 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAQJSK: Hierarchical-Aligned Quantum Jensen-Shannon Kernels for Graph Classification
Nov 08, 2022



In this work, we propose a family of novel quantum kernels, namely the Hierarchical Aligned Quantum Jensen-Shannon Kernels (HAQJSK), for un-attributed graphs. Different from most existing classical graph kernels, the proposed HAQJSK kernels can incorporate hierarchical aligned structure information between graphs and transform graphs of random sizes into fixed-sized aligned graph structures, i.e., the Hierarchical Transitive Aligned Adjacency Matrix of vertices and the Hierarchical Transitive Aligned Density Matrix of the Continuous-Time Quantum Walk (CTQW). For a pair of graphs to hand, the resulting HAQJSK kernels are defined by measuring the Quantum Jensen-Shannon Divergence (QJSD) between their transitive aligned graph structures. We show that the proposed HAQJSK kernels not only reflect richer intrinsic global graph characteristics in terms of the CTQW, but also address the drawback of neglecting structural correspondence information arising in most existing R-convolution kernels. Furthermore, unlike the previous Quantum Jensen-Shannon Kernels associated with the QJSD and the CTQW, the proposed HAQJSK kernels can simultaneously guarantee the properties of permutation invariant and positive definiteness, explaining the theoretical advantages of the HAQJSK kernels. Experiments indicate the effectiveness of the proposed kernels.
Revisiting Domain Generalized Stereo Matching Networks from a Feature Consistency Perspective
Mar 21, 2022
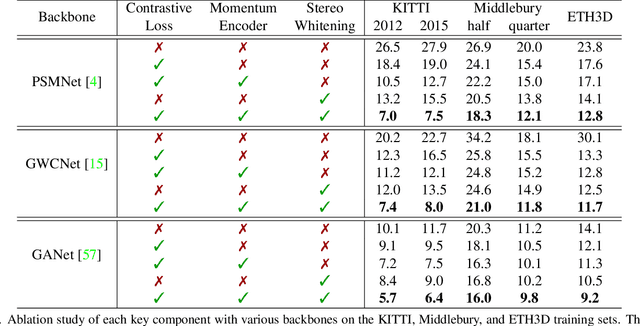
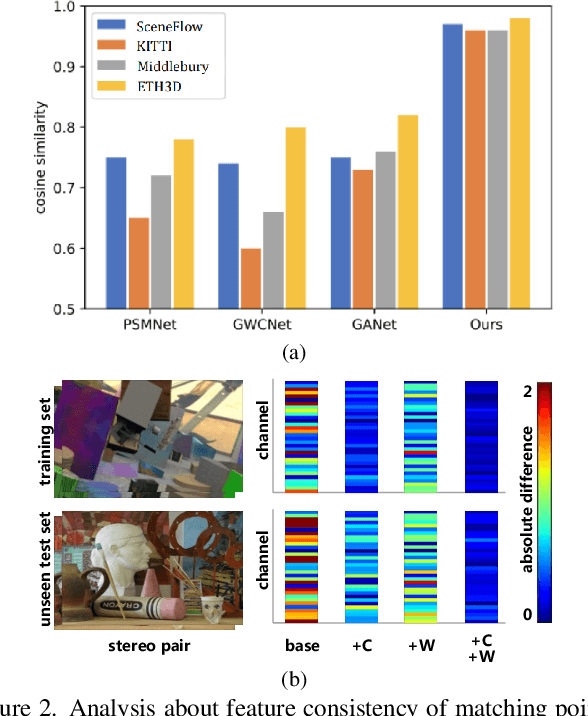

Despite recent stereo matching networks achieving impressive performance given sufficient training data, they suffer from domain shifts and generalize poorly to unseen domains. We argue that maintaining feature consistency between matching pixels is a vital factor for promoting the generalization capability of stereo matching networks, which has not been adequately considered. Here we address this issue by proposing a simple pixel-wise contrastive learning across the viewpoints. The stereo contrastive feature loss function explicitly constrains the consistency between learned features of matching pixel pairs which are observations of the same 3D points. A stereo selective whitening loss is further introduced to better preserve the stereo feature consistency across domains, which decorrelates stereo features from stereo viewpoint-specific style information. Counter-intuitively, the generalization of feature consistency between two viewpoints in the same scene translates to the generalization of stereo matching performance to unseen domains. Our method is generic in nature as it can be easily embedded into existing stereo networks and does not require access to the samples in the target domain. When trained on synthetic data and generalized to four real-world testing sets, our method achieves superior performance over several state-of-the-art networks.
