 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Scene Change Detection Using Visual Foundation Models and Cross-Attention Mechanisms
Sep 25, 2024



We present a novel method for scene change detection that leverages the robust feature extraction capabilities of a visual foundational model, DINOv2, and integrates full-image cross-attention to address key challenges such as varying lighting, seasonal variations, and viewpoint differences. In order to effectively learn correspondences and mis-correspondences between an image pair for the change detection task, we propose to a) ``freeze'' the backbone in order to retain the generality of dense foundation features, and b) employ ``full-image'' cross-attention to better tackle the viewpoint variations between the image pair. We evaluate our approach on two benchmark datasets, VL-CMU-CD and PSCD, along with their viewpoint-varied versions. Our experiments demonstrate significant improvements in F1-score, particularly in scenarios involving geometric changes between image pairs. The results indicate our method's superior generalization capabilities over existing state-of-the-art approaches, showing robustness against photometric and geometric variations as well as better overall generalization when fine-tuned to adapt to new environments. Detailed ablation studies further validate the contributions of each component in our architecture. Source code will be made publicly available upon acceptance.
Temporal Attention for Cross-View Sequential Image Localization
Aug 28, 2024



This paper introduces a novel approach to enhancing cross-view localization, focusing on the fine-grained, sequential localization of street-view images within a single known satellite image patch, a significant departure from traditional one-to-one image retrieval methods. By expanding to sequential image fine-grained localization, our model, equipped with a novel Temporal Attention Module (TAM), leverages contextual information to significantly improve sequential image localization accuracy. Our method shows substantial reductions in both mean and median localization errors on the Cross-View Image Sequence (CVIS) dataset, outperforming current state-of-the-art single-image localization techniques. Additionally, by adapting the KITTI-CVL dataset into sequential image sets, we not only offer a more realistic dataset for future research but also demonstrate our model's robust generalization capabilities across varying times and areas, evidenced by a 75.3% reduction in mean distance error in cross-view sequential image localization.
Physically Embodied Gaussian Splatting: A Realtime Correctable World Model for Robotics
Jun 16, 2024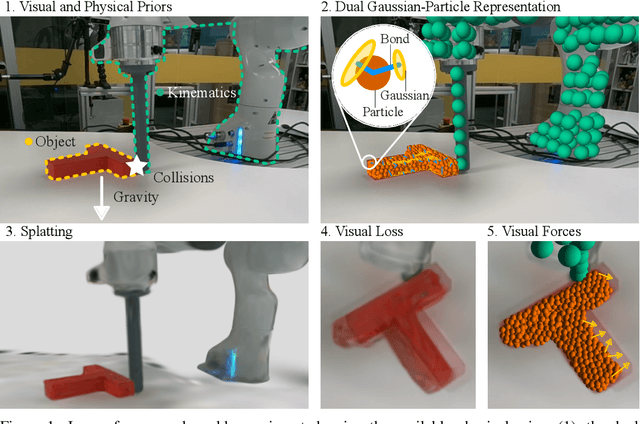
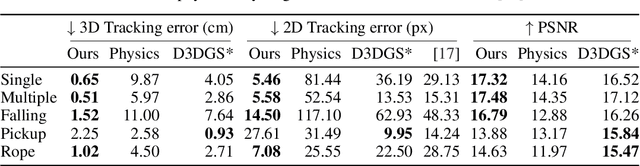


