 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Neural Character Rendering with Pose-Guided Multiplane Images
Apr 25, 2022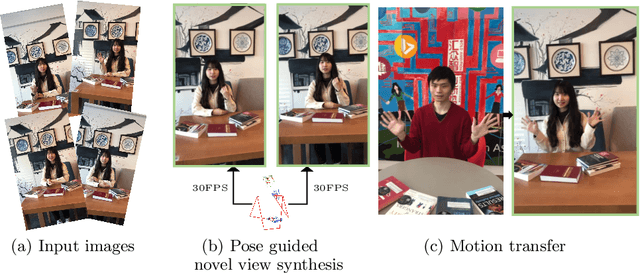
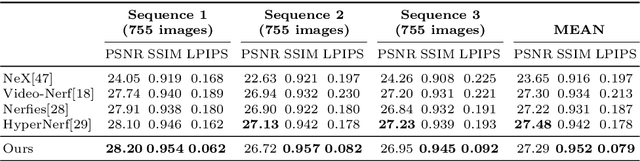
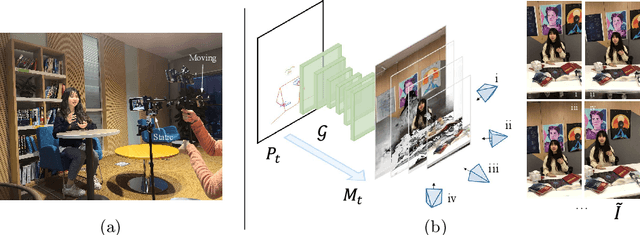
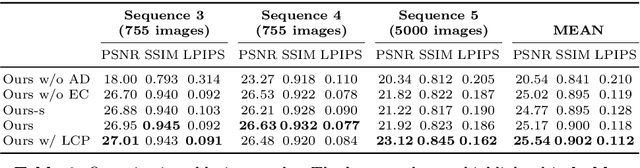
We propose pose-guided multiplane image (MPI) synthesis which can render an animatable character in real scenes with photorealistic quality. We use a portable camera rig to capture the multi-view images along with the driving signal for the moving subject. Our method generalizes the image-to-image translation paradigm, which translates the human pose to a 3D scene representation -- MPIs that can be rendered in free viewpoints, using the multi-views captures as supervision. To fully cultivate the potential of MPI, we propose depth-adaptive MPI which can be learned using variable exposure images while being robust to inaccurate camera registration. Our method demonstrates advantageous novel-view synthesis quality over the state-of-the-art approaches for characters with challenging motions. Moreover, the proposed method is generalizable to novel combinations of training poses and can be explicitly controlled. Our method achieves such expressive and animatable character rendering all in real time, serving as a promising solution for practical applications.
Protecting Celebrities from DeepFake with Identity Consistency Transformer
Apr 05, 2022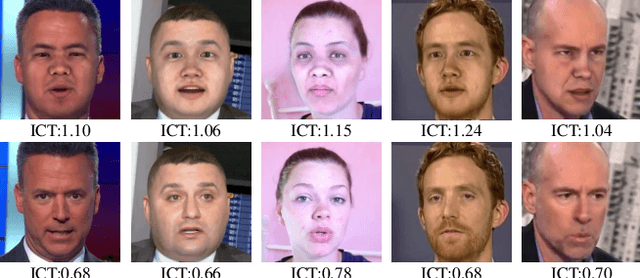
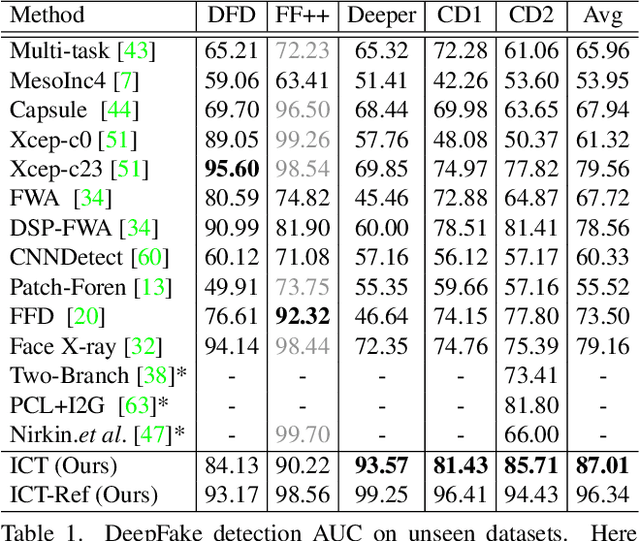

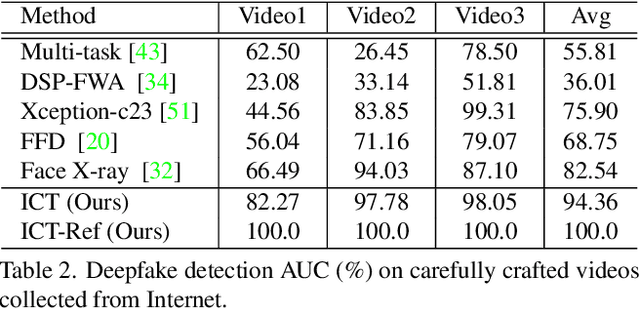
In this work we propose Identity Consistency Transformer, a novel face forgery detection method that focuses on high-level semantics, specifically identity information, and detecting a suspect face by finding identity inconsistency in inner and outer face regions. The Identity Consistency Transformer incorporates a consistency loss for identity