 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsetGAN for Full-Body Image Generation
Mar 14, 2022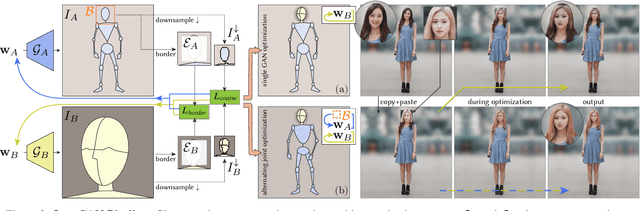



While GANs can produce photo-realistic images in ideal conditions for certain domains, the generation of full-body human images remains difficult due to the diversity of identities, hairstyles, clothing, and the variance in pose. Instead of modeling this complex domain with a single GAN, we propose a novel method to combine multiple pretrained GANs, where one GAN generates a global canvas (e.g., human body) and a set of specialized GANs, or insets, focus on different parts (e.g., faces, shoes) that can be seamlessly inserted onto the global canvas. We model the problem as jointly exploring the respective latent spaces such that the generated images can be combined, by inserting the parts from the specialized generators onto the global canvas, without introducing seams. We demonstrate the setup by combining a full body GAN with a dedicated high-quality face GAN to produce plausible-looking humans. We evaluate our results with quantitative metrics and user studies.
Third Time's the Charm? Image and Video Editing with StyleGAN3
Jan 31, 2022StyleGAN is arguably one of the most intriguing and well-studied generative models, demonstrating impressive performance in image generation, inversion, and manipulation. In this work, we explore the recent StyleGAN3 architecture, compare it to its predecessor, and investigate its unique advantages, as well as drawbacks. In particular, we demonstrate that while StyleGAN3 can be trained on unaligned data, one can still use aligned data for training, without hindering the ability to generate unaligned imagery. Next, our analysis of the disentanglement of the different latent spaces of StyleGAN3 indicates that the commonly used W/W+ spaces are more entangled than their StyleGAN2 counterparts, underscoring the benefits of using the StyleSpace for fine-grained editing. Considering image inversion, we observe that existing encoder-based techniques struggle when trained on unaligned data. We therefore propose an encoding scheme trained solely on aligned data, yet can still invert unaligned images. Finally, we introduce a novel video inversion and editing workflow that leverages the capabilities of a fine-tuned StyleGAN3 generator to reduce texture sticking and expand the field of view of the edited video.
GeoFill: Reference-Based Image Inpainting of Scenes with Complex Geometry
Jan 20, 2022

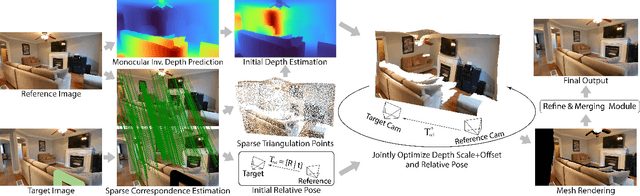
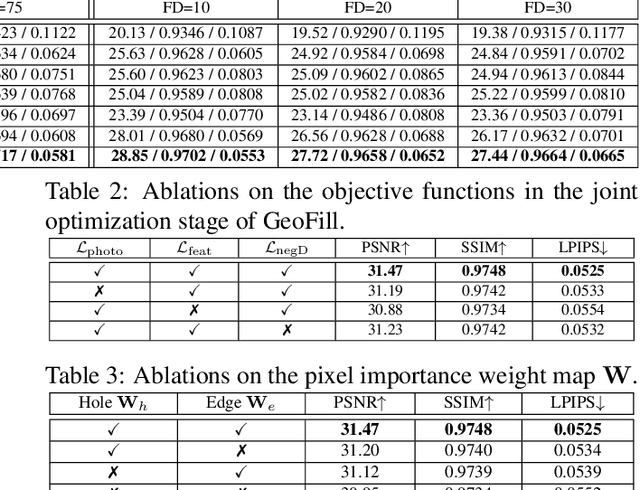
Reference-guided image inpainting restores image pixels by leveraging the content from another reference image. The previous state-of-the-art, TransFill, warps the source image with multiple homographies, and fuses them together for hole filling. Inspired by structure from motion pipelines and recent progress in monocular depth estimation, we propose a more principled approach that does not require heuristic planar assumptions. We leverage a monocular depth estimate and predict relative pose between cameras, then align the reference image to the target by a differentiable 3D reprojection and a joint optimization of relative pose and depth map scale and offset. Our approach achieves state-of-the-art performance on both RealEstate10K and MannequinChallenge dataset with large baselines, complex geometry and extreme camera motions. We experimentally verify our approach is also better at handling large holes.
