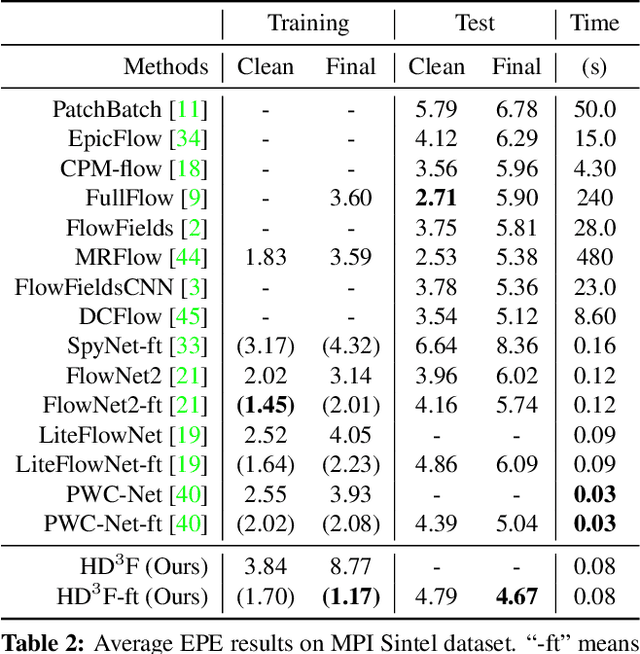
Existing deep learning methods for pixel correspondence output a point estimate of the motion field, but do not represent the full match distribution. Explicit representation of a match distribution is desirable for many applications as it allows direct representation of the correspondence probability. The main difficulty of estimating a full probability distribution with a deep network is the high computational cost of inferring the entire distribution. In this paper, we propose Hierarchical Discrete Distribution Decomposition, dubbed HD$^3$, to learn probabilistic point and region matching. Not only can it model match uncertainty, but also region propagation. To achieve this, we estimate the hierarchical distribution of pixel correspondences at different image scales without multi-hypotheses ensembling. Despite its simplicity, our method can achieve competitive results for both optical flow and stereo matching on established benchmarks, while the estimated uncertainty is a good indicator of errors. Furthermore, the point match distribution within a region can be grouped together to propagate the whole region even if the area changes across images.
Few-shot Object Detection via Feature Reweighting
Dec 05, 2018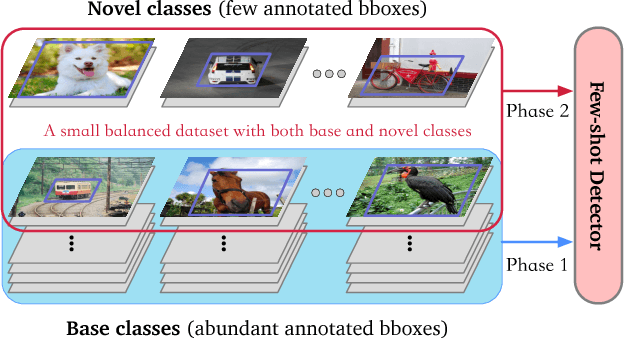
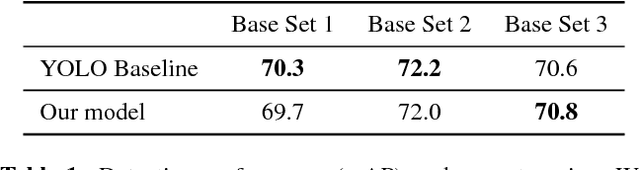
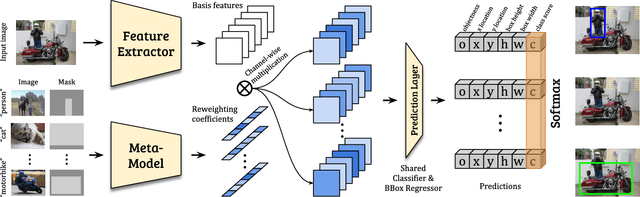
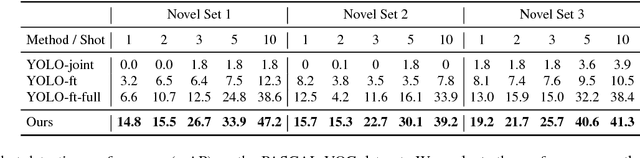
This work aims to solve the challenging few-shot object detection problem where only a few annotated examples are available for each object category to train a detection model. Such an ability of learning to detect an object from just a few examples is common for human vision systems, but remains absent for computer vision systems. Though few-shot meta learning offers a promising solution technique, previous works mostly target the task of image classification and are not directly applicable for the much more complicated object detection task. In this work, we propose a novel meta-learning based model with carefully designed architecture, which consists of a meta-model and a base detection model. The base detection model is trained on several base classes with sufficient samples to offer basis features. The meta-model is trained to reweight importance of features from the base detection model over the input image and adapt these features to assist novel object detection from a few examples. The meta-model is light-weight, end-to-end trainable and able to entail the base model with detection ability for novel objects fast. Through experiments we demonstrated our model can outperform baselines by a large margin for few-shot object detection, on multiple datasets and settings. Our model also exhibits fast adaptation speed to novel few-shot classes.