 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Language Models Hallucinate
Sep 04, 2025Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such "hallucinations" persist even in state-of-the-art systems and undermine trust. We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline. Hallucinations need not be mysterious -- they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures. We then argue that hallucinations persist due to the way most evaluations are graded -- language models are optimized to be good test-takers, and guessing when uncertain improves test performance. This "epidemic" of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
A Taxonomy of Transcendence
Aug 25, 2025Although language models are trained to mimic humans, the resulting systems display capabilities beyond the scope of any one person. To understand this phenomenon, we use a controlled setting to identify properties of the training data that lead a model to transcend the performance of its data sources. We build on previous work to outline three modes of transcendence, which we call skill denoising, skill selection, and skill generalization. We then introduce a knowledge graph-based setting in which simulated experts generate data based on their individual expertise. We highlight several aspects of data diversity that help to enable the model's transcendent capabilities. Additionally, our data generation setting offers a controlled testbed that we hope is valuable for future research in the area.
Enhancing Channel-Independent Time-Series Forecasting via Cross-Variate Patch Embedding
May 19, 2025Transformers have recently gained popularity in time series forecasting due to their ability to capture long-term dependencies. However, many existing models focus only on capturing temporal dependencies while omitting intricate relationships between variables. Recent models have tried tackling this by explicitly modeling both cross-time and cross-variate dependencies through a sequential or unified attention mechanism, but they are entirely channel dependent (CD) across all layers, making them potentially susceptible to overfitting. To address this, we propose Cross-Variate Patch Embeddings (CVPE), a lightweight CD module that injects cross-variate context into channel-independent (CI) models by simply modifying the patch embedding process. We achieve this by adding a learnable positional encoding and a lightweight router-attention block to the vanilla patch embedding layer. We then integrate CVPE into Time-LLM, a multimodal CI forecasting model, to demonstrate its effectiveness in capturing cross-variate dependencies and enhance the CI model's performance. Extensive experimental results on seven real-world datasets show that our enhanced Time-LLM outperforms the original baseline model simply by incorporating the CVPE module, with no other changes.
Creating a Cooperative AI Policymaking Platform through Open Source Collaboration
Dec 09, 2024

Advances in artificial intelligence (AI) present significant risks and opportunities, requiring improved governance to mitigate societal harms and promote equitable benefits. Current incentive structures and regulatory delays may hinder responsible AI development and deployment, particularly in light of the transformative potential of large language models (LLMs). To address these challenges, we propose developing the following three contributions: (1) a large multimodal text and economic-timeseries foundation model that integrates economic and natural language policy data for enhanced forecasting and decision-making, (2) algorithmic mechanisms for eliciting diverse and representative perspectives, enabling the creation of data-driven public policy recommendations, and (3) an AI-driven web platform for supporting transparent, inclusive, and data-driven policymaking.
Proof Flow: Preliminary Study on Generative Flow Network Language Model Tuning for Formal Reasoning
Oct 17, 2024



Reasoning is a fundamental substrate for solving novel and complex problems. Deliberate efforts in learning and developing frameworks around System 2 reasoning have made great strides, yet problems of sufficient complexity remain largely out of reach for open models. To address this gap, we examine the potential of Generative Flow Networks as a fine-tuning method for LLMs to unlock advanced reasoning capabilities. In this paper, we present a proof of concept in the domain of formal reasoning, specifically in the Neural Theorem Proving (NTP) setting, where proofs specified in a formal language such as Lean can be deterministically and objectively verified. Unlike classical reward-maximization reinforcement learning, which frequently over-exploits high-reward actions and fails to effectively explore the state space, GFlowNets have emerged as a promising approach for sampling compositional objects, improving generalization, and enabling models to maintain diverse hypotheses. Our early results demonstrate GFlowNet fine-tuning's potential for enhancing model performance in a search setting, which is especially relevant given the paradigm shift towards inference time compute scaling and "thinking slowly."
Large Legislative Models: Towards Efficient AI Policymaking in Economic Simulations
Oct 10, 2024