HMFlow: Hybrid Matching Optical Flow Network for Small and Fast-Moving Objects
Nov 19, 2020



In optical flow estimation task, coarse-to-fine (C2F) warping strategy is widely used to deal with the large displacement problem and provides efficiency and speed. However, limited by the small search range between the first images and warped second images, current coarse-to-fine optical flow networks fail to capture small and fast-moving objects which disappear at coarse resolution levels. To address this problem, we introduce a lightweight but effective Global Matching Component (GMC) to grab global matching features. We propose a new Hybrid Matching Optical Flow Network (HMFlow) by integrating GMC into existing coarse-to-fine networks seamlessly. Besides keeping in high accuracy and small model size, our proposed HMFlow can apply global matching features to guide the network to discover the small and fast-moving objects mismatched by local matching features. We also build a new dataset, named Small and Fast-Moving Chairs (SFChairs), for evaluation. The experimental results show that our proposed network achieves considerable performance, especially at regions with small and fast-moving objects.
Cross-Supervised Joint-Event-Extraction with Heterogeneous Information Networks
Oct 14, 2020
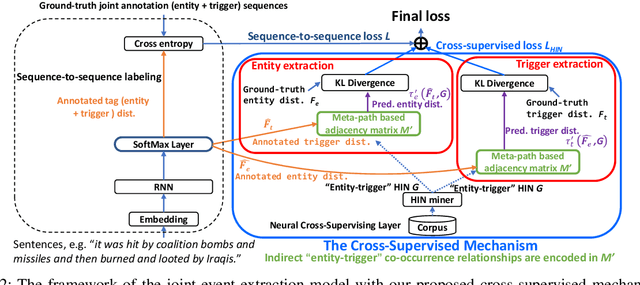
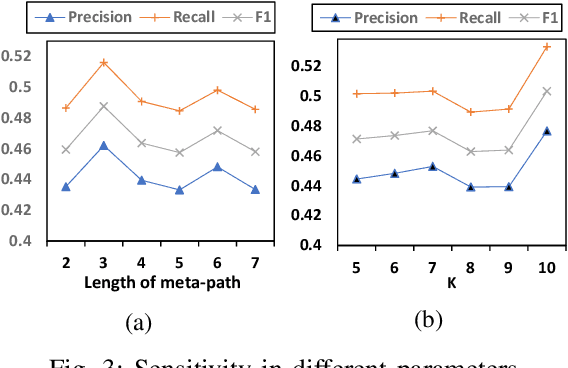

Joint-event-extraction, which extracts structural information (i.e., entities or triggers of events) from unstructured real-world corpora, has attracted more and more research attention in natural language processing. Most existing works do not fully address the sparse co-occurrence relationships between entities and triggers, which loses this important information and thus deteriorates the extraction performance. To mitigate this issue, we first define the joint-event-extraction as a sequence-to-sequence labeling task with a tag set composed of tags of triggers and entities. Then, to incorporate the missing information in the aforementioned co-occurrence relationships, we propose a Cross-Supervised Mechanism (CSM) to alternately supervise the extraction of either triggers or entities based on the type distribution of each other. Moreover, since the connected entities and triggers naturally form a heterogeneous information network (HIN), we leverage the latent pattern along meta-paths for a given corpus to further improve the performance of our proposed method. To verify the effectiveness of our proposed method, we conduct extensive experiments on four real-world datasets as well as compare our method with state-of-the-art methods. Empirical results and analysis show that our approach outperforms the state-of-the-art methods in both entity and trigger extraction.
