 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRICE: Reactive Interaction Controller for Cluttered Canopy Environment
Jun 12, 2025Robotic navigation in dense, cluttered environments such as agricultural canopies presents significant challenges due to physical and visual occlusion caused by leaves and branches. Traditional vision-based or model-dependent approaches often fail in these settings, where physical interaction without damaging foliage and branches is necessary to reach a target. We present a novel reactive controller that enables safe navigation for a robotic arm in a contact-rich, cluttered, deformable environment using end-effector position and real-time tactile feedback. Our proposed framework's interaction strategy is based on a trade-off between minimizing disturbance by maneuvering around obstacles and pushing through them to move towards the target. We show that over 35 trials in 3 experimental plant setups with an occluded target, the proposed controller successfully reached the target in all trials without breaking any branch and outperformed the state-of-the-art model-free controller in robustness and adaptability. This work lays the foundation for safe, adaptive interaction in cluttered, contact-rich deformable environments, enabling future agricultural tasks such as pruning and harvesting in plant canopies.
Enhancing Embodied Object Detection through Language-Image Pre-training and Implicit Object Memory
Feb 06, 2024Deep-learning and large scale language-image training have produced image object detectors that generalise well to diverse environments and semantic classes. However, single-image object detectors trained on internet data are not optimally tailored for the embodied conditions inherent in robotics. Instead, robots must detect objects from complex multi-modal data streams involving depth, localisation and temporal correlation, a task termed embodied object detection. Paradigms such as Video Object Detection (VOD) and Semantic Mapping have been proposed to leverage such embodied data streams, but existing work fails to enhance performance using language-image training. In response, we investigate how an image object detector pre-trained using language-image data can be extended to perform embodied object detection. We propose a novel implicit object memory that uses projective geometry to aggregate the features of detected objects across long temporal horizons. The spatial and temporal information accumulated in memory is then used to enhance the image features of the base detector. When tested on embodied data streams sampled from diverse indoor scenes, our approach improves the base object detector by 3.09 mAP, outperforming alternative external memories designed for VOD and Semantic Mapping. Our method also shows a significant improvement of 16.90 mAP relative to baselines that perform embodied object detection without first training on language-image data, and is robust to sensor noise and domain shift experienced in real-world deployment.
Reactive Base Control for On-The-Move Mobile Manipulation in Dynamic Environments
Sep 17, 2023



We present a reactive base control method that enables high performance mobile manipulation on-the-move in environments with static and dynamic obstacles. Performing manipulation tasks while the mobile base remains in motion can significantly decrease the time required to perform multi-step tasks, as well as improve the gracefulness of the robot's motion. Existing approaches to manipulation on-the-move either ignore the obstacle avoidance problem or rely on the execution of planned trajectories, which is not suitable in environments with dynamic objects and obstacles. The presented controller addresses both of these deficiencies and demonstrates robust performance of pick-and-place tasks in dynamic environments. The performance is evaluated on several simulated and real-world tasks. On a real-world task with static obstacles, we outperform an existing method by 48\% in terms of total task time. Further, we present real-world examples of our robot performing manipulation tasks on-the-move while avoiding a second autonomous robot in the workspace. See https://benburgesslimerick.github.io/MotM-BaseControl for supplementary materials.
An Architecture for Reactive Mobile Manipulation On-The-Move
Dec 14, 2022



We present a generalised architecture for reactive mobile manipulation while a robot's base is in motion toward the next objective in a high-level task. By performing tasks on-the-move, overall cycle time is reduced compared to methods where the base pauses during manipulation. Reactive control of the manipulator enables grasping objects with unpredictable motion while improving robustness against perception errors, environmental disturbances, and inaccurate robot control compared to open-loop, trajectory-based planning approaches. We present an example implementation of the architecture and investigate the performance on a series of pick and place tasks with both static and dynamic objects and compare the performance to baseline methods. Our method demonstrated a real-world success rate of over 99%, failing in only a single trial from 120 attempts with a physical robot system. The architecture is further demonstrated on other mobile manipulator platforms in simulation. Our approach reduces task time by up to 48%, while also improving reliability, gracefulness, and predictability compared to existing architectures for mobile manipulation. See https://benburgesslimerick.github.io/ManipulationOnTheMove for supplementary materials.