The improvement of economic policymaking presents an opportunity for broad societal benefit, a notion that has inspired research towards AI-driven policymaking tools. AI policymaking holds the potential to surpass human performance through the ability to process data quickly at scale. However, existing RL-based methods exhibit sample inefficiency, and are further limited by an inability to flexibly incorporate nuanced information into their decision-making processes. Thus, we propose a novel method in which we instead utilize pre-trained Large Language Models (LLMs), as sample-efficient policymakers in socially complex multi-agent reinforcement learning (MARL) scenarios. We demonstrate significant efficiency gains, outperforming existing methods across three environments. Our code is available at https://github.com/hegasz/large-legislative-models.
Global Human-guided Counterfactual Explanations for Molecular Properties via Reinforcement Learning
Jun 19, 2024Counterfactual explanations of Graph Neural Networks (GNNs) offer a powerful way to understand data that can naturally be represented by a graph structure. Furthermore, in many domains, it is highly desirable to derive data-driven global explanations or rules that can better explain the high-level properties of the models and data in question. However, evaluating global counterfactual explanations is hard in real-world datasets due to a lack of human-annotated ground truth, which limits their use in areas like molecular sciences. Additionally, the increasing scale of these datasets provides a challenge for random search-based methods. In this paper, we develop a novel global explanation model RLHEX for molecular property prediction. It aligns the counterfactual explanations with human-defined principles, making the explanations more interpretable and easy for experts to evaluate. RLHEX includes a VAE-based graph generator to generate global explanations and an adapter to adjust the latent representation space to human-defined principles. Optimized by Proximal Policy Optimization (PPO), the global explanations produced by RLHEX cover 4.12% more input graphs and reduce the distance between the counterfactual explanation set and the input set by 0.47% on average across three molecular datasets. RLHEX provides a flexible framework to incorporate different human-designed principles into the counterfactual explanation generation process, aligning these explanations with domain expertise. The code and data are released at https://github.com/dqwang122/RLHEX.
Transcendence: Generative Models Can Outperform The Experts That Train Them
Jun 17, 2024


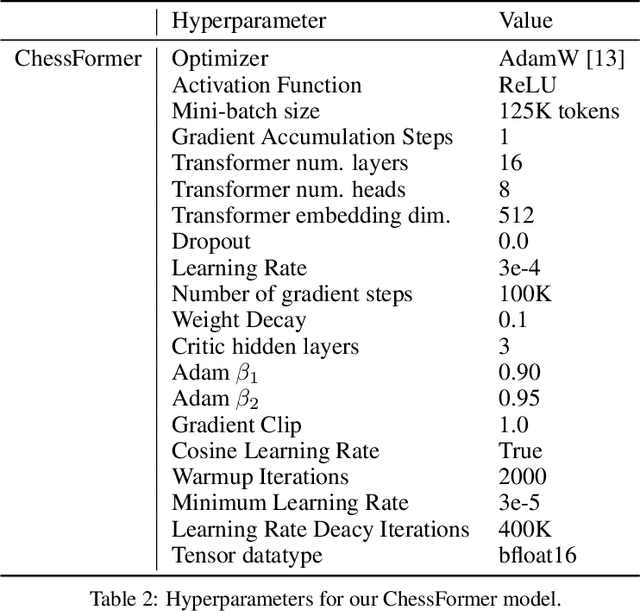
Generative models are trained with the simple objective of imitating the conditional probability distribution induced by the data they are trained on. Therefore, when trained on data generated by humans, we may not expect the artificial model to outperform the humans on their original objectives. In this work, we study the phenomenon of transcendence: when a generative model achieves capabilities that surpass the abilities of the experts generating its data. We demonstrate transcendence by training an autoregressive transformer to play chess from game transcripts, and show that the trained model can sometimes achieve better performance than all players in the dataset. We theoretically prove that transcendence is enabled by low-temperature sampling, and rigorously assess this experimentally. Finally, we discuss other sources of transcendence, laying the groundwork for future investigation of this phenomenon in a broader setting.
A Decision-Language Model (DLM) for Dynamic Restless Multi-Armed Bandit Tasks in Public Health
Feb 23, 2024Efforts to reduce maternal mortality rate, a key UN Sustainable Development target (SDG Target 3.1), rely largely on preventative care programs to spread critical health information to high-risk populations. These programs face two important challenges: efficiently allocating limited health resources to large beneficiary populations, and adapting to evolving policy priorities. While prior works in restless multi-armed bandit (RMAB) demonstrated success in public health allocation tasks, they lack flexibility to adapt to evolving policy priorities. Concurrently, Large Language Models (LLMs) have emerged as adept, automated planners in various domains, including robotic control and navigation. In this paper, we propose DLM: a Decision Language Model for RMABs. To enable dynamic fine-tuning of RMAB policies for challenging public health settings using human-language commands, we propose using LLMs as automated planners to (1) interpret human policy preference prompts, (2) propose code reward functions for a multi-agent RL environment for RMABs, and (3) iterate on the generated reward using feedback from RMAB simulations to effectively adapt policy outcomes. In collaboration with ARMMAN, an India-based public health organization promoting preventative care for pregnant mothers, we conduct a simulation study, showing DLM can dynamically shape policy outcomes using only human language commands as input.
Social Environment Design
Feb 21, 2024


Artificial Intelligence (AI) holds promise as a technology that can be used to improve government and economic policy-making. This paper proposes a new research agenda towards this end by introducing Social Environment Design, a general framework for the use of AI for automated policy-making that connects with the Reinforcement Learning, EconCS, and Computational Social Choice communities. The framework seeks to capture general economic environments, includes voting on policy objectives, and gives a direction for the systematic analysis of government and economic policy through AI simulation. We highlight key open problems for future research in AI-based policy-making. By solving these challenges, we hope to achieve various social welfare objectives, thereby promoting more ethical and responsible decision making.