A Hierarchical Transitive-Aligned Graph Kernel for Un-attributed Graphs
Feb 08, 2020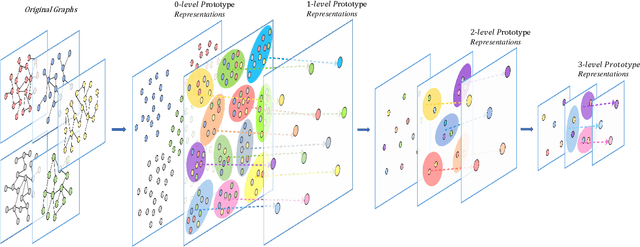
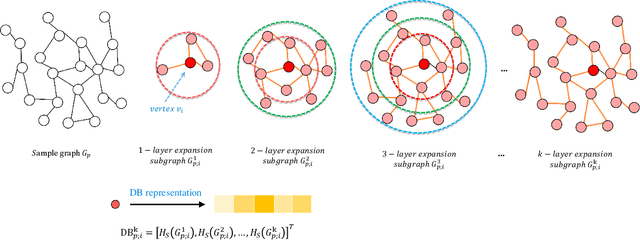


In this paper, we develop a new graph kernel, namely the Hierarchical Transitive-Aligned kernel, by transitively aligning the vertices between graphs through a family of hierarchical prototype graphs. Comparing to most existing state-of-the-art graph kernels, the proposed kernel has three theoretical advantages. First, it incorporates the locational correspondence information between graphs into the kernel computation, and thus overcomes the shortcoming of ignoring structural correspondences arising in most R-convolution kernels. Second, it guarantees the transitivity between the correspondence information that is not available for most existing matching kernels. Third, it incorporates the information of all graphs under comparisons into the kernel computation process, and thus encapsulates richer characteristics. By transductively training the C-SVM classifier, experimental evaluations demonstrate the effectiveness of the new transitive-aligned kernel. The proposed kernel can outperform state-of-the-art graph kernels on standard graph-based datasets in terms of the classification accuracy.
Entropic Dynamic Time Warping Kernels for Co-evolving Financial Time Series Analysis
Oct 21, 2019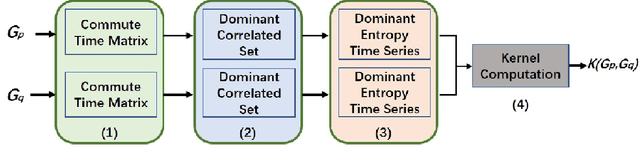
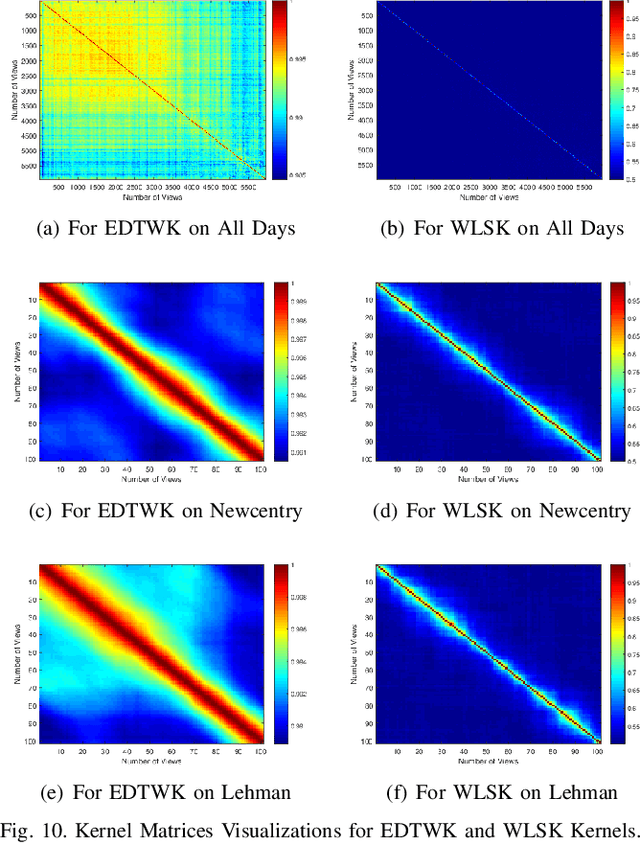
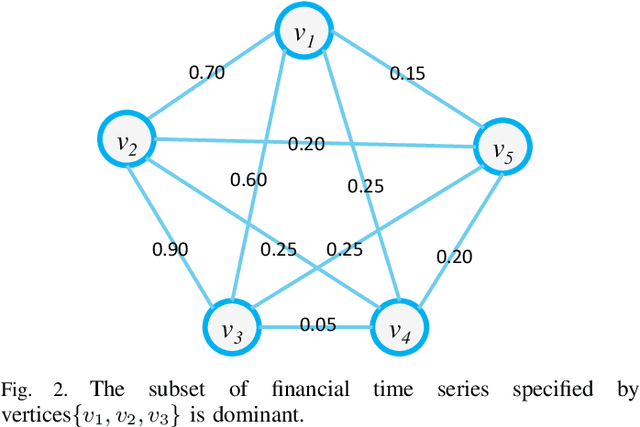
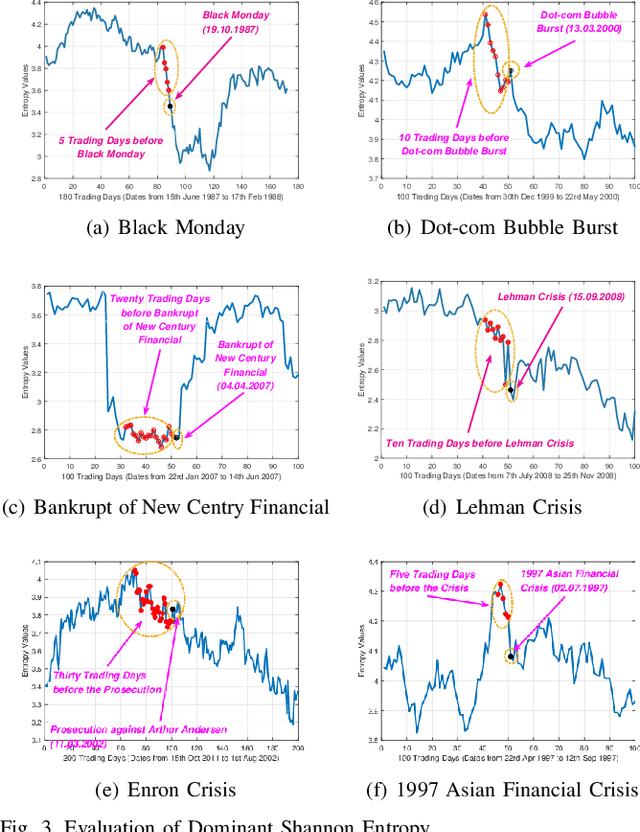
In this work, we develop a novel framework to measure the similarity between dynamic financial networks, i.e., time-varying financial networks. Particularly, we explore whether the proposed similarity measure can be employed to understand the structural evolution of the financial networks with time. For a set of time-varying financial networks with each vertex representing the individual time series of a different stock and each edge between a pair of time series representing the absolute value of their Pearson correlation, our start point is to compute the commute time matrix associated with the weighted adjacency matrix of the network structures, where each element of the matrix can be seen as the enhanced correlation value between pairwise stocks. For each network, we show how the commute time matrix allows us to identify a reliable set of dominant correlated time series as well as an associated dominant probability distribution of the stock belonging to this set. Furthermore, we represent each original network as a discrete dominant Shannon entropy time series computed from the dominant probability distribution. With the dominant entropy time series for each pair of financial networks to hand, we develop a similarity measure based on the classical dynamic time warping framework, for analyzing the financial time-varying networks. We show that the proposed similarity measure is positive definite and thus corresponds to a kernel measure on graphs. The proposed kernel bridges the gap between graph kernels and the classical dynamic time warping framework for multiple financial time series analysis. Experiments on time-varying networks extracted through New York Stock Exchange (NYSE) database demonstrate the effectiveness of the proposed approach.
