 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Switching Criteria for Sim2Real Transfer of Robotic Fabric Manipulation Policies
Jul 02, 2022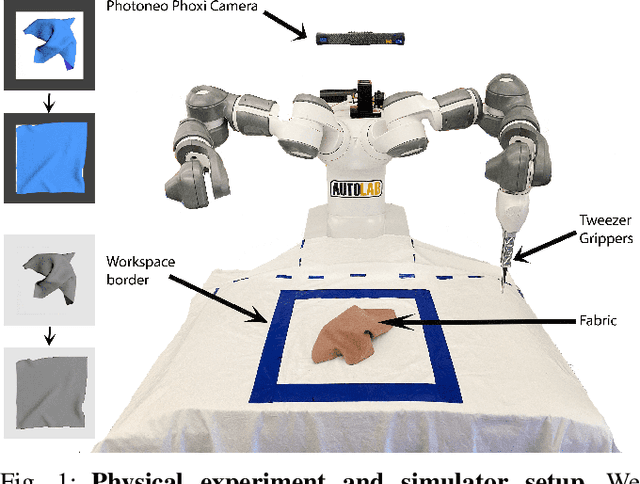
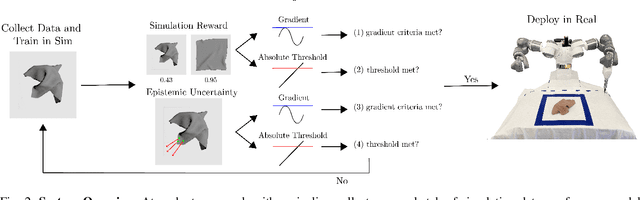

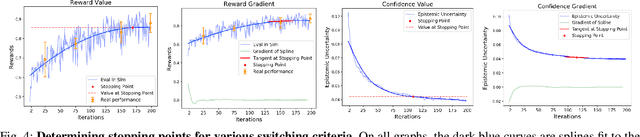
Simulation-to-reality transfer has emerged as a popular and highly successful method to train robotic control policies for a wide variety of tasks. However, it is often challenging to determine when policies trained in simulation are ready to be transferred to the physical world. Deploying policies that have been trained with very little simulation data can result in unreliable and dangerous behaviors on physical hardware. On the other hand, excessive training in simulation can cause policies to overfit to the visual appearance and dynamics of the simulator. In this work, we study strategies to automatically determine when policies trained in simulation can be reliably transferred to a physical robot. We specifically study these ideas in the context of robotic fabric manipulation, in which successful sim2real transfer is especially challenging due to the difficulties of precisely modeling the dynamics and visual appearance of fabric. Results in a fabric smoothing task suggest that our switching criteria correlate well with performance in real. In particular, our confidence-based switching criteria achieve average final fabric coverage of 87.2-93.7% within 55-60% of the total training budget. See https://tinyurl.com/lsc-case for code and supplemental materials.
Efficiently Learning Single-Arm Fling Motions to Smooth Garments
Jun 17, 2022

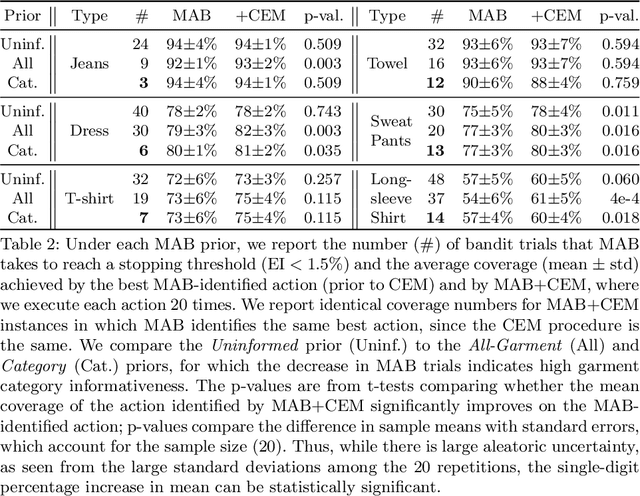
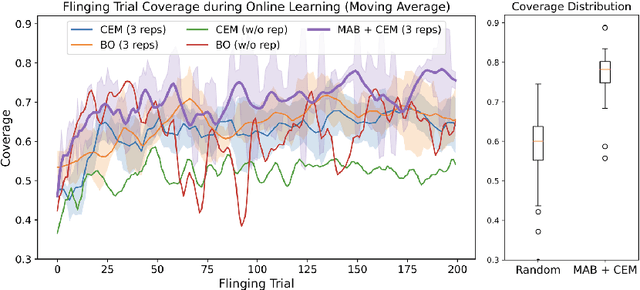
Recent work has shown that 2-arm "fling" motions can be effective for garment smoothing. We consider single-arm fling motions. Unlike 2-arm fling motions, which require little robot trajectory parameter tuning, single-arm fling motions are sensitive to trajectory parameters. We consider a single 6-DOF robot arm that learns fling trajectories to achieve