 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual use issues in the field of Natural Language Generation
Jan 11, 2025This report documents the results of a recent survey in the SIGGEN community, focusing on Dual Use issues in Natural Language Generation (NLG). SIGGEN is the Special Interest Group (SIG) of the Association for Computational Linguistics (ACL) for researchers working on NLG. The survey was prompted by the ACL executive board, which asked all SIGs to provide an overview of dual use issues within their respective subfields. The survey was sent out in October 2024 and the results were processed in January 2025. With 23 respondents, the survey is presumably not representative of all SIGGEN members, but at least this document offers a helpful resource for future discussions. This report is open to feedback from the SIGGEN community. Let me know if you have any questions or comments!
Evaluating Task-oriented Dialogue Systems: A Systematic Review of Measures, Constructs and their Operationalisations
Dec 21, 2023This review gives an extensive overview of evaluation methods for task-oriented dialogue systems, paying special attention to practical applications of dialogue systems, for example for customer service. The review (1) provides an overview of the used constructs and metrics in previous work, (2) discusses challenges in the context of dialogue system evaluation and (3) develops a research agenda for the future of dialogue system evaluation. We conducted a systematic review of four databases (ACL, ACM, IEEE and Web of Science), which after screening resulted in 122 studies. Those studies were carefully analysed for the constructs and methods they proposed for evaluation. We found a wide variety in both constructs and methods. Especially the operationalisation is not always clearly reported. We hope that future work will take a more critical approach to the operationalisation and specification of the used constructs. To work towards this aim, this review ends with recommendations for evaluation and suggestions for outstanding questions.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023



We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Evaluating NLG systems: A brief introduction
Mar 29, 2023This year the International Conference on Natural Language Generation (INLG) will feature an award for the paper with the best evaluation. The purpose of this award is to provide an incentive for NLG researchers to pay more attention to the way they assess the output of their systems. This essay provides a short introduction to evaluation in NLG, explaining key terms and distinctions.
Implicit causality in GPT-2: a case study
Dec 08, 2022This case study investigates the extent to which a language model (GPT-2) is able to capture native speakers' intuitions about implicit causality in a sentence completion task. We first reproduce earlier results (showing lower surprisal values for pronouns that are congruent with either the subject or object, depending on which one corresponds to the implicit causality bias of the verb), and then examine the effects of gender and verb frequency on model performance. Our second study examines the reasoning ability of GPT-2: is the model able to produce more sensible motivations for why the subject VERBed the object if the verbs have stronger causality biases? We also developed a methodology to avoid human raters being biased by obscenities and disfluencies generated by the model.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
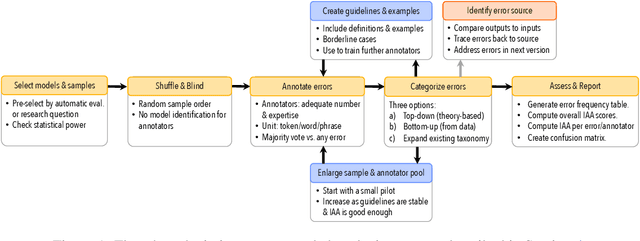
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.
Automatic Construction of Evaluation Suites for Natural Language Generation Datasets
Jun 16, 2021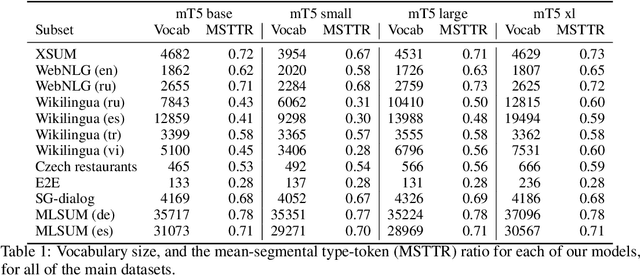
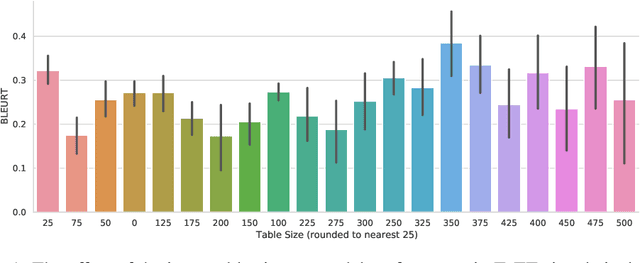
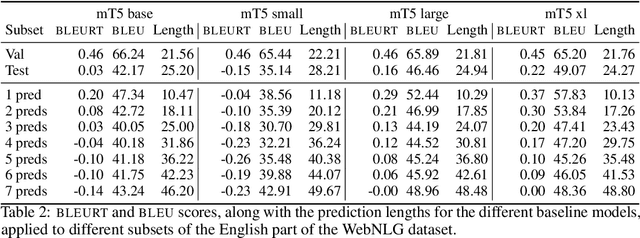
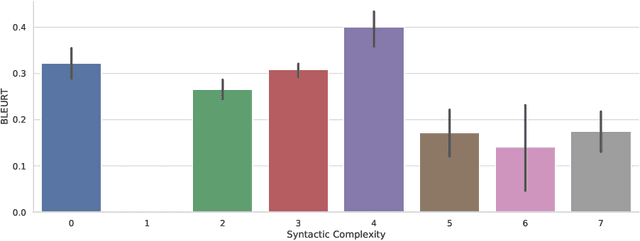
Machine learning approaches applied to NLP are often evaluated by summarizing their performance in a single number, for example accuracy. Since most test sets are constructed as an i.i.d. sample from the overall data, this approach overly simplifies the complexity of language and encourages overfitting to the head of the data distribution. As such, rare language phenomena or text about underrepresented groups are not equally included in the evaluation. To encourage more in-depth model analyses, researchers have proposed the use of multiple test sets, also called challenge sets, that assess specific capabilities of a model. In this paper, we develop a framework based on this idea which is able to generate controlled perturbations and identify subsets in text-to-scalar, text-to-text, or data-to-text settings. By applying this framework to the GEM generation benchmark, we propose an evaluation suite made of 80 challenge sets, demonstrate the kinds of analyses that it enables and shed light onto the limits of current generation models.
Preregistering NLP Research
Mar 23, 2021


Preregistration refers to the practice of specifying what you are going to do, and what you expect to find in your study, before carrying out the study. This practice is increasingly common in medicine and psychology, but is rarely discussed in NLP. This paper discusses preregistration in more detail, explores how NLP researchers could preregister their work, and presents several preregistration questions for different kinds of studies. Finally, we argue in favour of registered reports, which could provide firmer grounds for slow science in NLP research. The goal of this paper is to elicit a discussion in the NLP community, which we hope to synthesise into a general NLP preregistration form in future research.
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021



We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.
On the use of human reference data for evaluating automatic image descriptions
Jun 15, 2020Automatic image description systems are commonly trained and evaluated using crowdsourced, human-generated image descriptions. The best-performing system is then determined using some measure of similarity to the reference data (BLEU, Meteor, CIDER, etc). Thus, both the quality of the systems as well as the quality of the evaluation depends on the quality of the descriptions. As Section 2 will show, the quality of current image description datasets is insufficient. I argue that there is a need for more detailed guidelines that take into account the needs of visually impaired users, but also the feasibility of generating suitable descriptions. With high-quality data, evaluation of image description systems could use reference descriptions, but we should also look for alternatives.