 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Pretraining for Vertical Search: Case Study on Biomedical Literature
Jun 25, 2021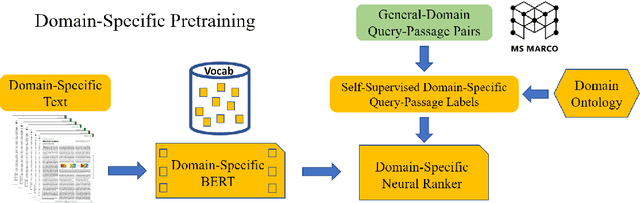
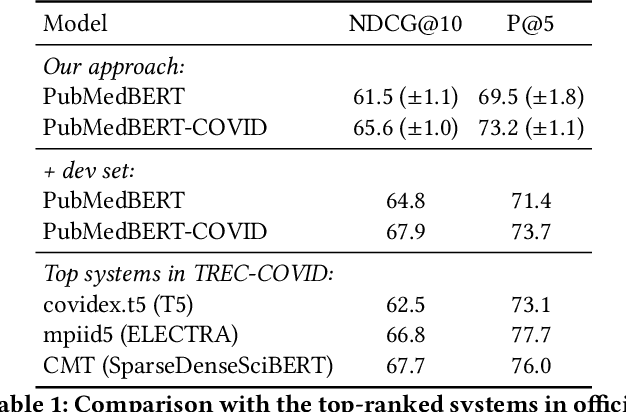

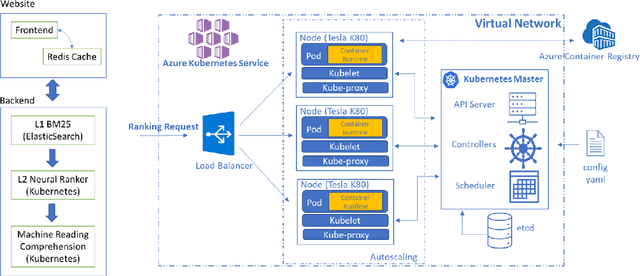
Information overload is a prevalent challenge in many high-value domains. A prominent case in point is the explosion of the biomedical literature on COVID-19, which swelled to hundreds of thousands of papers in a matter of months. In general, biomedical literature expands by two papers every minute, totalling over a million new papers every year. Search in the biomedical realm, and many other vertical domains is challenging due to the scarcity of direct supervision from click logs. Self-supervised learning has emerged as a promising direction to overcome the annotation bottleneck. We propose a general approach for vertical search based on domain-specific pretraining and present a case study for the biomedical domain. Despite being substantially simpler and not using any relevance labels for training or development, our method performs comparably or better than the best systems in the official TREC-COVID evaluation, a COVID-related biomedical search competition. Using distributed computing in modern cloud infrastructure, our system can scale to tens of millions of articles on PubMed and has been deployed as Microsoft Biomedical Search, a new search experience for biomedical literature: https://aka.ms/biomedsearch.
Platform for Situated Intelligence
Mar 29, 2021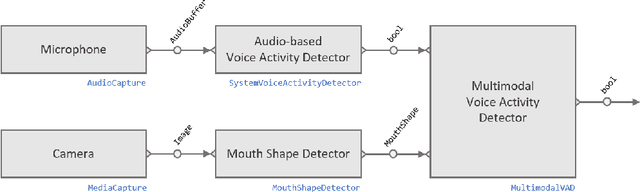

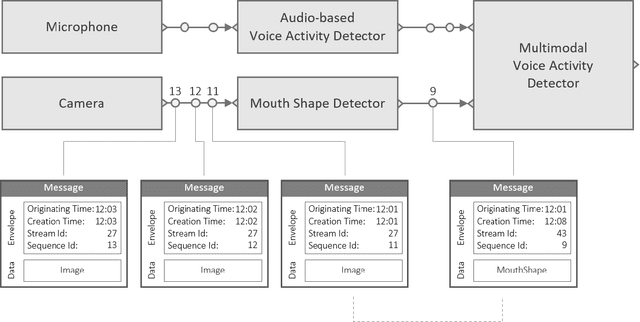

We introduce Platform for Situated Intelligence, an open-source framework created to support the rapid development and study of multimodal, integrative-AI systems. The framework provides infrastructure for sensing, fusing, and making inferences from temporal streams of data across different modalities, a set of tools that enable visualization and debugging, and an ecosystem of components that encapsulate a variety of perception and processing technologies. These assets jointly provide the means for rapidly constructing and refining multimodal, integrative-AI systems, while retaining the efficiency and performance characteristics required for deployment in open-world settings.