high garment coverage. Given a garment grasp point, the robot explores different parameterized fling trajectories in physical experiments. To improve learning efficiency, we propose a coarse-to-fine learning method that first uses a multi-armed bandit (MAB) framework to efficiently find a candidate fling action, which it then refines via a continuous optimization method. Further, we propose novel training and execution-time stopping criteria based on fling outcome uncertainty. Compared to baselines, we show that the proposed method significantly accelerates learning. Moreover, with prior experience on similar garments collected through self-supervision, the MAB learning time for a new garment is reduced by up to 87%. We evaluate on 6 garment types: towels, T-shirts, long-sleeve shirts, dresses, sweat pants, and jeans. Results suggest that using prior experience, a robot requires under 30 minutes to learn a fling action for a novel garment that achieves 60-94% coverage.
Policy-Based Bayesian Experimental Design for Non-Differentiable Implicit Models
Mar 08, 2022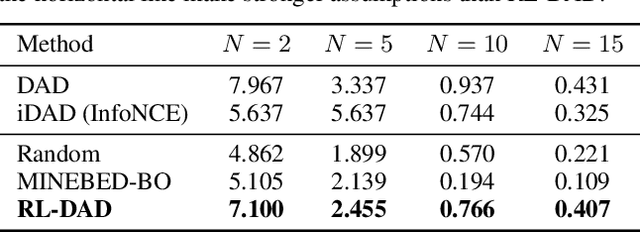
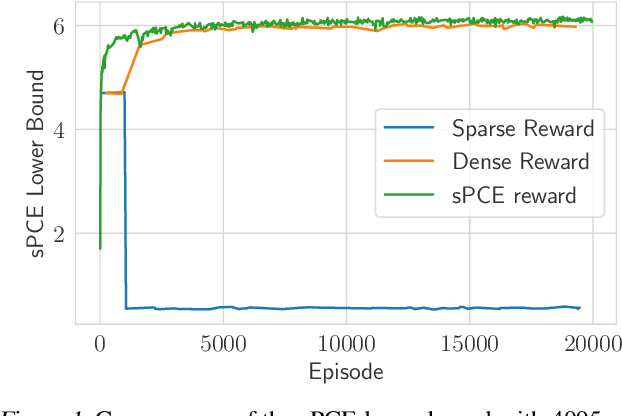
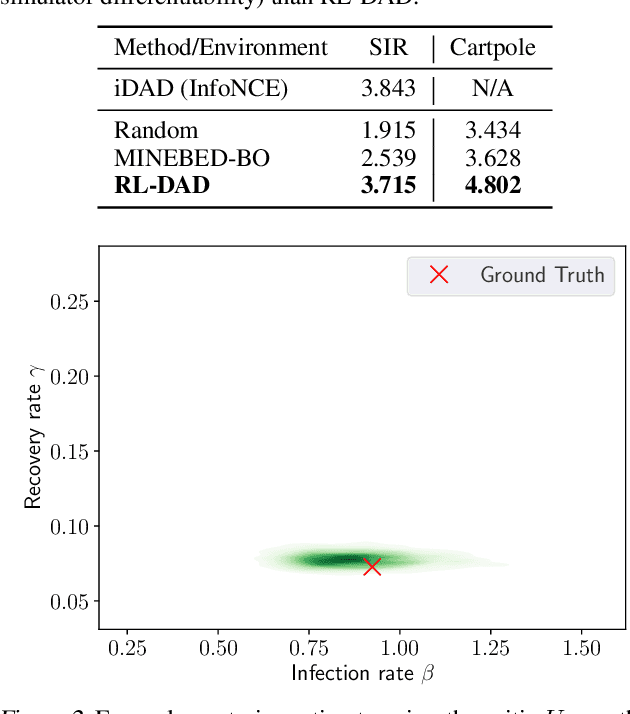
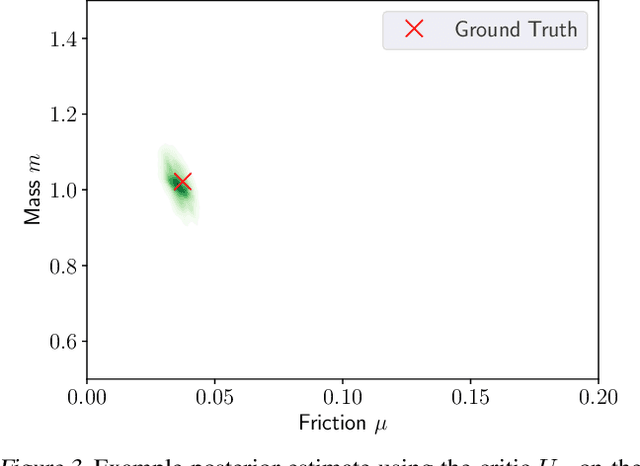
For applications in healthcare, physics, energy, robotics, and many other fields, designing maximally informative experiments is valuable, particularly when experiments are expensive, time-consuming, or pose safety hazards. While existing approaches can sequentially design experiments based on prior observation history, many of these methods do not extend to implicit models, where simulation is possible but computing the likelihood is intractable. Furthermore, they often require either significant online computation during deployment or a differentiable simulation system. We introduce Reinforcement Learning for Deep Adaptive Design (RL-DAD), a method for simulation-based optimal experimental design for non-differentiable implicit models. RL-DAD extends prior work in policy-based Bayesian Optimal Experimental Design (BOED) by reformulating it as a Markov Decision Process with a reward function based on likelihood-free information lower bounds, which is used to learn a policy via deep reinforcement learning. The learned design policy maps prior histories to experiment designs offline and can be quickly deployed during online execution. We evaluate RL-DAD and find that it performs competitively with baselines on three benchmarks.
ThriftyDAgger: Budget-Aware Novelty and Risk Gating for Interactive Imitation Learning
Sep 17, 2021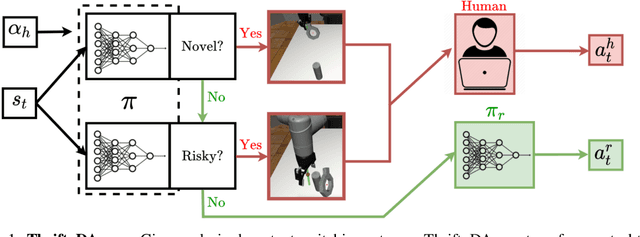
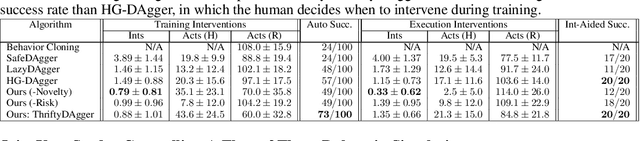
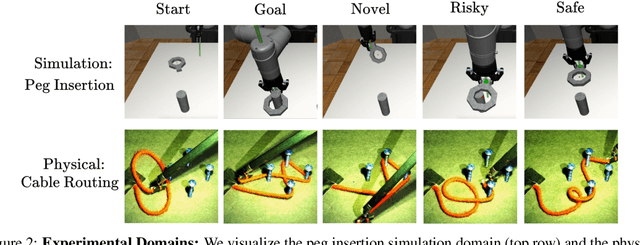

Effective robot learning often requires online human feedback and interventions that can cost significant human time, giving rise to the central challenge in interactive imitation learning: is it possible to control the timing and length of interventions to both facilitate learning and limit burden on the human supervisor? This paper presents ThriftyDAgger, an algorithm for actively querying a human supervisor given a desired budget of human interventions. ThriftyDAgger uses a learned switching policy to solicit interventions only at states that are sufficiently (1) novel, where the robot policy has no reference behavior to imitate, or (2) risky, where the robot has low confidence in task completion. To detect the latter, we introduce a novel metric for estimating risk under the current robot policy. Experiments in simulation and on a physical cable routing experiment suggest that ThriftyDAgger's intervention criteria balances task performance and supervisor burden more effectively than prior algorithms. ThriftyDAgger can also be applied at execution time, where it achieves a 100% success rate on both the simulation and physical tasks. A user study (N=10) in which users control a three-robot fleet while also performing a concentration task suggests that ThriftyDAgger increases human and robot performance by 58% and 80% respectively compared to the next best algorithm while reducing supervisor burden.