Ensembling Off-the-shelf Models for GAN Training
Jan 18, 2022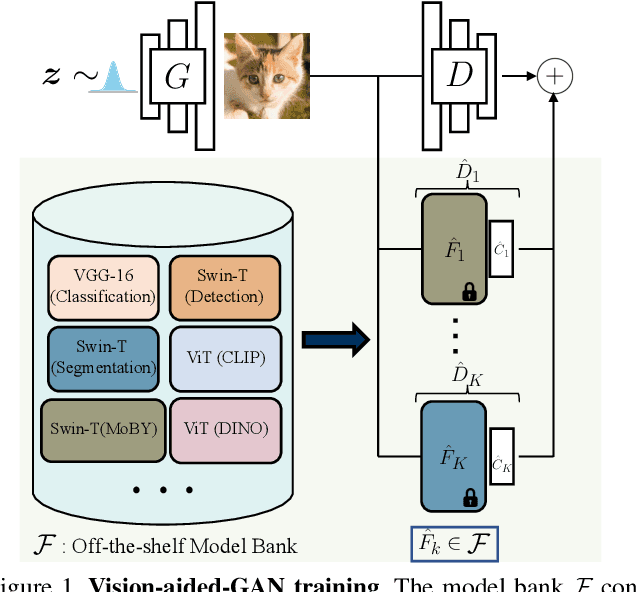
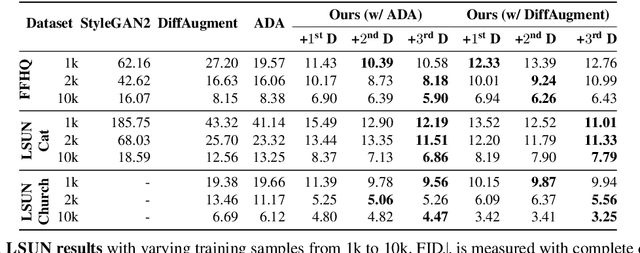
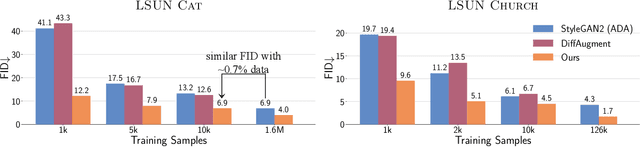
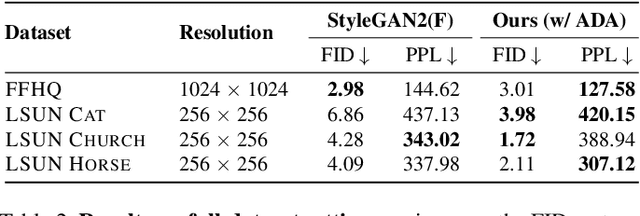
The advent of large-scale training has produced a cornucopia of powerful visual recognition models. However, generative models, such as GANs, have traditionally been trained from scratch in an unsupervised manner. Can the collective "knowledge" from a large bank of pretrained vision models be leveraged to improve GAN training? If so, with so many models to choose from, which one(s) should be selected, and in what manner are they most effective? We find that pretrained computer vision models can significantly improve performance when used in an ensemble of discriminators. Notably, the particular subset of selected models greatly affects performance. We propose an effective selection mechanism, by probing the linear separability between real and fake samples in pretrained model embeddings, choosing the most accurate model, and progressively adding it to the discriminator ensemble. Interestingly, our method can improve GAN training in both limited data and large-scale settings. Given only 10k training samples, our FID on LSUN Cat matches the StyleGAN2 trained on 1.6M images. On the full dataset, our method improves FID by 1.5x to 2x on cat, church, and horse categories of LSUN.