Formation of Social Ties Influences Food Choice: A Campus-Wide Longitudinal Study
Feb 17, 2021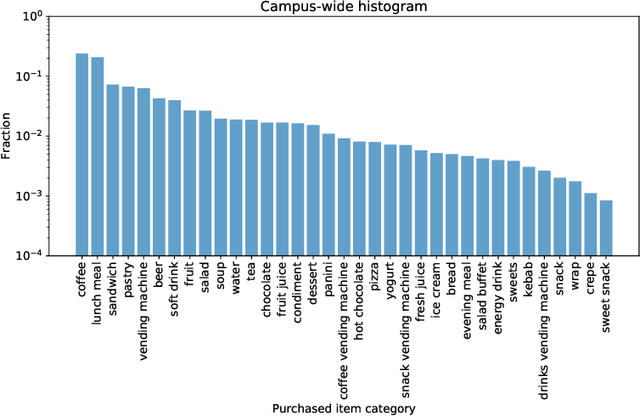
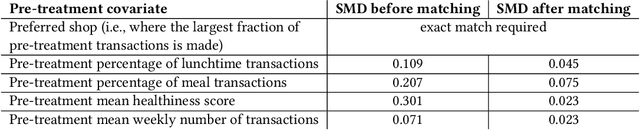
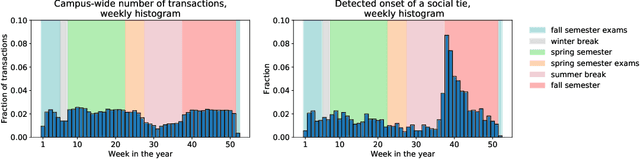
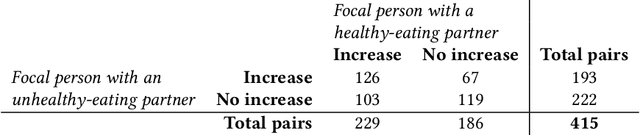
Nutrition is a key determinant of long-term health, and social influence has long been theorized to be a key determinant of nutrition. It has been difficult to quantify the postulated role of social influence on nutrition using traditional methods such as surveys, due to the typically small scale and short duration of studies. To overcome these limitations, we leverage a novel source of data: logs of 38 million food purchases made over an 8-year period on the Ecole Polytechnique Federale de Lausanne (EPFL) university campus, linked to anonymized individuals via the smartcards used to make on-campus purchases. In a longitudinal observational study, we ask: How is a person's food choice affected by eating with someone else whose own food choice is healthy vs. unhealthy? To estimate causal effects from the passively observed log data, we control confounds in a matched quasi-experimental design: we identify focal users who at first do not have any regular eating partners but then start eating with a fixed partner regularly, and we match focal users into comparison pairs such that paired users are nearly identical with respect to covariates measured before acquiring the partner, where the two focal users' new eating partners diverge in the healthiness of their respective food choice. A difference-in-differences analysis of the paired data yields clear evidence of social influence: focal users acquiring a healthy-eating partner change their habits significantly more toward healthy foods than focal users acquiring an unhealthy-eating partner. We further identify foods whose purchase frequency is impacted significantly by the eating partner's healthiness of food choice. Beyond the main results, the work demonstrates the utility of passively sensed food purchase logs for deriving insights, with the potential of informing the design of public health interventions and food offerings.
