 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplay-Guided Adversarial Environment Design
Oct 06, 2021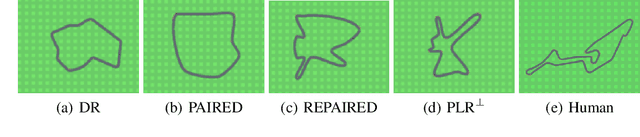
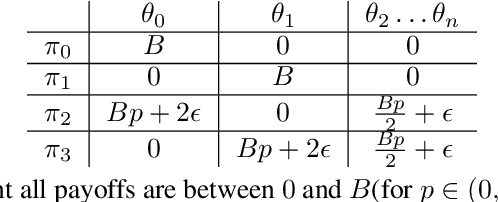
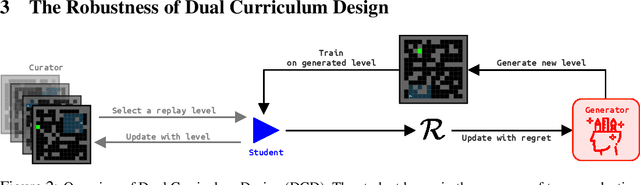
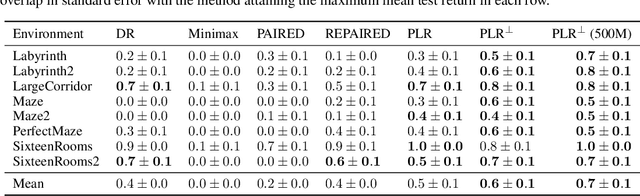
Deep reinforcement learning (RL) agents may successfully generalize to new settings if trained on an appropriately diverse set of environment and task configurations. Unsupervised Environment Design (UED) is a promising self-supervised RL paradigm, wherein the free parameters of an underspecified environment are automatically adapted during training to the agent's capabilities, leading to the emergence of diverse training environments. Here, we cast Prioritized Level Replay (PLR), an empirically successful but theoretically unmotivated method that selectively samples randomly-generated training levels, as UED. We argue that by curating completely random levels, PLR, too, can generate novel and complex levels for effective training. This insight reveals a natural class of UED methods we call Dual Curriculum Design (DCD). Crucially, DCD includes both PLR and a popular UED algorithm, PAIRED, as special cases and inherits similar theoretical guarantees. This connection allows us to develop novel theory for PLR, providing a version with a robustness guarantee at Nash equilibria. Furthermore, our theory suggests a highly counterintuitive improvement to PLR: by stopping the agent from updating its policy on uncurated levels (training on less data), we can improve the convergence to Nash equilibria. Indeed, our experiments confirm that our new method, PLR$^{\perp}$, obtains better results on a suite of out-of-distribution, zero-shot transfer tasks, in addition to demonstrating that PLR$^{\perp}$ improves the performance of PAIRED, from which it inherited its theoretical framework.
MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research
Sep 27, 2021
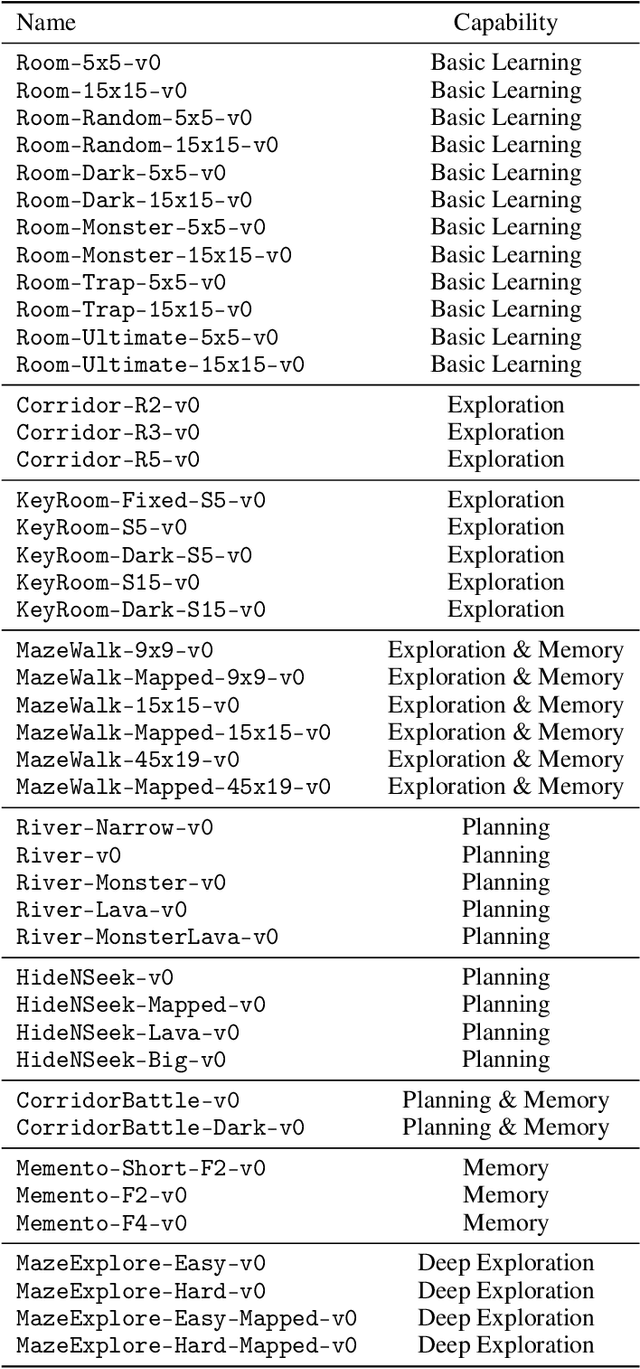

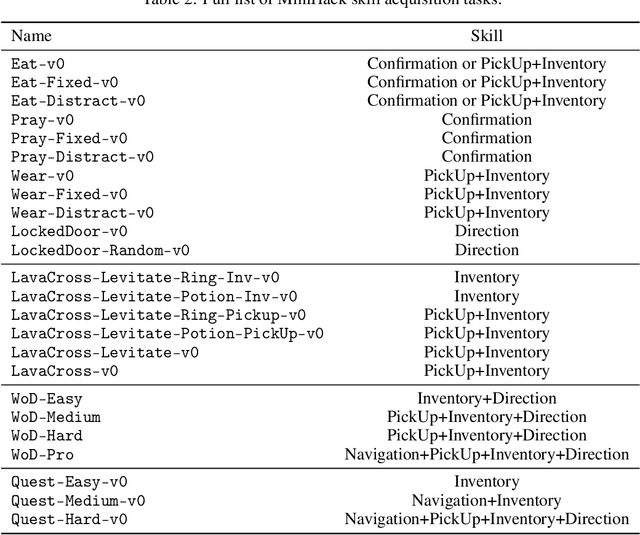
The progress in deep reinforcement learning (RL) is heavily driven by the availability of challenging benchmarks used for training agents. However, benchmarks that are widely adopted by the community are not explicitly designed for evaluating specific capabilities of RL methods. While there exist environments for assessing particular open problems in RL (such as exploration, transfer learning, unsupervised environment design, or even language-assisted RL), it is generally difficult to extend these to richer, more complex environments once research goes beyond proof-of-concept results. We present MiniHack, a powerful sandbox framework for easily designing novel RL environments. MiniHack is a one-stop shop for RL experiments with environments ranging from small rooms to complex, procedurally generated worlds. By leveraging the full set of entities and environment dynamics from NetHack, one of the richest grid-based video games, MiniHack allows designing custom RL testbeds that are fast and convenient to use. With this sandbox framework, novel environments can be designed easily, either using a human-readable description language or a simple Python interface. In addition to a variety of RL tasks and baselines, MiniHack can wrap existing RL benchmarks and provide ways to seamlessly add additional complexity.