Developing cooperative policies for multi-stage reinforcement learning tasks
May 11, 2022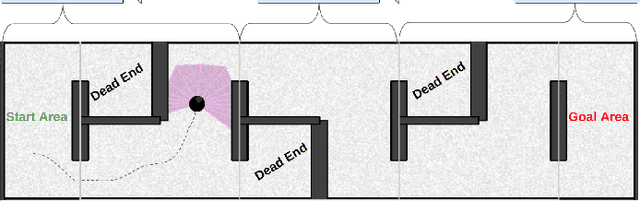
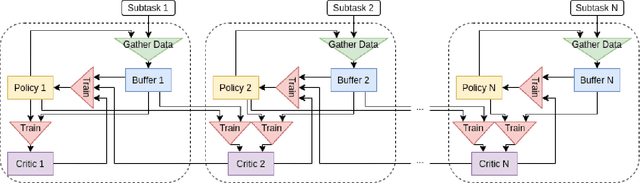
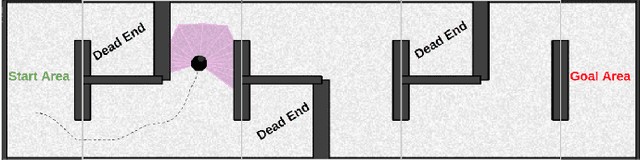
Many hierarchical reinforcement learning algorithms utilise a series of independent skills as a basis to solve tasks at a higher level of reasoning. These algorithms don't consider the value of using skills that are cooperative instead of independent. This paper proposes the Cooperative Consecutive Policies (CCP) method of enabling consecutive agents to cooperatively solve long time horizon multi-stage tasks. This method is achieved by modifying the policy of each agent to maximise both the current and next agent's critic. Cooperatively maximising critics allows each agent to take actions that are beneficial for its task as well as subsequent tasks. Using this method in a multi-room maze domain and a peg in hole manipulation domain, the cooperative policies were able to outperform a set of naive policies, a single agent trained across the entire domain, as well as another sequential HRL algorithm.
Eyes on the Prize: Improved Perception for Robust Dynamic Grasping
Apr 29, 2022

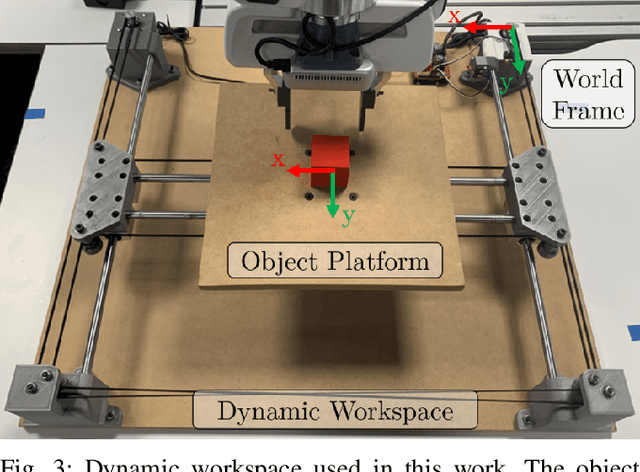
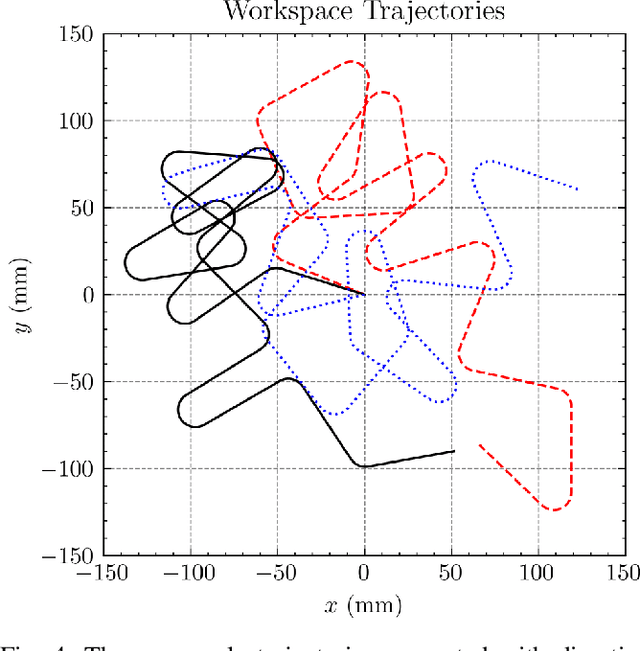
This paper is concerned with perception challenges for robust grasping in the presence of clutter and unpredictable relative motion between robot and object. Traditional perception systems developed for static grasping are unable to provide feedback during the final phase of a grasp due to sensor minimum range, occlusion, and a limited field of view. A multi-camera eye-in-hand perception system is presented that has advantages over commonly used camera configurations. We quantitatively evaluate the performance on a real robot with an image-based visual servoing grasp controller and show a significantly improved success rate on a dynamic grasping task. A fully reproducible open-source testing system is described to encourage benchmarking of dynamic grasping system performance.