For robots to robustly understand and interact with the physical world, it is highly beneficial to have a comprehensive representation - modelling geometry, physics, and visual observations - that informs perception, planning, and control algorithms. We propose a novel dual Gaussian-Particle representation that models the physical world while (i) enabling predictive simulation of future states and (ii) allowing online correction from visual observations in a dynamic world. Our representation comprises particles that capture the geometrical aspect of objects in the world and can be used alongside a particle-based physics system to anticipate physically plausible future states. Attached to these particles are 3D Gaussians that render images from any viewpoint through a splatting process thus capturing the visual state. By comparing the predicted and observed images, our approach generates visual forces that correct the particle positions while respecting known physical constraints. By integrating predictive physical modelling with continuous visually-derived corrections, our unified representation reasons about the present and future while synchronizing with reality. Our system runs in realtime at 30Hz using only 3 cameras. We validate our approach on 2D and 3D tracking tasks as well as photometric reconstruction quality. Videos are found at https://embodied-gaussians.github.io/.
RoboHop: Segment-based Topological Map Representation for Open-World Visual Navigation
May 09, 2024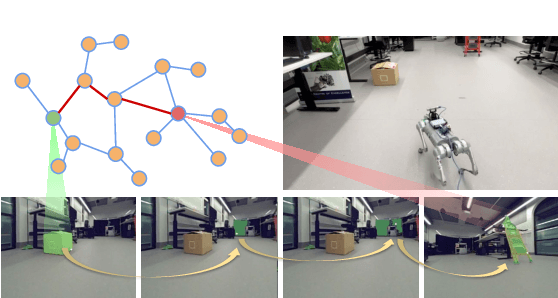
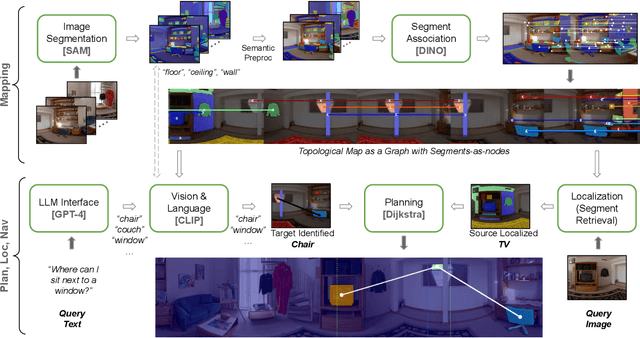
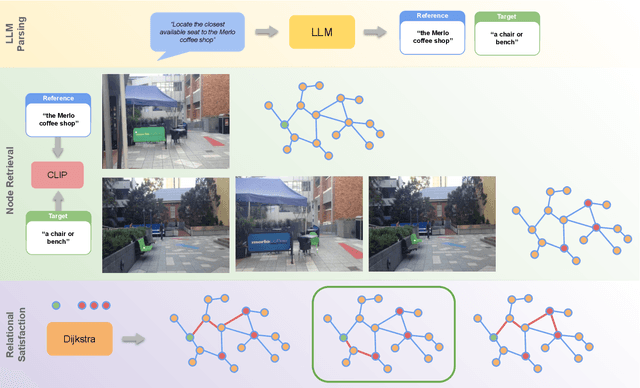

Mapping is crucial for spatial reasoning, planning and robot navigation. Existing approaches range from metric, which require precise geometry-based optimization, to purely topological, where image-as-node based graphs lack explicit object-level reasoning and interconnectivity. In this paper, we propose a novel topological representation of an environment based on "image segments", which are semantically meaningful and open-vocabulary queryable, conferring several advantages over previous works based on pixel-level features. Unlike 3D scene graphs, we create a purely topological graph with segments as nodes, where edges are formed by a) associating segment-level descriptors between pairs of consecutive images and b) connecting neighboring segments within an image using their pixel centroids. This unveils a "continuous sense of a place", defined by inter-image persistence of segments along with their intra-image neighbours. It further enables us to represent and update segment-level descriptors through neighborhood aggregation using graph convolution layers, which improves robot localization based on segment-level retrieval. Using real-world data, we show how our proposed map representation can be used to i) generate navigation plans in the form of "hops over segments" and ii) search for target objects using natural language queries describing spatial relations of objects. Furthermore, we quantitatively analyze data association at the segment level, which underpins inter-image connectivity during mapping and segment-level localization when revisiting the same place. Finally, we show preliminary trials on segment-level `hopping' based zero-shot real-world navigation. Project page with supplementary details: oravus.github.io/RoboHop/
Hybrid Navigation Acceptability and Safety
Apr 18, 2024



Autonomous vessels have emerged as a prominent and accepted solution, particularly in the naval defence sector. However, achieving full autonomy for marine vessels demands the development of robust and reliable control and guidance systems that can handle various encounters with manned and unmanned vessels while operating effectively under diverse weather and sea conditions. A significant challenge in this pursuit is ensuring the autonomous vessels' compliance with the International Regulations for Preventing Collisions at Sea (COLREGs). These regulations present a formidable hurdle for the human-level understanding by autonomous systems as they were originally designed from common navigation practices created since the mid-19th century. Their ambiguous language assumes experienced sailors' interpretation and execution, and therefore demands a high-level (cognitive) understanding of language and agent intentions. These capabilities surpass the current state-of-the-art in intelligent systems. This position paper highlights the critical requirements for a trustworthy control and guidance system, exploring the complexity of adapting COLREGs for safe vessel-on-vessel encounters considering autonomous maritime technology competing and/or cooperating with manned vessels.
PoIFusion: Multi-Modal 3D Object Detection via Fusion at Points of Interest
Mar 14, 2024