Learning Reasoning Strategies in End-to-End Differentiable Proving
Jul 14, 2020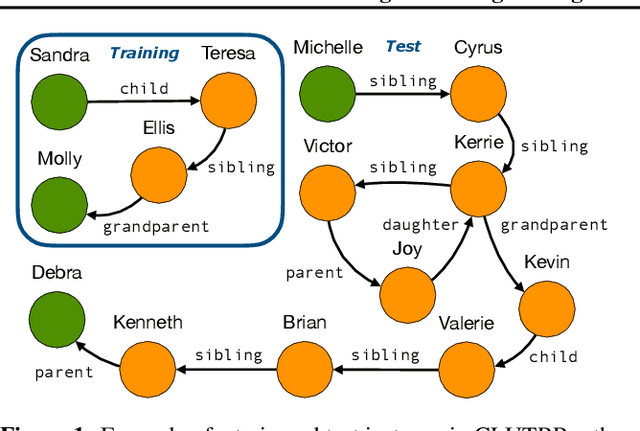
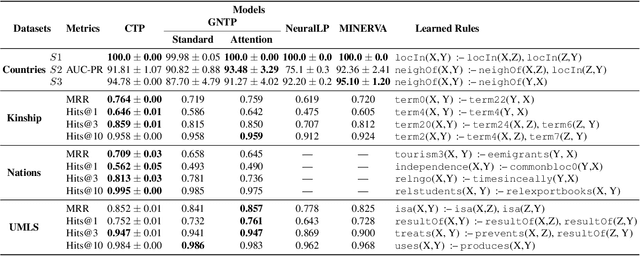

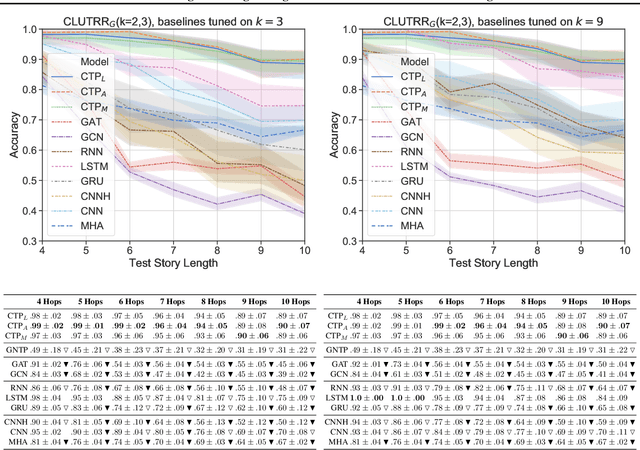
Attempts to render deep learning models interpretable, data-efficient, and robust have seen some success through hybridisation with rule-based systems, for example, in Neural Theorem Provers (NTPs). These neuro-symbolic models can induce interpretable rules and learn representations from data via back-propagation, while providing logical explanations for their predictions. However, they are restricted by their computational complexity, as they need to consider all possible proof paths for explaining a goal, thus rendering them unfit for large-scale applications. We present Conditional Theorem Provers (CTPs), an extension to NTPs that learns an optimal rule selection strategy via gradient-based optimisation. We show that CTPs are scalable and yield state-of-the-art results on the CLUTRR dataset, which tests systematic generalisation of neural models by learning to reason over smaller graphs and evaluating on larger ones. Finally, CTPs show better link prediction results on standard benchmarks in comparison with other neural-symbolic models, while being explainable. All source code and datasets are available online, at https://github.com/uclnlp/ctp.
The NetHack Learning Environment
Jun 24, 2020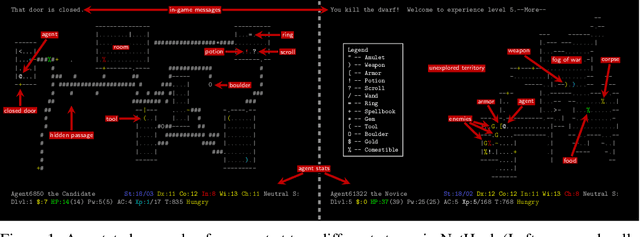
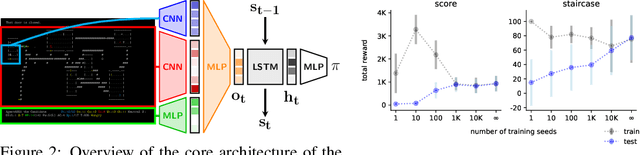
Progress in Reinforcement Learning (RL) algorithms goes hand-in-hand with the development of challenging environments that test the limits of current methods. While existing RL environments are either sufficiently complex or based on fast simulation, they are rarely both. Here, we present the NetHack Learning Environment (NLE), a scalable, procedurally generated, stochastic, rich, and challenging environment for RL research based on the popular single-player terminal-based roguelike game, NetHack. We argue that NetHack is sufficiently complex to drive long-term research on problems such as exploration, planning, skill acquisition, and language-conditioned RL, while dramatically reducing the computational resources required to gather a large amount of experience. We compare NLE and its task suite to existing alternatives, and discuss why it is an ideal medium for testing the robustness and systematic generalization of RL agents. We demonstrate empirical success for early stages of the game using a distributed Deep RL baseline and Random Network Distillation exploration, alongside qualitative analysis of various agents trained in the environment. NLE is open source at https://github.com/facebookresearch/nle.