StyleSDF: High-Resolution 3D-Consistent Image and Geometry Generation
Dec 21, 2021
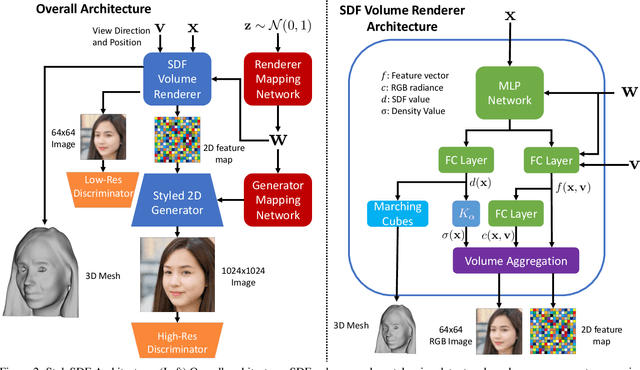


We introduce a high resolution, 3D-consistent image and shape generation technique which we call StyleSDF. Our method is trained on single-view RGB data only, and stands on the shoulders of StyleGAN2 for image generation, while solving two main challenges in 3D-aware GANs: 1) high-resolution, view-consistent generation of the RGB images, and 2) detailed 3D shape. We achieve this by merging a SDF-based 3D representation with a style-based 2D generator. Our 3D implicit network renders low-resolution feature maps, from which the style-based network generates view-consistent, 1024x1024 images. Notably, our SDF-based 3D modeling defines detailed 3D surfaces, leading to consistent volume rendering. Our method shows higher quality results compared to state of the art in terms of visual and geometric quality.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021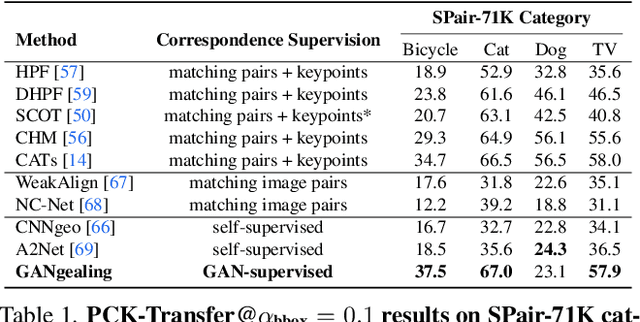
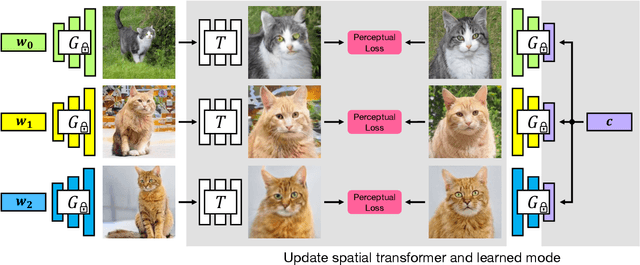


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
StyleAlign: Analysis and Applications of Aligned StyleGAN Models
Oct 21, 2021
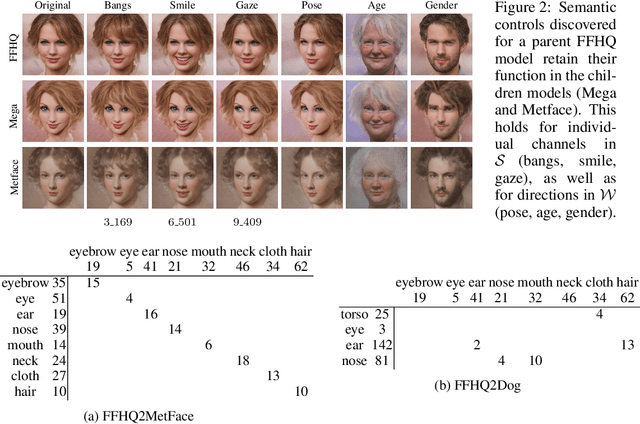
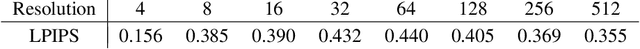

In this paper, we perform an in-depth study of the properties and applications of aligned generative models. We refer to two models as aligned if they share the same architecture, and one of them (the child) is obtained from the other (the parent) via fine-tuning to another domain, a common practice in transfer learning. Several works already utilize some basic properties of aligned StyleGAN models to perform image-to-image translation. Here, we perform the first detailed exploration of model alignment, also focusing on StyleGAN. First, we empirically analyze aligned models and provide answers to important questions regarding their nature. In particular, we find that the child model's latent spaces are semantically aligned with those of the parent, inheriting incredibly rich semantics, even for distant data domains such as human faces and churches. Second, equipped with this better understanding, we leverage aligned models to solve a diverse set of tasks. In addition to image translation, we demonstrate fully automatic cross-domain image morphing. We further show that zero-shot vision tasks may be performed in the child domain, while relying exclusively on supervision in the parent domain. We demonstrate qualitatively and quantitatively that our approach yields state-of-the-art results, while requiring only simple fine-tuning and inversion.