Understanding Failures of Deep Networks via Robust Feature Extraction
Dec 03, 2020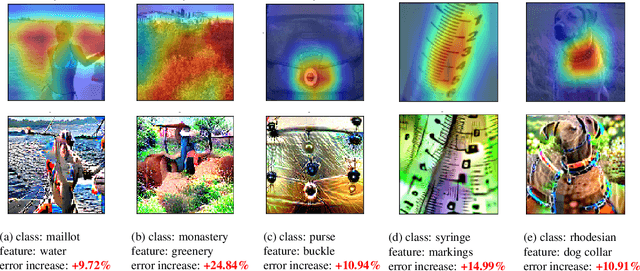
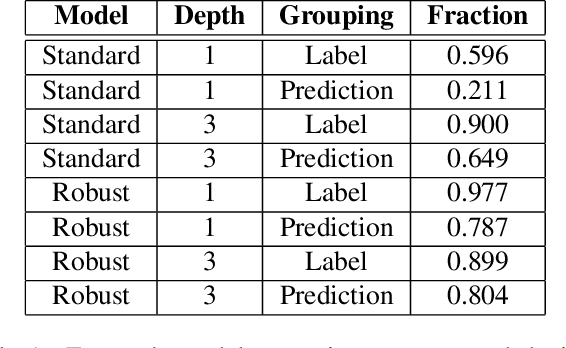
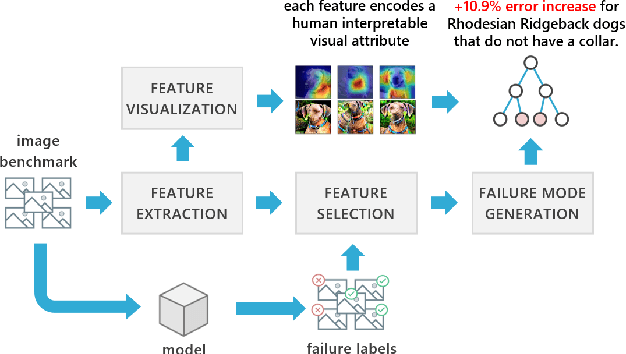
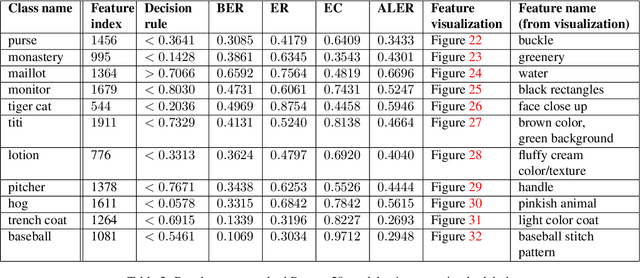
Traditional evaluation metrics for learned models that report aggregate scores over a test set are insufficient for surfacing important and informative patterns of failure over features and instances. We introduce and study a method aimed at characterizing and explaining failures by identifying visual attributes whose presence or absence results in poor performance. In distinction to previous work that relies upon crowdsourced labels for visual attributes, we leverage the representation of a separate robust model to extract interpretable features and then harness these features to identify failure modes. We further propose a visualization method to enable humans to understand the semantic meaning encoded in such features and test the comprehensibility of the features. An evaluation of the methods on the ImageNet dataset demonstrates that: (i) the proposed workflow is effective for discovering important failure modes, (ii) the visualization techniques help humans to understand the extracted features, and (iii) the extracted insights can assist engineers with error analysis and debugging.