Learning with AMIGo: Adversarially Motivated Intrinsic Goals
Jun 22, 2020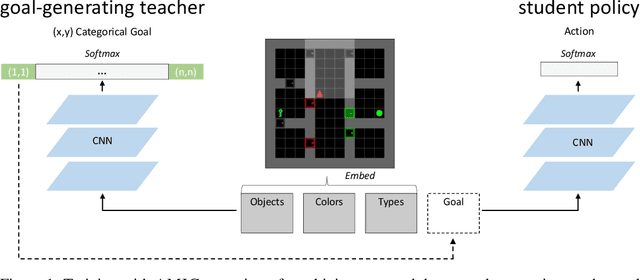
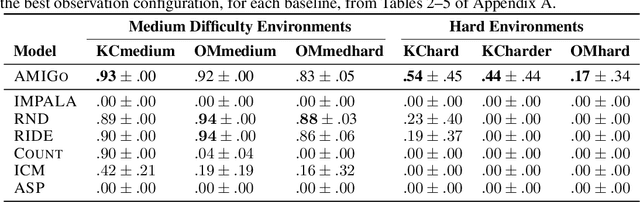
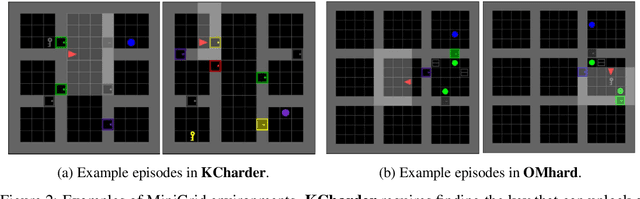
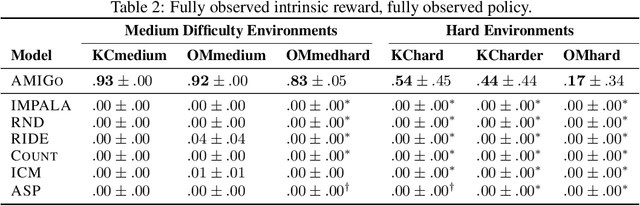
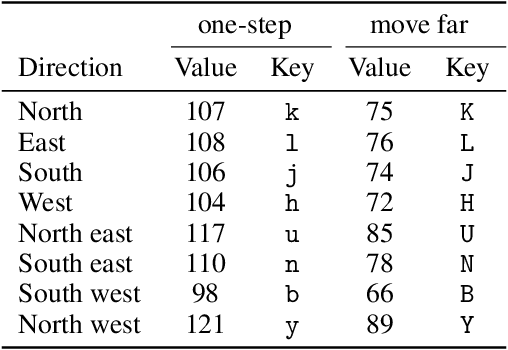
A key challenge for reinforcement learning (RL) consists of learning in environments with sparse extrinsic rewards. In contrast to current RL methods, humans are able to learn new skills with little or no reward by using various forms of intrinsic motivation. We propose AMIGo, a novel agent incorporating a goal-generating teacher that proposes Adversarially Motivated Intrinsic Goals to train a goal-conditioned "student" policy in the absence of (or alongside) environment reward. Specifically, through a simple but effective "constructively adversarial" objective, the teacher learns to propose increasingly challenging---yet achievable---goals that allow the student to learn general skills for acting in a new environment, independent of the task to be solved. We show that our method generates a natural curriculum of self-proposed goals which ultimately allows the agent to solve challenging procedurally-generated tasks where other forms of intrinsic motivation and state-of-the-art RL methods fail.