Untangling Dense Non-Planar Knots by Learning Manipulation Features and Recovery Policies
Jun 29, 2021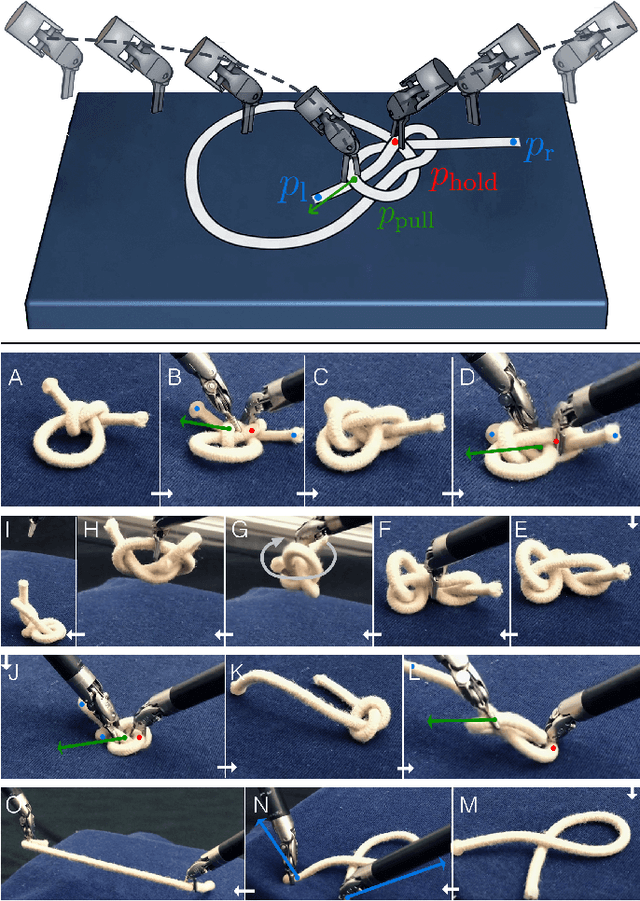
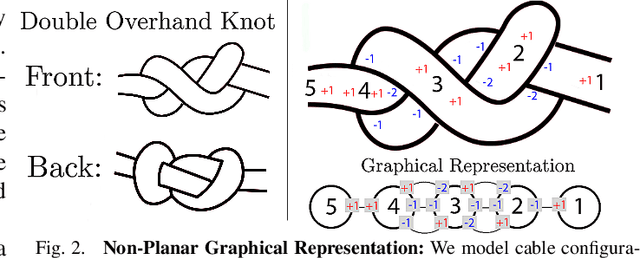
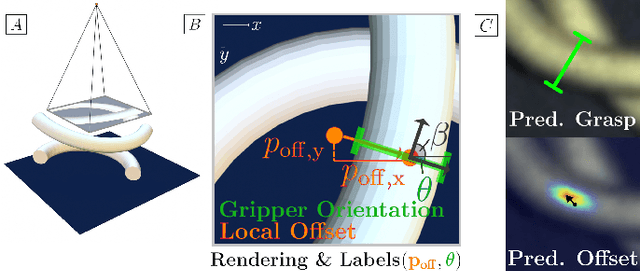
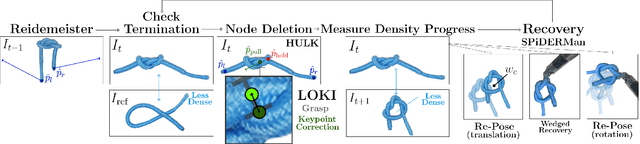
Robot manipulation for untangling 1D deformable structures such as ropes, cables, and wires is challenging due to their infinite dimensional configuration space, complex dynamics, and tendency to self-occlude. Analytical controllers often fail in the presence of dense configurations, due to the difficulty of grasping between adjacent cable segments. We present two algorithms that enhance robust cable untangling, LOKI and SPiDERMan, which operate alongside HULK, a high-level planner from prior work. LOKI uses a learned model of manipulation features to refine a coarse grasp keypoint prediction to a precise, optimized location and orientation, while SPiDERMan uses a learned model to sense task progress and apply recovery actions. We evaluate these algorithms in physical cable untangling experiments with 336 knots and over 1500 actions on real cables using the da Vinci surgical robot. We find that the combination of HULK, LOKI, and SPiDERMan is able to untangle dense overhand, figure-eight, double-overhand, square, bowline, granny, stevedore, and triple-overhand knots. The composition of these methods successfully untangles a cable from a dense initial configuration in 68.3% of 60 physical experiments and achieves 50% higher success rates than baselines from prior work. Supplementary material, code, and videos can be found at https://tinyurl.com/rssuntangling.
