 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Large Language Models Are Changing MOOC Essay Answers: A Comparison of Pre- and Post-LLM Responses
Apr 17, 2025The release of ChatGPT in late 2022 caused a flurry of activity and concern in the academic and educational communities. Some see the tool's ability to generate human-like text that passes at least cursory inspections for factual accuracy ``often enough'' a golden age of information retrieval and computer-assisted learning. Some, on the other hand, worry the tool may lead to unprecedented levels of academic dishonesty and cheating. In this work, we quantify some of the effects of the emergence of Large Language Models (LLMs) on online education by analyzing a multi-year dataset of student essay responses from a free university-level MOOC on AI ethics. Our dataset includes essays submitted both before and after ChatGPT's release. We find that the launch of ChatGPT coincided with significant changes in both the length and style of student essays, mirroring observations in other contexts such as academic publishing. We also observe -- as expected based on related public discourse -- changes in prevalence of key content words related to AI and LLMs, but not necessarily the general themes or topics discussed in the student essays as identified through (dynamic) topic modeling.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
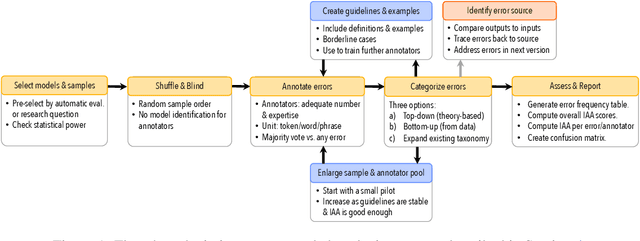
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.