Extracting a Knowledge Base of Mechanisms from COVID-19 Papers
Oct 08, 2020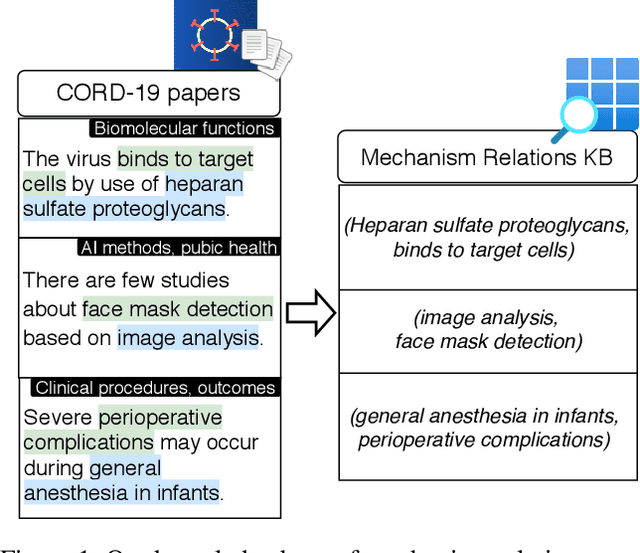
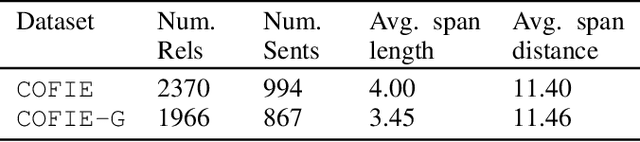

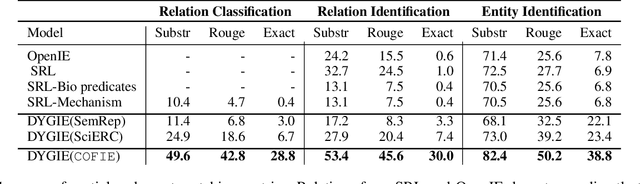
The urgency of mitigating COVID-19 has spawned a large and diverse body of scientific literature that is challenging for researchers to navigate. This explosion of information has stimulated interest in automated tools to help identify useful knowledge. We have pursued the use of methods for extracting diverse forms of mechanism relations from the natural language of scientific papers. We seek to identify concepts in COVID-19 and related literature which represent activities, functions, associations and causal relations, ranging from cellular processes to economic impacts. We formulate a broad, coarse-grained schema targeting mechanism relations between open, free-form entities. Our approach strikes a balance between expressivity and breadth that supports generalization across diverse concepts. We curate a dataset of scientific papers annotated according to our novel schema. Using an information extraction model trained on this new corpus, we construct a knowledge base (KB) of 2M mechanism relations, which we make publicly available. Our model is able to extract relations at an F1 at least twice that of baselines such as open IE or related scientific IE systems. We conduct experiments examining the ability of our system to retrieve relevant information on viral mechanisms of action, and on applications of AI to COVID-19 research. In both cases, our system identifies relevant information from our automatically-constructed knowledge base with high precision.
An Empirical Analysis of Backward Compatibility in Machine Learning Systems
Aug 11, 2020

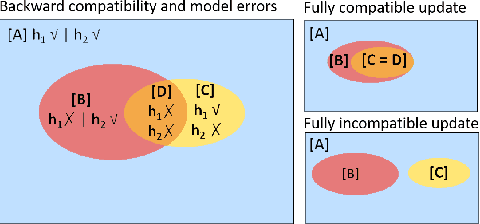

In many applications of machine learning (ML), updates are performed with the goal of enhancing model performance. However, current practices for updating models rely solely on isolated, aggregate performance analyses, overlooking important dependencies, expectations, and needs in real-world deployments. We consider how updates, intended to improve ML models, can introduce new errors that can significantly affect downstream systems and users. For example, updates in models used in cloud-based classification services, such as image recognition, can cause unexpected erroneous behavior in systems that make calls to the services. Prior work has shown the importance of "backward compatibility" for maintaining human trust. We study challenges with backward compatibility across different ML architectures and datasets, focusing on common settings including data shifts with structured noise and ML employed in inferential pipelines. Our results show that (i) compatibility issues arise even without data shift due to optimization stochasticity, (ii) training on large-scale noisy datasets often results in significant decreases in backward compatibility even when model accuracy increases, and (iii) distributions of incompatible points align with noise bias, motivating the need for compatibility aware de-noising and robustness methods.