Disentangling Dense Multi-Cable Knots
Jun 04, 2021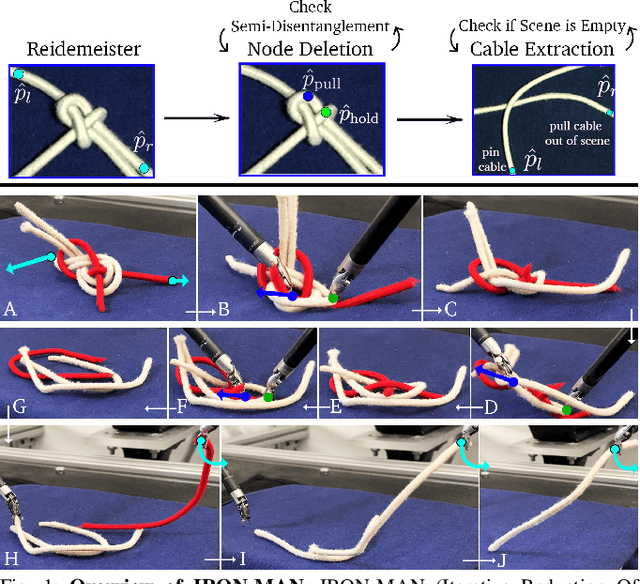
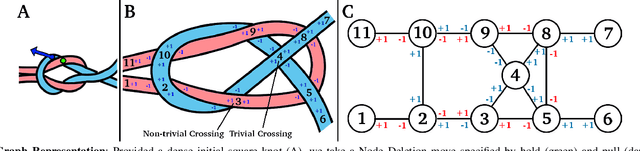
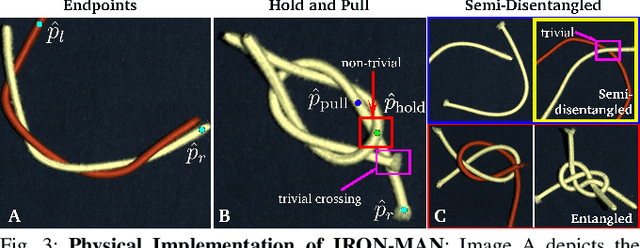

Disentangling two or more cables requires many steps to remove crossings between and within cables. We formalize the problem of disentangling multiple cables and present an algorithm, Iterative Reduction Of Non-planar Multiple cAble kNots (IRON-MAN), that outputs robot actions to remove crossings from multi-cable knotted structures. We instantiate this algorithm with a learned perception system, inspired by prior work in single-cable untying that given an image input, can disentangle two-cable twists, three-cable braids, and knots of two or three cables, such as overhand, square, carrick bend, sheet bend, crown, and fisherman's knots. IRON-MAN keeps track of task-relevant keypoints corresponding to target cable endpoints and crossings and iteratively disentangles the cables by identifying and undoing crossings that are critical to knot structure. Using a da Vinci surgical robot, we experimentally evaluate the effectiveness of IRON-MAN on untangling multi-cable knots of types that appear in the training data, as well as generalizing to novel classes of multi-cable knots. Results suggest that IRON-MAN is effective in disentangling knots involving up to three cables with 80.5% success and generalizing to knot types that are not present during training, with cables of both distinct or identical colors.