Combining Local and Global Viewpoint Planning for Fruit Coverage
Aug 18, 2021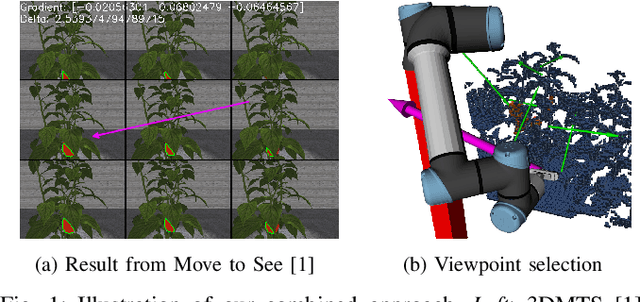
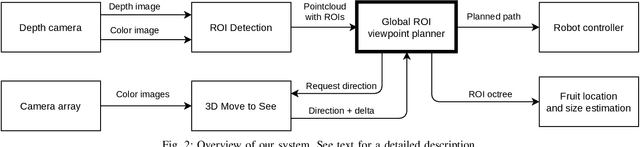
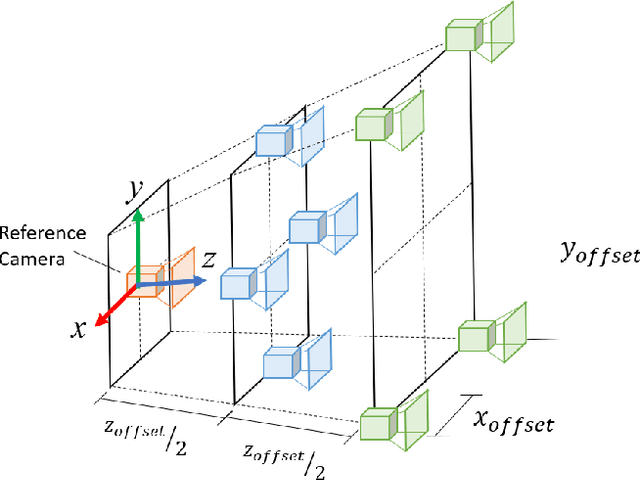

Obtaining 3D sensor data of complete plants or plant parts (e.g., the crop or fruit) is difficult due to their complex structure and a high degree of occlusion. However, especially for the estimation of the position and size of fruits, it is necessary to avoid occlusions as much as possible and acquire sensor information of the relevant parts. Global viewpoint planners exist that suggest a series of viewpoints to cover the regions of interest up to a certain degree, but they usually prioritize global coverage and do not emphasize the avoidance of local occlusions. On the other hand, there are approaches that aim at avoiding local occlusions, but they cannot be used in larger environments since they only reach a local maximum of coverage. In this paper, we therefore propose to combine a local, gradient-based method with global viewpoint planning to enable local occlusion avoidance while still being able to cover large areas. Our simulated experiments with a robotic arm equipped with a camera array as well as an RGB-D camera show that this combination leads to a significantly increased coverage of the regions of interest compared to just applying global coverage planning.