Learning Aligned-Spatial Graph Convolutional Networks for Graph Classification
Apr 06, 2019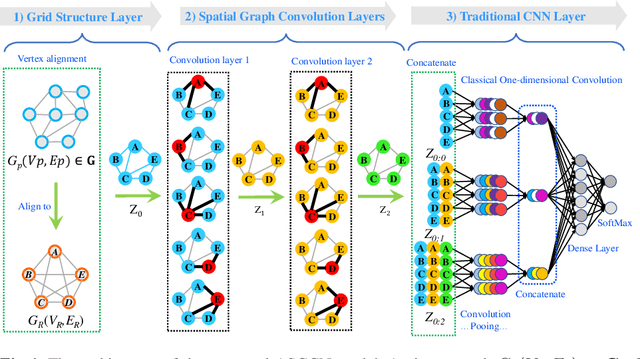
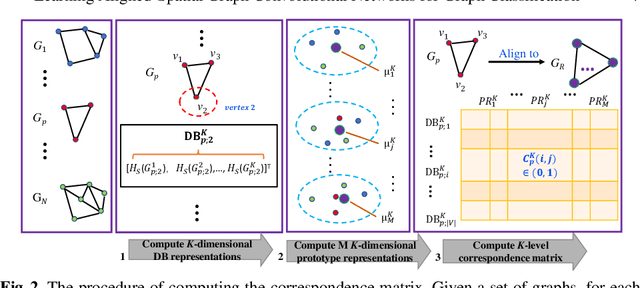
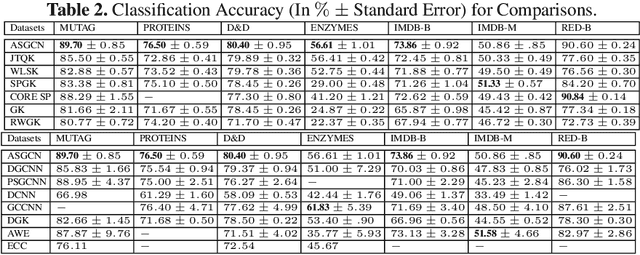
In this paper, we develop a novel Aligned-Spatial Graph Convolutional Network (ASGCN) model to learn effective features for graph classification. Our idea is to transform arbitrary-sized graphs into fixed-sized aligned grid structures, and define a new spatial graph convolution operation associated with the grid structures. We show that the proposed ASGCN model not only reduces the problems of information loss and imprecise information representation arising in existing spatially-based Graph Convolutional Network (GCN) models, but also bridges the theoretical gap between traditional Convolutional Neural Network (CNN) models and spatially-based GCN models. Moreover, the proposed ASGCN model can adaptively discriminate the importance between specified vertices during the process of spatial graph convolution, explaining the effectiveness of the proposed model. Experiments on standard graph datasets demonstrate the effectiveness of the proposed model.
Fused Lasso for Feature Selection using Structural Information
Feb 26, 2019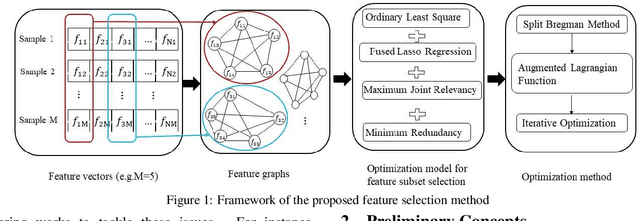
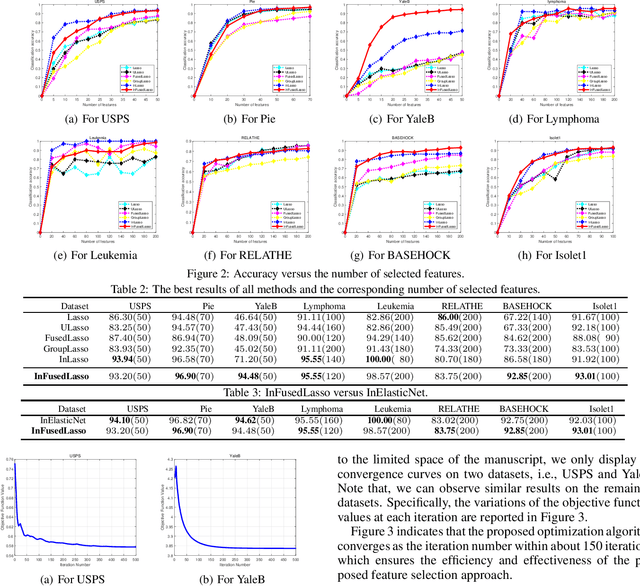
Feature selection has been proven a powerful preprocessing step for high-dimensional data analysis. However, most state-of-the-art methods suffer from two major drawbacks. First, they usually overlook the structural correlation information between pairwise samples, which may encapsulate useful information for refining the performance of feature selection. Second, they usually consider candidate feature relevancy equivalent to selected feature relevancy, and some less relevant features may be misinterpreted as salient features. To overcome these issues, we propose a new fused lasso for feature selection using structural information. Our idea is based on converting the original vectorial features into structure-based feature graph representations to incorporate structural relationship between samples, and defining a new evaluation measure to compute the joint significance of pairwise feature combinations in relation to the target feature graph. Furthermore, we formulate the corresponding feature subset selection problem into a least square regression model associated with a fused lasso regularizer to simultaneously maximize the joint relevancy and minimize the redundancy of the selected features. To effectively solve the challenging optimization problem, an iterative algorithm is developed to identify the most discriminative features. Experiments demonstrate the effectiveness of the proposed approach.