consistency determination. We show that Identity Consistency Transformer exhibits superior generalization ability not only across different datasets but also across various types of image degradation forms found in real-world applications including deepfake videos. The Identity Consistency Transformer can be easily enhanced with additional identity information when such information is available, and for this reason it is especially well-suited for detecting face forgeries involving celebrities. Code will be released at \url{https://github.com/LightDXY/ICT_DeepFake}
Large-Scale Pre-training for Person Re-identification with Noisy Labels
Apr 04, 2022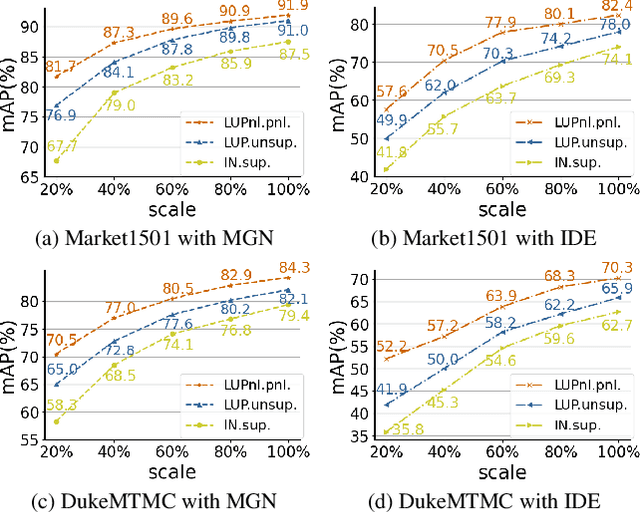
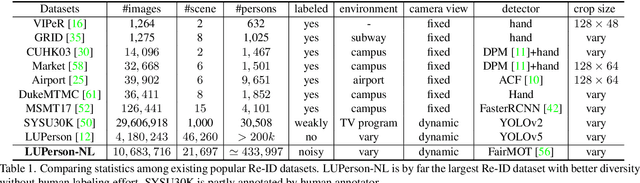
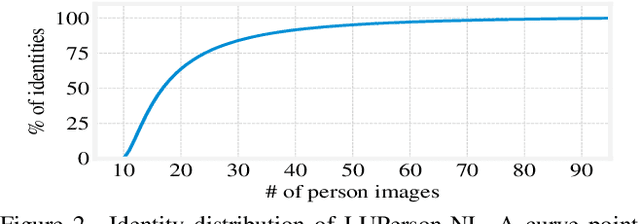
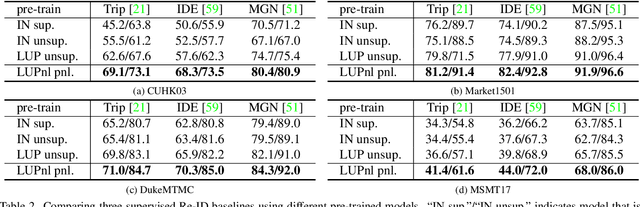
This paper aims to address the problem of pre-training for person re-identification (Re-ID) with noisy labels. To setup the pre-training task, we apply a simple online multi-object tracking system on raw videos of an existing unlabeled Re-ID dataset "LUPerson" nd build the Noisy Labeled variant called "LUPerson-NL". Since theses ID labels automatically derived from tracklets inevitably contain noises, we develop a large-scale Pre-training framework utilizing Noisy Labels (PNL), which consists of three learning modules: supervised Re-ID learning, prototype-based contrastive learning, and label-guided contrastive learning. In principle, joint learning of these three modules not only clusters similar examples to one prototype, but also rectifies noisy labels based on the prototype assignment. We demonstrate that learning directly from raw videos is a promising alternative for pre-training, which utilizes spatial and temporal correlations as weak supervision. This simple pre-training task provides a scalable way to learn SOTA Re-ID representations from scratch on "LUPerson-NL" without