SciSight: Combining faceted navigation and research group detection for COVID-19 exploratory scientific search
May 27, 2020

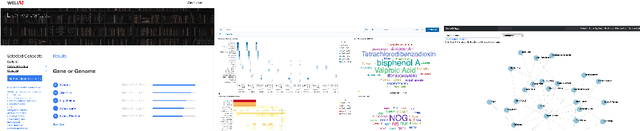
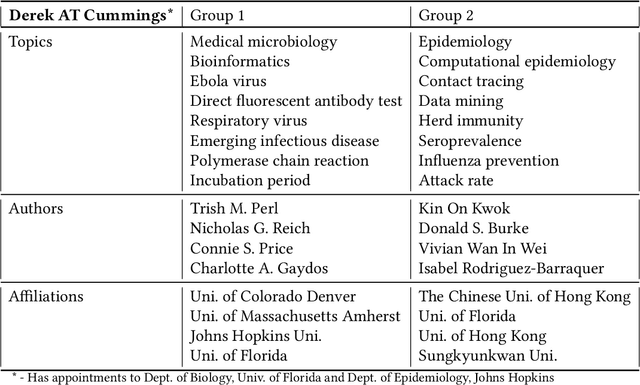
The COVID-19 pandemic has sparked unprecedented mobilization of scientists, already generating thousands of new papers that join a litany of previous biomedical work in related areas. This deluge of information makes it hard for researchers to keep track of their own research area, let alone explore new directions. Standard search engines are designed primarily for targeted search and are not geared for discovery or making connections that are not obvious from reading individual papers. In this paper, we present our ongoing work on SciSight, a novel framework for exploratory search of COVID-19 research. Based on formative interviews with scientists and a review of existing tools, we build and integrate two key capabilities: first, exploring interactions between biomedical facets (e.g., proteins, genes, drugs, diseases, patient characteristics); and second, discovering groups of researchers and how they are connected. We extract entities using a language model pre-trained on several biomedical information extraction tasks, and enrich them with data from the Microsoft Academic Graph (MAG). To find research groups automatically, we use hierarchical clustering with overlap to allow authors, as they do, to belong to multiple groups. Finally, we introduce a novel presentation of these groups based on both topical and social affinities, allowing users to drill down from groups to papers to associations between entities, and update query suggestions on the fly with the goal of