In this work, we present PoIFusion, a simple yet effective multi-modal 3D object detection framework to fuse the information of RGB images and LiDAR point clouds at the point of interest (abbreviated as PoI). Technically, our PoIFusion follows the paradigm of query-based object detection, formulating object queries as dynamic 3D boxes. The PoIs are adaptively generated from each query box on the fly, serving as the keypoints to represent a 3D object and play the role of basic units in multi-modal fusion. Specifically, we project PoIs into the view of each modality to sample the corresponding feature and integrate the multi-modal features at each PoI through a dynamic fusion block. Furthermore, the features of PoIs derived from the same query box are aggregated together to update the query feature. Our approach prevents information loss caused by view transformation and eliminates the computation-intensive global attention, making the multi-modal 3D object detector more applicable. We conducted extensive experiments on the nuScenes dataset to evaluate our approach. Remarkably, our PoIFusion achieves 74.9\% NDS and 73.4\% mAP, setting a state-of-the-art record on the multi-modal 3D object detection benchmark. Codes will be made available via \url{https://djiajunustc.github.io/projects/poifusion}.
Enhancing Embodied Object Detection through Language-Image Pre-training and Implicit Object Memory
Feb 06, 2024Deep-learning and large scale language-image training have produced image object detectors that generalise well to diverse environments and semantic classes. However, single-image object detectors trained on internet data are not optimally tailored for the embodied conditions inherent in robotics. Instead, robots must detect objects from complex multi-modal data streams involving depth, localisation and temporal correlation, a task termed embodied object detection. Paradigms such as Video Object Detection (VOD) and Semantic Mapping have been proposed to leverage such embodied data streams, but existing work fails to enhance performance using language-image training. In response, we investigate how an image object detector pre-trained using language-image data can be extended to perform embodied object detection. We propose a novel implicit object memory that uses projective geometry to aggregate the features of detected objects across long temporal horizons. The spatial and temporal information accumulated in memory is then used to enhance the image features of the base detector. When tested on embodied data streams sampled from diverse indoor scenes, our approach improves the base object detector by 3.09 mAP, outperforming alternative external memories designed for VOD and Semantic Mapping. Our method also shows a significant improvement of 16.90 mAP relative to baselines that perform embodied object detection without first training on language-image data, and is robust to sensor noise and domain shift experienced in real-world deployment.
Wasserstein Distance-based Expansion of Low-Density Latent Regions for Unknown Class Detection
Jan 19, 2024This paper addresses the significant challenge in open-set object detection (OSOD): the tendency of state-of-the-art detectors to erroneously classify unknown objects as known categories with high confidence. We present a novel approach that effectively identifies unknown objects by distinguishing between high and low-density regions in latent space. Our method builds upon the Open-Det (OD) framework, introducing two new elements to the loss function. These elements enhance the known embedding space's clustering and expand the unknown space's low-density regions. The first addition is the Class Wasserstein Anchor (CWA), a new function that refines the classification boundaries. The second is a spectral normalisation step, improving the robustness of the model. Together, these augmentations to the existing Contrastive Feature Learner (CFL) and Unknown Probability Learner (UPL) loss functions significantly improve OSOD performance. Our proposed OpenDet-CWA (OD-CWA) method demonstrates: a) a reduction in open-set errors by approximately 17%-22%, b) an enhancement in novelty detection capability by 1.5%-16%, and c) a decrease in the wilderness index by 2%-20% across various open-set scenarios. These results represent a substantial advancement in the field, showcasing the potential of our approach in managing the complexities of open-set object detection.
Segment Beyond View: Handling Partially Missing Modality for Audio-Visual Semantic Segmentation
Dec 14, 2023



Augmented Reality (AR) devices, emerging as prominent mobile interaction platforms, face challenges in user safety, particularly concerning oncoming vehicles. While some solutions leverage onboard camera arrays, these cameras often have limited field-of-view (FoV) with front or downward perspectives. Addressing this, we propose a new out-of-view semantic segmentation task and Segment Beyond View (SBV), a novel audio-visual semantic segmentation method. SBV supplements the visual modality, which miss the information beyond FoV, with the auditory information using a teacher-student distillation model (Omni2Ego). The model consists of a vision teacher utilising panoramic information, an auditory teacher with 8-channel audio, and an audio-visual student that takes views with limited FoV and binaural audio as input and produce semantic segmentation for objects outside FoV. SBV outperforms existing models in comparative evaluations and shows a consistent performance across varying FoV ranges and in monaural audio settings.
Improving Online Source-free Domain Adaptation for Object Detection by Unsupervised Data Acquisition
Oct 30, 2023Effective object detection in mobile robots is challenged by deployment in diverse and unfamiliar environments. Online Source-Free Domain Adaptation (O-SFDA) offers real-time model adaptation using a stream of unlabeled data from a target domain. However, not all captured frames in mobile robotics contain information that is beneficial for adaptation, particularly when there is a strong domain shift. This paper introduces a novel approach to enhance O-SFDA for adaptive object detection in mobile robots via unsupervised data acquisition. Our methodology prioritizes the most informative unlabeled samples for inclusion in the online training process. Empirical evaluation on a real-world dataset reveals that our method outperforms existing state-of-the-art O-SFDA techniques, demonstrating the viability of unsupervised data acquisition for improving adaptive object detection in mobile robots.