Developing cooperative policies for multi-stage tasks
Jul 01, 2020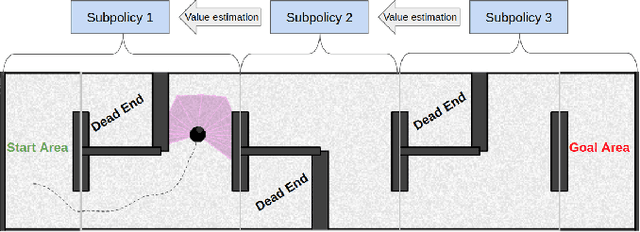
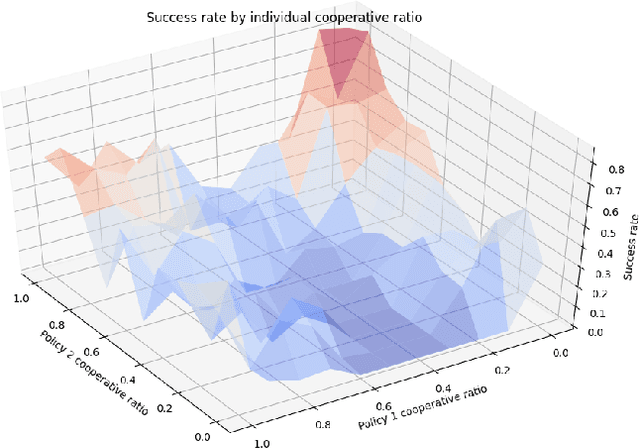
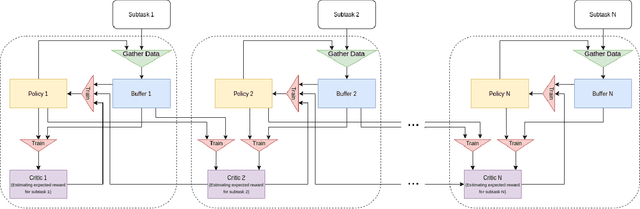
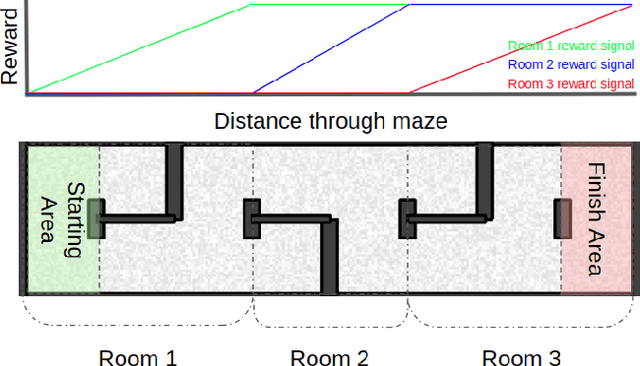
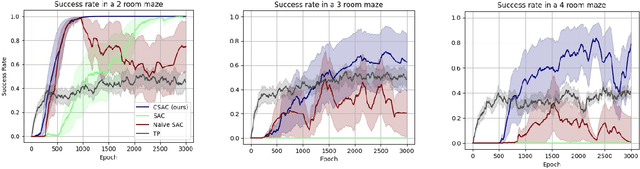
This paper proposes the Cooperative Soft Actor Critic (CSAC) method of enabling consecutive reinforcement learning agents to cooperatively solve a long time horizon multi-stage task. This method is achieved by modifying the policy of each agent to maximise both the current and next agent's critic. Cooperatively maximising each agent's critic allows each agent to take actions that are beneficial for its task as well as subsequent tasks. Using this method in a multi-room maze domain, the cooperative policies were able to outperform both uncooperative policies as well as a single agent trained across the entire domain. CSAC achieved a success rate of at least 20\% higher than the uncooperative policies, and converged on a solution at least 4 times faster than the single agent.