facilitating exploratory navigation. SciSight has thus far served over 10K users with over 30K page views and 13% returning users. Preliminary user interviews with biomedical researchers suggest that SciSight complements current approaches and helps find new and relevant knowledge.
Learning to Complement Humans
May 01, 2020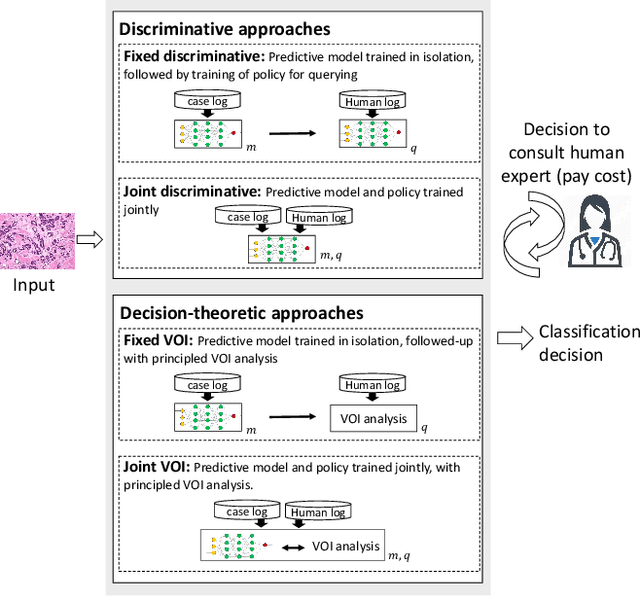
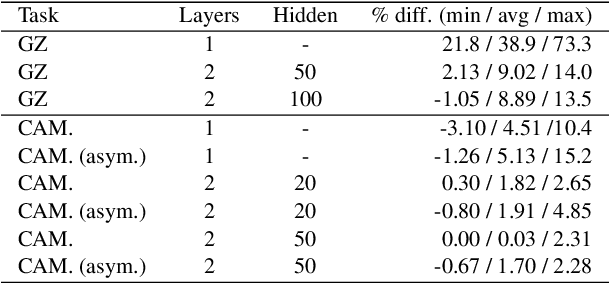
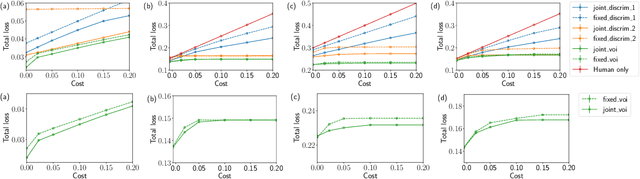
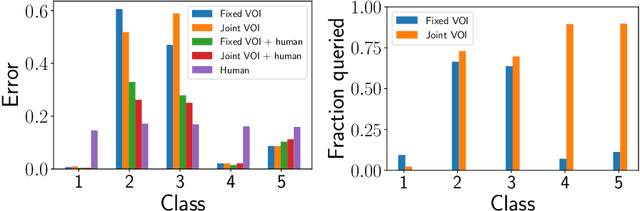
A rising vision for AI in the open world centers on the development of systems that can complement humans for perceptual, diagnostic, and reasoning tasks. To date, systems aimed at complementing the skills of people have employed models trained to be as accurate as possible in isolation. We demonstrate how an end-to-end learning strategy can be harnessed to optimize the combined performance of human-machine teams by considering the distinct abilities of people and machines. The goal is to focus machine learning on problem instances that are difficult for humans, while recognizing instances that are difficult for the machine and seeking human input on them. We demonstrate in two real-world domains (scientific discovery and medical diagnosis) that human-machine teams built via these methods outperform the individual performance of machines and people. We then analyze conditions under which this complementarity is strongest, and which training methods amplify it. Taken together, our work provides the first systematic investigation of how machine learning systems can be trained to complement human reasoning.
Optimizing AI for Teamwork
Apr 27, 2020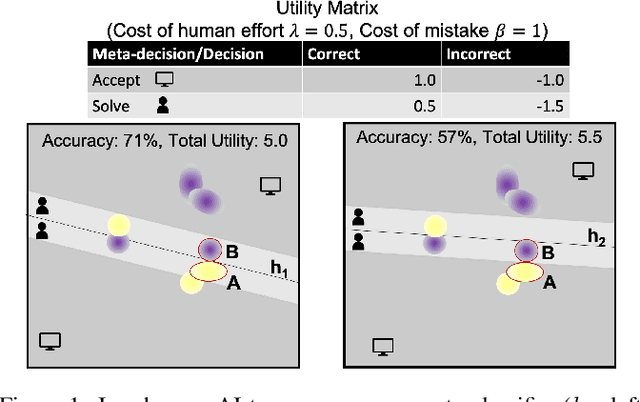
