 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Ahead: Prospection-Guided Retrieval of Memory with Language Models
May 13, 2026Long-horizon personalization requires dialogue assistants to retrieve user-specific facts from extended interaction histories. In practice, many relevant facts often have low semanticsimilarity to the query under dense retrieval. Standard Retrieval-Augmented Generation (RAG) and GraphRAG systems are still largely retrospective: they rely on embedding similarity to the query or on fixed graph traversals, so they often miss facts that matter for the user's needs but lie far from the query in embedding space. Inspired by prospection, the human ability to use imagined futures as cues for recall, we introduce Prospection-Guided Retrieval (PGR), which decouples retrieval from how memories are stored. Given a user query, PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes rather than relying on the original query alone. The facts retrieved by these probes are then used to personalize the next round of prospection, enabling PGR to uncover additional memories that become relevant only after the simulation is grounded in the user's history. We also introduce MemoryQuest, a challenging multi-session benchmark in which each query is annotated with 3--5 dated reference facts subject to a low query-reference similarity constraint. Across 1,625 queries spanning 185 user profiles from 3 publicly available datasets, PGR-TOT substantially improves retrieval, including nearly 3x recall on MemoryQuest over the strongest baseline. In pairwise LLM-as-judge comparisons against baselines, PGR-generated responses are preferred on 89--98% of queries, with blinded human annotations on held-out subsets showing the same trend. Overall, the results demonstrate that explicit prospection yields large gains in long-horizon retrieval and response quality relative to similarity-only baselines.
Trapped by Expectations: Functional Fixedness in LLM-Enabled Chat Search
Apr 02, 2025Functional fixedness, a cognitive bias that restricts users' interactions with a new system or tool to expected or familiar ways, limits the full potential of Large Language Model (LLM)-enabled chat search, especially in complex and exploratory tasks. To investigate its impact, we conducted a crowdsourcing study with 450 participants, each completing one of six decision-making tasks spanning public safety, diet and health management, sustainability, and AI ethics. Participants engaged in a multi-prompt conversation with ChatGPT to address the task, allowing us to compare pre-chat intent-based expectations with observed interactions. We found that: 1) Several aspects of pre-chat expectations are closely associated with users' prior experiences with ChatGPT, search engines, and virtual assistants; 2) Prior system experience shapes language use and prompting behavior. Frequent ChatGPT users reduced deictic terms and hedge words and frequently adjusted prompts. Users with rich search experience maintained structured, less-conversational queries with minimal modifications. Users of virtual assistants favored directive, command-like prompts, reinforcing functional fixedness; 3) When the system failed to meet expectations, participants generated more detailed prompts with increased linguistic diversity, reflecting adaptive shifts. These findings suggest that while preconceived expectations constrain early interactions, unmet expectations can motivate behavioral adaptation. With appropriate system support, this may promote broader exploration of LLM capabilities. This work also introduces a typology for user intents in chat search and highlights the importance of mitigating functional fixedness to support more creative and analytical use of LLMs.
Agents Are Not Enough
Dec 19, 2024
In the midst of the growing integration of Artificial Intelligence (AI) into various aspects of our lives, agents are experiencing a resurgence. These autonomous programs that act on behalf of humans are neither new nor exclusive to the mainstream AI movement. By exploring past incarnations of agents, we can understand what has been done previously, what worked, and more importantly, what did not pan out and why. This understanding lets us to examine what distinguishes the current focus on agents. While generative AI is appealing, this technology alone is insufficient to make new generations of agents more successful. To make the current wave of agents effective and sustainable, we envision an ecosystem that includes not only agents but also Sims, which represent user preferences and behaviors, as well as Assistants, which directly interact with the user and coordinate the execution of user tasks with the help of the agents.