Towards Active Robotic Vision in Agriculture: A Deep Learning Approach to Visual Servoing in Occluded and Unstructured Protected Cropping Environments
Aug 05, 2019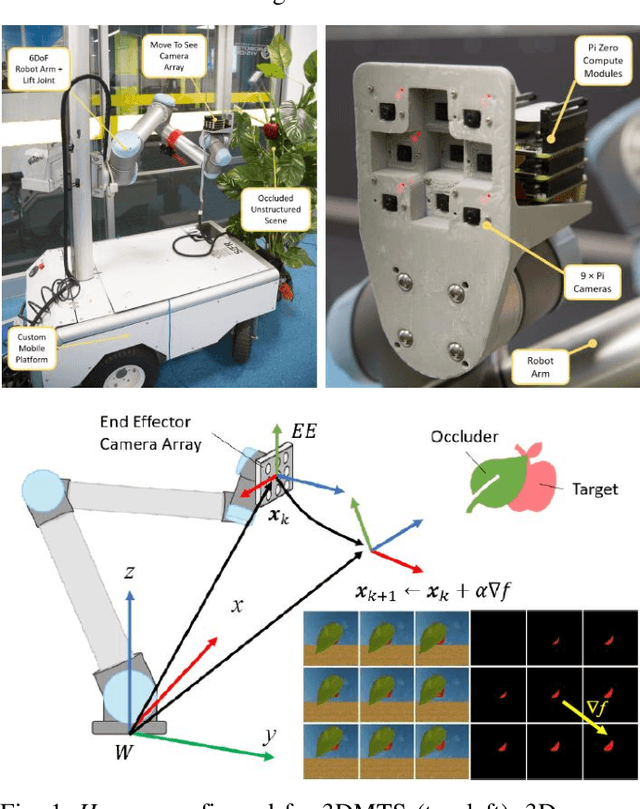
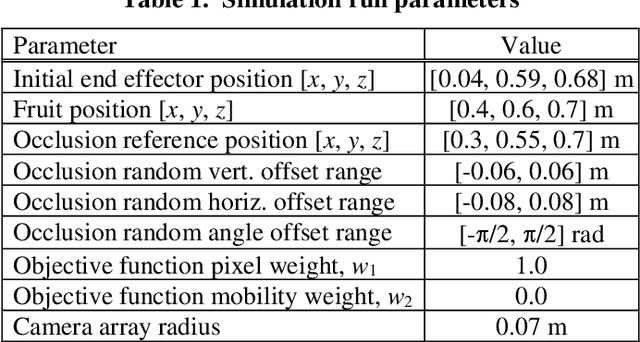
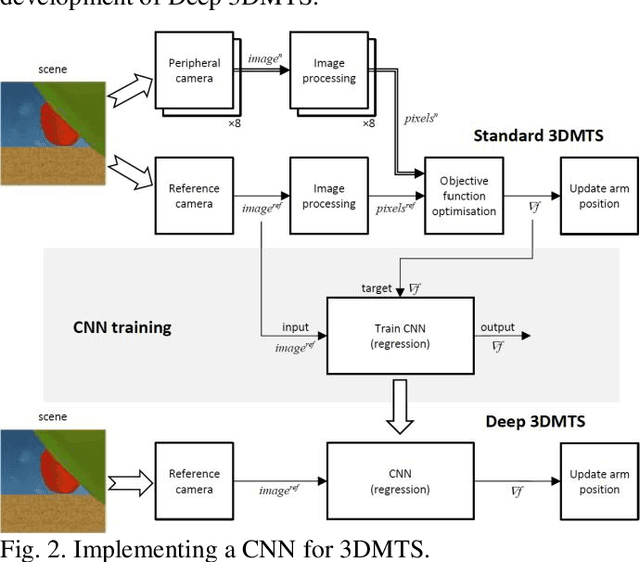
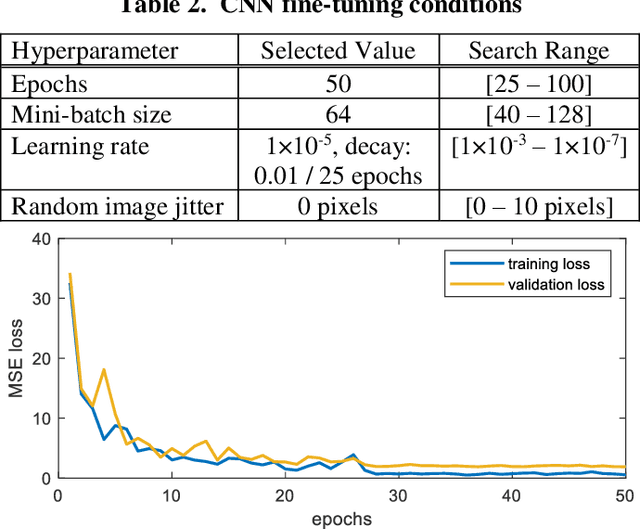
3D Move To See (3DMTS) is a mutli-perspective visual servoing method for unstructured and occluded environments, like that encountered in robotic crop harvesting. This paper presents a deep learning method, Deep-3DMTS for creating a single-perspective approach for 3DMTS through the use of a Convolutional Neural Network (CNN). The novel method is developed and validated via simulation against the standard 3DMTS approach. The Deep-3DMTS approach is shown to have performance equivalent to the standard 3DMTS baseline in guiding the end effector of a robotic arm to improve the view of occluded fruit (sweet peppers): end effector final position within 11.4 mm of the baseline; and an increase in fruit size in the image by a factor of 17.8 compared to the baseline of 16.8 (avg.).