LazyDAgger: Reducing Context Switching in Interactive Imitation Learning
Mar 31, 2021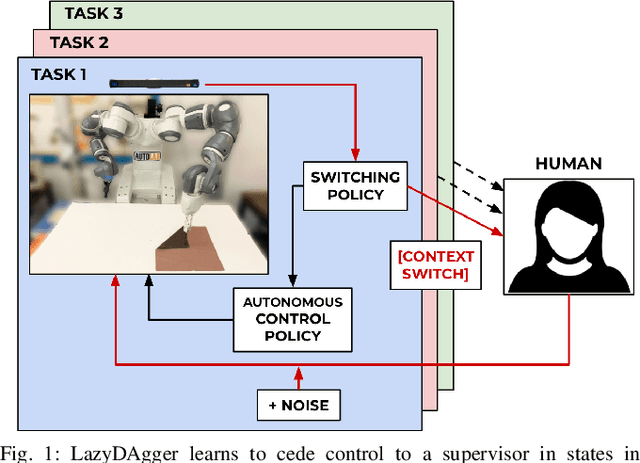
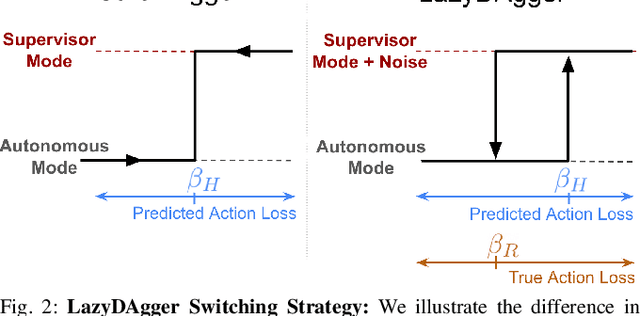
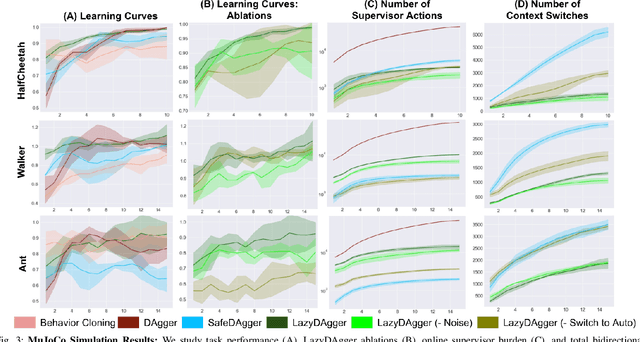
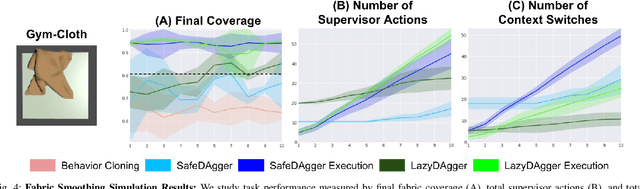
Corrective interventions while a robot is learning to automate a task provide an intuitive method for a human supervisor to assist the robot and convey information about desired behavior. However, these interventions can impose significant burden on a human supervisor, as each intervention interrupts other work the human is doing, incurs latency with each context switch between supervisor and autonomous control, and requires time to perform. We present LazyDAgger, which extends the interactive imitation learning (IL) algorithm SafeDAgger to reduce context switches between supervisor and autonomous control. We find that LazyDAgger improves the performance and robustness of the learned policy during both learning and execution while limiting burden on the supervisor. Simulation experiments suggest that LazyDAgger can reduce context switches by an average of 60% over SafeDAgger on 3 continuous control tasks while maintaining state-of-the-art policy performance. In physical fabric manipulation experiments with an ABB YuMi robot, LazyDAgger reduces context switches by 60% while achieving a 60% higher success rate than SafeDAgger at execution time.