Differentiable Reasoning on Large Knowledge Bases and Natural Language
Dec 17, 2019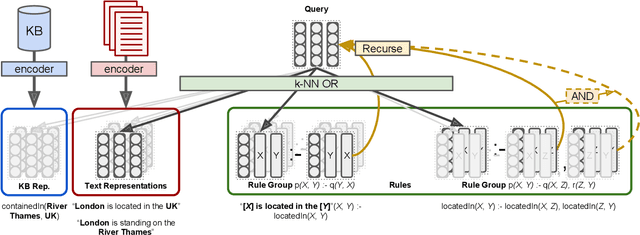
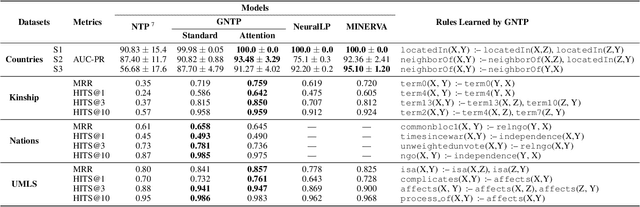
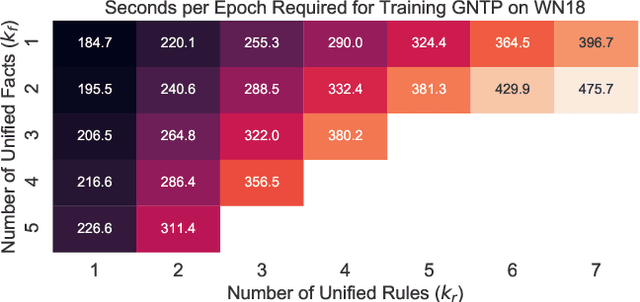
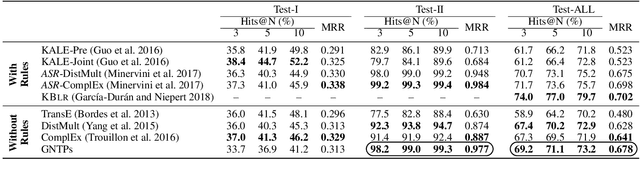
Reasoning with knowledge expressed in natural language and Knowledge Bases (KBs) is a major challenge for Artificial Intelligence, with applications in machine reading, dialogue, and question answering. General neural architectures that jointly learn representations and transformations of text are very data-inefficient, and it is hard to analyse their reasoning process. These issues are addressed by end-to-end differentiable reasoning systems such as Neural Theorem Provers (NTPs), although they can only be used with small-scale symbolic KBs. In this paper we first propose Greedy NTPs (GNTPs), an extension to NTPs addressing their complexity and scalability limitations, thus making them applicable to real-world datasets. This result is achieved by dynamically constructing the computation graph of NTPs and including only the most promising proof paths during inference, thus obtaining orders of magnitude more efficient models. Then, we propose a novel approach for jointly reasoning over KBs and textual mentions, by embedding logic facts and natural language sentences in a shared embedding space. We show that GNTPs perform on par with NTPs at a fraction of their cost while achieving competitive link prediction results on large datasets, providing explanations for predictions, and inducing interpretable models. Source code, datasets, and supplementary material are available online at https://github.com/uclnlp/gntp.
RTFM: Generalising to Novel Environment Dynamics via Reading
Oct 18, 2019
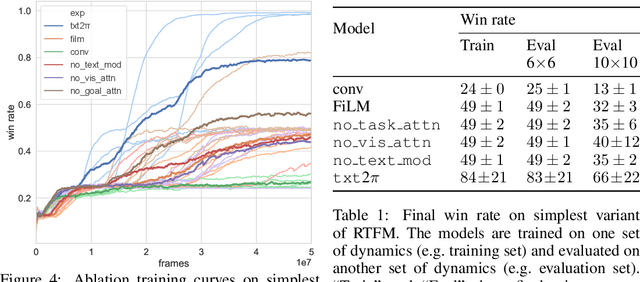
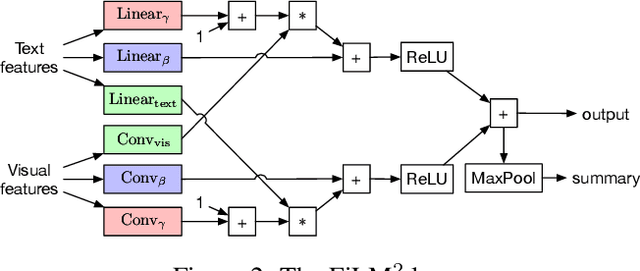

Obtaining policies that can generalise to new environments in reinforcement learning is challenging. In this work, we demonstrate that language understanding via a reading policy learner is a promising vehicle for generalisation to new environments. We propose a grounded policy learning problem, Read to Fight Monsters (RTFM), in which the agent must jointly reason over a language goal, relevant dynamics described in a document, and environment observations. We procedurally generate environment dynamics and corresponding language descriptions of the dynamics, such that agents must read to understand new environment dynamics instead of memorising any particular information. In addition, we propose txt2$\pi$, a model that captures three-way interactions between the goal, document, and observations. On RTFM, txt2$\pi$ generalises to new environments with dynamics not seen during training via reading. Furthermore, our model outperforms baselines such as FiLM and language-conditioned CNNs on RTFM. Through curriculum learning, txt2$\pi$ produces policies that excel on complex RTFM tasks requiring several reasoning and coreference steps.