Panmodal Information Interaction
May 21, 2024



The emergence of generative artificial intelligence (GenAI) is transforming information interaction. For decades, search engines such as Google and Bing have been the primary means of locating relevant information for the general population. They have provided search results in the same standard format (the so-called "10 blue links"). The recent ability to chat via natural language with AI-based agents and have GenAI automatically synthesize answers in real-time (grounded in top-ranked results) is changing how people interact with and consume information at massive scale. These two information interaction modalities (traditional search and AI-powered chat) coexist in current search engines, either loosely coupled (e.g., as separate options/tabs) or tightly coupled (e.g., integrated as a chat answer embedded directly within a traditional search result page). We believe that the existence of these two different modalities, and potentially many others, is creating an opportunity to re-imagine the search experience, capitalize on the strengths of many modalities, and develop systems and strategies to support seamless flow between them. We refer to these as panmodal experiences. Unlike monomodal experiences, where only one modality is available and/or used for the task at hand, panmodal experiences make multiple modalities available to users (multimodal), directly support transitions between modalities (crossmodal), and seamlessly combine modalities to tailor task assistance (transmodal). While our focus is search and chat, with learnings from insights from a survey of over 100 individuals who have recently performed common tasks on these two modalities, we also present a more general vision for the future of information interaction using multiple modalities and the emergent capabilities of GenAI.
Navigating Complex Search Tasks with AI Copilots
Nov 02, 2023



As many of us in the information retrieval (IR) research community know and appreciate, search is far from being a solved problem. Millions of people struggle with tasks on search engines every day. Often, their struggles relate to the intrinsic complexity of their task and the failure of search systems to fully understand the task and serve relevant results. The task motivates the search, creating the gap/problematic situation that searchers attempt to bridge/resolve and drives search behavior as they work through different task facets. Complex search tasks require more than support for rudimentary fact finding or re-finding. Research on methods to support complex tasks includes work on generating query and website suggestions, personalizing and contextualizing search, and developing new search experiences, including those that span time and space. The recent emergence of generative artificial intelligence (AI) and the arrival of assistive agents, or copilots, based on this technology, has the potential to offer further assistance to searchers, especially those engaged in complex tasks. There are profound implications from these advances for the design of intelligent systems and for the future of search itself. This article, based on a keynote by the author at the 2023 ACM SIGIR Conference, explores these issues and charts a course toward new horizons in information access guided by AI copilots.
Making Large Language Models Better Data Creators
Oct 31, 2023



Although large language models (LLMs) have advanced the state-of-the-art in NLP significantly, deploying them for downstream applications is still challenging due to cost, responsiveness, control, or concerns around privacy and security. As such, trainable models are still the preferred option in some cases. However, these models still require human-labeled data for optimal performance, which is expensive and time-consuming to obtain. In order to address this issue, several techniques to reduce human effort involve labeling or generating data using LLMs. Although these methods are effective for certain applications, in practice they encounter difficulties in real-world scenarios. Labeling data requires careful data selection, while generating data necessitates task-specific prompt engineering. In this paper, we propose a unified data creation pipeline that requires only a single formatting example, and which is applicable to a broad range of tasks, including traditionally problematic ones with semantically devoid label spaces. In our experiments we demonstrate that instruction-following LLMs are highly cost-effective data creators, and that models trained with these data exhibit performance better than those trained with human-labeled data (by up to 17.5%) on out-of-distribution evaluation, while maintaining comparable performance on in-distribution tasks. These results have important implications for the robustness of NLP systems deployed in the real-world.
Using Large Language Models to Generate, Validate, and Apply User Intent Taxonomies
Sep 14, 2023



Log data can reveal valuable information about how users interact with web search services, what they want, and how satisfied they are. However, analyzing user intents in log data is not easy, especially for new forms of web search such as AI-driven chat. To understand user intents from log data, we need a way to label them with meaningful categories that capture their diversity and dynamics. Existing methods rely on manual or ML-based labeling, which are either expensive or inflexible for large and changing datasets. We propose a novel solution using large language models (LLMs), which can generate rich and relevant concepts, descriptions, and examples for user intents. However, using LLMs to generate a user intent taxonomy and apply it to do log analysis can be problematic for two main reasons: such a taxonomy is not externally validated, and there may be an undesirable feedback loop. To overcome these issues, we propose a new methodology with human experts and assessors to verify the quality of the LLM-generated taxonomy. We also present an end-to-end pipeline that uses an LLM with human-in-the-loop to produce, refine, and use labels for user intent analysis in log data. Our method offers a scalable and adaptable way to analyze user intents in web-scale log data with minimal human effort. We demonstrate its effectiveness by uncovering new insights into user intents from search and chat logs from Bing.