bells and whistles. For example, by applying on the same supervised Re-ID method MGN, our pre-trained model improves the mAP over the unsupervised pre-training counterpart by 5.7%, 2.2%, 2.3% on CUHK03, DukeMTMC, and MSMT17 respectively. Under the small-scale or few-shot setting, the performance gain is even more significant, suggesting a better transferability of the learned representation. Code is available at https://github.com/DengpanFu/LUPerson-NL
Semi-Supervised Image-to-Image Translation using Latent Space Mapping
Mar 29, 2022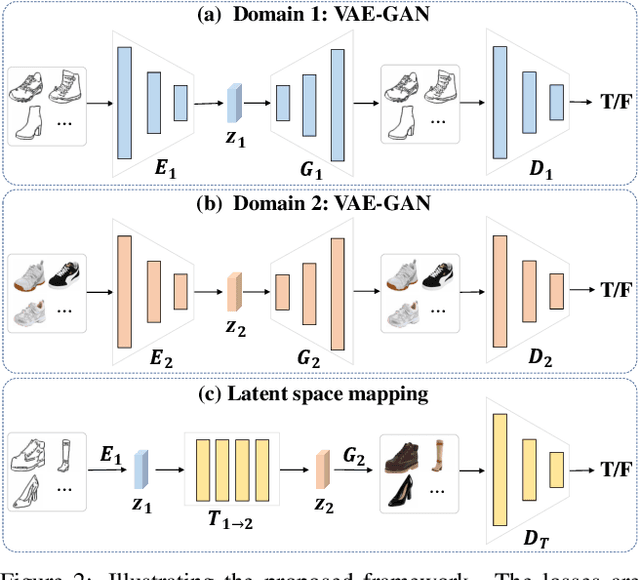
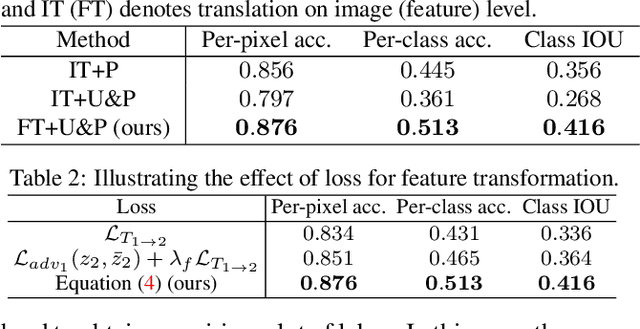
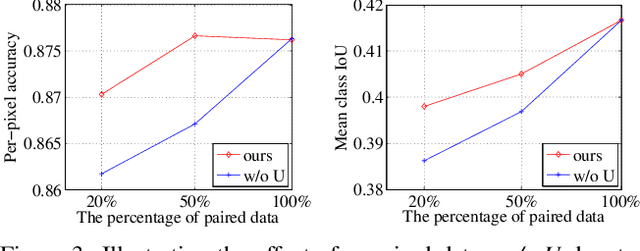
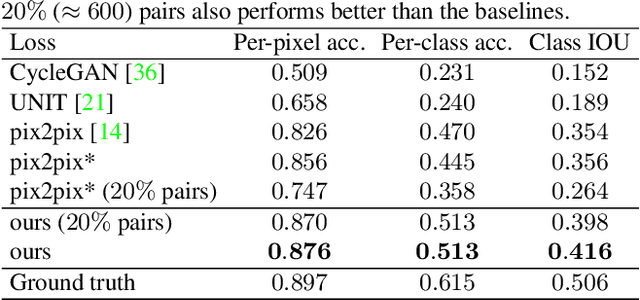
Recent image-to-image translation works have been transferred from supervised to unsupervised settings due to the expensive cost of capturing or labeling large amounts of paired data. However, current unsupervised methods using the cycle-consistency constraint may not find the desired mapping, especially for difficult translation tasks. On the other hand, a small number of paired data are usually accessible. We therefore introduce a general framework for semi-supervised image translation. Unlike previous works, our main idea is to learn the translation over the latent feature space instead of the image space. Thanks to the low dimensional feature space, it is easier to find the desired mapping function, resulting in improved quality of translation results as well as the stability of the translation model. Empirically we show that using feature translation generates better results, even using a few bits of paired data. Experimental comparisons with state-of-the-art approaches demonstrate the effectiveness of the proposed framework on a variety of challenging image-to-image translation tasks
StyleSwin: Transformer-based GAN for High-resolution Image Generation
Dec 20, 2021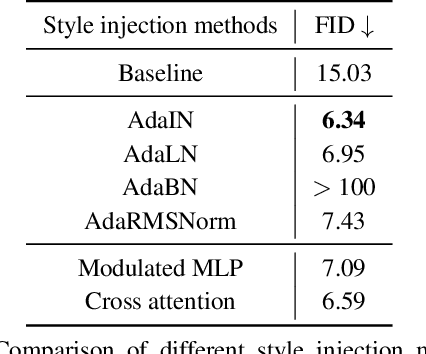