Learning Vertex Convolutional Networks for Graph Classification
Feb 26, 2019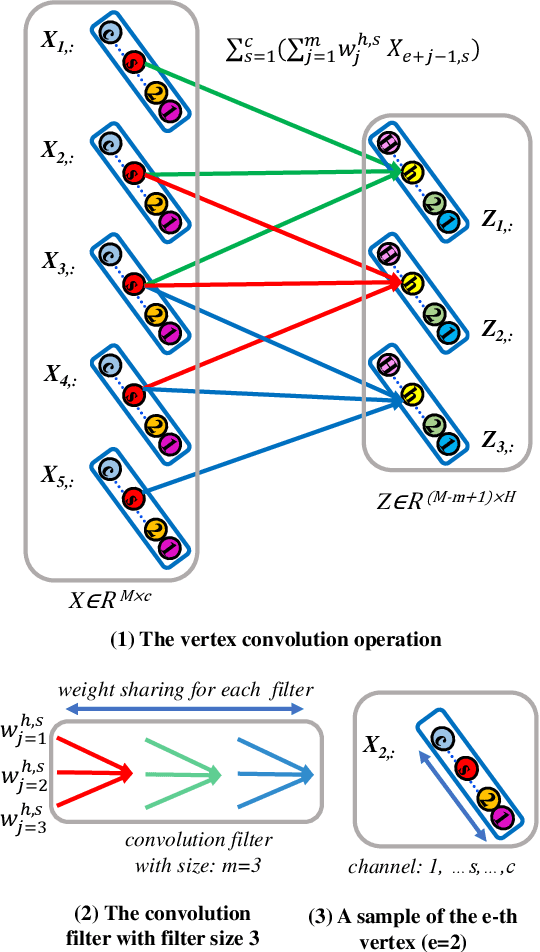


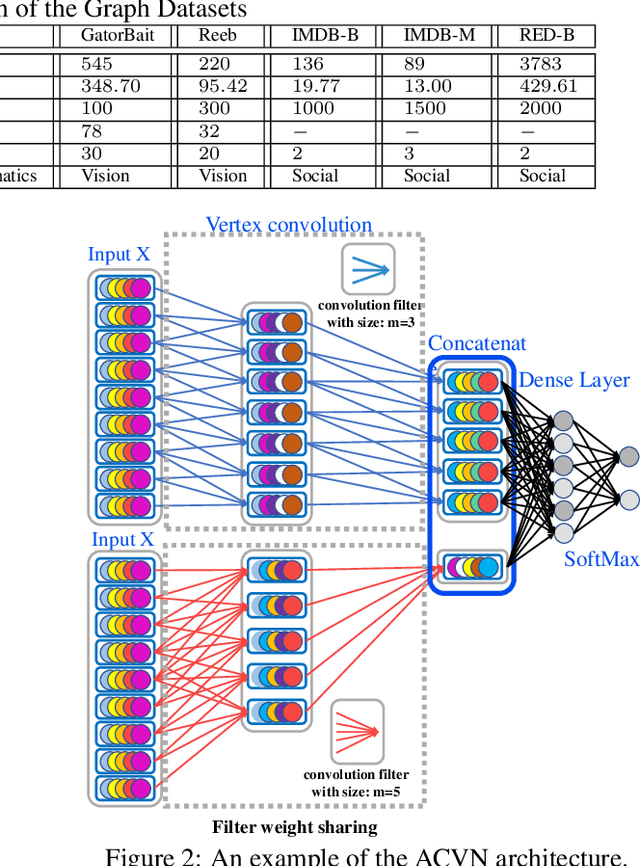
In this paper, we develop a new aligned vertex convolutional network model to learn multi-scale local-level vertex features for graph classification. Our idea is to transform the graphs of arbitrary sizes into fixed-sized aligned vertex grid structures, and define a new vertex convolution operation by adopting a set of fixed-sized one-dimensional convolution filters on the grid structure. We show that the proposed model not only integrates the precise structural correspondence information between graphs but also minimises the loss of structural information residing on local-level vertices. Experiments on standard graph datasets demonstrate the effectiveness of the proposed model.