Taking Search to Task
Jan 12, 2023
The importance of tasks in information retrieval (IR) has been long argued for, addressed in different ways, often ignored, and frequently revisited. For decades, scholars made a case for the role that a user's task plays in how and why that user engages in search and what a search system should do to assist. But for the most part, the IR community has been too focused on query processing and assuming a search task to be a collection of user queries, often ignoring if or how such an assumption addresses the users accomplishing their tasks. With emerging areas of conversational agents and proactive IR, understanding and addressing users' tasks has become more important than ever before. In this paper, we provide various perspectives on where the state-of-the-art is with regard to tasks in IR, what are some of the bottlenecks in deriving and using task information, and how do we go forward from here. In addition to covering relevant literature, the paper provides a synthesis of historical and current perspectives on understanding, extracting, and addressing task-focused search. To ground ongoing and future research in this area, we present a new framing device for tasks using a tree-like structure and various moves on that structure that allow different interpretations and applications. Presented as a combination of synthesis of ideas and past works, proposals for future research, and our perspectives on technical, social, and ethical considerations, this paper is meant to help revitalize the interest and future work in task-based IR.
MS-LaTTE: A Dataset of Where and When To-do Tasks are Completed
Nov 12, 2021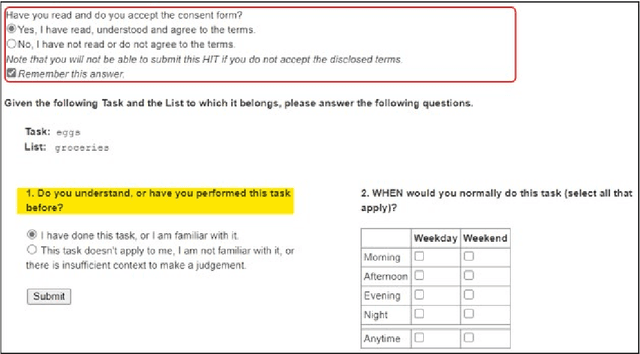
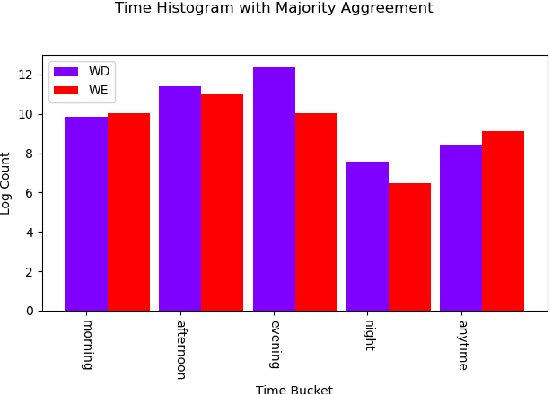
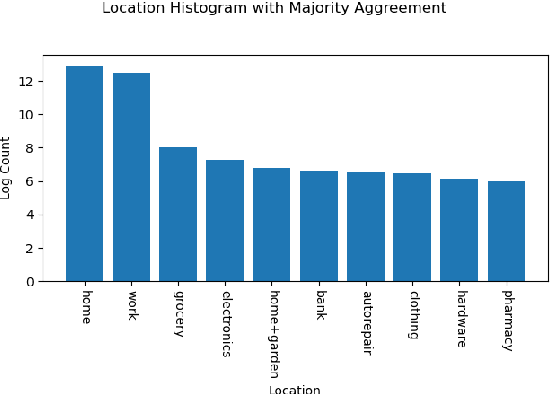
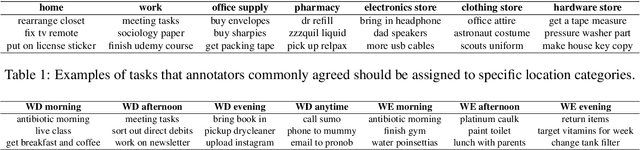
Tasks are a fundamental unit of work in the daily lives of people, who are increasingly using digital means to keep track of, organize, triage and act on them. These digital tools -- such as task management applications -- provide a unique opportunity to study and understand tasks and their connection to the real world, and through intelligent assistance, help people be more productive. By logging signals such as text, timestamp information, and social