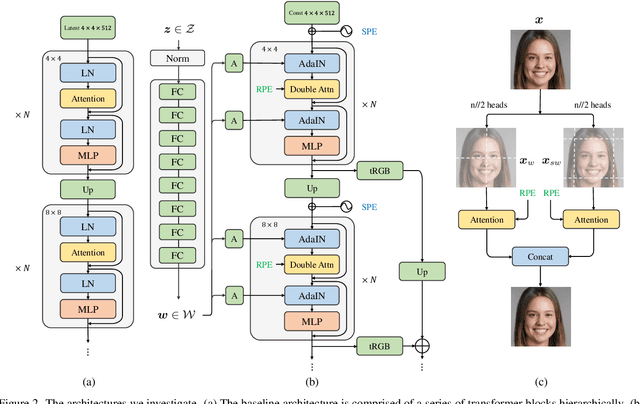
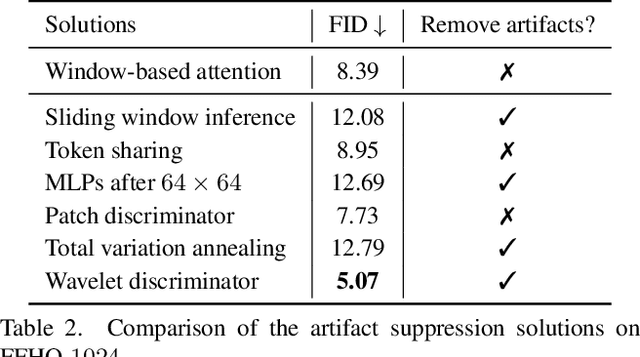

Despite the tantalizing success in a broad of vision tasks, transformers have not yet demonstrated on-par ability as ConvNets in high-resolution image generative modeling. In this paper, we seek to explore using pure transformers to build a generative adversarial network for high-resolution image synthesis. To this end, we believe that local attention is crucial to strike the balance between computational efficiency and modeling capacity. Hence, the proposed generator adopts Swin transformer in a style-based architecture. To achieve a larger receptive field, we propose double attention which simultaneously leverages the context of the local and the shifted windows, leading to improved generation quality. Moreover, we show that offering the knowledge of the absolute position that has been lost in window-based transformers greatly benefits the generation quality. The proposed StyleSwin is scalable to high resolutions, with both the coarse geometry and fine structures benefit from the strong expressivity of transformers. However, blocking artifacts occur during high-resolution synthesis because performing the local attention in a block-wise manner may break the spatial coherency. To solve this, we empirically investigate various solutions, among which we find that employing a wavelet discriminator to examine the spectral discrepancy effectively suppresses the artifacts. Extensive experiments show the superiority over prior transformer-based GANs, especially on high resolutions, e.g., 1024x1024. The StyleSwin, without complex training strategies, excels over StyleGAN on CelebA-HQ 1024, and achieves on-par performance on FFHQ-1024, proving the promise of using transformers for high-resolution image generation. The code and models will be available at https://github.com/microsoft/StyleSwin.