A Sweet Pepper Harvesting Robot for Protected Cropping Environments
Oct 29, 2018
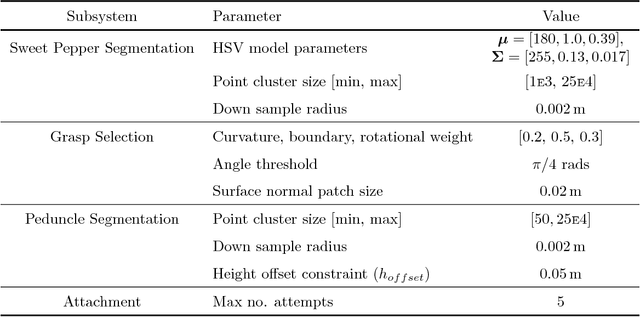
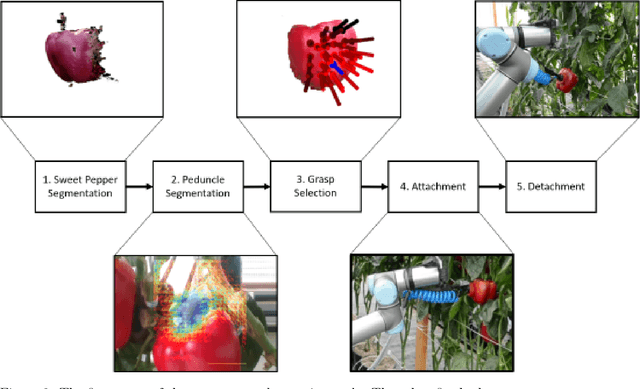
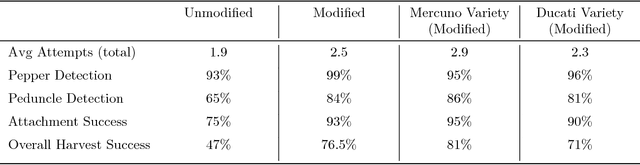
Using robots to harvest sweet peppers in protected cropping environments has remained unsolved despite considerable effort by the research community over several decades. In this paper, we present the robotic harvester, Harvey, designed for sweet peppers in protected cropping environments that achieved a 76.5% success rate (within a modified scenario) which improves upon our prior work which achieved 58% and related sweet pepper harvesting work which achieved 33\%. This improvement was primarily achieved through the introduction of a novel peduncle segmentation system using an efficient deep convolutional neural network, in conjunction with 3D post-filtering to detect the critical cutting location. We benchmark the peduncle segmentation against prior art demonstrating a considerable improvement in performance with an F_1 score of 0.564 compared to 0.302. The robotic harvester uses a perception pipeline to detect a target sweet pepper and an appropriate grasp and cutting pose used to determine the trajectory of a multi-modal harvesting tool to grasp the sweet pepper and cut it from the plant. A novel decoupling mechanism enables the gripping and cutting operations to be performed independently. We perform an in-depth analysis of the full robotic harvesting system to highlight bottlenecks and failure points that future work could address.