 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigates Like Me: Understanding How People Evaluate Human-Like AI in Video Games
Mar 02, 2023



We aim to understand how people assess human likeness in navigation produced by people and artificially intelligent (AI) agents in a video game. To this end, we propose a novel AI agent with the goal of generating more human-like behavior. We collect hundreds of crowd-sourced assessments comparing the human-likeness of navigation behavior generated by our agent and baseline AI agents with human-generated behavior. Our proposed agent passes a Turing Test, while the baseline agents do not. By passing a Turing Test, we mean that human judges could not quantitatively distinguish between videos of a person and an AI agent navigating. To understand what people believe constitutes human-like navigation, we extensively analyze the justifications of these assessments. This work provides insights into the characteristics that people consider human-like in the context of goal-directed video game navigation, which is a key step for further improving human interactions with AI agents.
Self-Supervised Interest Transfer Network via Prototypical Contrastive Learning for Recommendation
Feb 28, 2023Cross-domain recommendation has attracted increasing attention from industry and academia recently. However, most existing methods do not exploit the interest invariance between domains, which would yield sub-optimal solutions. In this paper, we propose a cross-domain recommendation method: Self-supervised Interest Transfer Network (SITN), which can effectively transfer invariant knowledge between domains via prototypical contrastive learning. Specifically, we perform two levels of cross-domain contrastive learning: 1) instance-to-instance contrastive learning, 2) instance-to-cluster contrastive learning. Not only that, we also take into account users' multi-granularity and multi-view interests. With this paradigm, SITN can explicitly learn the invariant knowledge of interest clusters between domains and accurately capture users' intents and preferences. We conducted extensive experiments on a public dataset and a large-scale industrial dataset collected from one of the world's leading e-commerce corporations. The experimental results indicate that SITN achieves significant improvements over state-of-the-art recommendation methods. Additionally, SITN has been deployed on a micro-video recommendation platform, and the online A/B testing results further demonstrate its practical value. Supplement is available at: https://github.com/fanqieCoffee/SITN-Supplement.
Safe Subgame Resolving for Extensive Form Correlated Equilibrium
Dec 29, 2022


Correlated Equilibrium is a solution concept that is more general than Nash Equilibrium (NE) and can lead to outcomes with better social welfare. However, its natural extension to the sequential setting, the \textit{Extensive Form Correlated Equilibrium} (EFCE), requires a quadratic amount of space to solve, even in restricted settings without randomness in nature. To alleviate these concerns, we apply \textit{subgame resolving}, a technique extremely successful in finding NE in zero-sum games to solving general-sum EFCEs. Subgame resolving refines a correlation plan in an \textit{online} manner: instead of solving for the full game upfront, it only solves for strategies in subgames that are reached in actual play, resulting in significant computational gains. In this paper, we (i) lay out the foundations to quantify the quality of a refined strategy, in terms of the \textit{social welfare} and \textit{exploitability} of correlation plans, (ii) show that EFCEs possess a sufficient amount of independence between subgames to perform resolving efficiently, and (iii) provide two algorithms for resolving, one using linear programming and the other based on regret minimization. Both methods guarantee \textit{safety}, i.e., they will never be counterproductive. Our methods are the first time an online method has been applied to the correlated, general-sum setting.
Function Approximation for Solving Stackelberg Equilibrium in Large Perfect Information Games
Dec 29, 2022Function approximation (FA) has been a critical component in solving large zero-sum games. Yet, little attention has been given towards FA in solving \textit{general-sum} extensive-form games, despite them being widely regarded as being computationally more challenging than their fully competitive or cooperative counterparts. A key challenge is that for many equilibria in general-sum games, no simple analogue to the state value function used in Markov Decision Processes and zero-sum games exists. In this paper, we propose learning the \textit{Enforceable Payoff Frontier} (EPF) -- a generalization of the state value function for general-sum games. We approximate the optimal \textit{Stackelberg extensive-form correlated equilibrium} by representing EPFs with neural networks and training them by using appropriate backup operations and loss functions. This is the first method that applies FA to the Stackelberg setting, allowing us to scale to much larger games while still enjoying performance guarantees based on FA error. Additionally, our proposed method guarantees incentive compatibility and is easy to evaluate without having to depend on self-play or approximate best-response oracles.