Vector Quantized Diffusion Model for Text-to-Image Synthesis
Dec 20, 2021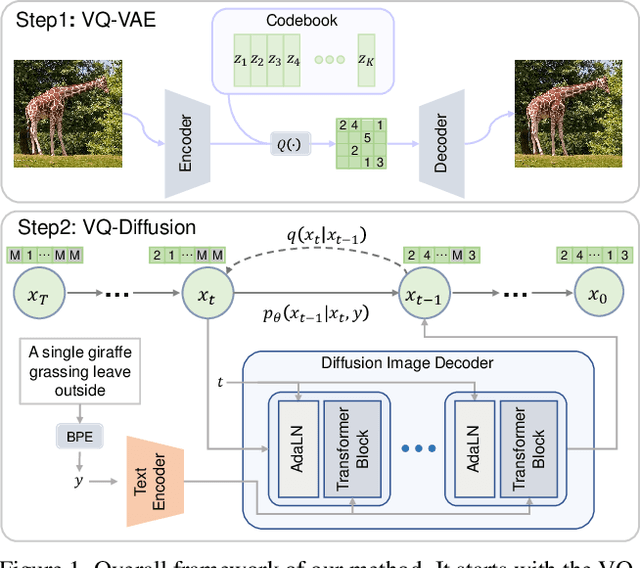
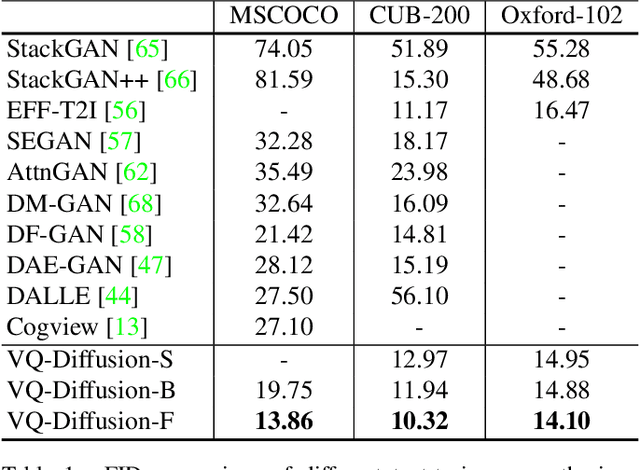

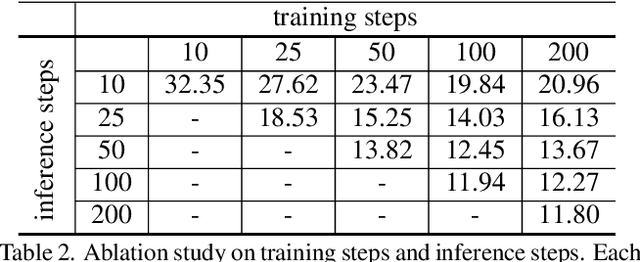
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
General Facial Representation Learning in a Visual-Linguistic Manner
Dec 06, 2021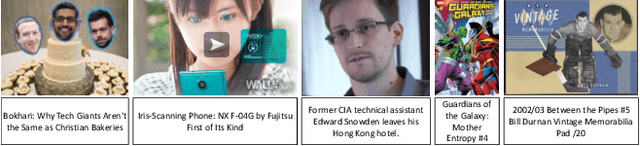
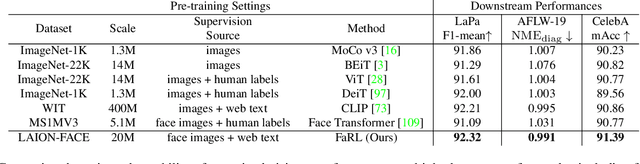
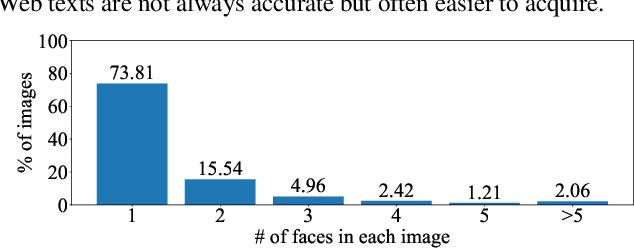

How to learn a universal facial representation that boosts all face analysis tasks? This paper takes one step toward this goal. In this paper, we study the transfer performance of pre-trained models on face analysis tasks and introduce a framework, called FaRL, for general Facial Representation Learning in a visual-linguistic manner. On one hand, the framework involves a contrastive loss to learn high-level semantic meaning from image-text pairs. On the other hand, we propose exploring low-level information simultaneously to further enhance the face representation, by adding a masked image modeling. We perform pre-training on LAION-FACE, a dataset containing large amount of face image-text pairs, and evaluate the representation capability on multiple downstream tasks. We show that FaRL achieves better transfer performance compared with previous pre-trained models. We also verify its superiority in the low-data regime. More importantly, our model surpasses the state-of-the-art methods on face analysis tasks including face parsing and face alignment.