TorchBeast: A PyTorch Platform for Distributed RL
Oct 08, 2019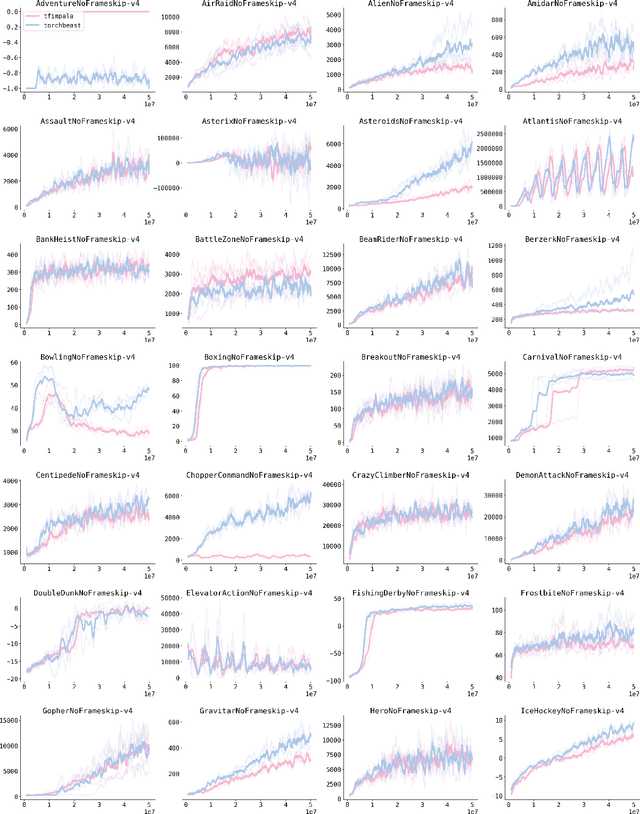
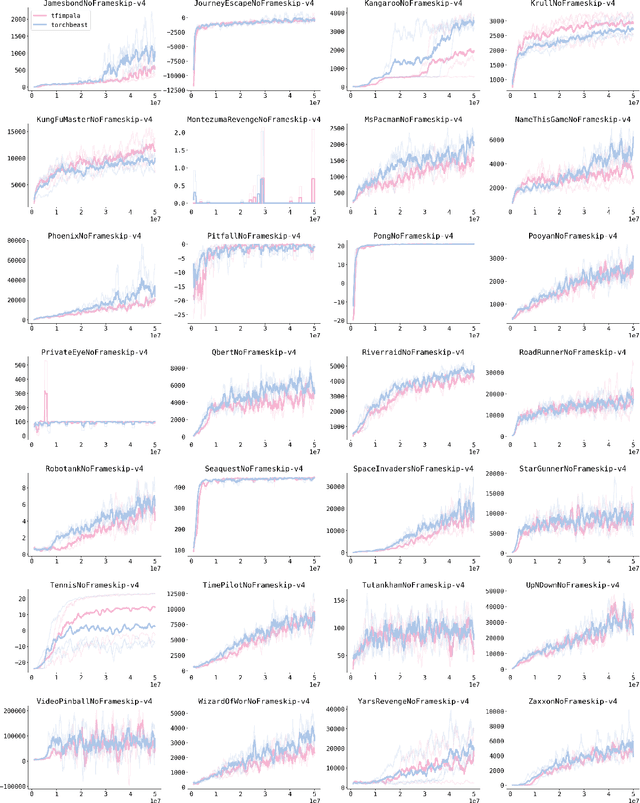
TorchBeast is a platform for reinforcement learning (RL) research in PyTorch. It implements a version of the popular IMPALA algorithm for fast, asynchronous, parallel training of RL agents. Additionally, TorchBeast has simplicity as an explicit design goal: We provide both a pure-Python implementation ("MonoBeast") as well as a multi-machine high-performance version ("PolyBeast"). In the latter, parts of the implementation are written in C++, but all parts pertaining to machine learning are kept in simple Python using PyTorch, with the environments provided using the OpenAI Gym interface. This enables researchers to conduct scalable RL research using TorchBeast without any programming knowledge beyond Python and PyTorch. In this paper, we describe the TorchBeast design principles and implementation and demonstrate that it performs on-par with IMPALA on Atari. TorchBeast is released as an open-source package under the Apache 2.0 license and is available at \url{https://github.com/facebookresearch/torchbeast}.