STALP: Style Transfer with Auxiliary Limited Pairing
Oct 20, 2021We present an approach to example-based stylization of images that uses a single pair of a source image and its stylized counterpart. We demonstrate how to train an image translation network that can perform real-time semantically meaningful style transfer to a set of target images with similar content as the source image. A key added value of our approach is that it considers also consistency of target images during training. Although those have no stylized counterparts, we constrain the translation to keep the statistics of neural responses compatible with those extracted from the stylized source. In contrast to concurrent techniques that use a similar input, our approach better preserves important visual characteristics of the source style and can deliver temporally stable results without the need to explicitly handle temporal consistency. We demonstrate its practical utility on various applications including video stylization, style transfer to panoramas, faces, and 3D models.
Real Image Inversion via Segments
Oct 12, 2021



In this short report, we present a simple, yet effective approach to editing real images via generative adversarial networks (GAN). Unlike previous techniques, that treat all editing tasks as an operation that affects pixel values in the entire image in our approach we cut up the image into a set of smaller segments. For those segments corresponding latent codes of a generative network can be estimated with greater accuracy due to the lower number of constraints. When codes are altered by the user the content in the image is manipulated locally while the rest of it remains unaffected. Thanks to this property the final edited image better retains the original structures and thus helps to preserve natural look.
Collaging Class-specific GANs for Semantic Image Synthesis
Oct 08, 2021
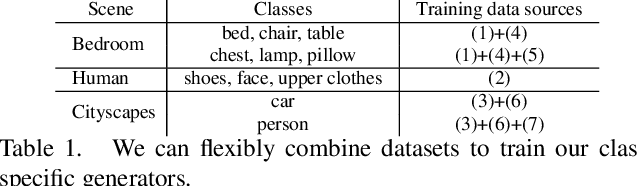
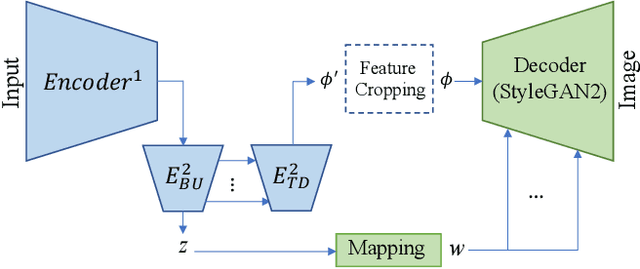
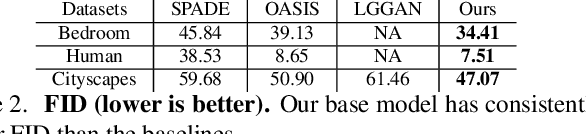
We propose a new approach for high resolution semantic image synthesis. It consists of one base image generator and multiple class-specific generators. The base generator generates high quality images based on a segmentation map. To further improve the quality of different objects, we create a bank of Generative Adversarial Networks (GANs) by separately training class-specific models. This has several benefits including -- dedicated weights for each class; centrally aligned data for each model; additional training data from other sources, potential of higher resolution and quality; and easy manipulation of a specific object in the scene. Experiments show that our approach can generate high quality images in high resolution while having flexibility of object-level control by using class-specific generators.