PeCo: Perceptual Codebook for BERT Pre-training of Vision Transformers
Nov 24, 2021
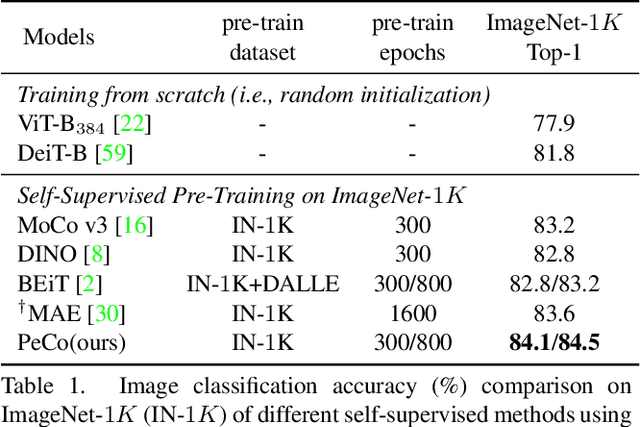
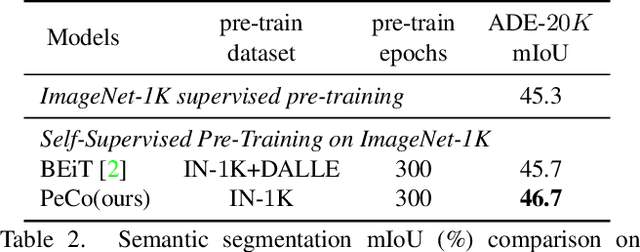

This paper explores a better codebook for BERT pre-training of vision transformers. The recent work BEiT successfully transfers BERT pre-training from NLP to the vision field. It directly adopts one simple discrete VAE as the visual tokenizer, but has not considered the semantic level of the resulting visual tokens. By contrast, the discrete tokens in NLP field are naturally highly semantic. This difference motivates us to learn a perceptual codebook. And we surprisingly find one simple yet effective idea: enforcing perceptual similarity during the dVAE training. We demonstrate that the visual tokens generated by the proposed perceptual codebook do exhibit better semantic meanings, and subsequently help pre-training achieve superior transfer performance in various downstream tasks. For example, we achieve 84.5 Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming the competitive method BEiT by +1.3 with the same pre-training epochs. It can also improve the performance of object detection and segmentation tasks on COCO val by +1.3 box AP and +1.0 mask AP, semantic segmentation on ADE20k by +1.0 mIoU, The code and models will be available at \url{https://github.com/microsoft/PeCo}.