connectivity graphs, an increasingly rich and detailed picture of how tasks are created and organized, what makes them important, and who acts on them, can be progressively developed. Yet the context around actual task completion remains fuzzy, due to the basic disconnect between actions taken in the real world and telemetry recorded in the digital world. Thus, in this paper we compile and release a novel, real-life, large-scale dataset called MS-LaTTE that captures two core aspects of the context surrounding task completion: location and time. We describe our annotation framework and conduct a number of analyses on the data that were collected, demonstrating that it captures intuitive contextual properties for common tasks. Finally, we test the dataset on the two problems of predicting spatial and temporal task co-occurrence, concluding that predictors for co-location and co-time are both learnable, with a BERT fine-tuned model outperforming several other baselines. The MS-LaTTE dataset provides an opportunity to tackle many new modeling challenges in contextual task understanding and we hope that its release will spur future research in task intelligence more broadly.
CoSEM: Contextual and Semantic Embedding for App Usage Prediction
Aug 26, 2021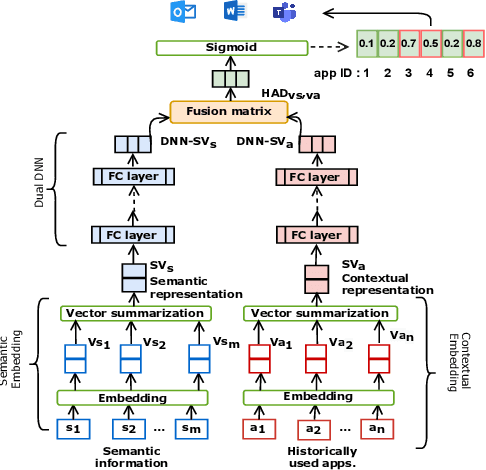
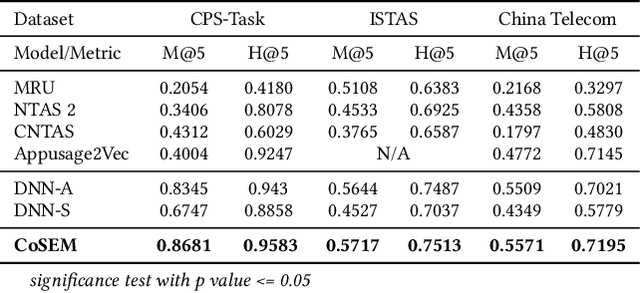
App usage prediction is important for smartphone system optimization to enhance user experience. Existing modeling approaches utilize historical app usage logs along with a wide range of semantic information to predict the app usage; however, they are only effective in certain scenarios and cannot be generalized across different situations. This paper address this problem by developing a model called Contextual and Semantic Embedding model for App Usage Prediction (CoSEM) for app usage prediction that leverages integration of 1) semantic information embedding and 2) contextual information embedding based on historical app usage of individuals. Extensive experiments show that the combination of semantic information and history app usage information enables our model to outperform the baselines on three real-world datasets, achieving an MRR score over 0.55,0.57,0.86 and Hit rate scores of more than 0.71, 0.75, and 0.95, respectively.