ROIAL: Region of Interest Active Learning for Characterizing Exoskeleton Gait Preference Landscapes
Nov 09, 2020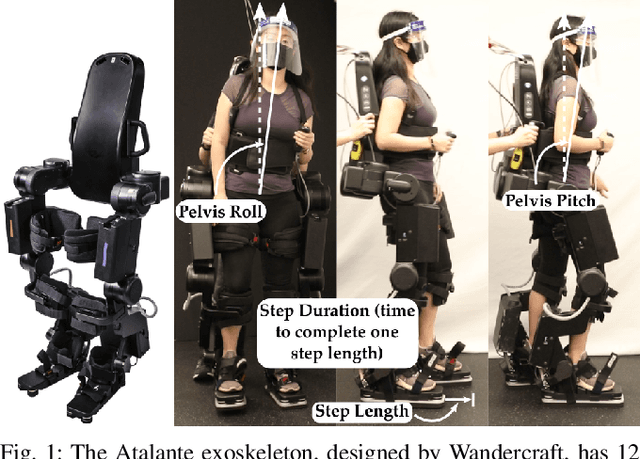

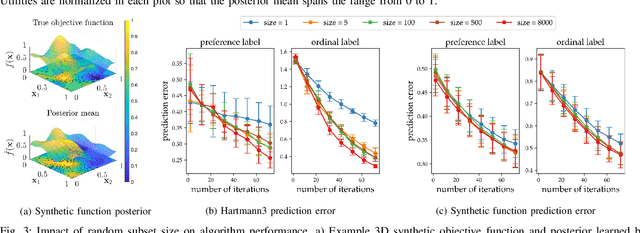
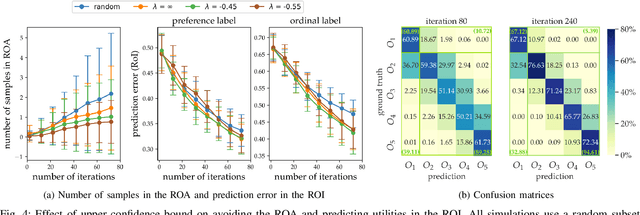
Characterizing what types of exoskeleton gaits are comfortable for users, and understanding the science of walking more generally, require recovering a user's utility landscape. Learning these landscapes is challenging, as walking trajectories are defined by numerous gait parameters, data collection from human trials is expensive, and user safety and comfort must be ensured. This work proposes the Region of Interest Active Learning (ROIAL) framework, which actively learns each user's underlying utility function over a region of interest that ensures safety and comfort. ROIAL learns from ordinal and preference feedback, which are more reliable feedback mechanisms than absolute numerical scores. The algorithm's performance is evaluated both in simulation and experimentally for three able-bodied subjects walking inside of a lower-body exoskeleton. ROIAL learns Bayesian posteriors that predict each exoskeleton user's utility landscape across four exoskeleton gait parameters. The algorithm discovers both commonalities and discrepancies across users' gait preferences and identifies the gait parameters that most influenced user feedback. These results demonstrate the feasibility of recovering gait utility landscapes from limited human trials.