Generalized Inner Loop Meta-Learning
Oct 07, 2019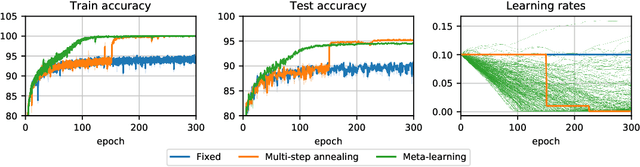

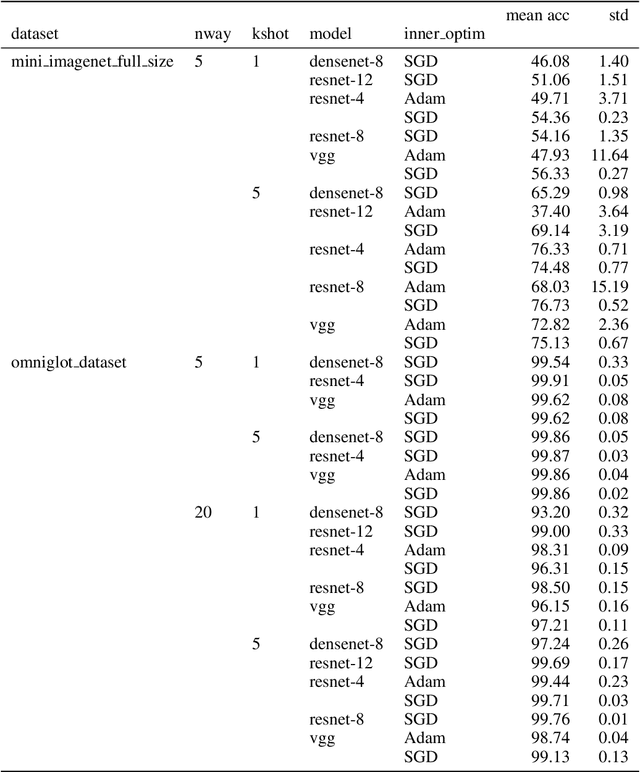
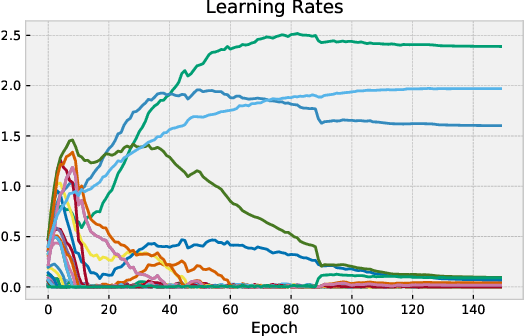
Many (but not all) approaches self-qualifying as "meta-learning" in deep learning and reinforcement learning fit a common pattern of approximating the solution to a nested optimization problem. In this paper, we give a formalization of this shared pattern, which we call GIMLI, prove its general requirements, and derive a general-purpose algorithm for implementing similar approaches. Based on this analysis and algorithm, we describe a library of our design, higher, which we share with the community to assist and enable future research into these kinds of meta-learning approaches. We end the paper by showcasing the practical applications of this framework and library through illustrative experiments and ablation studies which they facilitate.
A Survey of Reinforcement Learning Informed by Natural Language
Jun 10, 2019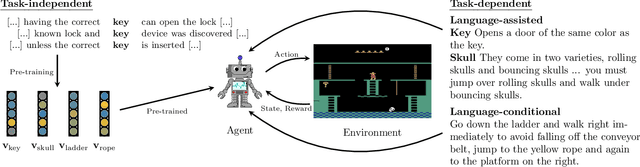
To be successful in real-world tasks, Reinforcement Learning (RL) needs to exploit the compositional, relational, and hierarchical structure of the world, and learn to transfer it to the task at hand. Recent advances in representation learning for language make it possible to build models that acquire world knowledge from text corpora and integrate this knowledge into downstream decision making problems. We thus argue that the time is right to investigate a tight integration of natural language understanding into RL in particular. We survey the state of the field, including work on instruction following, text games, and learning from textual domain knowledge. Finally, we call for the development of new environments as well as further investigation into the potential uses of recent Natural Language Processing (NLP) techniques for such tasks.