 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGoal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
Jun 30, 2023



Our goal is for robots to follow natural language instructions like "put the towel next to the microwave." But getting large amounts of labeled data, i.e. data that contains demonstrations of tasks labeled with the language instruction, is prohibitive. In contrast, obtaining policies that respond to image goals is much easier, because any autonomous trial or demonstration can be labeled in hindsight with its final state as the goal. In this work, we contribute a method that taps into joint image- and goal- conditioned policies with language using only a small amount of language data. Prior work has made progress on this using vision-language models or by jointly training language-goal-conditioned policies, but so far neither method has scaled effectively to real-world robot tasks without significant human annotation. Our method achieves robust performance in the real world by learning an embedding from the labeled data that aligns language not to the goal image, but rather to the desired change between the start and goal images that the instruction corresponds to. We then train a policy on this embedding: the policy benefits from all the unlabeled data, but the aligned embedding provides an interface for language to steer the policy. We show instruction following across a variety of manipulation tasks in different scenes, with generalization to language instructions outside of the labeled data. Videos and code for our approach can be found on our website: http://tiny.cc/grif .
PLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining
Mar 15, 2023



A rich representation is key to general robotic manipulation, but existing model architectures require a lot of data to learn it. Unfortunately, ideal robotic manipulation training data, which comes in the form of expert visuomotor demonstrations for a variety of annotated tasks, is scarce. In this work we propose PLEX, a transformer-based architecture that learns from task-agnostic visuomotor trajectories accompanied by a much larger amount of task-conditioned object manipulation videos -- a type of robotics-relevant data available in quantity. The key insight behind PLEX is that the trajectories with observations and actions help induce a latent feature space and train a robot to execute task-agnostic manipulation routines, while a diverse set of video-only demonstrations can efficiently teach the robot how to plan in this feature space for a wide variety of tasks. In contrast to most works on robotic manipulation pretraining, PLEX learns a generalizable sensorimotor multi-task policy, not just an observational representation. We also show that using relative positional encoding in PLEX's transformers further increases its data efficiency when learning from human-collected demonstrations. Experiments showcase \appr's generalization on Meta-World-v2 benchmark and establish state-of-the-art performance in challenging Robosuite environments.
The Sandbox Environment for Generalizable Agent Research (SEGAR)
Mar 19, 2022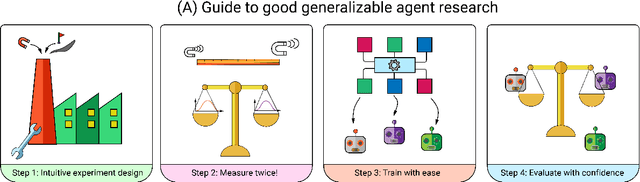
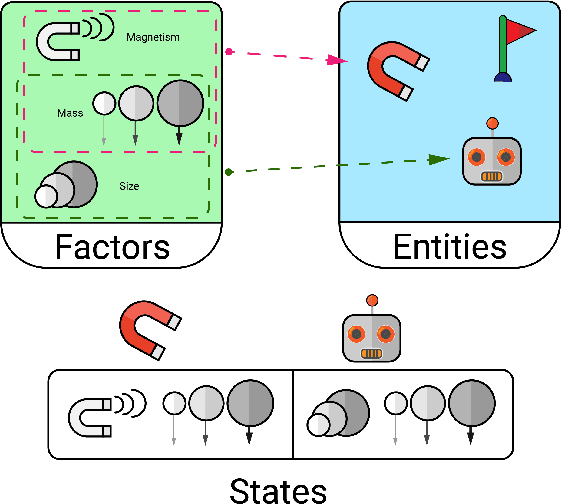
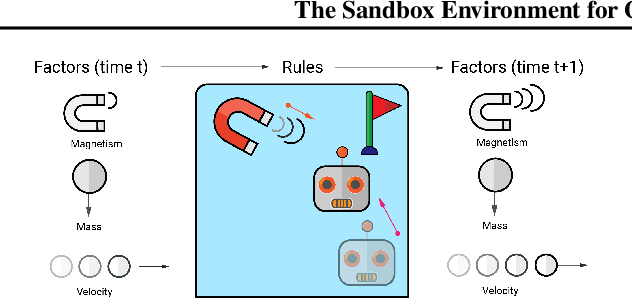
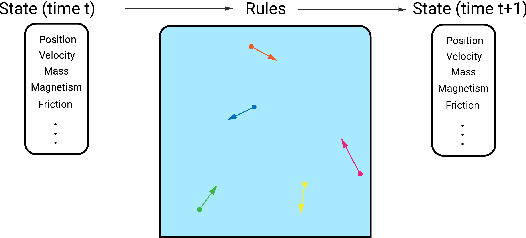
A broad challenge of research on generalization for sequential decision-making tasks in interactive environments is designing benchmarks that clearly landmark progress. While there has been notable headway, current benchmarks either do not provide suitable exposure nor intuitive control of the underlying factors, are not easy-to-implement, customizable, or extensible, or are computationally expensive to run. We built the Sandbox Environment for Generalizable Agent Research (SEGAR) with all of these things in mind. SEGAR improves the ease and accountability of generalization research in RL, as generalization objectives can be easy designed by specifying task distributions, which in turns allows the researcher to measure the nature of the generalization objective. We present an overview of SEGAR and how it contributes to these goals, as well as experiments that demonstrate a few types of research questions SEGAR can help answer.
Platform for Situated Intelligence
Mar 29, 2021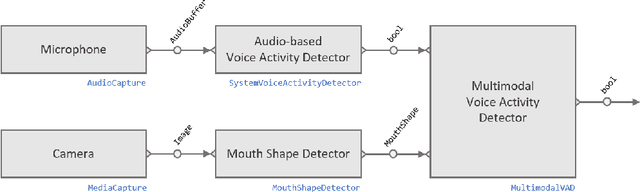

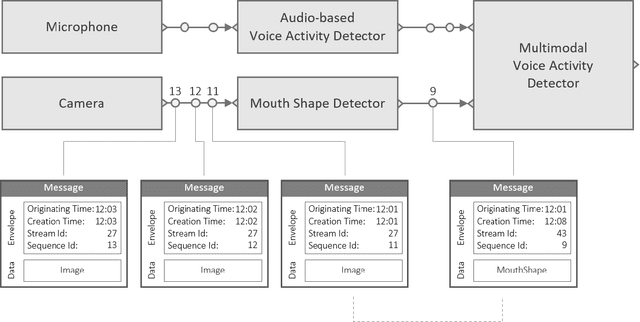

We introduce Platform for Situated Intelligence, an open-source framework created to support the rapid development and study of multimodal, integrative-AI systems. The framework provides infrastructure for sensing, fusing, and making inferences from temporal streams of data across different modalities, a set of tools that enable visualization and debugging, and an ecosystem of components that encapsulate a variety of perception and processing technologies. These assets jointly provide the means for rapidly constructing and refining multimodal, integrative-AI systems, while retaining the efficiency and performance characteristics required for deployment in open-world settings.