Exploring Temporal Coherence for More General Video Face Forgery Detection
Aug 15, 2021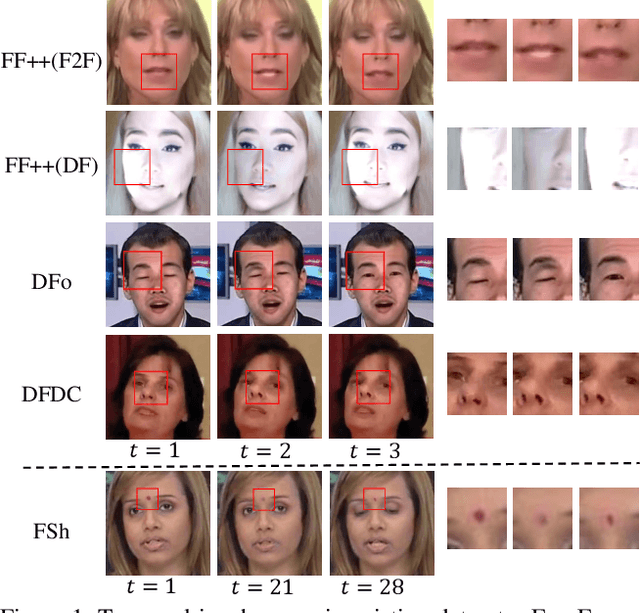
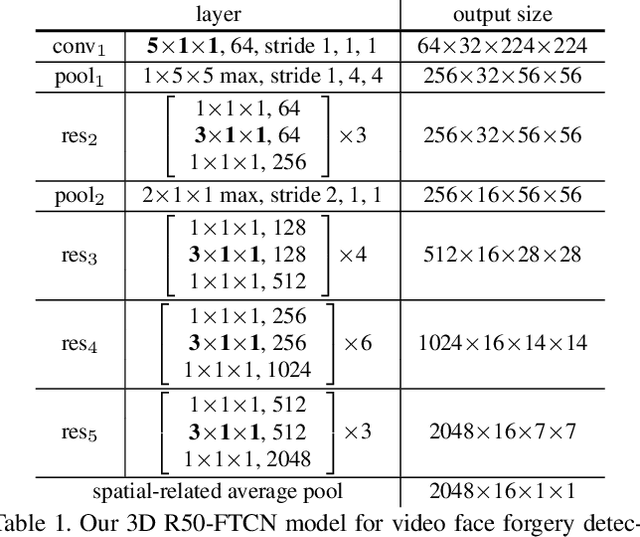
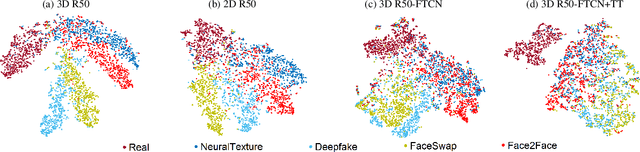
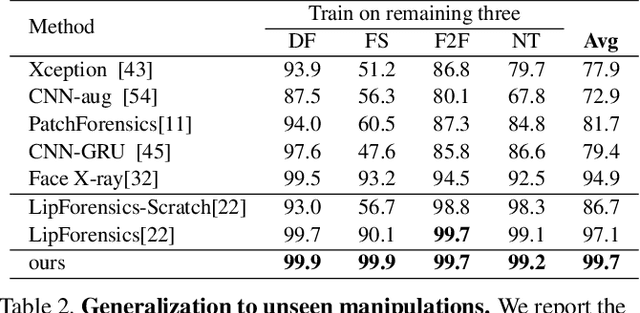
Although current face manipulation techniques achieve impressive performance regarding quality and controllability, they are struggling to generate temporal coherent face videos. In this work, we explore to take full advantage of the temporal coherence for video face forgery detection. To achieve this, we propose a novel end-to-end framework, which consists of two major stages. The first stage is a fully temporal convolution network (FTCN). The key insight of FTCN is to reduce the spatial convolution kernel size to 1, while maintaining the temporal convolution kernel size unchanged. We surprisingly find this special design can benefit the model for extracting the temporal features as well as improve the generalization capability. The second stage is a Temporal Transformer network, which aims to explore the long-term temporal coherence. The proposed framework is general and flexible, which can be directly trained from scratch without any pre-training models or external datasets. Extensive experiments show that our framework outperforms existing methods and remains effective when applied to detect new sorts of face forgery videos.