Neighborhood Adaptive Estimators for Causal Inference under Network Interference
Dec 07, 2022Estimating causal effects has become an integral part of most applied fields. Solving these modern causal questions requires tackling violations of many classical causal assumptions. In this work we consider the violation of the classical no-interference assumption, meaning that the treatment of one individuals might affect the outcomes of another. To make interference tractable, we consider a known network that describes how interference may travel. However, unlike previous work in this area, the radius (and intensity) of the interference experienced by a unit is unknown and can depend on different sub-networks of those treated and untreated that are connected to this unit. We study estimators for the average direct treatment effect on the treated in such a setting. The proposed estimator builds upon a Lepski-like procedure that searches over the possible relevant radii and treatment assignment patterns. In contrast to previous work, the proposed procedure aims to approximate the relevant network interference patterns. We establish oracle inequalities and corresponding adaptive rates for the estimation of the interference function. We leverage such estimates to propose and analyze two estimators for the average direct treatment effect on the treated. We address several challenges steaming from the data-driven creation of the patterns (i.e. feature engineering) and the network dependence. In addition to rates of convergence, under mild regularity conditions, we show that one of the proposed estimators is asymptotically normal and unbiased.
Explainable Action Advising for Multi-Agent Reinforcement Learning
Nov 15, 2022



Action advising is a knowledge transfer technique for reinforcement learning based on the teacher-student paradigm. An expert teacher provides advice to a student during training in order to improve the student's sample efficiency and policy performance. Such advice is commonly given in the form of state-action pairs. However, it makes it difficult for the student to reason with and apply to novel states. We introduce Explainable Action Advising, in which the teacher provides action advice as well as associated explanations indicating why the action was chosen. This allows the student to self-reflect on what it has learned, enabling advice generalization and leading to improved sample efficiency and learning performance - even in environments where the teacher is sub-optimal. We empirically show that our framework is effective in both single-agent and multi-agent scenarios, yielding improved policy returns and convergence rates when compared to state-of-the-art methods.
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Oct 18, 2022

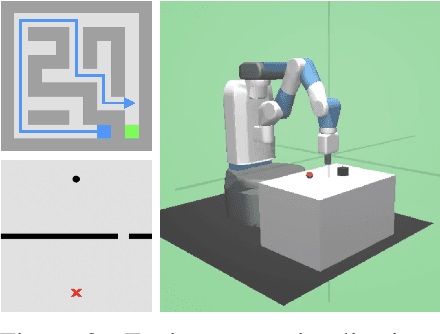
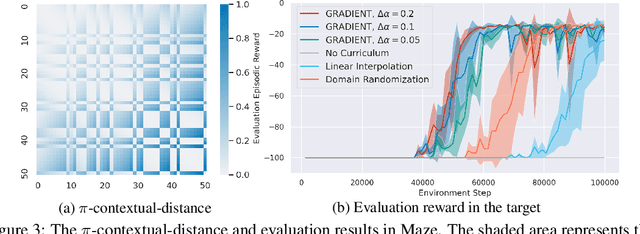
Curriculum Reinforcement Learning (CRL) aims to create a sequence of tasks, starting from easy ones and gradually learning towards difficult tasks. In this work, we focus on the idea of framing CRL as interpolations between a source (auxiliary) and a target task distribution. Although existing studies have shown the great potential of this idea, it remains unclear how to formally quantify and generate the movement between task distributions. Inspired by the insights from gradual domain adaptation in semi-supervised learning, we create a natural curriculum by breaking down the potentially large task distributional shift in CRL into smaller shifts. We propose GRADIENT, which formulates CRL as an optimal transport problem with a tailored distance metric between tasks. Specifically, we generate a sequence of task distributions as a geodesic interpolation (i.e., Wasserstein barycenter) between the source and target distributions. Different from many existing methods, our algorithm considers a task-dependent contextual distance metric and is capable of handling nonparametric distributions in both continuous and discrete context settings. In addition, we theoretically show that GRADIENT enables smooth transfer between subsequent stages in the curriculum under certain conditions. We conduct extensive experiments in locomotion and manipulation tasks and show that our proposed GRADIENT achieves higher performance than baselines in terms of learning efficiency and asymptotic performance.