Human Preference-Based Learning for High-dimensional Optimization of Exoskeleton Walking Gaits
Mar 13, 2020
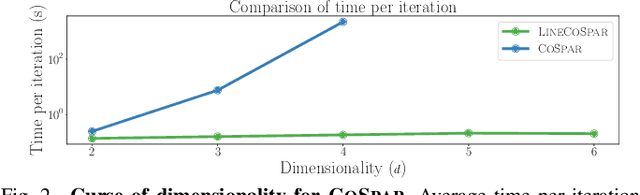
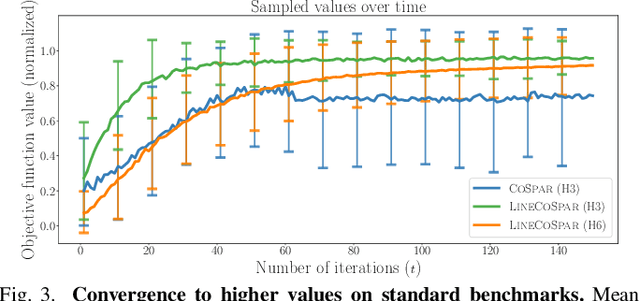
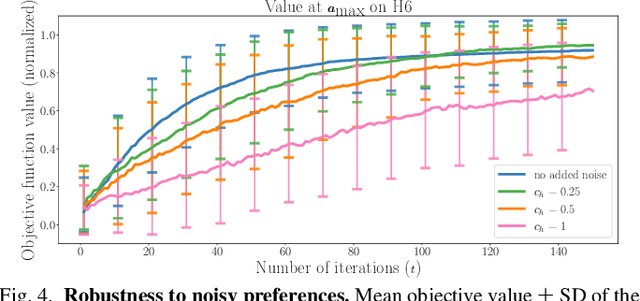
Understanding users' gait preferences of a lower-body exoskeleton requires optimizing over the high-dimensional gait parameter space. However, existing preference-based learning methods have only explored low-dimensional domains due to computational limitations. To learn user preferences in high dimensions, this work presents LineCoSpar, a human-in-the-loop preference-based framework that enables optimization over many parameters by iteratively exploring one-dimensional subspaces. Additionally, this work identifies gait attributes that characterize broader preferences across users. In simulations and human trials, we empirically verify that LineCoSpar is a sample-efficient approach for high-dimensional preference optimization. Our analysis of the experimental data reveals a correspondence between human preferences and objective measures of dynamic stability, while also highlighting inconsistencies in the utility functions underlying different users' gait preferences. This has implications for exoskeleton gait synthesis, an active field with applications to clinical use and patient rehabilitation.
Preference-Based Learning for Exoskeleton Gait Optimization
Sep 26, 2019

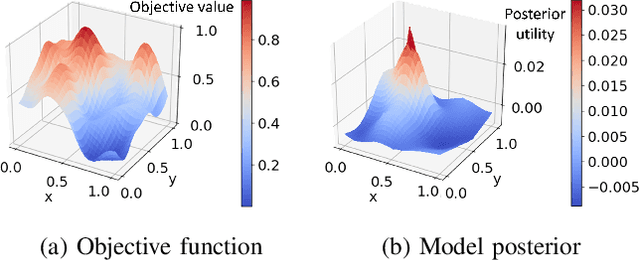
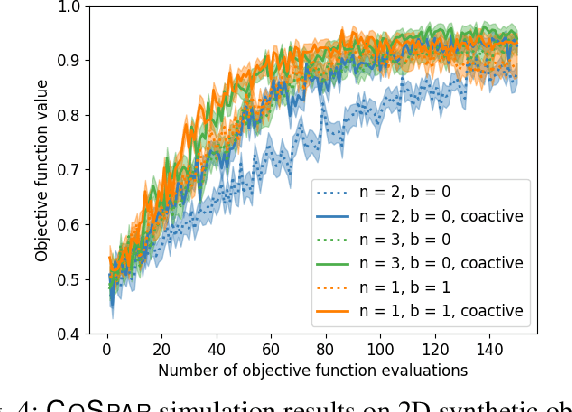
This paper presents a personalized gait optimization framework for lower-body exoskeletons. Rather than optimizing numerical objectives such as the mechanical cost of transport, our approach directly learns from user preferences, e.g., for comfort. Building upon work in preference-based interactive learning, we present the CoSpar algorithm. CoSpar prompts the user to give pairwise preferences between trials and suggest improvements; as exoskeleton walking is a non-intuitive behavior, users can provide preferences more easily and reliably than numerical feedback. We show that CoSpar performs competitively in simulation and demonstrate a prototype implementation of CoSpar on a lower-body exoskeleton to optimize human walking trajectory features. In the experiments, CoSpar consistently found user-preferred parameters of the exoskeleton's walking gait, which suggests that it is a promising starting point for adapting and personalizing exoskeletons (or other assistive devices) to individual users.