Dual Path Learning for Domain Adaptation of Semantic Segmentation
Aug 13, 2021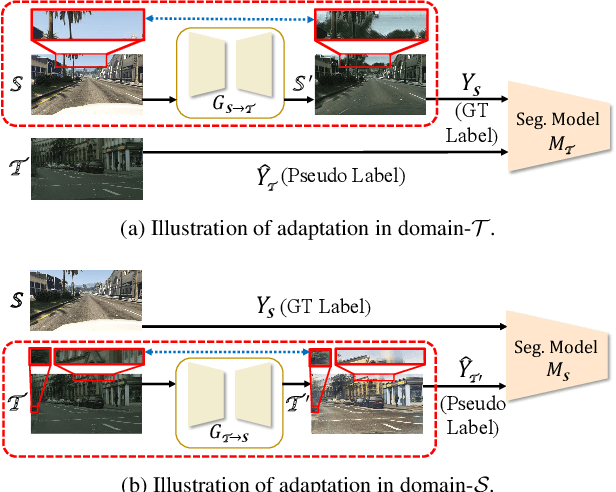
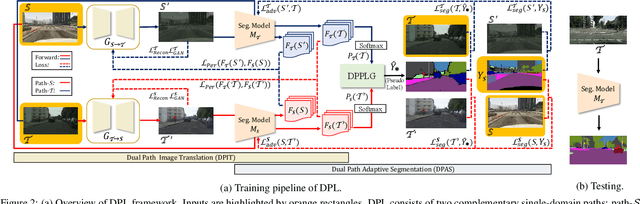
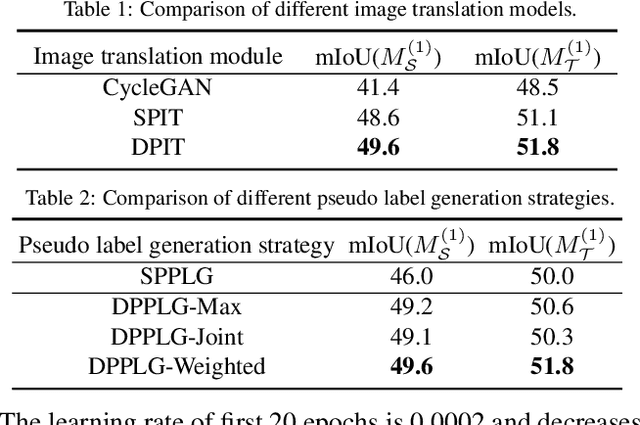
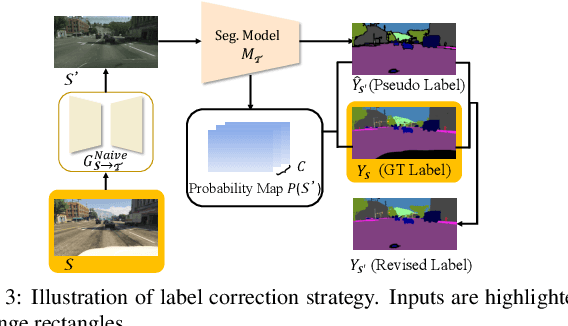
Domain adaptation for semantic segmentation enables to alleviate the need for large-scale pixel-wise annotations. Recently, self-supervised learning (SSL) with a combination of image-to-image translation shows great effectiveness in adaptive segmentation. The most common practice is to perform SSL along with image translation to well align a single domain (the source or target). However, in this single-domain paradigm, unavoidable visual inconsistency raised by image translation may affect subsequent learning. In this paper, based on the observation that domain adaptation frameworks performed in the source and target domain are almost complementary in terms of image translation and SSL, we propose a novel dual path learning (DPL) framework to alleviate visual inconsistency. Concretely, DPL contains two complementary and interactive single-domain adaptation pipelines aligned in source and target domain respectively. The inference of DPL is extremely simple, only one segmentation model in the target domain is employed. Novel technologies such as dual path image translation and dual path adaptive segmentation are proposed to make two paths promote each other in an interactive manner. Experiments on GTA5$\rightarrow$Cityscapes and SYNTHIA$\rightarrow$Cityscapes scenarios demonstrate the superiority of our DPL model over the state-of-the-art methods. The code and models are available at: \url{https://github.com/royee182/DPL}