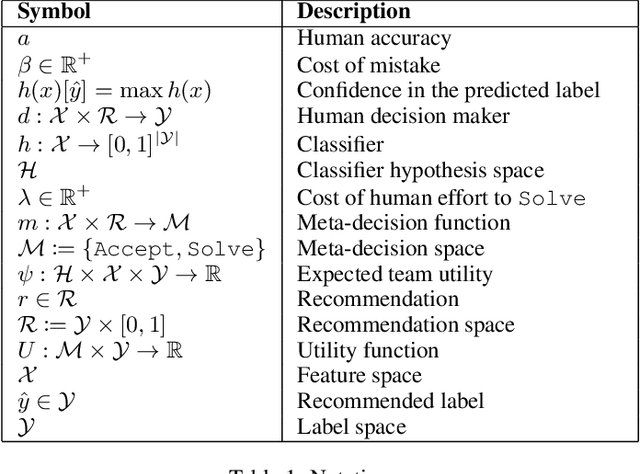
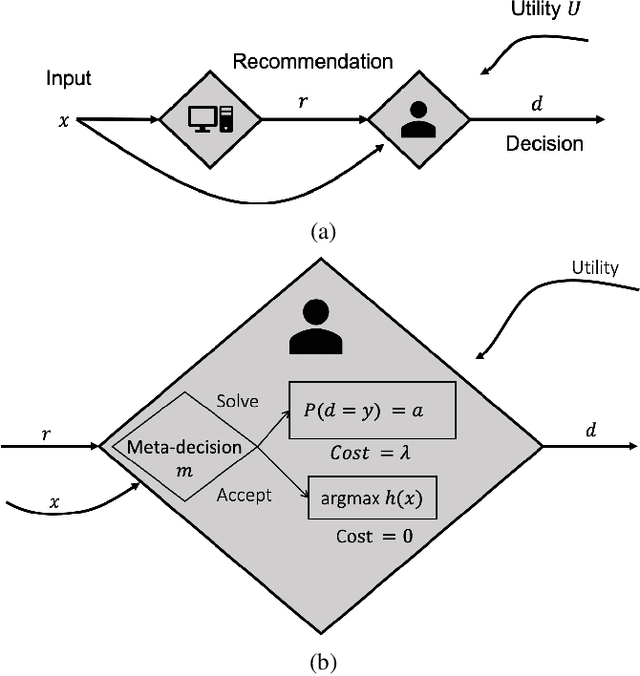
In many high-stakes domains such as criminal justice, finance, and healthcare, AI systems may recommend actions to a human expert responsible for final decisions, a context known as AI-advised decision making. When AI practitioners deploy the most accurate system in these domains, they implicitly assume that the system will function alone in the world. We argue that the most accurate AI team-mate is not necessarily the em best teammate; for example, predictable performance is worth a slight sacrifice in AI accuracy. So, we propose training AI systems in a human-centered manner and directly optimizing for team performance. We study this proposal for a specific type of human-AI team, where the human overseer chooses to accept the AI recommendation or solve the task themselves. To optimize the team performance we maximize the team's expected utility, expressed in terms of quality of the final decision, cost of verifying, and individual accuracies. Our experiments with linear and non-linear models on real-world, high-stakes datasets show that the improvements in utility while being small and varying across datasets and parameters (such as cost of mistake), are real and consistent with our definition of team utility. We discuss the shortcoming of current optimization approaches beyond well-studied loss functions such as log-loss, and encourage future work on human-centered optimization problems motivated by human-AI collaborations.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020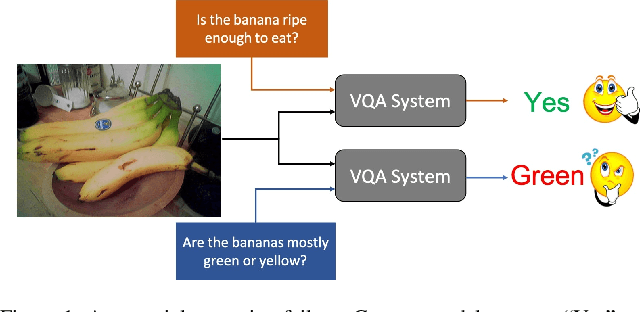

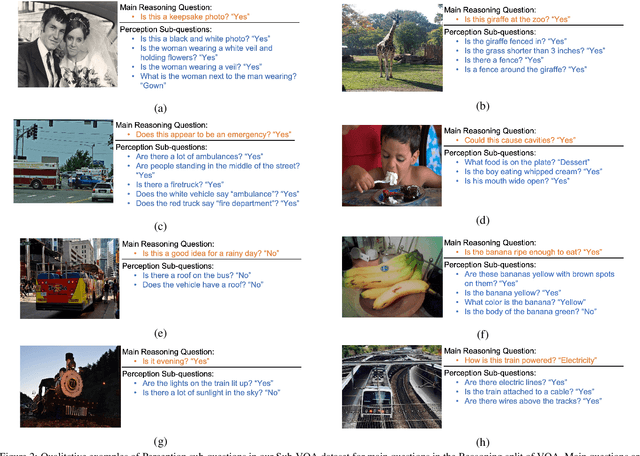
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.