 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep CG2Real: Synthetic-to-Real Translation via Image Disentanglement
Paper and Code
Mar 27, 2020
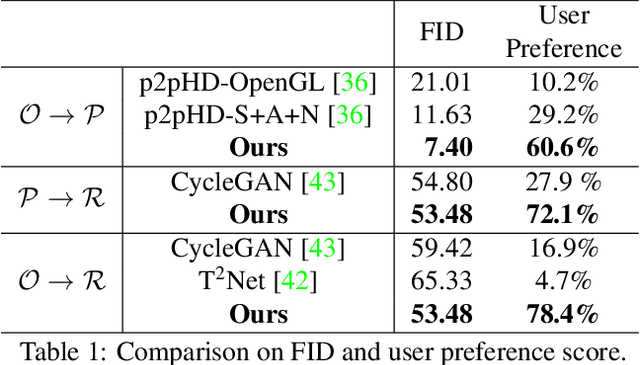
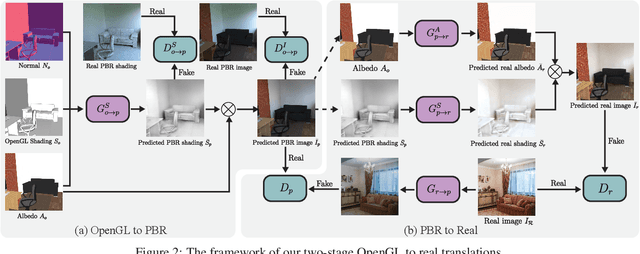
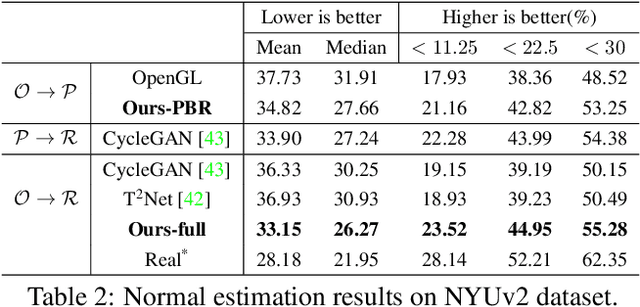
We present a method to improve the visual realism of low-quality, synthetic images, e.g. OpenGL renderings. Training an unpaired synthetic-to-real translation network in image space is severely under-constrained and produces visible artifacts. Instead, we propose a semi-supervised approach that operates on the disentangled shading and albedo layers of the image. Our two-stage pipeline first learns to predict accurate shading in a supervised fashion using physically-based renderings as targets, and further increases the realism of the textures and shading with an improved CycleGAN network. Extensive evaluations on the SUNCG indoor scene dataset demonstrate that our approach yields more realistic images compared to other state-of-the-art approaches. Furthermore, networks trained on our generated "real" images predict more accurate depth and normals than domain adaptation approaches, suggesting that improving the visual realism of the images can be more effective than imposing task-specific losses.