Scenario-Adaptive and Self-Supervised Model for Multi-Scenario Personalized Recommendation
Aug 24, 2022
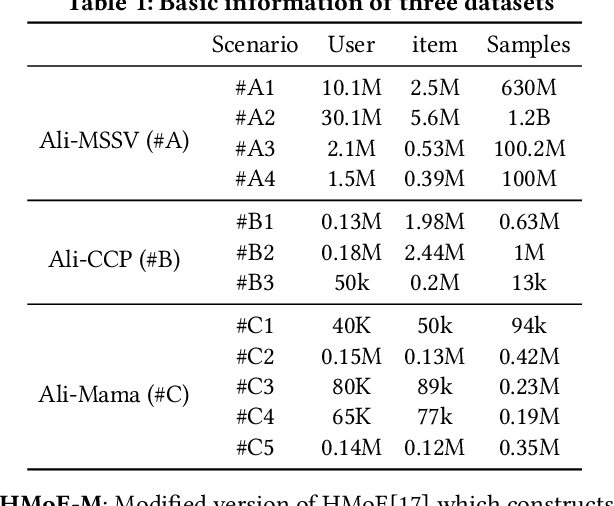

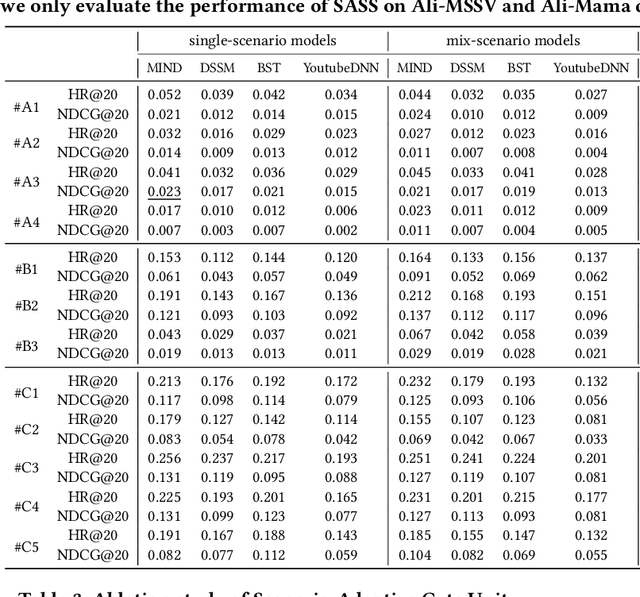
Multi-scenario recommendation is dedicated to retrieve relevant items for users in multiple scenarios, which is ubiquitous in industrial recommendation systems. These scenarios enjoy portions of overlaps in users and items, while the distribution of different scenarios is different. The key point of multi-scenario modeling is to efficiently maximize the use of whole-scenario information and granularly generate adaptive representations both for users and items among multiple scenarios. we summarize three practical challenges which are not well solved for multi-scenario modeling: (1) Lacking of fine-grained and decoupled information transfer controls among multiple scenarios. (2) Insufficient exploitation of entire space samples. (3) Item's multi-scenario representation disentanglement problem. In this paper, we propose a Scenario-Adaptive and Self-Supervised (SASS) model to solve the three challenges mentioned above. Specifically, we design a Multi-Layer Scenario Adaptive Transfer (ML-SAT) module with scenario-adaptive gate units to select and fuse effective transfer information from whole scenario to individual scenario in a quite fine-grained and decoupled way. To sufficiently exploit the power of entire space samples, a two-stage training process including pre-training and fine-tune is introduced. The pre-training stage is based on a scenario-supervised contrastive learning task with the training samples drawn from labeled and unlabeled data spaces. The model is created symmetrically both in user side and item side, so that we can get distinguishing representations of items in different scenarios. Extensive experimental results on public and industrial datasets demonstrate the superiority of the SASS model over state-of-the-art methods. This model also achieves more than 8.0% improvement on Average Watching Time Per User in online A/B tests.
Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao
Aug 11, 2022

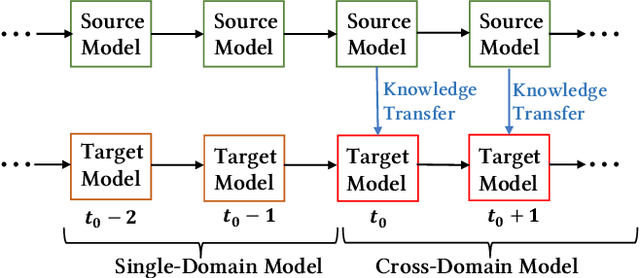
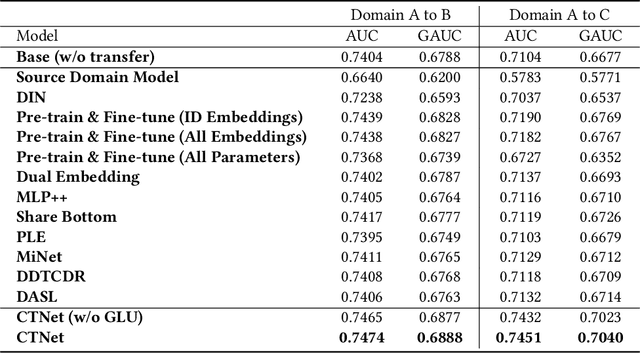
As one of the largest e-commerce platforms in the world, Taobao's recommendation systems (RSs) serve the demands of shopping for hundreds of millions of customers. Click-Through Rate (CTR) prediction is a core component of the RS. One of the biggest characteristics in CTR prediction at Taobao is that there exist multiple recommendation domains where the scales of different domains vary significantly. Therefore, it is crucial to perform cross-domain CTR prediction to transfer knowledge from large domains to small domains to alleviate the data sparsity issue. However, existing cross-domain CTR prediction methods are proposed for static knowledge transfer, ignoring that all domains in real-world RSs are continually time-evolving. In light of this, we present a necessary but novel task named Continual Transfer Learning (CTL), which transfers knowledge from a time-evolving source domain to a time-evolving target domain. In this work, we propose a simple and effective CTL model called CTNet to solve the problem of continual cross-domain CTR prediction at Taobao, and CTNet can be trained efficiently. Particularly, CTNet considers an important characteristic in the industry that models has been continually well-trained for a very long time. So CTNet aims to fully utilize all the well-trained model parameters in both source domain and target domain to avoid losing historically acquired knowledge, and only needs incremental target domain data for training to guarantee efficiency. Extensive offline experiments and online A/B testing at Taobao demonstrate the efficiency and effectiveness of CTNet. CTNet is now deployed online in the recommender systems of Taobao, serving the main traffic of hundreds of millions of active users.
Tradeoffs in Preventing Manipulation in Paper Bidding for Reviewer Assignment
Jul 22, 2022
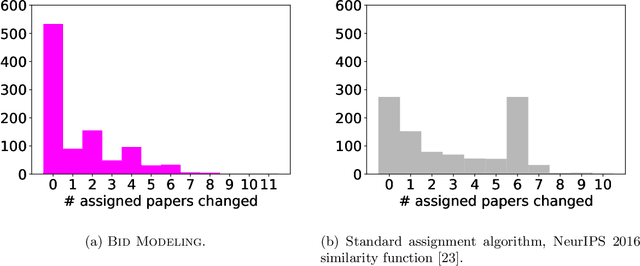
Many conferences rely on paper bidding as a key component of their reviewer assignment procedure. These bids are then taken into account when assigning reviewers to help ensure that each reviewer is assigned to suitable papers. However, despite the benefits of using bids, reliance on paper bidding can allow malicious reviewers to manipulate the paper assignment for unethical purposes (e.g., getting assigned to a friend's paper). Several different approaches to preventing this manipulation have been proposed and deployed. In this paper, we enumerate certain desirable properties that algorithms for addressing bid manipulation should satisfy. We then offer a high-level analysis of various approaches along with directions for future investigation.