Identifying The Most Informative Features Using A Structurally Interacting Elastic Net
Sep 08, 2018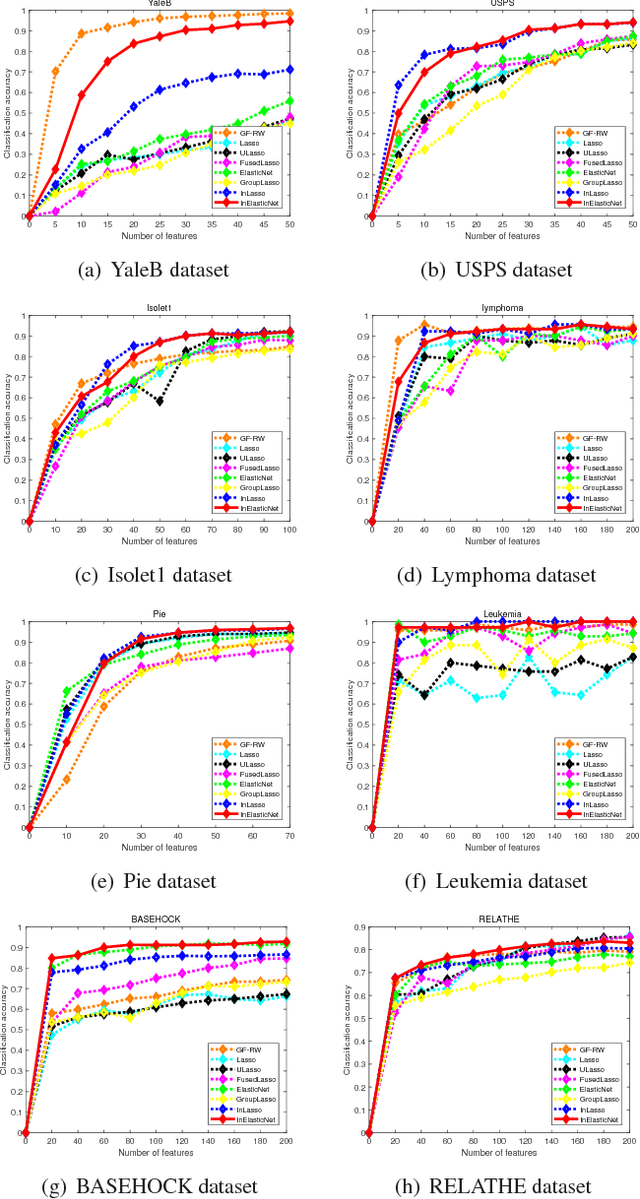
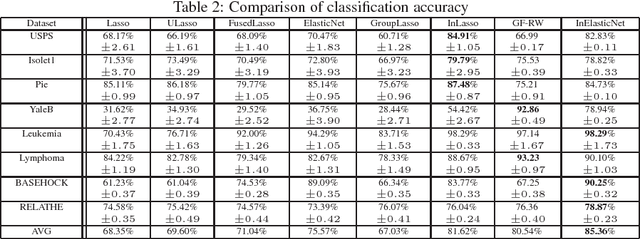
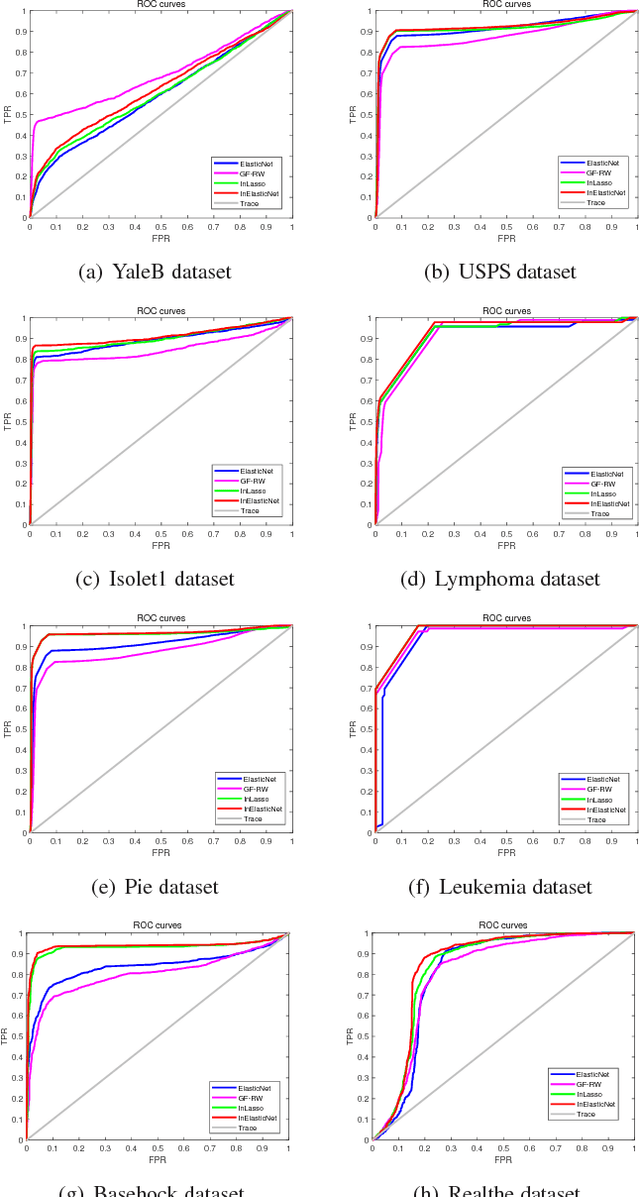
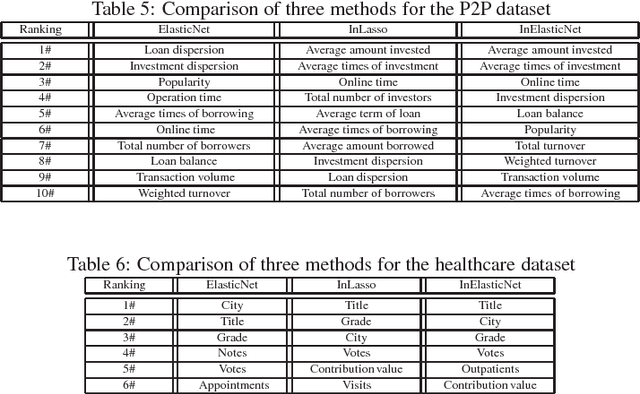
Feature selection can efficiently identify the most informative features with respect to the target feature used in training. However, state-of-the-art vector-based methods are unable to encapsulate the relationships between feature samples into the feature selection process, thus leading to significant information loss. To address this problem, we propose a new graph-based structurally interacting elastic net method for feature selection. Specifically, we commence by constructing feature graphs that can incorporate pairwise relationship between samples. With the feature graphs to hand, we propose a new information theoretic criterion to measure the joint relevance of different pairwise feature combinations with respect to the target feature graph representation. This measure is used to obtain a structural interaction matrix where the elements represent the proposed information theoretic measure between feature pairs. We then formulate a new optimization model through the combination of the structural interaction matrix and an elastic net regression model for the feature subset selection problem. This allows us to a) preserve the information of the original vectorial space, b) remedy the information loss of the original feature space caused by using graph representation, and c) promote a sparse solution and also encourage correlated features to be selected. Because the proposed optimization problem is non-convex, we develop an efficient alternating direction multiplier method (ADMM) to locate the optimal solutions. Extensive experiments on various datasets demonstrate the effectiveness of the proposed methods.